From Prince of Persia to Replay: A video game creator’s family odyssey
Jordan Mechner (creator of “Prince of Persia”) shares his story as a pioneer in the fast-growing video game industry from the 1980s to today, and how his family’s back story as refugees from war-torn Europe led to his own multifaceted 4-decade creative career. Interweaving of past and present, family transmission, exile and renewal are at the heart of his award-winning graphic novel “Replay: Memoir of an Uprooted Family.”
For general audiences, including anyone interested in video game development, graphic novels, transmedia, or multigenerational family stories.
Book Talk: REPLAY March 27 @ 10am PT / 1pm ET Register now for the virtual event!
About REPLAY
1914. A teenage romantic heads to the enlistment ofice when his idyllic life in a Jewish enclave of the Austro-Hungarian Empire is shattered by World War I.
1938. A seven-year-old refugee begins a desperate odyssey through France, struggling to outrun the rapidly expanding Nazi regime and reunite with his family on the other side of the Atlantic.
2015. e creator of a world-famous video game franchise weighs the costs of uprooting his family and moving to France as the cracks in his marriage begin to grow.
Prince of Persia creator Jordan Mechner calls on the voices of his father and grandfather to weave a powerful story about the enduring challenge of holding a family together in the face of an ever-changing world.
JORDAN MECHNER is an author, graphic novelist, game designer, and screenwriter. He created the video game Prince of Persia in 1989, rebooted it with Ubisot in 2003, and wrote the first screenplay for Disney’s 2010 film adaptation, Prince of Persia: The Sands of Time. His other games include Karateka and The Last Express. In 2017, he received the Pioneer Award from the International Game Developers Association. Jordan’s graphic novels as writer include the New York Times bestseller Templar (from First Second, with LeUyen Pham and Alex Puvilland), Monte Cristo (Mario Alberti), and Liberty (Etienne LeRoux). Replay is his first book as writer/artist.
Book Talk: REPLAY March 27 @ 10am PT / 1pm ET Register now for the virtual event!
How data surveillance, digital forensics, and generative AI pose new long-term threats and opportunities—and how we can use them to make better decisions in the face of technological uncertainty.
Book Talk: The Secret Life of Data April 18 @ 10am PT / 1pm ET ONLINE Register now!
“I have been waiting a long time for a clearly written book that cuts through the hype and describes how data—big and small, old and new—actually operate in our lives. Neither utopian nor dystopian, The Secret Life of Data just tells it like it is.” —Siva Vaidhyanathan, Professor of Media Studies, The University of Virginia; author of Antisocial Media and The Googlization of Everything (And Why We Should Worry)
In The Secret Life of Data, Aram Sinnreich and Jesse Gilbert explore the many unpredictable, and often surprising, ways in which data surveillance, AI, and the constant presence of algorithms impact our culture and society in the age of global networks. The authors build on this basic premise: no matter what form data takes, and what purpose we think it’s being used for, data will always have a secret life. How this data will be used, by other people in other times and places, has profound implications for every aspect of our lives—from our intimate relationships to our professional lives to our political systems.
ARAM SINNREICH is an author, professor, and musician. He is Chair of Communication Studies at American University. His books include Mashed Up,The Piracy Crusade, The Essential Guide to Intellectual Property, and A Second Chance for Yesterday(published as R. A. Sinn).
JESSE GILBERT is an interdisciplinary artist exploring the intersection of visual art, sound, and software design at his firm Dark Matter Media. He was the founding Chair of the Media Technology department at Woodbury University, and he has taught interactive software design at both CalArts and UC San Diego.
DR. LAURA DENARDIS is Professor and Endowed Chair in Technology, Ethics, and Society and Director of the Center for Digital Ethics at Georgetown University in Washington, DC. Her book The Internet in Everything: Freedom and Security in a World with No Off Switch (Yale University Press) was recognized as a Financial Times Top Technology Book of 2020. Among her seven books, The Global War for Internet Governance (Yale University Press) is considered a definitive source for understanding cyber governance debates and solutions. Professor DeNardis is an affiliated Fellow of the Yale Information Society Project, where she previously served as Executive Director, and is a life Member of the Council on Foreign Relations. She holds engineering degrees and a PhD in Science and Technology Studies, and was awarded a postdoctoral fellowship from Yale Law School.
Book Talk: The Secret Life of Data April 18 @ 10am PT / 1pm ET ONLINE Register now!
Join us for a VIRTUAL book talk with author Joanne McNeil about her latest book, WRONG WAY, which examines the treacherous gaps between the working and middle classes wrought by the age of AI. McNeil will be in conversation with author Sarah Jaffe.
This is the first Internet Archive / Authors Alliance book talk for a work of fiction! Come for a reading, stay for a thoughtful conversation between McNeil & Jaffe about the labor implications of artificial intelligence.
WRONG WAY was named one of the best books of 2023 by the New Yorker and Esquire. It was the Endless Bookshelf Book of the Year and named one of the best tech books by the LA Times.
“Wrong Way is a chilling portrait of economic precarity, and a disturbing reminder of how attempts to optimize life and work leave us all alienated.” —Adrienne Westenfeld, Esquire
For years, Teresa has passed from one job to the next, settling into long stretches of time, struggling to build her career in any field or unstick herself from an endless cycle of labor. The dreaded move from one gig to another is starting to feel unbearable. When a recruiter connects her with a contract position at AllOver, it appears to check all her prerequisites for a “good” job. It’s a fintech corporation with progressive hiring policies and a social justice-minded mission statement. Their new service for premium members: a functional fleet of driverless cars. The future of transportation. As her new-hire orientation reveals, the distance between AllOver’s claims and its actions is wide, but the lure of financial stability and a flexible schedule is enough to keep Teresa driving forward.
Joanne McNeil, who often reports on how the human experience intersects with labor and technology brings blazing compassion and criticism to Wrong Way, examining the treacherous gaps between the working and middle classes wrought by the age of AI. Within these divides, McNeil turns the unsaid into the unignorable, and captures the existential perils imposed by a nonstop, full-service gig economy.
JOANNE MCNEIL was the inaugural winner of the Carl & Marilynn Thoma Art Foundation’s Arts Writing Award for an emerging writer. She has been a resident at Eyebeam, a Logan Nonfiction Program fellow, and an instructor at the School for Poetic Computation. Joanne is the author of Lurking: How a Person Became a User.
SARAH JAFFE is an author, independent journalist, and a co-host of Dissent magazine’s Belabored podcast.
Book Talk: Wrong Way by Joanne McNeil February 29 @ 10am PT / 1pm ET VIRTUAL Register now!
Have you ever used the Wayback Machine and witnessed the magic of internet time travel? We want to hear your stories of how web archives have made a positive impact on your life! Whether it’s preserving a cherished memory, aiding in research, or sparking a meaningful change – your stories matter!
Fill out our quick questionnaire and let us know how the Wayback Machine has left a mark on your digital journey: https://forms.gle/5DhDqNTLqxY41K3p6
Your stories could inspire others and highlight the importance of preserving the web’s rich history. Let’s celebrate the incredible moments made possible by the Wayback Machine!
You may be wondering, “Will anyone actually read my submission?” YES! We appreciate your time in sharing your story. Submissions will be reviewed and may be included in upcoming social media posts and news stories. We put out a similar call last year and received hundreds of responses, which we turned into testimonials & blog posts to help people understand how our library is used.
Started in 2017, our Community Webs program has over 175 public libraries and local cultural organizations working to build digital archives documenting the experiences of their communities, especially those patrons often underrepresented in traditional archives. Participating public libraries have created over 1,400 collections documenting local civic life totaling nearly 100 terabytes and tens of millions of individual documents, images, audio/video files, blogs, websites, social media, and more. You can browse many of these collections at the Community Webs website. Participants have also collaborated on digitization efforts to bring minority newspapers online, held public programming and outreach events, and formed local partnerships to help preservation efforts at other mission-aligned organizations. The program has conducted numerous workshops and national symposia to help public librarians gain expertise in digital preservation and cohort members have done dozens of presentations at professional conferences showcasing their work. In the past, Community Webs has received support from the Institute of Museum and Library Services, the Mellon Foundation, the Kahle Austin Foundation, and the National Historical Publications and Records Commission.
We are excited to announce that Community Webs has received $750,000 in funding from The Mellon Foundation to continue expanding the program. The award will allow additional public libraries to join the program and will enable new and existing members to continue their web archiving collection building using our Archive-It service. In addition, the funding will also provide members access to Internet Archive’s new Vault digital preservation service, enabling them to build and preserve collections of any type of digital materials. Lastly, leveraging members’ prior success in local partnerships, Community Webs will now include an “Affiliates” program so member public libraries can nominate local nonprofit partners that can also receive access to archiving services and resources. Funding will also support the continuation of the program’s professional development training in digital preservation and community archiving and its overall cohort and community building activities of workshops, events, and symposia.
We thank The Andrew W. Mellon Foundation for their generous support of Community Webs. We are excited to continue to expand the program and empower hundreds of public librarians to build archives that document the voices, lives, and events of their communities and to ensure this material is permanently available to patrons, students, scholars, and citizens.
Ham Radio & More was the first radio show devoted to ham radio on the commercial radio band. It began as a one-hour show on KFNN 1510 AM in Phoenix, Arizona, then expanded to a two-hour format and national syndication. The program’s host, Len Winkler, invited guests to discuss the issues of the day and educate listeners about various aspects of the radio hobby. Today the episodes, some more than 30 years old, provide an invaluable time capsule of the ham radio hobby.
just some of the HR&M cassette tapes
Len Winkler said, “I’m so happy that the Digital Library of Amateur Radio & Communications took all my old shows and made them eternally available for everyone to hear and enjoy. I had the absolute pleasure, along with a few super knowledgeable co-hosts, to interview many of the people that made ham radio great in the past and now everyone can go back and listen to what they had to say. From the early beginnings of SETI (search for extraterrestrial intelligence) to Senator Barry Goldwater to the daughter of Marconi. So much thanks to the Digital Library of Amateur Radio & Communications for doing this amazing service.”
Other interviewees included magazine publisher Wayne Green, Sheriff Joe Arpaio, Bob Heil, Bill Pasternak, Fred Maia, and other names well known to the amateur radio community. Discussion topics spanned the technical, such as signal propagation, to community issues, including the debate over the Morse code knowledge requirement for ham radio operators—a requirement eventually dropped, to the benefit of the community.
The radio programs were recorded on cassette tapes when they originally aired. Winkler digitized 149 episodes of the show himself in 2015 and 2016. The digitizing project paused for years. In January 2024 he sent the remaining cassettes to DLARC. Using two audio digitizing workstations, we digitized another 165 episodes in about three weeks. The combined collection is now available online: a total of 464 hours of programming, most of which have not been heard since their original air date. The collection represents nearly every episode of the show: only a few tapes went missing over the years or were unrepairable.
The Digital Library of Amateur Radio & Communications is funded by a grant from Amateur Radio Digital Communications (ARDC) to create a free digital library for the radio community, researchers, educators, and students. DLARC invites radio clubs and individuals to submit material in any format. To contribute or ask questions about the project, contact: Kay Savetz at kay@archive.org or on Mastodon at dlarc@mastodon.radio.
Once upon a time, Liz Gotauco fell in love with fairy tales. That is, making videos while retelling them with some quirky twists.
Librarian Liz Gotauco, aka “Cosbrarian” across social media.
By day, Gotauco is a full-time public librarian in Rhode Island. On nights and weekends, she creates content for TikTok, Instagram and YouTube under the name Cosbrarian (a portmanteau of “cosplay” and “librarian”). Gotauco takes a traditional fairy tale or folk tale, writes her own scripts, and films herself telling it — often wearing costumes and using props to make it come alive.
To find the original fairy tales, many of which are in books that are out of print, Gotauco often uses the Internet Archive. She lists her more than 100 stories and sources on her website.
“It has been invaluable to me to have an easily accessible resource like the Internet Archive at my fingertips,” Gotauco said. “Sometimes I’m writing my content on the fly—but I don’t want my time constraints to compromise my research. Being able to quickly find a reputable source is such a gift, especially to those of us without academic library access.”
In her saucy, darker, and wilder versions of fairy tales for adult audiences, she weaves in humor and commentary. Gotauco likes to feature lesser-known folklore from a variety of cultures for her series, “Around the World in 80 Folk Tales.” Many of these books are old and no longer on library shelves, but she often finds them at the Internet Archive.
“I was blown away that there was so much in the collection,” she said. Gotauco recently found Inuit folk tales and stories from Latin America that she adapted. Her online audience also requests stories from their home countries, and she is intentional about representation in her work.
Once she discovers books in the Archive, Gotauco said she then sometimes buys a copy to add to her collection at home.
Gotauco started as a freelance content creator in 2021. It has almost become a part-time job, as she produces about two videos a week, which are available for free to viewers.
“The responses I’m most happy to get are when I make people laugh,” she said. “Especially since I started during the early pandemic, some people were like, “Wow, I just really needed to smile today and this did it for me.’”
Gotauco is busier these days, but plans to continue producing new content and hopes material continues to be available through the Archive to support her endeavor.
“Fairy tales have always been a part of my life. It’s been nice to indulge in that interest and find other people whose interests are the same,” said Gotauco, who has enjoyed tapping into her love for theater. “It’s partially a performance piece, as well as storytelling. I’ve been able to merge my two personas: the theater kid Liz and librarian Liz.”
Hundreds of people from all over the world gathered together on January 25 to honor the thousands of movies, plays, books, poems and songs that recently entered the U.S. public domain.
Steamboat Willie, Walt Disney’s 1928 animated film featuring Mickey Mouse, had top billing at the virtual event. Literature now free from restriction for reuse includes Orlando by Virginia Woolf and Tarzan Lord of the Jungle by Edgar R. Burroughs. Sound recordings from 1923 (released on a different schedule) joined the public domain such as ”Down Hearted Blues” by Bessie Smith and ”Who’s Sorry Now” by Isham Jones Orchestra.
WATCH RECORDING:
“There’s so much to rediscover and to celebrate,” said Jennifer Jenkins, director of the Center for the Study of the Public Domain at Duke Law School. For example, the release of The Great Gatsby into the public domain in 2021 inspired a creative flurry — new versions of the novel from the perspective of different characters, a prequel telling the backstory of Nick Caraway, a young adult remix, and song. “From the serious to the creative, to the whimsical to the wacky, these are all the great things we can do…now that [these works] are in the public domain and free to copy, to share, to digitize and to build upon without permission or fee.”
The winning film from the Public Domain Day 2024 Remix Contest was shown as well: “Sick on New Year’s,” by Ty Cummings. Every year since 2021, this contest has invited artists to remix works from its collection to showcase new and creative uses of public domain materials. Fifty films were submitted to this year’s competition, according to Amir Esfahania, artist in residence at the Archive. Learn more about the finalists or watch all the submissions in our recent blog post.
Advocacy
“Celebrating the public domain is not just about vintage references and period-appropriate clothing. It’s about understanding history to inform the present day,” said Lila Bailey, Internet Archive senior policy counsel and co-host of the virtual festivities. “We think there should be time set aside every year to celebrate the immense riches that free and open culture provides to everyone.”
While federal holiday recognition (like MLK Day or Presidents’ Day) for the public domain is unlikely, there was a discussion of an advocacy campaign for establishment of a commemorative Public Domain Day (more along the lines of National Data Privacy Day or National Whistleblowers Day).
“It only requires a simple resolution in the Senate with high chances of recognition,” said Amanda Levendowski, director of Georgetown Law School’s Intellectual Property and Information Policy Clinic. “Prospects for passage are way better than possible. About 80 percent of proposals are passed — and maybe next year, Public Domain Day will be among them.”
Experts said a successful drive for the designation will require a collaborative effort. A kickoff event will be held February 29 in New York City, hosted by Library Futures, executive director Jennie-Rose Halperin announced.
AI and the Public Domain
The online program also featured a panel discussion on generative artificial intelligence, copyright and artist expression. Experts weighed in on just what should be the copyright status of the outputs of generative AI.
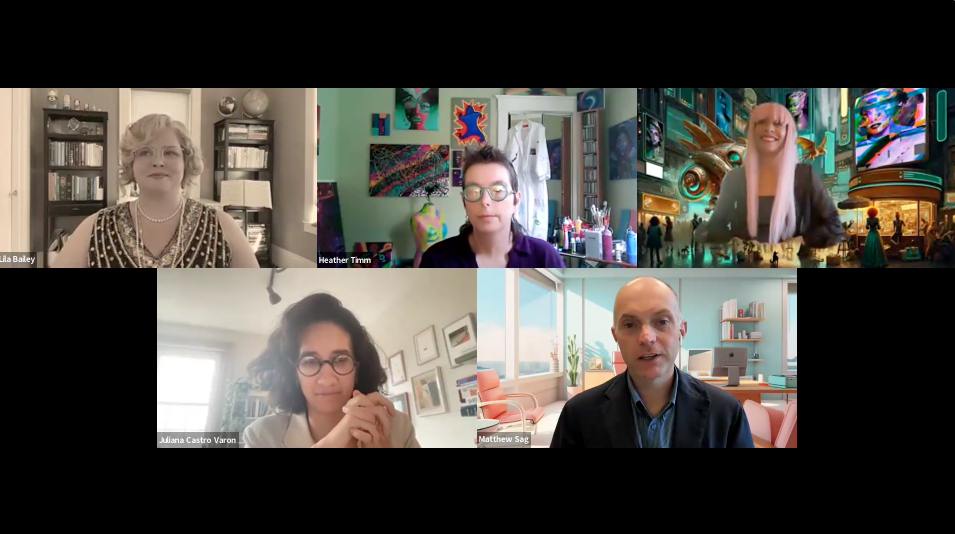
Panelists (clockwise from top left): Lila Bailey (Internet Archive), Heather Timm (artist), Maxximillian (artist), Matthew Sag (Emory Law), and Juliana Castro Varón (Cita Press).
Now, AI tools can turn text or simple descriptions into images that are genuinely new and often look like exactly the kind of things that people get copyrighted if a human made them, explained Matthew Sag, professor of law, artificial intelligence, machine learning, and data science at Emory University.
“The copyright office is quite clear that to get copyright, you have to have human authorship. So something created entirely by an unsupervised machine is not eligible for copyright,” Sag said, noting that the courts have recently agreed. “The interesting question is what about when humans are using AI as a tool and directing the output. This is where the controversy really is.”
On the panel, two artists, Heather Timm and Maxximillian, shared how they both leverage AI in the creative process.
Timm said she started using generative AI in 2021 and thinks the copyright office should cover works that have results from it. She has trained AI models on her own physical work and then created something new collaborating with the machine, as well as conceptualized how to blend different pieces of work in a collage or sculpture.
“I use it almost as a notebook,” Timm said. “If I have a concept or an idea about something on the go, I can immediately prompt that and have it as a placeholder to explore it later.”
As a filmmaker and musician, Maxximillian said she feels passionate about AI and it has saved her time creating animated characters and helping refine her text. “As a professional artist, I rely on copyright to keep viable the works that I produce for clients legally,” said Maxximillian. “It’s important to understand that copyright protection enables the creator to be a steward of that work. The question to consider: Who benefits by denying copyright on AI? I think nobody benefits.”
An open access publisher, Juliana Castro Varón, design director and founder of Cita Press, also addressed the issue. “I believe that AI may pose economic, power, and labor challenges, but I feel very confident that creativity will survive technology,” she said. All books Cita produces are in the public domain for everyone to download. “We are not at all against people using AI for their work, but we continue to hire humans…elevating the work of people is core to our mission.”
***
The event was co-hosted by Internet Archive and Library Futures with support from Creative Commons, Authors Alliance, Public Knowledge, SPARC and Duke Law’s Center for the Study of the Public Domain.
After sifting through a sea of talent and creativity, we are thrilled to present the cinematic achievements of three winners and two honorable mentions in our Public Domain Day 2024 Remix Contest. These winning entries not only captivated our imaginations, but also showcased the immense power of remixing, reimagining, and breathing new life into public domain works.
View the winning entries & honorable mentions below. Rick Prelinger, noted film archivist, helped judge the competition and offers why each film was selected for recognition.
Found-footage filmmaking is all about taking material that might have almost-sacred status and, well, bringing it back down to earth. We find this film worthy of our first prize because of its irreverent humor and skilled editing, its playful predictions of the future, and because it points to the limitless opportunities that a constantly-refreshed public domain offers makers in all media.
Second Place: “Keaton and Kaufman: The Cameramen” by Max Teeth
This film brings together two characters who will be familiar to people who love films, characters that lived and worked very far away from one another and did deeply different work, but might perhaps have more in common with one another than we might think. We see it as a poetic piece, a loving tribute to some of the people who put the motion in motion pictures.
Third Place: “Just Like a Hollywood Star” by Timothy Johnson
Our 3rd prize winner is a rich montage of sound and picture, focusing on images that model beauty, fitness, posture, proper behavior, and the laws of physics. We like this film’s uninhibited reach and its draw from wildly disparate material, often pretty predictable, to produce an unpredictable result.
Honorable Mention, Historical Perspective: “A Member of the Family” by Lizzy Tolentino
Combining government-produced films, family home movies and an unusual sponsored film by a world-famous company, this filmmaker makes a chilling statement about the gap between the promise of our society and the reality of 20th-century history. The public domain is a record of both proud achievements and disturbing histories, and we feel this film exemplified the potential of the public domain to reveal histories that some might prefer to be kept silent.
Honorable Mention, Quirkiest Film: “Domain” by Cullen J. Sanchez
Sometimes you just have to recognize the unusual. But this unusual film makes a critical point about the public domain — that WE are the public domain, and the public domain is us. Take it away! “It’s us. It’s all of us.”
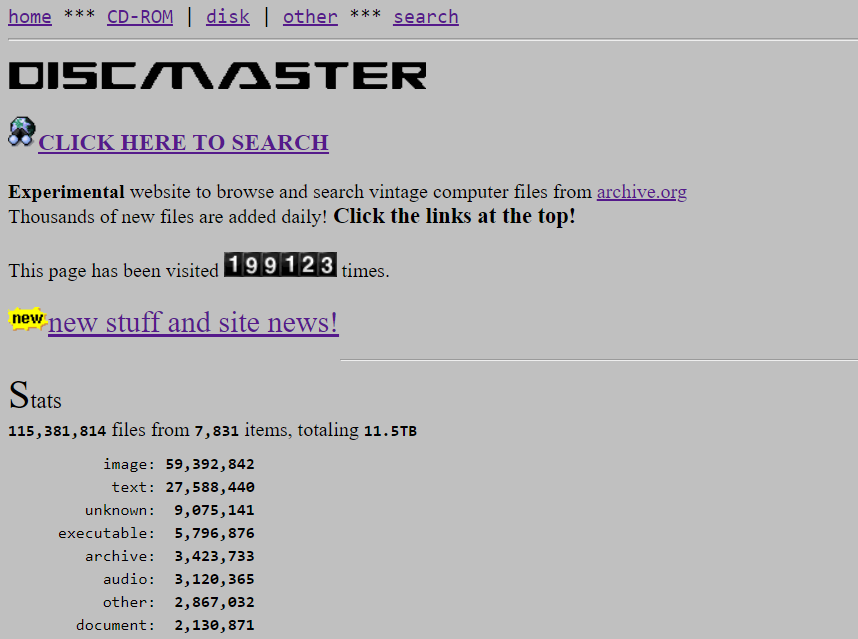
In October of 2022, the DISCMASTER site arrived, providing amazing semantic search of thousands of shareware and compilation CD-ROMs at the Internet Archive. In the entry written on the blog back then, the advantages and features of this site were pretty well enumerated.
Unfortunately, the site went down in June of 2023, due to a number of factors, the most pressing of which was a need to switch hosting and administration duties. (It is not run by Internet Archive and is not hosted at Internet Archive’s datacenters.)
However, DISCMASTER HAS RETURNED!
Thanks to a set of generous donors and the efforts of multiple volunteers, the site is back running with all the data and functionality it had in its previous incarnation.
The previous blog entry has fuller details on the meaning of this site and the many uses it has for computer and internet history. All hail DISCMASTER!