Internet Archive’s Community Webs program is excited to announce that metadata for more than 4,800 archived websites and web collections created by 23 Community Webs member organizations are now available in Digital Public Library of America (DPLA). This marks the first of many metadata ingests that will come over the next months and years, as additional web and digital archives are created and described by members of the program. To access Community Webs web content in DPLA, click here.
The Community Webs program was launched in 2017, and currently provides web and digital archiving training, infrastructure, services, and professional community cultivation for more than 150 public libraries and cultural heritage organizations across the country and around the world. The participating organizations have shared goals of documenting local history and community archiving, especially documenting communities and populaces traditionally excluded from the historical record. These goals dovetail nicely with DPLA’s recently launched Digital Equity Project, which aims to provide support to libraries and archives as they shift toward greater inclusion of diverse stories and voices.
Community Webs collections now available in DPLA include:
The #Syllabus collection, created by the Schomburg Center for Research in Black Culture in New York City, which “aims to web archive Black-authored and Black-related educational resources to document Black studies, movements, and experiences in the twenty-first century.”
The D.C. Punk (Web) Archive, created by People’s Archive, DC Public Library, which documents the punk and hardcore music scenes in Washington, DC.
The Covid-19 in Hennepin County collection, created by Hennepin County Library, which documents the pandemic’s impact on Minneapolis, Minnesota and the surrounding areas, is one of a dozen web collections on local impacts of the Covid-19 pandemic which are now available in DPLA.
The Internet Archive has been a DPLA content provider since 2015, primarily contributing digital materials from our many print digitizing partnerships. However, this is the first time our partners’ web collections have appeared in the DPLA. We are excited for this opportunity to add community-focused born-digital and web collections from our program partners to the already unparalleled breadth of cultural heritage collections accessible via DPLA’s portal. We think these hyperlocal archived web resources will add additional depth and context to DPLA’s existing national collections. Meanwhile, the Community Webs collections’ inclusion in the portal will put these materials alongside other types of digital objects and in front of a broader audience of researchers, steps that are vital to dismantling the silos that often enclose web archives.
We are grateful to be partnering with DPLA to increase access to these vital community history collections and look forward to building more integrations and furthering this collaboration in the years to come. We would like to extend special thanks to the team at DPLA for all their work making this integration possible and to the 23 Community Webs member organizations who have both built and shared their local history web content for posterity.
This post is part of a series written by members of the Internet Archive’s Community Webs program. Community Webs advances the capacity for community-focused memory organizations to build web and digital archives documenting local histories and underrepresented voices. For more information, visit communitywebs.archive-it.org/
What is an archivist to do when items of public record, which have been systematically added to publicly accessible collections for over a century, suddenly turn from paper into bits and bytes that disappear from the web, or even get stuck behind paywalls? Like many in my profession, I’ve been grappling with this question for a while. Having no real training in digital archiving and facing this quandary as a lone arranger, it’s sometimes hard to keep that grappling from turning into low-key panicking that my inaction has been causing information to be lost forever.
Imagine my excitement, then, when I learned about the Community Webs program – access to and training for Archive-It, collaboration with the Internet Archive, and a network of others like me to bounce ideas off and get inspiration from? Yes please! With the blessing of my boss, I applied right away and my library joined the program in April 2021.
The outside of the Waltham Public Library. Photo by C. Sowa.
(This might be a good point for a quick introduction. I work as the archivist/local history librarian at the Waltham Public Library (WPL) in Waltham, Massachusetts. Waltham is a city about 10 miles west of Boston, and is home to an ethnically and economically diverse population of just over 62,000 people. The WPL is a fully-funded community hub, fostering a healthy democratic society by providing a wealth of current informational, educational, and recreational resources free of charge to all members of the community. The library is known throughout the area for its knowledgeable and friendly staff, welcoming and safe environment, accessibility, convenience, current technology, and helpful assistance.)
I eagerly dove into the program and used our first web-archive collection – Waltham Public Library – as a testing ground, a place to gain familiarity with both Archive-It and the whole process of web archiving. I’ve been trying to capture content that aligns with the material found in the library’s analog records – annual reports, policies, announcements, event flyers, records from our Friends group, etc. – by doing a weekly crawl of the library website, our Friends website, and the library’s Twitter feed. For the most part this collection has been thankfully pretty straightforward.
Our largest collection so far is COVID-19 in Waltham, which makes up a portion of the library’s very first born-digital archival collection. That collection began in April 2020, when the WPL (like most other places) was closed to help “flatten the curve.” A month or two prior, as the pandemic was building steam, I had become fascinated with the 1918 influenza. A poke through our archives for the topic had been disappointing, as there wasn’t too much beyond a couple of newspaper clippings, brief mentions in the library trustees’ minutes, and a few pages in the records of the local nurses’ association. I was hoping to put together a better picture of what it was like to live in Waltham during the flu, perhaps to give myself a glimpse of what I could expect in the coming weeks (heh… how naïve I was).
Scrapbook page showing newspaper clippings from the early days of the 1918 flu. Scrapbook is part of the records of the Waltham Public Library. Photo by D. Hamlin.
I put out a call via the library’s social media for those who lived, worked, and/or went to school in Waltham to share their stories, hoping to build the kind of collection I wanted and failed to find from 1918. There was an initial rush of Google Form submissions, a handful of photos, and one video, and then nothing. I was pleased we had received some materials, but still wanted to paint a broader picture of Waltham under Covid. Enter Community Webs! For the past several months I’ve been working to collect retroactively what I was hoping to capture at the time – news articles, videos, the city website, information from the schools, and so on. While it’s not as comprehensive as it might have been if I’d been able to gather it all as it happened, I’ve been able to save over 500 GB of data that will help those in the future to better imagine what it was like to live in Waltham during Covid.
Screenshot from a WPL Instagram post sharing a patron’s submission to our COVID-19 in Waltham collection.Screenshot examples of Covid-related content captured retroactively with Archive-It.
Finally, related to the quandary in the first paragraph of this post, our most complicated collection is the Waltham News Tribune. The WPL has microfilm copies of the paper going back to its earliest iteration in the 1860s, and part of my job has been to collect each issue and send yearly batches to a vendor for microfilming. However, as of this past May, the publisher has moved the paper entirely online, with some content requiring a paid subscription to view. The WPL has a subscription so that we can continue to provide free access to our patrons, but what happens to our archive of back issues? Does it just stop abruptly in May 2022, even as time and local news continue to march on? As it is, our microfilm is heavily used, especially since the paper’s offices burned down in 1999, making ours the only existing archive.
Drawers full of microfilmed newspapers at the WPL. Photo by D. Hamlin.
Thanks to web archiving, we’re able to continue to fulfill our unofficial role as the repository for the city newspaper, at least in theory. In practice, I look at the daily crawls of the digital edition of the paper and can’t help but see that it is no longer the type of local news we’ve been archiving for over a century. The corporate publisher of the paper has consolidated ours with those from several other local cities and towns, and has sacrificed true local news coverage for more generic topics, many of which aren’t even related specifically to Massachusetts. This is a problem that sits well outside of my archives wheelhouse, but at least I feel I can do my due diligence by capturing what local news does trickle through.
I’ve had a slower go of web archiving than I’d like so far, thanks to several months of parental leave in 2021 and a very packed part-time work schedule. Nevertheless, I’ve been chipping away at our collections and planning for more, with an eye to add more diverse voices than those that make up much of our analog collections. I’m grateful for the encouragement and help I’ve received from Community Webs staff and peers, and want to give a special shout-out to the Archive-It folks who hold office hours to assist us with technical issues! This really is a fantastic program, and I’m so glad my library is part of it.
On June 21st, the Community Webs program team hosted its 2022 US Symposium at the National Museum of the American Indian in Washington, DC. For this day-long meeting, we welcomed over 30 librarians and archivists from across the country for presentations, discussion, networking, and some much-needed catch up following two years of entirely virtual events.
National Museum of the American Indian, Washington, DC
Community Webs is a community history web and digital archiving program operated by the Internet Archive. The program seeks to advance the capacity for community-focused memory organizations to build web and digital archives documenting local histories, with a particular focus on communities that have been underrepresented in the historic record. Community Webs provides its members with web and digital archiving tools, as well as training, technical support and access to a network of organizations doing similar work. The Community Webs program, including this event, is generously funded with support from the Institute of Museum and Library Services (IMLS) and the Mellon Foundation.
Jefferson Bailey, Director of Archiving & Data Services at the Internet Archive, describes the concepts that have underpinned the development of Community Webs since its inception
The day began with opening remarks and program updates from Internet Archive staff, including an overview of Community Webs and the significant growth the program has experienced since its launch in 2017. Staff provided a glimpse at what lies ahead both for Community Webs and the Internet Archive’s Archiving and Data Services team. This included plans to incorporate digitization, digital preservation and other forms of digital collecting into Community Webs, as well as projects and services either newly released or in development at IA.
Dr. Doretha Williams, Director of the Robert F. Smith Center for the Digitization and Curation of African American History at the National Museum of African American History and Culture
The first keynote speaker of the day was Dr. Doretha Williams, Director of the Robert F. Smith Center for the Digitization and Curation of African American History at the National Museum of African American History and Culture. Dr. Williams detailed her organization’s commitment to serving its communities via the Center’s Community Curation Program, Internships and Fellowships Program, Family History Center, and Great Migration Home Movie Project. Throughout her presentation, Dr. Williams stressed the importance of community input and partnerships to achieving the Center’s mission, echoing one of the central tenets of the Community Webs program.
National Gallery of Art Executive Librarian Roger Lawson discusses his organization’s involvement with the Collaborative ART Archive (CARTA)
Following this presentation, three speakers shared their experiences working on collaborative web archiving initiatives. Lori Donovan, Senior Program Manager for Community Programs at the Internet Archive, began with an overview of various collaborative web archiving initiatives the Internet Archive and its partners have participated in, including the Collaborative ART Archive (CARTA), a web archiving initiative aimed at capturing web-based art materials utilizing a collective approach. Roger Lawson, Executive Librarian at the National Gallery of Art, shared his institution’s perspective as a member of CARTA. Finally, Christie Moffatt, Digital Manuscripts Program Manager at the National Library of Medicine, described working with colleagues both across her organization and externally to capture health-related web content at a national scale. Each of these presentations emphasized the advantages in scale, resources, staffing and knowledge-sharing that can be achieved by pursuing web archiving via collaborative entities.
Our afternoon session kicked off with a second keynote presentation from Leslie Johnston, Director of Digital Preservation at the National Archives and Records Administration (NARA). Johnston detailed the challenges NARA faces while contending with digital preservation across the enterprise. These challenges include the heterogeneity of digital outputs and technologies, the complexity of digital objects and environments, the scale of the archivable digital universe, and the difficulties in ensuring equitable access. As an antidote to these challenges, Johnston recommends archivists provide guidance to content creators, take a risk-based approach, prioritize basic levels of control, maintain scalable and flexible infrastructure, and engage in collaborations and partnerships. She also advocated for a people- rather than technology-centric approach to digital preservation, again mirroring the ethos of the Community Webs program.
Leslie Johnston, Director of Digital Preservation at NARA, outlines the challenges her institution is facing while contending with digital preservation
For our final speaker session of the afternoon, we welcomed Community Webs members up to the lectern to share their web archiving and digital goals and achievements. Librarian, archivist, Phd student, and creative polymath kYmberly Keeton discussed her work as founder of Art | Library Deco, an online archive of African American art. Keeton described working closely with the artists featured in the archive, reiterating the theme of collaboration espoused by other speakers at the event. Tricia Dean, Tech Services Manager at Wilmington Public Library (Illinois), argued for the importance of capturing the histories of small and rural communities through initiatives like Community Webs. Liz Paulus, Adult Services Librarian at Cedar Mill & Bethany Community Libraries described her efforts to capture the online Cedar Mill News via web archiving, stressing how one successful project can play a significant role when advocating for future resources. Longtime Community Webs member Dylan Gaffney, Information Services Associate for Local History & Special Collections at Forbes Library, described his library’s participation in States of Incarceration, a traveling exhibition on mass incarceration, the Historic Northampton Enslaved People Project, and other initiatives. Gaffney credited Community Webs with paving the way for an equity-focused approach to digital projects such as these. Finally, Dana Hamlin, Archivist at Waltham Public Library showcased her organization’s web archiving efforts, highlighting the library’s COVID-19 collections and their attempts to capture the online local newspaper, the Waltham News Tribune.
Throughout the day, attendees had opportunities to discuss digital initiatives at their organizations, to catch up informally after a long hiatus, and to browse the exhibitions on display at the National Museum of the American Indian. We’re so grateful to all of our Community Webs members who were able to attend the event and especially to those who shared their knowledge. Our next Community Webs Symposium will be held in Chattanooga this September 13 to coincide with the Association for Rural and Small Libraries Conference. We are looking forward to seeing more program members there!
Guest Post by: Tricia Dean, Tech Services Manager at Wilmington Public Library District (IL)
This post is part of a series written by members of the Community Webs program. Community Webs advances the capacity for community-focused memory organizations to build web and digital archives documenting local histories and underrepresented voices. For more information, visit communitywebs.archive-it.org/
Wilmington Public Library. Photo: T. Dean 4/21/22
I was excited when I saw the call for participants in Community Webs. While Wilmington, Illinois is a small, rural town (5,664 people), the thought was that we still had something to contribute. Most Archive-It partners are universities, museums and large libraries, and being in their company was a little daunting to me initially. Other institutions have someone who opens the project, and then it develops into a larger team project. Wilmington Public Library District (WPLD) has a much smaller staff; the project has been wholly mine, which has been both thrilling and terrifying.
Wilmington is a small rural town, falling on the lower end of the economic scale. Because we are isolated,the library plays a vital part in the community. We offer the usual storytimes and adult programs, but also loan out hotspots and ChromeBooks. We have 45 hotspots and these are almost always checked out; some people are using them for vacations, but by usage it is apparent that others are using them as their primary means of connecting to the Internet. Internet access has been more and more important, but after the Covid-19 broke out, more governmental services went strictly online, making access even more critical – and to many who had not been regular patrons. WPLD is a hub for the community, offering computers, information, tax forms, and a place to come in and chat – even more important when we are trying to stay close and limit outside contact.
Main Street in Wilmington, circa 1900
I am a Chicago native who went to Champaign-Urbana for grad school. I was a scanner for the Internet Archive for several years where I was privileged to handle some incunabula (pre-1500 items). I am the Technical Services Supervisor at Wilmington; primarily I catalog our materials, but I also tend toward Projects, from adding series labels to re-orienting all the calls in the juvenile non-fiction section. I am currently going through our attic to help determine what we have (it’s a Mystery!). I’m making lists, and hoping to have items to scan which would be available online, in multiple places. I applied for the Community Webs program (with my director’s blessing) because I felt that it’s important for small towns to be represented in the collection of history. Only 20% of the population still lives outside major metro areas, but it is every bit as important to capture that life as it is to retain the history of large cities.
Wilmington Library joined Community Webs in the summer of 2021. After some technical clarifications with the Archive-It staff WLPD was set up. In considering what made Wilmington unique, the first link was to our library and social media pages. Social media has grown in importance in the last twenty years, but it became a vital link during Covid when services were otherwise unavailable. Wilmington Library YouTube videos, how-tos, crafts and storytime, stand to remind us of how we responded and as a continuing reference for parents who can’t get to the library. But since social media, specifically, is known for ‘right now,’ it lacks the kind of reflection over time that we can create through the Community Webs project.
We may be small, but we have a number of historical articles and sites which needed to be brought together. We want to reflect events that have been impactful to our community, from the explosion of the Joliet Armory in the 1940s to the continuing issues with the Wilmington Dam, which has proved dangerous, but has complicated ownership issues. I still have a long way to go; the projects (attic/local history/web archive) are all intertwined. Wilmington has the usual Community Resources and City Government collections in Archive-It. Going forward, we want to continue to develop our Wilmington History collection. We are working on local history and will establish a collection of materials from our attic and public donations. Our local paper has vertical files which could be a goldmine of information – again, on my to-do list. We will be kicking off an Oral History Project, which will begin with a series of simple gatherings/coffee hours for our seniors, providing a place for them to gather, and a space to share their stories. I am hoping these will be in our Community Webs archive. Who better to speak to where we’ve been and where we are than some of our oldest residents?
Wilmington Dam (present). Photo: T. Dean 4/21/22[Photo by John Irvine – Chicago Tribune – August 29, 1992]. Shallow appearing dam is still quite hazardous, partially because it doesn’t ‘look’ dangerous – photo long before warning signs went up.
Why is Community Webs important? Because it will help to remember when we cannot keep up with the information overload. Because there is so much happening that we miss a good deal of what is around us – or can’t bear to face it for long. Because so very very much of our lives are now online – and can be erased with a keystroke. Because we are seeing, painfully, that those who do not learn from the past will be/are condemned to re-live it. And, for Wilmington, I think it is important because so many of the voices and sites being captured are from museums, universities and large public libraries. It is important that we remember that we used to be far less urban than we are today. It is important to remember the smaller places, those who are too easily lost in the maelstrom of modern life, because to be forgotten is to be erased.
This post is part of a series written by members of Internet Archive’s Community Webs program. Community Webs advances the capacity for community-focused memory organizations to build web and digital archives documenting local histories and underrepresented voices. For more information, visit communitywebs.archive-it.org/
Can you describe your community and the services and role of your organization within the community?
Inuit Circumpolar Council (ICC) Alaska works on behalf of the Inupiat of the North Slope, Northwest and Bering Straits Regions; St. Lawrence Island Yupik; and the Central Yup’ik and Cup’ik of the Yukon-Kuskokwim Region in Southwest Alaska. ICC Alaska is a national member of ICC International. Since inception in 1977, ICC has gained consultative status II with the United Nations, and is a Permanent Participant of the Arctic Council.
For example, ICC has provisional status with the International Maritime Organization (IMO), is an active member at the Arctic Council senior level and within the working groups and is a prominent voice at the UN Framework Convention on Climate Change (UNFCCC). Work and engagement occur in many ways at these different Fora. Within the UNFCCC, ICC has taken a leadership role in putting forward Indigenous Knowledge and establishing a platform for providing equitable space for multiple knowledge systems. Additionally, at the UNFCCC COP 26, ICC Chair, Dr. Dalee Sambo Dorough, led an ICC delegation made up of Inuitrepresentatives from across the Arctic.
An immense amount of work occurs in direct partnership with Inuit communities to inform work at international fora. For example, ICC is facilitating the development of international protocols for Equitable and Ethical Engagement. These protocols will provide a pathway to success for all that want to work within Inuit homelands and whose work impacts the Arctic. The protocols will aid in a paradigm shift in how work, decisions, and policies are currently created and carried out. The paradigm shift will lead toward greater equity and recognition of Inuit sovereignty and Self-determination.
Why was your organization interested in participating in Community Webs?
The Community Webs program was attractive to ICC because it provided the training and the storage to effectively preserve ICC’s digitized & born-digital archival materials. We were pleased to see this offering as a solution for an ongoing desire to archive the prolific organization’s digital materials & products. This work dovetails nicely with ICC Alaska’s efforts to digitize 47 boxes, or around 80 linear feet of material that span 6 decades, including audio, film, photographic media, and paper documents.
ICC Jam – part 2 – Greenland
Cultural programming as part of the 1983 General Assembly. In this clip, view performances from Greenland’s Tuktak Theater and a Greenlandic choir
ICC advocates for Inuit and Inuit way of life, highlighted by ICC’s General Assembly meetings. The ICC receives its mandate from a General Assembly held every four years. The General Assembly is the heart of the organization, providing an opportunity for sharing information, discussing common concerns, debating issues, and strengthening the unity between all Inuit across our homelands. Through the Community Webs project, ICC Alaska has been able to preserve archival video of the ICC General Assemblies going back 30 years using Archive-It and the Internet Archive, as well as all newsletters, press releases, resolutions, social media campaigns, and reports published on its website. These are a significant record of ICC advocacy, but more importantly, Inuit political and cultural heritage.
Why do you think it is important for public libraries, community archives, and other local and community-based organizations to do this work?
Community-based organizations are uniquely positioned as both a part of and apart from the community. This vantage point allows for the self-reflection and observation needed for web archiving, as well as the relationships within the community to create the space and dialogue needed for community archiving projects. By building more capacity within community-based organizations for web archiving and digital preservation efforts, we can expand the recorded historical narrative and humanities-based inquiries in a multitude of directions, to truly reflect the diversity of our world & time.
Where do you hope to see your web archiving program going?
The core goal of this work is to make ICC documents and its historical narrative more accessible and discoverable within ICC, to ICC’s member organizations, international bodies, and researchers, our aspirations are much bigger. Our hope is that this web archive goes beyond the core goal to inspire, delight, hearten, inform, and add depth to the conversations Inuit are having about cultural identity, relationship to the land, hunting, advocacy, self-determination, and self-governance.
We are curious about the intangible outcomes: What new work does the archive inspire? How does the archive add depth & historical weight to existing projects, discussions, and advocacy? What stories and knowledge gets re-remembered, or re-investigated after viewing archival materials? What advocacy, ethics, and philosophical works come from Inuit leaders informed by the legacy that the archive shared? Are youth leaders interested in adding to the archive?
Is there anything you would like your organization to contribute back to the broader community of web archiving and/or local history in the form of documentation, workflows, policy drafts or other resources?
We have several aspirations. Firstly, it is the telling of Inuit stories. The archive is another manifestation of that mission – to record and share Inuit voices across time. To increase access to those voices, information, knowledge, and history. The ICC Archival holdings are a historically unique & culturally significant telling of Inuit cultural heritage, history (including political history), educational pedagogy, philosophy, self-determination, values, ethics, environmental stewardship, and Indigenous Knowledge. It is important to create a way for Inuit to discover and interact with this work. Community Webs has offered a new tool in our toolkit.
Secondly, the goal is to move forward conversations about categorization and information management for indigenous communities. What does that look like in best practice? Can we, together with other Inuit archives, improve on existing practices to create a more equitable and ethical engagement with Inuit-produced information, the management of that information, and the discovery and access of that information.
What are you most excited to learn through your participation in Community Webs?
It was exciting to discover that many Inuit and Alaska Native resources that have already been preserved using the Internet Archive. These resources are often affected by insufficient financial support. Being able to have a preserved and accessible copy of these resources is an important step towards creating the bigger picture of the historical record of Inuit advocacy. As part of the Community Webs meetings, it was exciting to hear from other tribal librarians and community archivists across the country & world. Additionally, it was exciting to hear from speakers whose work informs our community archival work at ICC Alaska – such as Chaitra Powell who created (among other amazing things) the “Archive in a Backpack” project.
What impact do you think web archiving could have within your community?
Hopefully this work inspires other organizations to also preserve their digital assets, creating a richer narrative of Inuit political and cultural heritage.
What do you foresee as some of the challenges you may face?
We are eager to preserve our social media channels that have replaced the DRUM newsletter as a vehicle for keeping our community up-to-date on ICC’s work. Ongoing challenges with Facebook and Instagram archiving are preventing us from doing that. Hopefully these issues are resolved in the favor of the communities who created the content and bring their community and connections to these software platforms.
The COVID-19 pandemic has been life-changing for people around the globe. As efforts to slow the progress of the virus unfolded in early 2020, librarians, archivists and others with interest in preserving cultural heritage began considering ways to document the personal, societal, and systemic impacts of the global pandemic. These collections included preserving physical, digital and web-based information and artifacts for posterity and future research use.
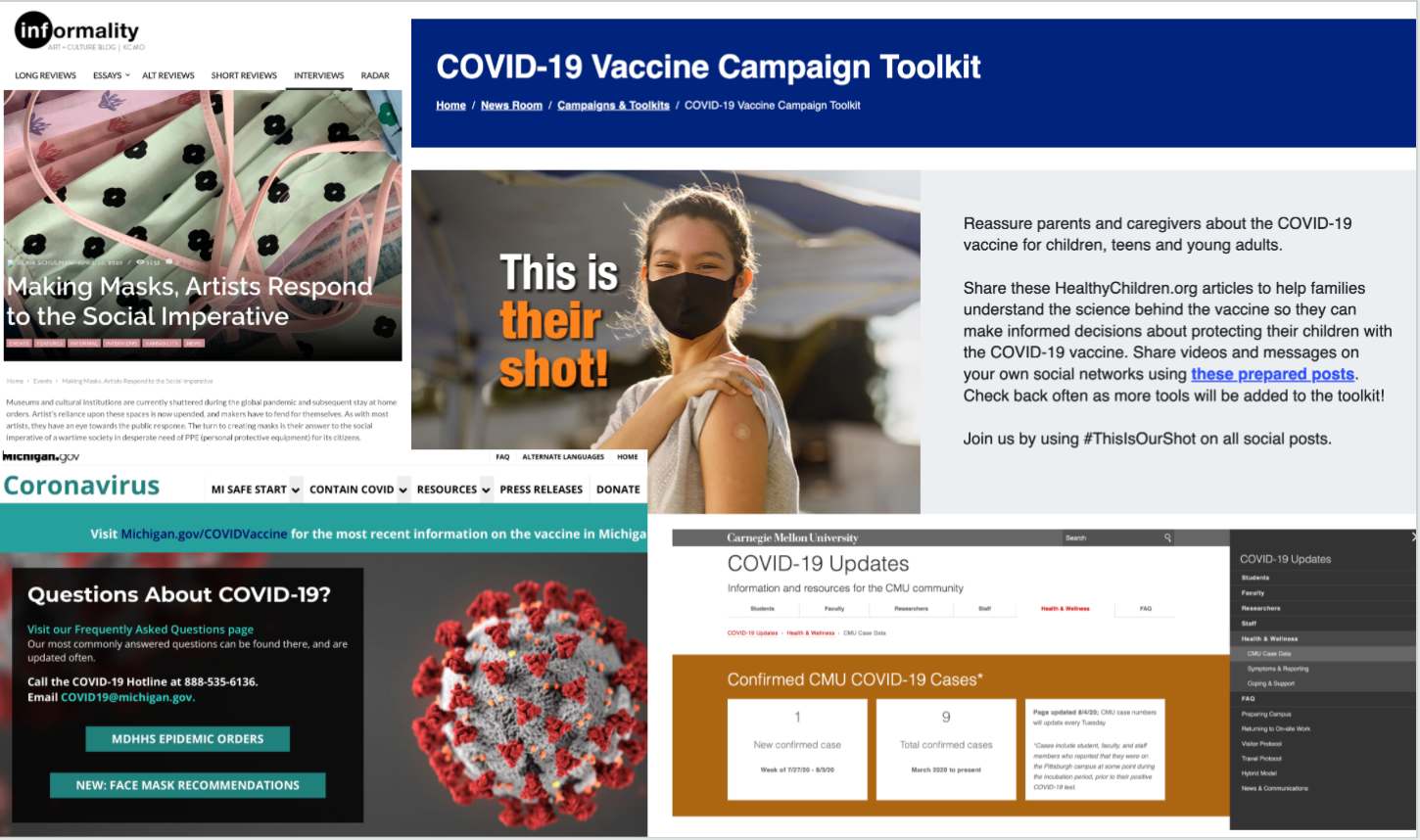
Clockwise from top left: blog post about local artists making masks from Kansas City Public Library’s “COVID-19 Outbreak” collection; youth vaccination campaign website from American Academy of Pediatrics’ “AAP COVID” collection, COVID-19 case dashboard from Carnegie Mellon University’s “COVID-19” collection and COVID-19 FAQs from Library of Michigan’s “COVID-19 in Michigan” collection.
In response, the Internet Archive’s Archive-It service launched a COVID-19 Web Archiving Special Campaign starting in April 2020 to allow existing Archive-It partners to increase their web archiving capacity or new partners to join to collect COVID-19 related content. In all, more than 100 organizations took advantage of the COVID-19 Web Archiving Special Campaign and more than 200 Archive-It partner organizations built more than 300 new collections specifically about the global pandemic and its effects on their regions, institutions, and local communities. From colleges, universities, and governments documenting their own responses to community-driven initiatives like Sonoma County Library’s Sonoma Responds Community Memory Archive, a variety of information has been preserved and made available. These collections are critical historical records in and of themselves, and when taken in aggregate will allow researchers a comprehensive view into life during the pandemic.
Sonoma County Library’s Sonoma Responds: A Community Memory Archive encouraged community members to contribute content documenting their lives during the COVID-19 pandemic.
We have been exploring with partners ways to provide unified access to hundreds of individual COVID-related web collections created by Archive-It users. When the Institute of Museum and Library Services launched the American Rescue Plan grant program, that was part of the broader American Rescue Plan, a $1.9 trillion stimulus package signed into law on March 11, we applied and were awarded funding to build a COVID-19 Web Archive access portal – a dedicated search and discovery access platform for COVID-19 web collections from hundreds of institutions. The COVID-19 Web Archive will allow for browsing and full text search across diverse institutional collections and enable other access methods, including making datasets and code notebooks available for data analysis of the aggregate collections by scholars. This work will support scholars, public health officials, and the general public in fully understanding the scope and magnitude of our historical moment now and into the future. The COVID-19 Web Archive is unique in that it will provide a unified discovery mechanism to hundreds of aggregated web archive collections built by a diverse group of over 200 libraries from over 40 US states and several other nations, from large research libraries to small public libraries to government agencies. If you would like your Archive-It collection or a portion of it included in the COVID-19 Web Archive, please fill out this interest form by Friday, April 29, 2022. If you are an institution in the United States that has COVID-related web archives collected outside of Archive-It or Internet Archive services that you are interested in having included in the COVID-19 Web Archive, please contact covidwebarchive@archive.org.
To celebrate National Library Week 2022, we are taking readers behind the scenes to Meet the Librarians who work at the Internet Archive and in associated programs.
In the spring of 2021, Catherine Falls was hired by the Internet Archive to launch the Community Webs program in Canada. She was excited about the prospect of helping public libraries, museums, local historical societies and archives digitally preserve important material.
Catherine Falls
“Most web archiving happens at really large institutions, so much of the experience of local communities is missing from the historic record. It’s giving us a biased view of contemporary society,” Falls said. “The more of these local organizations that we can get to do this archiving, the more the historic record will be brought into balance.”
Since her efforts began, the Internet Archive has partnered with 43 institutions and organizations in Canada to build community-based collections. Falls said it’s been rewarding to follow the growth and variety of web-archiving projects . For example, the Milton Public Library in Ontario is working with the Halton Black History Awareness Society and other organizations to document items that may not otherwise be captured on the web. Meanwhile, the ArQuives: Canada’s LGBTQ2+ Archives is working with its community members to build web archive collections that capture the community’s web presence.
Falls earned bachelor’s degrees in commerce and art history from the University of British Columbia. She also has a master’s degree in library science and a master’s degree in art history from the University of Toronto. Before coming to the Internet Archive, she worked as an archivist in Canada at several institutions including York University and the Archives of Ontario.
“I’m interested in the free circulation of ideas and the library as a place where public knowledge is accessible.”
Catherine Falls, Community Webs
“I was drawn to libraries as a kind of place that facilitates research–which for me is the most exciting phase of any project,” Falls said. “I’m interested in the free circulation of ideas and the library as a place where public knowledge is accessible. I like how the intellectual possibilities of a library intersect with the library as a community space.”
Catherine Falls
Falls says her background gives her a solid understanding of the basic functions of the library and the common language used within the profession. With that theoretical grounding, she said she can approach her work from a critical perspective to make improvements.
“It’s important to keep in mind that libraries are not infallible institutions. We need to be constantly questioning our practice and finding ways to be better,” Falls said. “It’s easy to say libraries are these beautiful, idyllic institutions. But I think it’s healthy to take a critical eye toward the work we do so that we can try to live up to our ideals in terms of whose stories we tell, who has access to our services, and what is preserved for the long term.”
Falls said she enjoys the mission-driven focus of the Internet Archive. Operating in the library, technology and archival world, it has a dynamic, nimble culture that provides fertile ground in which to explore new ideas, she said.
In celebration of National Library Week, we’d like to introduce you to some of the professional librarians who work at the Internet Archive and in projects closely associated with our programs. Over the next two weeks, you’ll hear from librarians and other information professionals who are using their education and training in library science and related fields to support the Internet Archive’s patrons.
What draws librarians to work at the Internet Archive? From patron services to collection management to web archiving, the answers are as varied as the departments in which these professionals work. But a common theme emerges from the profiles—that of professionals wanting to use their skills and knowledge in support of the Internet Archive’s mission: “Universal Access to All Knowledge.”
We hope that over these next two weeks you’ll learn something about the librarians working behind the scenes at the Internet Archive, and you’ll come to appreciate the training and dedication that influence their daily work. We’re pleased to help you “Meet the Librarians” during this National Library Week and beyond:
Jessamyn West, accessibility – Vermont Mutual Aid Society
Guest post by: Olivia Radbill, Adult Services/Local History Librarian, South Pasadena Public Library
This post is part of a series written by members of Internet Archive’s Community Webs program. Community Webs advances the capacity for community-focused memory organizations to build web and digital archives documenting local histories and underrepresented voices. For more information, visit communitywebs.archive-it.org/
The South Pasadena Public Library (SPPL) is a single branch library system located in the small city of South Pasadena, California, just fifteen minutes from downtown Los Angeles. SPPL serves a population of approximately 25,000 residents, many of whom are very dedicated to preservation and local history. As the Adult Services/Local History Librarian at SPPL, I regularly interact with local organizations, City staff, City commissioners, and residents in search of the many little-known details of South Pasadena’s history. My role not only entails organizing, processing, and making accessible local history, but also archiving current events that will inevitably be the subject of future research.
Screenshot of “Summers in SoPas: Highlights of Summers Past” online exhibit.
While this series did quell some of the community desire to interact with the Local History Collection, it did not address the needs of the community in regards to born-digital content. The COVID-19 pandemic highlighted certain gaps in our collection. One of the most notable gaps was the lack of any born-digital or web-archived content. Previously, SPPL has relied primarily on physical donations and physical City documentation. However, once these objects became inaccessible to both Library staff and patrons during our initial COVID-19 closure in March 2020, we sought means of preserving documentation that has increasingly moved to exclusively web-based platforms. For example, in April 2020 the City of South Pasadena launched “City Hall Scoop”, an online blog intended to provide quick, reliable news updates to local residents. It became imperative for Library staff to actively seek out and ensure preservation of this kind of content.
The South Pasadena Public Library homepage on Archive-It.
At the onset of our involvement in the Community Webs program, I strove to ensure that the objective of our internet archiving was specific, consistent, and attainable. After careful consideration, the following categories were determined to be priorities to the SPPL Local History Collection: City Government, Local Newspapers, and Nonprofit Organizations. Based on these categories we have identified many relevant websites, but chose to focus primarily on official websites and social media pages, to add to the Archive-It platform. The Community Webs project has been an invaluable resource for addressing the needs of both the SPPL staff and the community. Online trainings have aided significantly in overcoming learning curves, helped us determine the scope of our archiving project, and have allowed SPPL to create a system in which web-based content is an integral part of our Local History Collection. SPPL, as of March 2022, has archived, either singularly or on a recurring basis, eleven websites. We are hoping to archive 22 new sites by the end of the year, doubling the number we reached last year.
Earlier this summer, the Internet Archive announced its partnership with the New York Art Resources Consortium (NYARC) to form a collaborative, web-based art resources preservation and access initiative. We are now thrilled to announce that the initiative has kicked off with a diverse roster of 24 participating member institutions throughout the United States and Canada.
The Collaborative ART Archive (CARTA)projecthas a mission to collect, preserve, and provide access to vital arts content from the web by supporting a vibrant, growing collaboration of art and museum libraries. With funding from federal agencies and foundations, the Internet Archive is able to expand CARTA to a diverse set of museums and art libraries worldwide and to broaden the ways the resulting collections can be discovered and used both by scholar and patrons.
The arts institutions actively participating in this program so far include:
American Craft Council
American Folk Art Museum
ART | library deco
Art Gallery of Ontario
Art Institute of Chicago
Fashion Institute of Technology
Getty Research Institute (Getty Library)
Harvard University – Fine Arts Library
Harvard University – Graduate School of Design
Indianapolis Museum of Art at Newfields
Leonardo/ISAST
Maryland Institute College of Art
Museum of Contemporary Art of Georgia
National Gallery of Art Library
National Gallery of Canada
New York Art Resources Consortium
Philadelphia Museum of Art
San Francisco Museum of Modern Art
Sterling and Francine Clark Art Institute Library
The Corning Museum of Glass
The Menil Collection
The Metropolitan Museum of Art
The Nelson-Atkins Museum of Art, Spencer Reference Library
University of Hawaii at Manoa, Hamilton Library
Membership in the program includes national and regional art and museum libraries throughout the United States and Canada committed to the preservation of 21st century art historical resources on the web. One of our early supporters and current CARTA member Amelia Nelson, Director of Library and Archives at The Nelson-Atkins Museum of Art, noted the increased risk of losing art history on the web in comparison to earlier generations of artists: “Websites are the letters, exhibition postcards, exhibition reviews and newspaper articles of today’s artists and artistic communities, but they aren’t resources that scholars can find in archives like the physical materials that document the careers of earlier generations of artists. I worry that as we lose these sites, we are also losing the potential for scholars to place this moment in the canon of art history and culture broadly. This initiative will build a collaborative and sustainable way for art libraries to pool their limited resources, with the technical, administrative, and organizational expertise of the Internet Archive, to ensure that this content is available for future generations.”
The initial group of member institutions have identified an initial set of more than 150 valuable and at-risk websites, articles, and other materials on five primary collection topics: Local Arts Organizations; Artists Websites; Art Galleries; Auction Houses (Catalogs/Price Lists); and Art Criticism. These collections will continue to grow and evolve over the course of the project, capturing thousands of websites and many terabytes of data.
Untitled Art website, nominated by NYARC for inclusion in the CARTA Art Fairs and Events collection.
We’re actively seeking more US-based arts institutions to participate in the project as we continue to grow our collections of web-based art history resources. Collaborative members attend meetings every two months to coordinate curation and other group activities as well as participate in subcommittees focused on collection development, metadata, end-user/researcher engagement, and outreach. If you are involved with an art and/or museum library interested in joining this collaborative project, please complete this form.