Looking for a research paper but can’t find a copy in your library’s catalog or popular search engines? Give Internet Archive Scholar a try! We might have a PDF from a “vanished” Open Access publisher in our web archive, an author’s pre-publication manuscript from their archived faculty webpage, or a digitized microfilm version of an older publication.
We hope Internet Archive Scholar will aid researchers and librarians looking for specific open access papers that may not be otherwise available to them. Judith van Stegeren (@jd7g on Twitter), a PhD candidate in the Netherlands, encountered just such a situation recently when sharing a workshop paper on procedural generation in computer games: “Towards Qualitative Procedural Generation” by Mark R. Johnson, originally presented at the Computational Creativity & Games Workshop in 2016. The papers for this particular year of the workshop are not indexed in the usual bibliographic catalogs, and the original workshop website hosting the Open Access papers is no longer accessible. Fortunately, copies of all the 2016 workshop papers were captured in the Wayback Machine, and can be found today by searching IA Scholar by title or conference name.
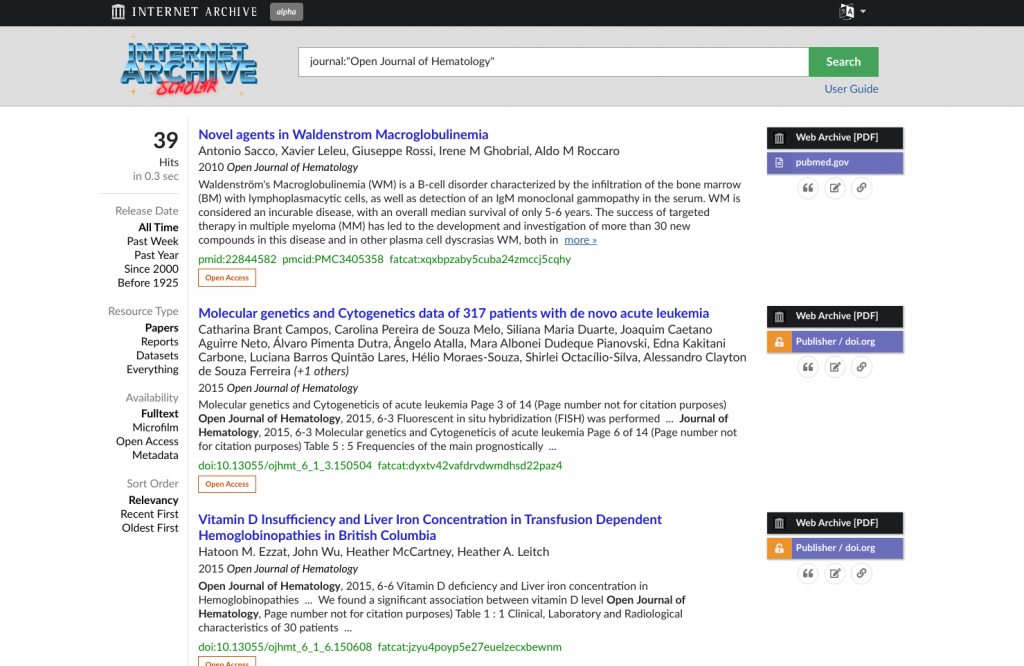
As another example, dozens of papers from the Open Journal of Hematology are no longer resolvable via DOI. As mentioned in a previous blog post, the publisher’s website vanished and has been replaced with unrelated advertisements. But before that happened, the papers were captured in the Wayback Machine, indexed in our catalog, and can now be searched in full:
IA Scholar is a simple, access-oriented interface to content identified across several Internet Archive collections, including web archives, archive.org files, and digitized print materials. The full text of articles is searchable for users that are hunting for particular phrases or keywords. This complements our existing full-text search index of millions of digitized books and other documents on archive.org.
The service builds on Fatcat, an open catalog we have developed to identify at-risk and web-published open scholarly outputs that can benefit from long-term preservation, additional metadata, and perpetual access. Fatcat includes resources that may be useful to librarians and archivists, such as bulk metadata dumps, a read/write API, command-line tool, and file-level archival metadata. If you are interested in collaborating with us, or are a researcher interested in text analysis applications, we have a public chat channel or can be contacted by email at info@archive.org.
IA Scholar marks a milestone in our work initiated in 2018 to leverage the automation and scale of web and API harvesting in providing open infrastructure for the preservation of and perpetual access to scholarly materials from the public web. We particularly want to thank the Mellon Foundation for their original and ongoing support of this work, our many current partners, and the other collaborators, contributors, and volunteers.
All of this is possible because of the incredible open research ecosystem built and collectively maintained by Open Access advocates. Thank you to the DOAJ and other groups for helping catalog open access journals which has aided preservation. Thank you to the Biodiversity Heritage Library and its supporters for digitizing print journal literature. And thank you to the many other organizations we have worked with, integrated, or whose services we have utilized, including open web indices (Unpaywall, CORE, CiteseerX, Microsoft Academic, Semantic Scholar), directories of open journals (DOAJ, ROAD SHERPA/ROMEO, JURN, Wikidata), and open bibliographic catalogs (Crossref, Datacite, J-STAGE, Pubmed, dblp).
IA Scholar is built from open source software components, and is itself released as Free Software. The website has been translated into eight languages (so far!) by generous volunteers.