Guest post by Dr. Kalev Leetaru
Radio remains one of the most-consumed forms of traditional media today, with 89% of Americans listening to radio at least once a week as of 2018, a number that is actually increasing during the pandemic. News is the most popular radio format and 60% of Americans trust radio news to “deliver timely information about the current COVID-19 outbreak.”
Local talk radio is home to a diverse assortment of personality-driven programming that offers unique insights into the concerns and interests of citizens across the nation. Yet radio has remained stubbornly inaccessible to scholars due to the technical challenges of monitoring and transcribing broadcast speech at scale.
Debuting this past July, the Internet Archive’s Radio Archive uses automatic speech recognition technology to transcribe this vast collection of daily news and talk radio programming into searchable text dating back to 2016, and continues to archive and transcribe a selection of stations through present, making them browsable and keyword searchable.
Ngrams data set
Building on this incredible archive, the GDELT Project and I have transformed this massive archive into a research dataset of radio news ngrams spanning 26 billion English language words across portions of 550 stations, from 2016 to the present.
You can keyword search all 3 million shows, but for researchers interested in diving into the deeper linguistic patterns of radio news, the new ngrams dataset includes 1-5grams at 10 minute resolution covering all four years and updated every 30 minutes. For those less familiar with the concept of “ngrams,” they are word frequency tables in which the transcript of each broadcast is broken into words and for each 10 minute block of airtime a list is compiled of all of the words spoken in those 10 minutes for each station and how many times each word was mentioned.
Some initial research using these ngrams
How can researchers use this kind of data to understand new insights into radio news?
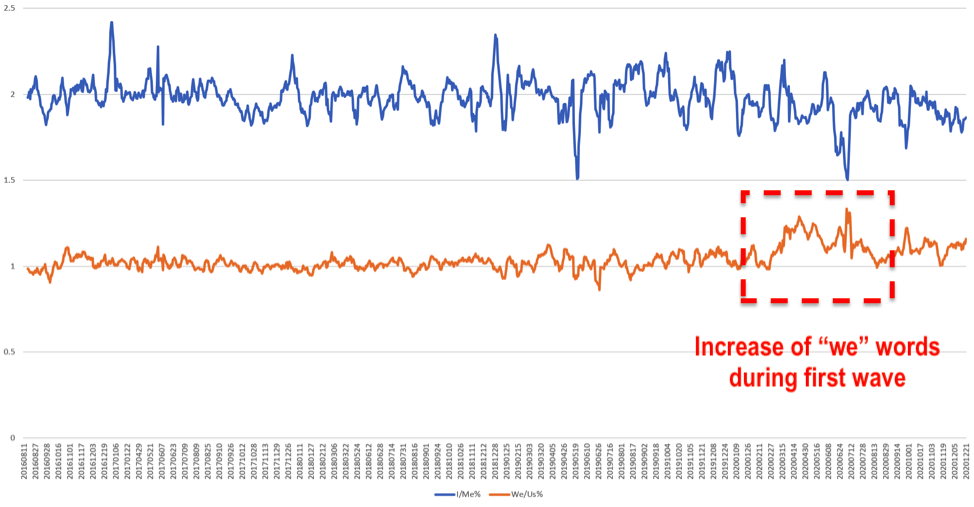
The graph below looks at pronoun usage on BBC Radio 4 FM, comparing the percentage of words spoken each day that were either (“we”, “us”, “our”, “ours”, “ourselves”) or (“i”, “me”, “i’m”). “Me” words are used more than twice as often as “we” words but look closely at February of 2020 as the pandemic began sweeping the world and “we” words start increasing as governments began adopting language to emphasize togetherness.
TV vs. Radio
Combined with the television news ngrams that I previously created, it is possible to compare how topics are being covered across television and radio.
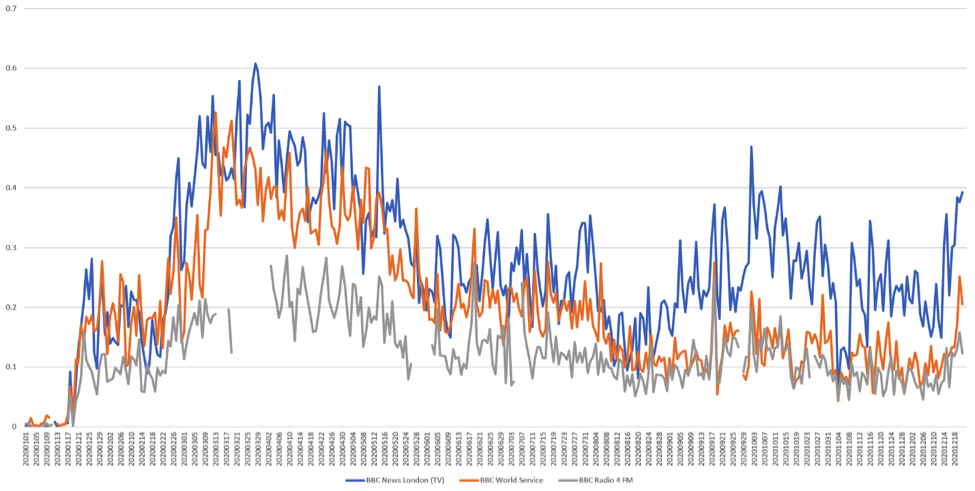
The graph below compares the percentage of spoken words that mentioned Covid-19 since the start of this year across BBC News London (television) versus radio programming on BBC World Service (international focus) and BBC Radio 4 FM (domestic focus).
All three show double surges at the start of the year as the pandemic swept across the world, a peak in early April and then a decrease since. Yet BBC Radio 4 appears to have mentioned the pandemic far less than the internationally-focused BBC World Service, though the two are now roughly equal even as the pandemic has continued to spread. Over all, television news has emphasized Covid-19 more than radio.
For now, you can download the entire dataset to explore on your own computer but there will also be an interactive visualization and analysis interface available sometime in mid-Spring.
It is important to remember that these transcripts are generated through computer speech recognition, so are imperfect transcriptions that do not properly recognize all words or names, especially rare or novel terms like “Covid-19,” so experimentation may be required to yield the best results.
The graphs above just barely scratch the surface of the kinds of questions that can now be explored through the new radio news ngrams, especially when coupled with television news and 152-language online news ngrams.
From transcribing 3 million radio broadcasts into ngrams to describing a decade of television news frame by frame, cataloging the objects and activities of half a billion online news images, to inventorying the tens of billions of entities and relationships in half a decade of online journalism, it is becoming increasingly possible to perform multimodal analysis at the scale of entire archives.
Researchers can ask questions that for the first time simultaneously look across audio, video, imagery and text to understand how ideas, narratives, beliefs and emotions diffuse across mediums and through the global news ecosystem. Helping to seed the future of such at-scale research, the Internet Archive and GDELT are collaborating with a growing number of media archives and researchers through the newly formed Media Data Research Consortium to better understand how critical public health messaging is meeting the challenges of our current global pandemic.
About Kalev Leetaru
For more than 25 years, GDELT’s creator, Dr. Kalev H. Leetaru, has been studying the web and building systems to interact with and understand the way it is reshaping our global society. One of Foreign Policy Magazine’s Top 100 Global Thinkers of 2013, his work has been featured in the presses of over 100 nations and fundamentally changed how we think about information at scale and how the “big data” revolution is changing our ability to understand our global collective consciousness.




















 When you visit a public library, you get to meet the librarians and others who build and care for those collections. You know there are people who empty the garbage cans, who put back the borrowed books, who maintain the computers, and who determine what ends up on the shelf.
When you visit a public library, you get to meet the librarians and others who build and care for those collections. You know there are people who empty the garbage cans, who put back the borrowed books, who maintain the computers, and who determine what ends up on the shelf. knowledge. Every person on the planet should have the opportunity to learn and to make a contribution.
knowledge. Every person on the planet should have the opportunity to learn and to make a contribution.

























{kind=link}
.jpg){kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}