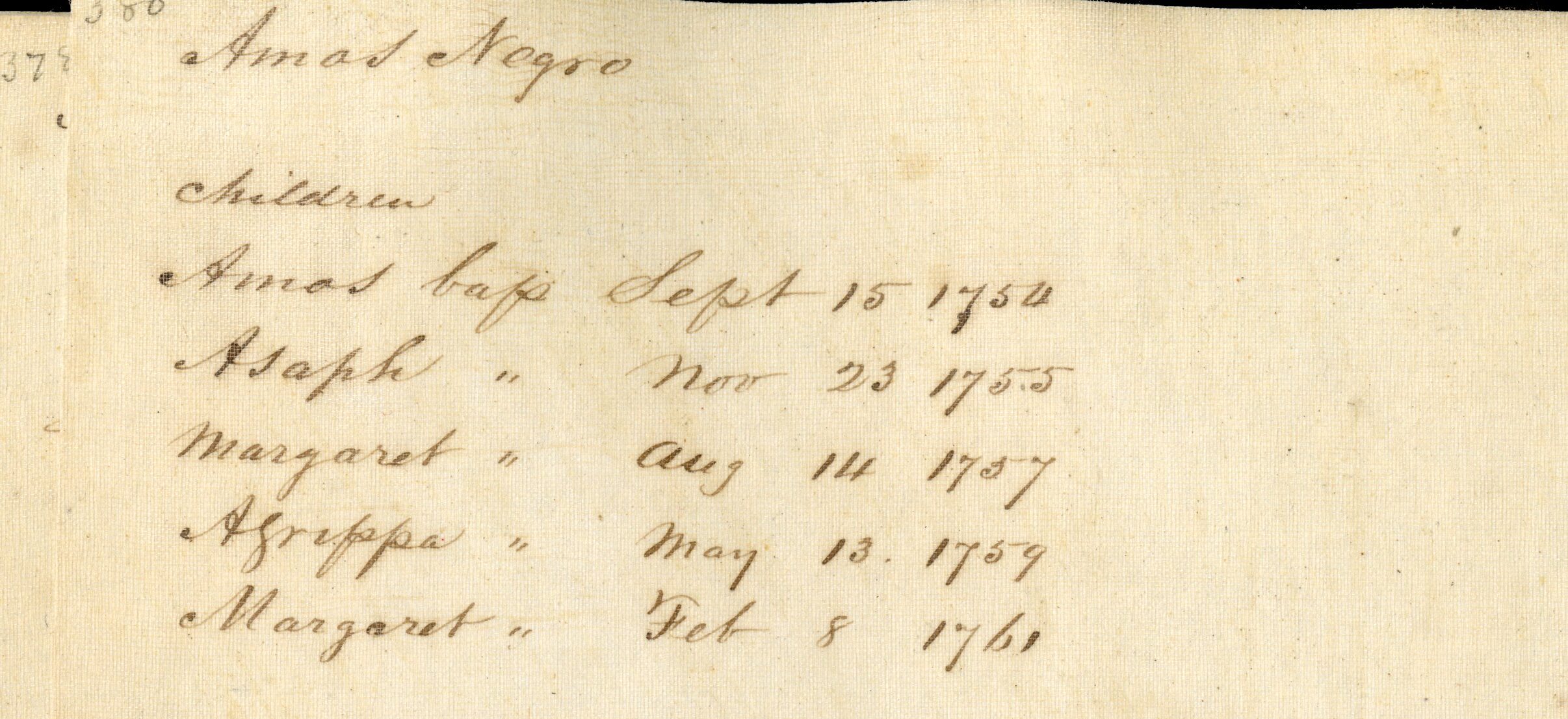If you’ve ever taken a tour of the Internet Archive headquarters with Brewster Kahle, you’ve likely watched him play a minute or two of the game “Prince of Persia” on our in-browser emulator. While talking through the technology involved, Brewster will press the keys to make the main character run through the dungeons of a kingdom, often dying rather quickly.
Over the years, the area around the “Prince of Persia” station has added additional decorations, including a print drawn by the creator of Prince of Persia, Jordan Mechner. Entitled A Faithful Friend, the print depicts a moment in the Prince of Persia Game where a small mouse visits the captive princess.
Worlds collided recently when Jordan Mechner, in town for the Game Developers Conference 2024 and doing some readings of his new graphic novel memoir Replay, stopped by the Internet Archive for a tour and discussion with Brewster.
This provided a unique opportunity for the creator of a game that Brewster had been playing for years to give him tips to learn how to do a better running jump and get farther along than he had in his many demonstrations on the tour. It can be reported that Brewster was a fast learner and took Jordan’s suggestions to heart.
Jordan was also kind enough to gift a signed copy of Replay to the Internet Archive.
Conversation turned to the Internet Archive’s help in Jordan’s work creating Replay, including images and research for the historical parts of the novel.
During the conversation, Jordan had this to say:
“I appreciate [The Internet Archive] as a graphic novelist and as a game developer. Everything I’ve done throughout my life has been based on inspiration that I get from other things and on research that I’m able to do. When I went online to write and draw this 320-page book about game development and about my life and my family’s history, I looked for visual references of everything from old postcards and photographs to video game consoles.”
“I wanted to draw the floppy disk caddies and 1970s movie posters I had in my office in Brøderbund when I was making the first Prince of Persia on the Apple II. And where could I find a 1983 April issue of Softalk magazine, which is how I learned 6502 assembly language programming? So many times, when I searched online, it was the Internet Archive that came through.”
Brewster agreed:
“Well, I’m glad we’ve been useful to you, but also thank you for going and being a model for taking something that’s very, very popular in the past and making sure that it makes it to a generation that is going to download it from GitHub and play with it and mod it and do something else with it. And you’re welcoming of that next generation, living and growing with your work.”
And Jordan couldn’t have been clearer:
“And I will say that I don’t feel harmed by that. A few years ago somebody took the time to port Prince of Persia to the Commodore 64, which the publisher had no interest in doing in 1989, because the Commodore 64 was already outdated as a platform. Even the Apple II was on its way out. But somebody has done it now just out of love, out of its challenge, and the fact that the source code was available made that easier, I hope.
“Making things available to this generation. They’re going to do weird different things with it, especially if it’s not a permission-based society. But that’s what creativity has always been based on.“
Jordan acknowledged: “Copyright law exists and was created to protect the incentive of creators to work really hard at making something. So that if someone makes something great against all odds and it gets out there and sells a lot of copies, they can make money from it. But at a certain point, things that have been created need to then be used by other people to make their versions of it. The games and movies that we love, operas, films made of the works of Shakespeare, are building on creations of the past.”
There was one last reunion in the visit: Years ago, the Archive was donated a travel case (for trade shows) used by Jordan’s game publisher, Brøderbund Software. It currently lives in one of the Internet Archive’s guest rooms, and Jordan got a quick selfie with a piece of his own history.
As an editorial strategist and tech journalist, JD Shadel spends a lot of time thinking about how the content on the internet continues to rapidly evolve. One telling example they’ve followed closely is the evolution of GIFs. Two decades ago, the web was filled with millions of jittery, pixelated, handmade GIFs wherever you looked. And for many of us, there’s a nostalgia for the early days of the web when things felt a bit wilder and untamed.
That nostalgia for the version of the internet they grew up with is what first sparked Shadel’s interest in collecting old-school GIFs. During the first months of pandemic lockdowns in 2020, Shadel started spending a lot of their extra spare time diving deep into the Internet Archive’s GifCities collection. Shadel’s personal fascination began with under construction GIFs, a rich niche in the GifCities collection full of animated construction workers and tools. Then came seeking out GIFs of Furbies, Tamagotchi, and other cultural touchstones that the 33-year-old came of age with online. Over the next few years, downloading and organizing GIFs became a hobby for Shadel.
Recently, it came time to update Shadel’s professional website. “It’s one of those evergreen chores it’s easy to obsess over as a freelancer, when your website is your calling card for new work,” said Shadel, who found themself digging back through the hundreds of GIFs they’ve curated thanks to the Internet Archive.
Early cyberspace-themed GIFs became the theme for their new and somewhat unconventional portfolio, which features more than two dozen images sourced entirely from GifCities. Users can, for example, click on a spinning globe for an introduction or a British Furby to learn about Shadel’s background as an American now based in London—including editorial work for outlets such as Vice, The Washington Post, and Conde Nast Traveler and consulting for clients including Airbnb and Adidas.
“I’m so happy GifCities exists to capture that specific snapshot of the internet,” Shadel said. “It really relates, metaphorically, to a lot of my work where the real world and the internet blur, where the digital and the physical intersect.”
In addition to GifCities, the Wayback Machine has also been useful to Shadel. Professionally, it is a resource when reporting and fact checking stories. Personally, they recently found material from a band they played in years ago.
“The Internet Archive just touches my digital life in so many different ways,” Shadel said. “As a journalist, it’s a fact-checking tool. Having the ephemeral internet preserved for future researchers, writers, reporters and editors is a huge service to democracy. And it’s also just fun.”
On the website with its Space Jam-like navigation, Shadel wanted to reference the history of the internet — and maybe even inspire visitors to think more actively about their own role in charting the future. “I think we can reclaim our digital lives and rekindle the notion of ourselves as ‘netizens’—citizens of the internet and not just passive participants,” Shadel said.
“That’s why the work of the Internet Archive is so important,” they continued. “Despite the fact that we have access to more information than ever before, it’s really easy to forget digital histories and the lessons that we can learn from that.”
Shadel’s writing touches on a range of intersecting topics—such as tech, travel and queerness—but the one thing they hope everyone takes away from their work is the idea that we’re all netizens with a role to play in shaping what we want these shared public spaces to be.
“If we all have some shared sense of ownership of the internet, which is so involved in our lives, I believe we have a greater chance to make it better.” Sometimes, that can start in simple ways—in this case, building a DIY website with a bunch of old GIFs reminded one tech journalist in London that there are lessons we can take from the early internet. “We all have a part to play in making the internet a better place.” And at the least, they hope you enjoy the GIFs they’ve selected.
A family in Hatfield, ca. 1889. L.H. Kingsley, photographer.
Guest post by Dylan Gaffney, Information Services Associate for Local History & Special Collections, Forbes Library.
This post is part of a series written by members of the Community Webs program. Community Webs advances the capacity for community-focused memory organizations to build web and digital archives documenting local histories and underrepresented voices. For more information, visit communitywebs.archive-it.org.
Forbes Library has been a member of Community Webs since its inception in 2017. At that time, we were hopeful that the program would allow us to create an archive which more fully represented the community in which we live, and provide a more diverse history/record of our region and the people we serve. This project inspired archives staff to examine the many silences in our archives, and make plans for the ethical collection and preservation of materials that would help fill in these gaps in our historical record. At the same time, the library had begun to shift its focus toward collaboration with other local historical and community organizations.
In the years following the kickoff of the Community Webs Project, Forbes library co-hosted multiple series of exhibits, films, workshops, walking tours, and community reads on themes of mass incarceration, the Underground Railroad, and the history of slavery in our region. These events, and the passionate response of the community to them, inspired us to continue seeking out collaborations, large and small, and solidified our view that surfacing stories of people who had been underrepresented in the archives should be a core value in our work as an institution.
This work inspired Forbes Library, Historic Northampton, UMass Amherst, and the Pioneer Valley History Network to take lead roles in the 2021 Documenting Early Black Lives in the Connecticut River Valley project, which seeks to gather the fragmentary information about Black lives from the wide range of sources and archives in Western Massachusetts so that a whole might be perceived that is larger than the sum of those parts. The project, to date, has surfaced over 3500 records or references to people of color, enslaved and free, in Western Massachusetts from the 17th through 19th centuries. These histories are being made available through the project’s database and on the project website. We contributed an essay titled Searching for Black History in a Public Library Archive to the Project Handbook on the experiences and takeaways of doing this work from a public librarian’s perspective.
We know too little about Black lives in rural and small-town New England, and the places Black residents were able to carve out for themselves in these communities. With this project, we hoped to uncover names, details of their lives, and some small sense of how people of color survived in the Connecticut River Valley before and after the abolition of slavery in Massachusetts in 1783. At the kickoff event for the project, UMass Amherst professor Gretchen Holbrook Gerzina mentioned challenging the assumptions of others (sometimes called Gatekeepers) who “might be quick to discourage a researcher interested in Black History, reporting that they don’t have much…or not thinking about ways that records of white families might be useful to this research” Gerzina remarked that researchers, curators, and librarians should ”start from the perspective of presence.”
As the Documenting Black Lives project was undertaken with grant funding, and the time thus limited, we needed to develop an approach that would be productive right away. We identified several collections in the library’s Hampshire Room for Local History that we expected could be productive resources for identifying enslaved people in the area. The most promising of these was the Judd Manuscript Collection, a collection of 60+ volumes created by local newspaper editor and historian Sylvester Judd in the 1840s. The manuscript was originally purchased from the Judd estate by local historian James Trumbull and subsequently sold to the trustees of the library. It has been the property of the library since 1904, but use has been limited to a small group of academics and local historians who were aware of the contents and could physically visit during our few open archives hours. Those who knew of its tremendous historical value had discovered that it features content documenting Indigenous lives, enslaved people, and free Black people in New England and had used it to research Indigenous culture, the history of colonial settlement, enslavement, and the early abolitionist movement in the area.
Public Historian and Author Marla Miller on the value of Judd:
“Sylvester Judd, in his transcriptions of historic documents as well as the conversations he described with local residents, preserves extraordinary details that survive nowhere else. Because of Judd’s meticulous, wide-ranging work, I was able to gain insight into the lives of laboring people that would never otherwise have been possible…Judd’s notes preserve genealogical information about enslaved people that is found nowhere else. The Judd manuscript is almost archaeological in nature, with shards of evidence that can be unearthed via careful scrutiny. As he records, for instance, who had the first piano in town, who laid the first carpet, the sound of the geese squawking through Sunday sermons, and a hundred other small details of daily life, a picture emerges that simply cannot be found in any other kind of more formal or systematic archival material. These pages, filled from edge to edge with his notes, cross references, sketches, and other materials, simply teem with the kinds of details that historians crave, but cannot hope to find—except in Northampton.”
If we start from an assumption of presence (of underrepresented people both in the community and in the archives), the primary obstacles to discovering and surfacing information in collections like ours, often revolve around issues of access, and methodologies for search and discovery. We had long dreamed of digitizing all 60+ bound volumes of the collection to make them available to a wider group of researchers and the public at large. When the Community Webs program began to explore funding for a digitization program dedicated to expanding the amount and diversity of locally-focused community archives available online to users, the Judd Manuscript Collection seemed a good fit.
Now that the volumes have been digitized, our mission is to spread the word about their value and availability, so that the materials within can inform and inspire new research and discovery. As an illustration of the value of the collection and its contents, it is useful to look at how the increased availability of this resource could lead to new discoveries in long hidden collections. As an example, I will examine how Judd enriched our understanding of one local Black family.
Judd devoted entire volumes to genealogies of local families, but the 600+ page volume on Northampton Genealogies contains, to our knowledge, only two Black families, both listed without last names. The work we had done in the Documenting Black Lives project enabled us to compile a list of 3500+ entries for Black residents of the region in the period between the 1650-1900. We recognized these names as those of Amos and Bathsheba Hull and their children. Bathsheba can be found elsewhere in our own archives as a member of the Church of Christ during Jonathan Edwards ministry between 1729-1750, in records recorded by Jonathan Edwards own hand.
This entry transcribed from a local merchant’s account book shows items purchased by Amos Hull, the services he would perform in exchange for goods received, and the rate at which he was paid. It notes that in 1761, the same year their daughter Margaret was born, Amos Hull died. Afterward, his widow Bathsheba paid for his and her accounts by washing. Bathsheba surely would have a difficult time supporting multiple children without her husband, and documents subsequently found elsewhere in our archives and in other institutions prove this to be the case.
By 1762, a document found elsewhere in our archives records their son Asaph indentured to Seth Pomeroy, who is well known for his service in the French and Indian War and would go onto fight at the Battle of Bunker Hill and achieve the rank of Major General.
Bathsheba and her family come up again in several entries in Judd, including multiple mentions of the town seizing her land and displacing her from it in 1765. This cruel act forces Bathsheba and her young children from the town. Bathsheba and her son Agrippa would relocate to Stockbridge, Massachusetts. It is in Stockbridge where Agrippa Hull would enlist in May of 1777, and served for the remainder of the Revolutionary War in the Continental Army, including witnessing the surrender of British General John Burgoyne at Saratoga, New York, enduring the winter of 1777-78 at Valley Forge and was part of the battle at Monmouth Courthouse, New Jersey in June 1778. He then served as a personal assistant for the famed Polish general, revolutionary and engineer Taddeusz Kosciuszko and became a close friend of the General, during their years of War Service together. Agrippa’s story and friendship with Kosciuszko, along with Kosciuszko’s friendship with Thomas Jefferson is examined in Gary Nash and Graham Hodge’s 2012 book “Friends of Liberty: Thomas Jefferson, Tadeusz Kosciuszko, and Agrippa Hull”.
Portrait of Agrippa Hull, Courtesy of the Stockbridge Library, Museum & Archives.
Agrippa Hull went on to become the most prominent black landowner in Stockbridge MA and is buried along with his wife and children in Stockbridge Cemetery. His brother Amos Hull, Jr. also fought in the Continental Army, and surfaces in Belchertown MA records recorded as part of the Documenting Black Lives project.
This is just one brief example of the elaborate web of information that can be revealed when we prioritize the surfacing of stories that had previously been hidden in our collections, increase access through digitization, and collaborate to research and promote the information within.
“ We can hardly wait to learn— alongside the many other academic and avocational historians whose work will be enriched and transformed by these records—what else remains to be discovered. Once available in digital form, available for scouring by researchers with their own wide range of questions, these materials will certainly spark, inform, and enrich generations of new research, from student papers to dissertations to academic monographs. It is almost impossible to predict all the ways the volumes might reshape historiography, as well as conventional historical wisdom, because the contents at present are comparatively difficult to ferret out. But to be sure, these volumes have the potential to transform local and regional historical understanding, and once digitized, will certainly come to the attention of researchers nationwide.”
The Internet Archive and Community Webs are thankful for the support from the National Historical Publications & Records Commission for Collaborative Access to Diverse Public Library Local History Collections, which will digitize and provide access to a diverse range of local history archives that represent the experiences of immigrant, indigenous, and African American communities throughout the United States.
Join us for a book talk with ANDREA I. COPLAND & KATHLEEN DeLAURENTI about UNLOCKING THE DIGITAL AGE, a crucial resource for early career musicians navigating the complexities of the digital era.
“[Musicians,] Use this book as a tool to enhance your understanding, protect your creations, and confidently step into the world of digital music. Embrace the journey with the same fervor you bring to your music and let this guide be a catalyst in shaping a fulfilling and sustainable musical career.” – Dean Fred Bronstein, THE PEABODY INSTITUTE OF THE JOHNS HOPKINS UNIVERSITY
Based on coursework developed at the Peabody Conservatory, Unlocking the Digital Age: The Musician’s Guide to Research, Copyright, and Publishingby Andrea I. Copland and Kathleen DeLaurenti [READ NOW] serves as a crucial resource for early career musicians navigating the complexities of the digital era. This guide bridges the gap between creative practice and scholarly research, empowering musicians to confidently share and protect their work as they expand their performing lives beyond the concert stage as citizen artists. It offers a plain language resource that helps early career musicians see where creative practice and creative research intersect and how to traverse information systems to share their work. As professional musicians and researchers, the authors’ experiences on stage and in academia makes this guide an indispensable tool for musicians aiming to thrive in the digital landscape.
Copland and DeLaurenti will be in conversation with musician and educator, Kyoko Kitamura. Music librarian Matthew Vest will facilitate our discussion.
Unlocking the Digital Age: The Musician’s Guide to Research, Copyright, and Publishing is available to read & download.
ANDREA I. COPLAND is an oboist, music historian, and librarian based in Baltimore, MD. Andrea has dual master’s of music degrees in oboe performance and music history from the Peabody Institute of the Johns Hopkins University and is currently Research Coordinator at the Répertoire International de la Presse Musicale (RIPM) database. She is also a teaching artist with the Baltimore Symphony Orchestra’s OrchKids program and writes a public musicology blog, Outward Sound, on substack.
KATHLEEN DeLAURENTI is the Director of the Arthur Friedheim Library at the Peabody Institute of The Johns Hopkins University where she also teaches Foundations of Music Research in the graduate program. Previously, she served as scholarly communication librarian at the College of William and Mary where she participated in establishing state-wide open educational resources (OER) initiatives. She is co-chair of the Music Library Association (MLA) Legislation Committee as well as a member of the Copyright Education sub-committee of the American Library Association (ALA) and is past winner of the ALA Robert Oakley Memorial Scholarship for copyright research. DeLaurenti is passionate about copyright education, especially for musicians. She is active in communities of practice working on music copyright education, sustainable economic models for artists and musicians, and policy for a balanced copyright system. DeLaurenti served as the inaugural Open Access Editor of MLA and continues to serve on the MLA Open Access Editorial Board. She holds an MLIS from the University of Washington and a BFA in vocal performance from Carnegie Mellon University.
KYOKO KITAMURA is a Brookyn-based vocal improviser, bandleader, composer and educator, currently co-leading the quartet Geometry (with cornetist Taylor Ho Bynum, guitarist Joe Morris and cellist Tomeka Reid) and the trio Siren Xypher (with violist Melanie Dyer and pianist Mara Rosenbloom). A long-time collaborator of legendary composer Anthony Braxton, Kitamura appears on many of his releases and is the creator of the acclaimed 2023 documentary Introduction to Syntactical Ghost Trance Music which DownBeat Magazine calls “an invaluable resource for Braxton-philes.” Active in interdisciplinary performances, Kitamura recently provided vocals for, and appeared in, artist Matthew Barney’s 2023 five-channel installation Secondary.
MATTHEW VEST is the Music Inquiry and Research Librarian at UCLA. His research interests include change leadership in higher education, digital projects and publishing for music and the humanities, and composers working at the margins of the second Viennese School. He has also worked in the music libraries at the University of Virginia, Davidson College, and Indiana University and is the Open Access Editor for the Music Library Association.
Book Talk: UNLOCKING THE DIGITAL AGE April 3 @ 10am PT / 1pm ET VIRTUAL Register now!
Growing up in New Jersey, Beth Noveck says she was surrounded by so many books in her home that it felt like a library.
Simon and Doris Noveck. Image credit: Reiner Leist, American Portraits Prestel Publishing, 1999
Her father, Simon Noveck, was a voracious reader. A rabbi with a Ph.D. in political science from Columbia University, Simon collected books about Jewish philosophy, history, and sociology. Her mother, Doris, was interested in books about the arts and cooking. Together, they traveled around the world and often brought home souvenirs in the form of books, including a Turkish dictionary and a guidebook from a Jewish cemetery in Prague.
Over the years, the Novecks amassed a collection of more than 10,000 volumes. After they died (Simon in 2005; Doris in 2022), the family had to decide what to do with all the books.
“My parents had always talked about the idea of building a lending library, creating a home for the collection that people could access,” said Beth, a professor at Northeastern University in Boston.
While storing the items in a physical library was not feasible, Beth said the Internet Archive provided the perfect solution: Digitizing the collection.
Donating the collection
The donation process started by completing the Internet Archive’s physical item donation form. She then got in touch with the Internet Archive team who helped answer questions about the deduplication, packing and shipping process.
“We work with prospective donors to make sure that the valuable information in their collections will be unique to our library,” said Liz Rosenberg, Internet Archive’s donations manager. “Once we determine the collection will help add new resources to our library we help coordinate the logistics of getting the collection to the physical archives. There can be all sorts of logistics puzzles involved in physical item donations, especially for sizable donations like this one, like how to box books for efficient storage and transport. It’s always meaningful to work with families to help honor the legacy of their loved ones by preserving the materials they curated over time.”
Boxing and moving the collection.
In November, the family donated approximately 5,000 books in 200 boxes—every book from the collection that the Archive did not already have online. Staff from the Internet Archive provided the boxes, staff and two trucks to move the items from New Jersey to the physical archives. The items will eventually be scanned, cataloged and available for free to the public online.
“I can think of no better way to honor my father’s memory and all the work that he did to create this collection,” Beth said. “This way his legacy continues, and other people get to benefit from the work that he did. I’m so thrilled and grateful for this opportunity.”
To decide what to donate, Beth and her son, Amedeo Bettauer, 14, used the Donate Books app (iPhone / Android) from the Internet Archive to review each book to see if it would be new to the collection or a duplicate. The books had been moved to a family member’s house in New Jersey, where Beth and Amedeo went over the course of five weekends last fall (by plane, car or train) to sort out the collection.
“It was an occasion for a lot of reminiscence, wonderful stories and exchange of memories,” Beth said.
Understanding the collection
Born in 1914, Simon had served congregations in New York City and Hartford, Connecticut; was the head of adult education for B’Nai Brith; and wrote several books about Jewish history, sociology and philosophy. Living far from a research library in rural New Jersey, Beth said her parents frequently bought books and remained in touch with the wider world through their reading.
Sample book from the donation.
For Amedeo, who never met his grandfather, the process was a chance to learn more about his family’s history.
“Books really do reflect a person,” Amedeo said. “Getting to see my grandfather’s entire collection gave me a window into who he was, as a man, which was very interesting. There were some moments where I thought, ‘Wait, that’s a book that I might have gotten or that I even have.’ It was very enlightening to see.”
Amedeo and Beth said they were amazed at the breadth of the collection, including papers from U.S. presidents, and rare books on a variety of topics. The process was both sentimental and enjoyable, Beth said, knowing that her father had read every book they sorted. A long-time fan and supporter of the Internet Archive, she said it was very satisfying for the family to know that so much of the collection will be preserved.
“A lot of my grandfather’s books were very esoteric, so he might have been the only person left that had a physical copy of a certain book,” Amedeo said. “To have that be lost or destroyed would be a catastrophic loss of knowledge. This way the collection is digitized and forever available to everyone for free. I think it’s what my grandparents would have wanted.”
LOST LANDSCAPES OF SAN FRANCISCO: The City and Bay in Motion March 18 @ 6:30pm – 9pm Internet Archive, 300 Funston Avenue, San Francisco Buy Tickets
This 18th edition of LOST LANDSCAPES immerses viewers in the dynamic tapestry of mobility and communication across the Bay Area. Delving into the rich archival footage of San Francisco and its environs, the film captures the essence of daily life, work, and celebration, while revisiting both familiar and obscure historical moments.
This unique film event is taking place at the Internet Archive where you can experience rare and unseen footage from the Prelinger Archives. The film features footage drawn from a vast repository of over 3,000 newly scanned archival films, including home movies, government productions, industrial reels, and unexpected gems.
By attending, you’ll directly contribute to supporting the Internet Archive. Rick Prelinger will be presenting as per usual. Don’t miss this opportunity to be a part of truly special evening!
Doors open at 6:30 pm. Film starts at 7:30 PM. Register now!
No one will be turned away due to lack of funds!
LOST LANDSCAPES OF SAN FRANCISCO: The City and Bay in Motion March 18 @ 6:30pm – 9pm Internet Archive, 300 Funston Avenue, San Francisco Buy Tickets
Please come join us as the Internet Archive partners with the Skyline College Art Gallery for the viewing of “Portraits of Growing Up Asian,” a photo exhibition that tells a visual story of a Chinese American family’s journey from China to San Francisco’s Chinatown.
The Hall family’s arrival from China in the 1850’s resulted in the opening of the first Chinese herbal medicine shop in San Francisco’s Chinatown in 1864 and became a hub for the local community. The business was open until it was unlawfully shut down by the FBI in 1957. This tragedy led to a family tradition in photography that spanned generations.
The exhibition features archived photographs and artifacts from the Hall Family Collection, including the family herb shop signage. It also features photographs by Timothy Hall and his experiences growing up in San Francisco from the 1950’s to contemporary times.
The exhibition explores themes of ancestry, family, discrimination, and all that comes with growing up as Chinese Americans in San Francisco’s Chinatown in the mid to late 20th century.
In an era where the vast majority of “photographs” are a series of captured data points stored in the etheric realm of a digital universe, it becomes a delightful trip to step into the authentic past and to awaken to the sensations conveyed through the experience of an actual photograph. Please join us.
DATES: Mon Feb 26th Opening Reception and Opening 12-2pm Mar 26th – Closing Day
HOURS: Please visit the Skyline College Art Gallery Website for Hours Monday: 10am-12:30pm Tuesday: 4pm-6pm Wednesday: 10am-12:30pm Thursday: 4pm-6pm Friday: 11-4pm
This post was originally published in a newsletter by Project Liberty, February 20, 2024. Image by Project Liberty.
In the summer of 2023, the New York Times ran an article titled “Ways You Can Still Cancel Your Federal Student Loan Debt.”
The article outlined six ways to cancel student debt, with the final being:
“Death This is not something that most people would choose as a solution to their debt burden.”
At least that was the sixth reason until the New York Times revised it with a stealth edit. When you read the article today, choosing death as a solution to a debt burden has been replaced, but there’s no mention that this article was revised. The timestamp is still the day it was originally published.
The internet is constantly being revised in ways that allow history to be rewritten and a shared sense of truth to be questioned. With AI-generated disinformation, the potential to exert control over the future by rewriting the past has never been greater.
This week we’re exploring how digital archives are crucial in developing a record of truth in an ever-changing web.
The need for digital archives
Mark Graham, Director of the Wayback Machine, spoke with the Project Liberty Foundation and shared the key reasons why there’s an even greater need for digital archives:
The importance of the internet. So much of what humanity publishes and makes available lives only on the internet. Given how much time we spend online, the internet has become a central medium of human expression, history, and culture.
The fragile and ephemeral nature of the internet. Graham shared two stats that underscore how fragile today’s internet is:
A study found that of the two million hyperlinks in New York Times articles from 1996 to 2019, 25% of all links were broken (described as link rot).
The Wayback Machine has fixed 20 million broken links in Wikipedia articles with the correct ones.
“The web itself is a living thing. Webpages change. They go away on quite a frequent basis. There’s no backup system or version control system for the web,” Graham explained. That is, except for archives like the Wayback Machine.
The Wayback Machine
The Wayback Machine is a “time machine for the web,” in Graham’s words. It allows users to trace the evolution (or disappearance) of a webpage over time, enabling them to establish a record of what happened on the internet.
For example, the Apple.com URL has been archived 539,000 times since its first archived page in October 1996.
The Wayback Machine has archived over 866 billion webpages in its 28-year history. Today, it archives hundreds of millions of webpages every day and has become one of the most important archives of online content in the world.
How it works
The Wayback Machine “crawls” the web and downloads publicly accessible information. Webpages, documents, and data are stored with a time-stamped URL.
For information that’s not publicly accessible, Internet Archive offers web archiving services through Archive-It for 1,200 organizations in 24 countries around the world (from libraries to research institutions).
The Wayback Machine supports everyday people to help it archive the internet. Anyone can go to Save Page Now to archive a webpage or article.
The Wayback Machine partners with 1,200 fact-checking organizations globally to help it reference material on the web that was the source of disinformation. It has built a library of more than 200,000 examples where a claim has been made, and the Wayback Machine has provided additional context on if that claim is true (known as a review of the claim).
Archive of facts
Fixing links, archiving webpages, and fact-checking digital articles are part of a deeper, more important project to chronicle digital history and establish a record of facts.
Last month, the archive of press releases from a sitting member of Congress, New York’s Elise Stefanik, vanished after she came under scrutiny. The Wayback Machine documented this erasure and provided a time-stamped record of past versions of her website and press releases.
In 2018, a US Appeals court ruled that the Wayback Machine’s archive of webpages can be used as legitimate legal evidence.
The Internet Archive has countless examples of when the press have referenced the Wayback Machine to correct disinformation and dispel rumors. In one example from last year, the Associated Press relied on the Wayback Machine to set the record that the CDC did not say the polio vaccine gave millions of Americans a “cancer virus.”
Building digital archives is a bulwark against those attempting to rewrite history and spread misinformation. An archived, time-stamped webpage is not just unimpeachable evidence, it’s a foundational building block of a shared sense of reality.
In 2014, when Malaysia Airlines Flight 17 went down over Ukraine, the Wayback Machine captured evidence that a pro-Russian group was behind the missile attack. But it wasn’t the Wayback Machine’s algorithms that captured the evidence by crawling the internet; it was an individual who found an obscure blog post from a Ukrainian separatist leader touting the shooting down of a plane. That individual identified the blogpost as important enough to be archived, and it became a critical piece of evidence, even after that post disappeared from the internet.
As Graham said, “You don’t know what you got until it’s gone. If you see something, save something.”
What pages can you help archive? Archive them with the Wayback Machine on Save Page Now.
As we celebrate Fair Use/Fair Dealing Week, we are reminded of all the ways these flexible copyright exceptions enable libraries to preserve materials and meet the needs of the communities they serve. Indeed, fair use is essential to the functioning of libraries, and underlies many of the ordinary library practices that we all take for granted. In this blog post, we wanted to describe a few of the ways the fair use doctrine has helped us build our library.
Fair use in action: Web Archives and the Wayback Machine
The Internet Archive has been archiving the web since the mid-1990’s. Our web collection now includes more than 850 billion web pages, with hundreds of millions added each day. The Wayback Machine is a free service that lets people visit these archived websites. Users can type in a URL, select a date range, and then begin surfing on an archived version of the web.
Web archives are used for a variety of important purposes, many of which are themselves fair uses. News reporting and investigative journalism is one such use of the Wayback Machine. Indeed, thousands of news articles have relied upon historical versions of the web from the Wayback Machine. Just last week, 13 links to the Wayback Machine were used in a CNN story about an Ohio GOP Senate candidate’s previous statements that were critical of former President Trump. Our web archive also becomes an urgent backup for media sites that are shut down suddenly, whether by authoritarian governments or for other reasons, often becoming the only accessible source both for the authors of these stories and for the public. Another important purpose web archives can serve is as evidence in legal disputes. Attorneys use the Wayback Machine in their daily practice for evidentiary and research purposes. In 2023 alone, the Internet Archive attested to 450 affidavits in cases where Wayback Machine captures were used as evidence in court.
The Wayback Machine also makes other parts of the web, such as Wikipedia, more useful and reliable. To date, the Internet Archive has been able to repair over 19 million broken links, URLs, that had returned a 404 (Page Not Found) error message, from 320 different Wikipedia language editions. There are many reasons, including bit rot and content drift, why links stop working. Restoring links ensures that Wikipedia remains an accurate and verifiable source of information for the public good. And we hope to build new tools and partnerships to help create a more dependable knowledge ecosystem as more and more content on the web is created by generative AI.
The Fair Use doctrine is broadly considered to be what makes web archiving possible. Without it, much of our knowledge and cultural heritage–huge amounts of which are now artifacts in digital form–would be at risk. In today’s chaotic information ecosystem, safeguarding this material in an open, accessible, and transparent way is vital for history and vital for democracy.
Fair use in action: Manuals collection
Whether you are an individual who has rendered an appliance useless because you lost the instructions, or a professional mechanic looking to fix an old vehicle, owners’ manuals are invaluable. As the right to repair movement has amply demonstrated, copyright should not stand as an obstacle to using machines you’ve bought and paid for. This is a place where fair use can shine.
Over the years, the Internet Archive has received manuals, instruction sheets and informational pamphlets of all kinds. The Manuals collection has well over a million items—or users to access 24/7 at no cost. This resource gives people the right to repair and extend the life of their products. Whether you are a rocket scientist needing to operate your space shuttle, a mechanic who needs to repair a vintage VW Bug, or a curious kid trying to fix up your mom’s old computer, having free online access to the technical documentation you need is essential. And in many cases, there would appear to be no other way to get access to this crucial information.
Some preserved manuals are a single printed page with poorly constructed diagrams. Others are multi-volume tomes that give exacting details on operation of a complex piece of machinery. These materials are more than instructions or a list of components. They reflect the priorities and approaches that companies and individuals take with products, as well as the artistic and visual efforts to make an item clear to the reader.
This collection is a cool example of how fair use provides a framework for the Internet Archive to share critical knowledge with consumers. At the same time, it provides a historical timeline of sorts for innovation and the development of technology.
From preserving our digital history to providing access to manuals of obsolete devices, fair use helps libraries like ours serve our community. And while there are no doubt a variety of commercial projects that properly rely on fair use, fair use is at heart about the public good. As we celebrate Fair Use week, we should remember the crucial role it plays, and ensure that we preserve and protect fair use for the good of future generations. For more on events and news on Fair Use/Fair Dealing Week, visit FairUseWeek.org.
From Prince of Persia to Replay: A video game creator’s family odyssey
Jordan Mechner (creator of “Prince of Persia”) shares his story as a pioneer in the fast-growing video game industry from the 1980s to today, and how his family’s back story as refugees from war-torn Europe led to his own multifaceted 4-decade creative career. Interweaving of past and present, family transmission, exile and renewal are at the heart of his award-winning graphic novel “Replay: Memoir of an Uprooted Family.”
For general audiences, including anyone interested in video game development, graphic novels, transmedia, or multigenerational family stories.
Book Talk: REPLAY March 27 @ 10am PT / 1pm ET Register now for the virtual event!
About REPLAY
1914. A teenage romantic heads to the enlistment ofice when his idyllic life in a Jewish enclave of the Austro-Hungarian Empire is shattered by World War I.
1938. A seven-year-old refugee begins a desperate odyssey through France, struggling to outrun the rapidly expanding Nazi regime and reunite with his family on the other side of the Atlantic.
2015. e creator of a world-famous video game franchise weighs the costs of uprooting his family and moving to France as the cracks in his marriage begin to grow.
Prince of Persia creator Jordan Mechner calls on the voices of his father and grandfather to weave a powerful story about the enduring challenge of holding a family together in the face of an ever-changing world.
JORDAN MECHNER is an author, graphic novelist, game designer, and screenwriter. He created the video game Prince of Persia in 1989, rebooted it with Ubisot in 2003, and wrote the first screenplay for Disney’s 2010 film adaptation, Prince of Persia: The Sands of Time. His other games include Karateka and The Last Express. In 2017, he received the Pioneer Award from the International Game Developers Association. Jordan’s graphic novels as writer include the New York Times bestseller Templar (from First Second, with LeUyen Pham and Alex Puvilland), Monte Cristo (Mario Alberti), and Liberty (Etienne LeRoux). Replay is his first book as writer/artist.
Book Talk: REPLAY March 27 @ 10am PT / 1pm ET Register now for the virtual event!