In August 2022, the UC Berkeley Library and Internet Archive were awarded a grant from the National Endowment for the Humanities (NEH) to study legal and ethical issues in cross-border text and data mining (TDM).
The project, entitled Legal Literacies for Text Data Mining – Cross-Border (“LLTDM-X”), supported research and analysis to address law and policy issues faced by U.S. digital humanities practitioners whose text data mining research and practice intersects with foreign-held or licensed content, or involves international research collaborations.
LLTDM-X is now complete, resulting in the publication of an instructive case study for researchers and white paper. Both resources are explained in greater detail below.
Project Origins
LLTDM-X built upon the previous NEH-sponsored institute, Building Legal Literacies for Text Data Mining. That institute provided training, guidance, and strategies to digital humanities TDM researchers on navigating legal literacies for text data mining (including copyright, contracts, privacy, and ethics) within a U.S. context.
A common challenge highlighted during the institute was the fact that TDM practitioners encounter expanding and increasingly complex cross-border legal problems. These include situations in which: (i) the materials they want to mine are housed in a foreign jurisdiction, or are otherwise subject to foreign database licensing or laws; (ii) the human subjects they are studying or who created the underlying content reside in another country; or, (iii) the colleagues with whom they are collaborating reside abroad, yielding uncertainty about which country’s laws, agreements, and policies apply.
Project Design
LLTDM-X was designed to identify and better understand the cross-border issues that digital humanities TDM practitioners face, with the aim of using these issues to inform prospective research and education. Secondarily, it was hoped that LLTDM-X would also suggest preliminary guidance to include in future educational materials. In early 2023, the project hosted a series of three online round tables with U.S.-based cross-border TDM practitioners and law and ethics experts from six countries.
The round table conversations were structured to illustrate the empirical issues that researchers face, and also for the practitioners to benefit from preliminary advice on legal and ethical challenges. Upon the completion of the round tables, the LLTDM-X project team created a hypothetical case study that (i) reflects the observed cross-border LLTDM issues and (ii) contains preliminary analysis to facilitate the development of future instructional materials.
The project team also charged the experts with providing responsive and tailored written feedback to the practitioners about how they might address specific cross-border issues relevant to each of their projects.
Extrapolating from the issues analyzed in the round tables, the practitioners’ statements, and the experts’ written analyses, the Project Team developed a hypothetical case study reflective of “typical” cross-border LLTDM issues that U.S.-based practitioners encounter. The case study provides basic guidance to support U.S. researchers in navigating cross-border TDM issues, while also highlighting questions that would benefit from further research.
The case study examines cross-border copyright, contracts, and privacy & ethics variables across two distinct paradigms: first, a situation where U.S.-based researchers perform all TDM acts in the U.S., and second, a situation where U.S.-based researchers engage with collaborators abroad, or otherwise perform TDM acts in both U.S. and abroad.
The LLTDM-X white paper provides a comprehensive description of the project, including origins and goals, contributors, activities, and outcomes. Of particular note are several project takeaways and recommendations, which the project team hopes will help inform future research and action to support cross-border text data mining. Project takeaways touched on seven key themes:
Uncertainty about cross-border LLTDM issues indeed hinders U.S. TDM researchers, confirming the need for education about cross-border legal issues;
The expansion of education regarding U.S. LLTDM literacies remains essential, and should continue in parallel to cross-border education;
Disparities in national copyright, contracts, and privacy laws may incentivize TDM researcher “forum shopping” and exacerbate research bias;
License agreements (and the concept of “contractual override”) often dominate the overall analysis of cross-border TDM permissibility;
Emerging lawsuits about generative artificial intelligence may impact future understanding of fair use and other research exceptions;
Research is needed into issues of foreign jurisdiction, likelihood of lawsuits in foreign countries, and likelihood of enforcement of foreign judgments in the U.S. However, the overall “risk” of proceeding with cross-border TDM research may remain difficult to quantify; and
Institutional review boards (IRBs) have an opportunity to explore a new role or build partnerships to support researchers engaged in cross-border TDM.
Gratitude & Next Steps
Thank you to the practitioners, experts, project team, and generous funding of the National Endowment for the Humanities for making this project a success.
We aim to broadly share our project outputs to continue helping U.S.-based TDM researchers navigate cross-border LLTDM hurdles. We will continue to speak publicly to educate researchers and the TDM community regarding project takeaways, and to advocate for legal and ethical experts to undertake the essential research questions and begin developing much-needed educational materials. And, we will continue to encourage the integration of LLTDM literacies into digital humanities curricula, to facilitate both domestic and cross-border TDM research.
We are excited to announce that the National Endowment for the Humanities (NEH) has awarded nearly $50,000 through its Digital Humanities Advancement Grant program to UC Berkeley Library and Internet Archive to study legal and ethical issues in cross-border text data mining research. NEH funding for the project, entitled Legal Literacies for Text Data Mining – Cross Border (LLTDM-X), will support research and analysis that addresses law and policy issues faced by U.S. digital humanities practitioners whose text data mining research and practice intersects with foreign-held or licensed content, or involves international research collaborations. LLTDM-X builds upon Building Legal Literacies for Text Data Mining Institute (Building LLTDM), previously funded by NEH. UC Berkeley Library directed BuildingLLTDM, bringing together expert faculty from across the country to train 32 digital humanities researchers on how to navigate law, policy, ethics, and risk within text data mining projects (results and impacts are summarized in the white paper here.)
Why is LLTDM-X needed?
Text data mining, or TDM, is an increasingly essential and widespread research approach. TDM relies on automated techniques and algorithms to extract revelatory information from large sets of unstructured or thinly-structured digital content. These methodologies allow scholars to identify and analyze critical social, scientific, and literary patterns, trends, and relationships across volumes of data that would otherwise be impossible to sift through. While TDM methodologies offer great potential, they also present scholars with nettlesome law and policy challenges that can prevent them from understanding how to move forward with their research. Building LLTDM trained TDM researchers and professionals on essential principles of licensing, privacy law, as well as ethics and other legal literacies —thereby helping them move forward with impactful digital humanities research. Further, digital humanities research in particular is marked by collaboration across institutions and geographical boundaries. Yet, U.S. practitioners encounter increasingly complex cross-border problems and must accordingly consider how they work with internationally-held materials and international collaborators.
How will LLTDM-X help?
Our long-term goal is to design instructional materials and institutes to support digital humanities TDM scholars facing cross-border issues. Through a series of virtual roundtable discussions, and accompanying legal research and analyses, LLTDM-X will surface these cross-border issues and begin to distill preliminary guidance to help scholars in navigating them. After the roundtables, we will work with the law and ethics experts to create instructive case studies that reflect the types of cross-border TDM issues practitioners encountered. Case studies, guidance, and recommendations will be widely-disseminated via an open access report to be published at the completion of the project. And most importantly, these resources will be used to inform our future educational offerings.
The LLTDM-X team is eager to get started. The project is co-directed by Thomas Padilla, Deputy Director, Archiving and Data Services at Internet Archive and Rachael Samberg, who leads UC Berkeley Library’s Office of Scholarly Communication Services. Stacy Reardon, Literatures and Digital Humanities Librarian, and Timothy Vollmer, Scholarly Communication and Copyright Librarian, both at UC Berkeley Library, round out the team.
We would like to thank NEH’s Office of Digital Humanities again for funding this important work. The full press release is available at UC Berkeley Library’s website. We invite you to contact us with any questions.
In this final session of the Internet Archive’s digital humanities expo, Library as Laboratory, attendees heard from scholars in a series of short presentations about their research and how they’re using collections and infrastructure from the Internet Archive for their work.
Speakers:
Forgotten Histories of the Mid-Century Coding Bootcamp, [watch] Kate Miltner (University of Edinburgh)
Japan As They Saw It, [watch] Tom Gally (University of Tokyo)
The Bibliography of Life, [watch] Rod Page (University of Glasgow)
Automated Hashtag Hierarchy Generation Using Community Detection and the Shannon Diversity Index, [watch] Spencer Torene (Thomson Reuters Special Services, LLC)
My Internet Archive Enabled Journey As A Digital Humanities Citizen Scientist, [watch] Jim Salmons
Web and cities: (early internet) geographies through the lenses of the Internet Archive, [watch] Emmanouil Tranos (University of Bristol)
Forgotten Novels of the 19th Century, [watch] Tom Gally (University of Tokyo)
Links shared during the session are available in the series Resource Guide.
WARC Collection Summarization
Sawood Alam (Internet Archive)
Items in the Internet Archive’s Petabox collections of various media types like image, video, audio, book, etc. have rich metadata, representative thumbnails, and interactive hero elements. However, web collections, primarily containing WARC files and their corresponding CDX files, often look opaque. We created an open-source CLI tool called “CDX Summary” [1] to process sorted CDX files and generate reports. These summary reports give insights on various dimensions of CDX records/captures, such as, total number of mementos, number of unique original resources, distribution of various media types and their HTTP status codes, path and query segment counts, temporal spread, and capture frequencies of top TLDs, hosts, and URIs. We also implemented a uniform sampling algorithm to select a given number of random memento URIs (i.e., URI-Ms) with 200 OK HTML responses that can be utilized for quality assurance purposes or as a representative sample for the collection of WARC files. Our tool can generate both comprehensive and brief reports in JSON format as well as human readable textual representation. We ran our tool on a selected set of public web collections in Petabox, stored resulting JSON files in their corresponding collections, and made them accessible publicly (with the hope that they might be useful for researchers). Furthermore, we implemented a custom Web Component that can load CDX Summary report JSON files and render them in interactive HTML representations. Finally, we integrated this Web Component into the collection/item views of the main site of the Internet Archive, so that patrons can access rich and interactive information when they visit a web collection/item in Petabox. We also found our tool useful for crawl operators as it helped us identify numerous issues in some of our crawls that would have otherwise gone unnoticed. [1] https://github.com/internetarchive/cdx-summary/
More Than Words: Fed Chairs’ Communication During Congressional Testimonies
Michelle Alexopoulos (University of Toronto)
Economic policies enacted by the government and its agencies have large impacts on the welfare of businesses and individuals—especially those related to fiscal and monetary policy. Communicating the details of the policies to the public is an important and complex undertaking. Policymakers tasked with the communication not only need to present complicated information in simple and relatable terms, but they also need to be credible and convincing—all the while being at the center of the media’s spotlight. In this briefing, I will discuss recent research on the applications of AI to monetary policy communications, and lessons learned to date. In particular, I will report on my recent ongoing project with researchers at the Bank of Canada that analyzes the effects of emotional cues by the Chairs of the U.S. Federal Reserve on financial markets during congressional testimonies.
While most previous work has mainly focused on the effects of a central bank’s highly scripted messages about its rate decisions delivered by its leader, we use resources from the Internet Archive, CSPAN and copies of testimony transcripts and apply a variety of tools and techniques to study the both the messages and the messengers’ delivery of them. I will review how we apply recent advances in machine learning and big data to construct measures of Federal Reserve Chair’s emotions, expressed via his or her words, voice, and face, as well as discuss challenges encountered and our findings to date. In all, our initial results highlight the salience of the Fed Chair’s emotional cues for shaping market responses to Fed communications. Understanding the effects of non-verbal communication and responses to verbal cues may help policy makers improve upon their communication strategies going forward.
Digging into the (Internet) Archive: Examining the NSFW Model Responsible for the 2018 Tumblr Purge
Renata Barreto (University of California Berkeley)
In December 2018, Tumblr took down massive amounts of LGBTQ content from its platform. Motivated in part by increasing pressures from financial institutions and a newly passed law — SESTA / FOSTA, which made companies liable for sex trafficking online — Tumblr implemented a strict “not safe for work” or NSFW model, whose false positives included images of fully clothed women, handmade and digital art, and other innocuous objects, such as vases. The Archive Team, in conjunction with the Internet Archive, jumped into high gear and began to scrape self-tagged NSFW blogs in the 2 weeks between Tumblr’s announcement of its new policy and its algorithmic operationalization. At the time, Tumblr was considered a safe haven for the LGBTQ community and in 2013 Yahoo! bought Tumblr for 1.1 billion. In the aftermath of the so-called “Tumblr purge,” Tumblr lost its main user base and, as of 2019, was valued at 3 million. This paper digs into a slice of the 90 TB of data saved by the Archive Team. This is a unique opportunity to peek under the hood of Yahoo’s open_nsfw model, which experts believe was used in the Tumblr purge, and examine the distribution of false positives on the Archive Team dataset. Specifically, we run the open_nsfw model on our dataset and use the t-SNE algorithm to project the similarities across images on 3D space.
Japan As They Saw It (video)
Tom Gally (University of Tokyo)
“Japan As They Saw It” is a collection of descriptions of Japan by American and British visitors in the 1850s and later. Japan had been closed to outsiders for more than two centuries, and there was much curiosity in the West about this newly accessible country. The excerpts are grouped by category—Land, People, Culture, etc.—and each excerpt is linked to the book where it first appeared at the Internet Archive. “Japan As They Saw It” can be read online, or it can be downloaded as a free ebook.
Forgotten Novels of the 19th Century (video)
Tom Gally (University of Tokyo)
Novels were the binge-watched television, the hit podcasts of the 19th century—immersive, addictive, commercial—and they were produced and consumed in huge numbers. But many novels of that era have slipped through the cracks of literary memory. “Forgotten Novels of the 19th Century” is a list of fifty of those neglected novels, all waiting to be discovered and read for free at the Internet Archive.
Forgotten Histories of the Mid-Century Coding Bootcamp
Kate Miltner (University of Edinburgh)
Over the past 10 years, Americans have been exhorted to “learn to code” in order to solve a series of entrenched social issues: the tech “skills gap”, the looming threat of AI and automation, social mobility, and the underrepresentation of women and people of color in the tech industry. In response to this widespread discourse, an entire industry of short-term intensive training courses– otherwise known as coding bootcamps– have sprung up across the US, bringing in hundreds of millions of dollars in revenue a year and training tens of thousands of people. Coding bootcamps have been framed as a novel kind of institution that is equipped to solve contemporary problems. However, materials from the Internet Archive show us that, in fact, a similar discourse about computer programming and similar organizations called EDP schools existed over 70 years ago. This talk will showcase materials from the Ted Nelson Archive and the Computerworld archive to showcase how lessons from the past can inform the present.
The Bibliography of Life
Roderic Page (University of Glasgow)
The “bibliography of life” is the aspiration of making all the taxonomic literature available so that for every species on the planet we can find its original description, as well as track how our knowledge of those species has changed over time. By combining content from the Internet Archive and the Wayback Machine with information in Wikidata we can make 100’s of thousands of taxonomic publications discoverable, and many of these can also be freely read via the Internet Archive. This presentation will outline this project, how it relates to efforts such as the Biodiversity Heritage Library, and highlight some tools such as Wikicite Search and ALEC to help export this content.
Automatic scanning with an Internet Archive TT scanner (video)
Art Rhyno (University of Windsor)
The University of Windsor has set up a mechanism for automatic scanning with an Internet Archive TT scanner, used for the library’s Major Papers collection.
Automated Hashtag Hierarchy Generation Using Community Detection and the Shannon Diversity Index
Spencer Torene (Thomson Reuters Special Services, LLC)
Developing semantic hierarchies from user-created hashtags in social media can provide useful organizational structure to large volumes of data. However, construction of these hierarchies is difficult using established ontologies (e.g. WordNet) due to the differences in the semantic and pragmatic use of words vs. hashtags in social media. While alternative construction methods based on hashtag frequency are relatively straightforward, these methods can be susceptible to the dynamic nature of social media, such as hashtags associated with surges in popularity. We drew inspiration from the ecologically-based Shannon Diversity Index (SDI) to create a more representative and resilient method of semantic hierarchy construction that relies upon graph-based community detection and a novel, entropy-based ensemble diversity index (EDI) score. The EDI quantifies the contextual diversity of each hashtag, resulting in thousands of semantically-related groups of hashtags organized along a general-to-specific spectrum. Through an application of EDI to social media data (Twitter) and a comparison of our results to prior approaches, we demonstrate our method’s ability to create semantically consistent hierarchies that can be flexibly applied and adapted to a range of use cases.
Web and cities: (early internet) geographies through the lenses of the Internet Archive
Emmanouil Tranos (University of Bristol)
While geographers first turned their focus on the internet 25 years ago, the wealth of data that the Internet Archive preserves and offers remains at large unexplored, especially for large projects in terms of scope and geographical scale. However, there is hardly any other data source that depicts the evolution of our interaction with the digital and, importantly, the spatial footprint of this interaction better than the Internet Archive. Therefore, the last few years we have been using extensively data from the Internet Archive in order to understand the geography and the evolution of the creation of online content and their interrelation with cities and spatial structure. Specifically, we have worked with The British Library and utilised the JISC UK Web Domain Dataset (1996-2013)1 for a number of projects in order to (i) explore whether the availability of online content of local interest can attract individuals online, (ii) assess how the early engagement with web tools can affect future productivity, (iii) map the evolution of economic clusters, and (iv) predict interregional trade flows. The Internet Archive helps us not only to map the evolution and the geography of the engagement with the internet especially at its early stages and, therefore, draw important lessons regarding new future technologies, but also to understand economic activities that take place within and between cities. 1http://data.webarchive.org.uk/opendata/ukwa.ds.2/
At a recent webinar hosted by the Internet Archive, leaders from the Biodiversity Heritage Library (BHL) shared how its massive open access digital collection documenting life on the planet is an invaluable resource of use to scientists and ordinary citizens.
“The BHL is a global consortium of the leading natural history museums, botanical gardens, and research institutions — big and small— from all over the world. Working together and in partnership with the Internet Archive, these libraries have digitized more than 60 million pages of scientific literature available to the public”, said Chris Freeland, director of Open Libraries and moderator of the event.
Watch session recording:
Established in 2006 with a commitment to inspiring discovery through free access to biodiversity knowledge, BHL has 19 members and 22 affiliates, plus 100 worldwide partners contributing data. The BHL has content dating back nearly 600 years alongside current literature that, when liberated from the print page, holds immense promise for advancing science and solving today’s pressing problems of climate change and the loss of biodiversity.
Martin Kalfatovic, BHL program director and associate director of the Smithsonian Libraries and Archives, noted in his presentation that Charles Darwin and colleagues famously said “the cultivation of natural science cannot be efficiently carried on without reference to an extensive library.”
“Today, the Biodiversity Heritage Library is creating this global, accessible open library of literature that will help scientists, taxonomists, environmentalists—a host of people working with our planet—to actually have ready access to these collections,” Kalfatovic said. BHL’s mission is to improve research methodology by working with its partner libraries and the broader biodiversity and bioinformatics community. Each month, BHL draws about 142,000 visitors and 12 million users overall.
“The outlook for the planet is challenging. By unlocking this historic data [in the Biodiversity Heritage Library], we can find out where we’ve been over time to find out more about where we need to be in the future.”
Martin Kalfatovic, program director, Biodiversity Heritage Library
Most of the BHL’s materials are from collections in the global north, primarily in large, well-funded institutions. Digitizing these collections helps level the playing field, providing researchers in all parts of the world equal access to vital content.
The vast collection includes species descriptions, distribution records, climate records, history of scientific discovery, information on extinct species, and records of scientific distributions of where species live. To date, BHL has made over 176,000 titles and 281,000 volumes available. Through a partnership with the Global Names Architecture project, more than 243 million instances of taxonomic (Latin) names have been found in BHL content.
Kalfatovic underscored the value of BHL content in understanding the environment in the wake of recent troubling news from the Sixth Assessment Report (AR6) published by the Intergovernmental Panel on Climate Change about the impact of the earth’s warming.
“The outlook for the planet is challenging,” he said. “By unlocking this historic data, we can find out where we’ve been over time to find out more about where we need to be in the future.”
JJ Dearborn, BHL data manager, discussed how digitization transforms physical books into digital objects that can be shared with “anyone, at any time, anywhere.” She describes the Wikimedia ecosystem as “fertile ground for open access experimentation,” crediting the organization with giving BHL the ability to reach new audiences and transform its data into 5-star linked open data. “Dark data” that is locked up in legacy formats, JP2s, and OCR text are sources of valuable checklist, species occurrence, and event sampling data that the larger biodiversity community can use to improve humanity’s collective ability to monitor biodiversity loss and the destructive impacts of climate change, at scale.
The majority of the world’s data today is siloed, unstructured, and unused, Dearborn explained. This “dark data” “represents an untapped resource that could really transform human understanding if it could be truly utilized,” she said. “It might represent a gestalt leap for humanity.”
The event was the fifth in a series of six sessions highlighting how researchers in the humanities use the Internet Archive. The final session of the Library as Laboratory series will be a series of lightning talks on May 11 at 11am PT / 2pm ET—register now!
Watching a single episode of the evening news can be informative. Tracking trends in broadcasts over time can be fascinating.
The Internet Archive has preserved nearly 3 million hours of U.S. local and national TV news shows and made the material open to researchers for exploration and non-consumptive computational analysis. At a webinar April 13, TV News Archive experts shared how they’ve curated the massive collection and leveraged technology so scholars, journalists and the general public can make use of the vast repository.
Roger Macdonald, founder of the TV News Archive, and Kalev Leetaru, collaborating data scientist and GDELT Project founder, spoke at the session. Chris Freeland, director of Open Libraries, served as moderator and Internet Archive founder Brewster Kahle offered opening remarks.
Watch video
“Growing up in the television age, [television] is such an influential, important medium—persuasive, yet not something you can really quote,” Kahle said. “We wanted to make it so that you could quote, compare and contrast.”
The Internet Archive built on the work of the Vanderbilt Television Archive, and the UCLA Library Broadcast NewsScape to give the public a broader “macro view,” said Kahle. The trends seen in at-scale computational analyses of news broadcasts can be used to understand the bigger picture of what is happening in the world and the lenses through which we see the world around us.
In 2012, with donations from individuals and philanthropies such as the Knight Foundation, the Archive started repurposing the closed captioning data stream required of all U.S. broadcasters into a search index. “This simple approach transformed the antiquated experience of searching for specific topics within video,” said Macdonald, who helped lead the effort. “The TV caption search enabled discovery at internet speed with the ability to simultaneously search millions of programs and have your results plotted over time, down to individual broadcasters and programs.”
“[Television] is such an influential, important medium—persuasive, yet not something you can really quote. We wanted to make it so that you could quote, compare and contrast.”
Brewster Kahle, Internet Archive
Scholars and journalists were quick to embrace this opportunity, but the team kept experimenting with deeper indexing. Techniques like audio fingerprinting, Optical Character Recognition (OCR) and Computer Vision made it possible to capture visual elements of the news and improve access, Macdonald said.
Sub-collections of political leaders’ speeches and interviews have been created, including an extensive Donald Trump Archive. Some of the Archive’s most productive advances have come from collaborating with outsiders who have requested more access to the collection than is available through the public interface, Macdonald said. With appropriate restrictions to maintain respect for broadcasters and distribution platforms, the Archive has worked with select scientists and journalists as partners to use data in the collection for more complex analyses.
Treating television as data
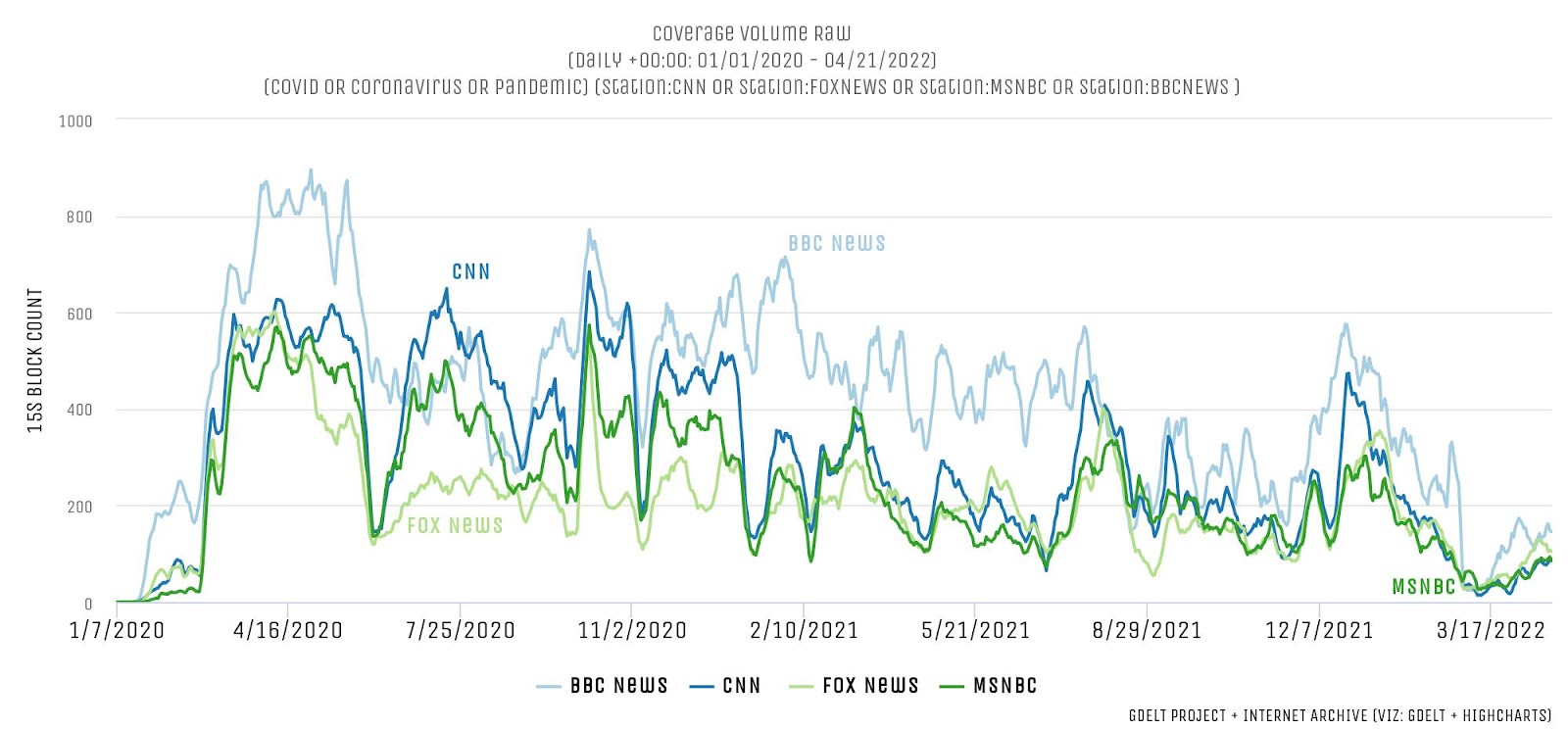
Treating television news as data creates vast opportunities for computational analysis, said Leetaru. Researchers can track word frequency use in the news and how that has changed over time. For instance, it’s possible to look at mentions of COVID-related words across selected news programs and see when it surged and leveled off with each wave before plummeting downward, as shown in the graph below.
From television news to digitized books and periodicals, dozens of projects rely on the collections available at archive.org for computational and bibliographic research across a large digital corpus. Data scientists or anyone with questions about the TV News Archives, can contact info@archive.org.
Up Next
This webinar was the fourth a series of six sessions highlighting how researchers in the humanities use the Internet Archive. The next will be about Analyzing Biodiversity Literature at Scale on April 27. Register here.
Laura Gibbs and Helen Nde share a passion for African folktales. They are both active researchers and bloggers on the subject who rely on the Internet Archive’s extensive collection in their work.
In the third of a series of webinars highlighting how researchers in the humanities use the Internet Archive, Gibbs and Nde spoke on March 30 about how they use the online library and contribute to its resources.
Watch now:
Gibbs was teaching at the University of Oklahoma in the spring of 2020 when the campus library shut down due to the pandemic. “That’s when I learned about controlled digital lending at the Internet Archive and that changed everything for me. I hadn’t realized how extensive the materials were,” said Gibbs, who was trained as a folklorist. She retired last May and began a project of cross-referencing her bookshelves of African and African-American folktales to see how many were available at the Internet Archive. Being able to check out one digital title at a time through controlled digital lending (CDL) opened up new possibilities for her research.
“It was just mind boggling to me and so exciting,” she said of discovering the online library. “I want to be a provocation to get other people to go read, do their own writing and thinking from books that we can all access. That’s what the Internet Archive has miraculously done.”
A Reader’s Guide to African Folktales at the Internet Archive by Laura Gibbs. Now available.
Gibbs said it has been very helpful to use the search function using the title of a book, name of an illustrator or some other kind of detail. With an account, the user can see the search results and borrow the digital book through CDL. “It’s all super easy to do. And if you’re like me and weren’t aware of the amazing resources available through controlled digital lending, now is the time to create your account at the Internet Archive,” Gibbs said.
Every day, Gibbs blogs about a different book and rewrites a 100-word “tiny-tale” synopsis. In less than a year, she compiled A Reader’s Guide to African Folktales at the Internet Archive, a curated bibliography of hundreds of folktale books that she has shared with the public through the Internet Archive. Some are in the public domain, but many are later works and only available for lending one copy at a time through CDL.
In her work, Nde explores mythological folklore from the African continent and is dedicated to preserving the storyteller traditions of African peoples, which is largely oral culture. Nde maintains the Mythological Africans website where she hosts storytelling sessions, modern lectures, and posts essays.
“[The Internet Archive] is an amazing resource of information online, which is readily available, and really goes to dispel the notion that there is no uniformity of folklore from the African continent,” Nde said. “Through Mythological Africans, I am able to share these stories and make these cultures come alive as much as possible.”
As an immigrant in the United States from Cameroon, Nde began to research the topic of African folklore because she was curious about exploring her background and identity. She said she found a community and a creative outlet for examining storytelling, poetry, dance and folktales. Nde said examining Gibb’s works gave her an opportunity to reconnect with some of the favorite books from her childhood. She’s also discovered reference books through the Internet Archive collection that have been helpful. Nde is active on social media (Twitter.com/mythicafricans) and has a YouTube channel on African mythology. She recently collaborated on a project with PBS highlighting the folklore behind an evil entity called the Adze, which can take the form of a firefly.
The presenters said when citing material from the Internet Archive, not only can they link to a source, a blog or an academic article, they can link to the specific page number in that source. This gives credit to the author and also access to that story for anybody who wants to read it for themselves.
The next webinar in the series, Television as Data: Opening TV News for Deep Analysis and New Forms of Interactive Search, on April 13 will feature Roger MacDonald, Founder of the TV News Archive and Kalev Leetaru, Data Scientist at GDELT. Register now.
From projects that compare public health misinformation to feminist media tactics, the Internet Archive is providing researchers with vital data to assist them with archival web collection analysis.
In the second of a series of webinars highlighting how the Internet Archive supports digital humanities research, five scholars shared their experience with the Archives Unleashed Project on March 16.
Archives Unleashed was established in 2017 with funding from the Andrew Mellon Foundation. The team developed open-source, user-friendly Archives Research Compute Hub (ARCH) tools to allow researchers to conduct scalable analyses, as well as resources and tutorials. An effort to build and engage a community of users led to a partnership with the Internet Archive.
A cohort program was launched in 2020 to provide researchers with mentoring and technical expertise to conduct analyses of archival web material on a variety of topics. The webinar speakers provided an overview of their innovative projects:
WATCH: Crisis communication during the COVID-19 pandemic was the focus of an investigation by Tim Ribaric and researchers at Brock University in Ontario, Canada. Using fully extracted texts from websites of municipal governments, community organizations and others, the team compared how well information was conveyed to the public. The analysis assessed four facets of communication: resilience, education, trust and engagement. The data set was used to teach senior communication students at the university about digital scholarship, Ribaric said, and the team is now finalizing a manuscript with the results of the analysis.
WATCH: Shana MacDonald from the University of Waterloo in Ontario Canada applied archival web data to do a comparative analysis of feminist media tactics over time. The project mapped the presence of feminist key concepts and terms to better understand who is using them and why. The researchers worked with the Archives Unleashed team to capture information from relevant websites, write code and analyze the data. They found the top three terms used were “media, culture and community,” MacDonald said, providing an interesting snapshot into trends with language and feminism.
WATCH: At the University of Siegen, a public research university in Germany, researchers examined the online commenting system on new websites from 1996 to 2021. Online media outlets started to remove commenting systems in about 2015 and the project was focused on this time of disruption. With the rise of Web 2.0 and social media, commenting is becoming increasingly toxic and taking away from the main text, said the university’s Robert Jansma. Technology providers have begun to offer ways to stem the tide of these unwanted comments and, in general, the team discovered comments are not very well preserved.
WATCH: Web archives of the COVID-19 crisis through the IIPC Novel Coronavirus dataset was analyzed by a team at the University of Luxembourg led by Valérie Schafer. As a shared, unforeseen, global event, the researchers found vast institutional differences in web archiving. Looking at tracking systems from the U.S. Library of Congress, European libraries and others, the team did not see much overlap in national collections and are in the midst of finalizing the project’s results.
WATCH: Researchers at Arizona State University worked with ARCH tools to compare health misinformation circulating during the HIV/AIDS crisis and COVID-19 pandemic. ASU’s Shawn Walker did a text analysis to link patterns and examine how gaps in understanding of health crises can fuel misinformation. In both cases, the community was trying to make sense of information in an uncertain environment. However, the government conspiracy theories rampant in the COVID-19 pandemic were not part of the dialogue during the HIV/AIDS crisis, Walker said.
Archives Unleashed is accepting applications for its 2022-23 cohort research teams. For more information, view the application & instructions: https://archivesunleashed.org/cohorts2022-2023/.
Up next in the Library as Laboratory series:
The next webinar in the series, Hundreds of Books, Thousands of Stories: A Guide to the Internet Archive’s African Folktales will be held March 30. Register now
For scholars, especially those in the humanities, the library is their laboratory. Published works and manuscripts are their materials of science. Today, to do meaningful research, that also means having access to modern datasets that facilitate data mining and machine learning.
On March 2, the Internet Archive launched a new series of webinars highlighting its efforts to support data-intensive scholarship and digital humanities projects. The first session focused on the methods and techniques available for analyzing web archives at scale.
Watch the session recording now:
“If we can have collections of cultural materials that are useful in ways that are easy to use — still respectful of rights holders — then we can start to get a bigger idea of what’s going on in the media ecosystem,” said Internet Archive Founder Brewster Kahle.
Just what can be done with billions of archived web pages? The possibilities are endless.
Jefferson Bailey, Internet Archive’s Director of Web Archiving & Data Services, and Helge Holzmann, Web Data Engineer, shared some of the technical issues libraries should consider and tools available to make large amounts of digital content available to the public.
The Internet Archive gathers information from the web through different methods including global and domain crawling, data partnerships and curation services. It preserves different types of content (text, code, audio-visual) in a variety of formats.
Social scientists, data analysts, historians and literary scholars make requests for data from the web archive for computational use in their research. Institutions use its service to build small and large collections for a range of purposes. Sometimes the projects can be complex and it can be a challenge to wrangle the volume of data, said Bailey.
The Internet Archive has worked on a project reviewing changes to the content of 800,000 corporate home pages since 1996. It has also done data mining for a language analysis that did custom extractions for Icelandic, Norwegian and Irish translation.
Transforming data into useful information requires data engineering. As librarians consider how to respond to inquiries for data, they should look at their tech resources, workflow and capacity. While more complicated to produce, the potential has expanded given the size, scale and longitudinal analysis that can be done.
“We are getting more and more computational use data requests each year,” Bailey said. “If librarians, archivists, cultural heritage custodians haven’t gotten these requests yet, they will be getting them soon.”
Up next in the Library as Laboratory series:
The next webinar in the series will be held March 16, and will highlight five innovative web archiving research projects from the Archives Unleashed Cohort Program. Register now.
From web archives to television news to digitized books & periodicals, dozens of projects rely on the collections available at archive.org for computational & bibliographic research across a large digital corpus. This series will feature six sessions highlighting the innovative scholars that are using Internet Archive collections, services and APIs to support data-driven projects in the humanities and beyond.
Many thanks to the program advisory group:
Dan Cohen, Vice Provost for Information Collaboration and Dean, University Library and Professor of History, Northeastern University
Makiba Foster, Library Regional Manager for the African American Research Library and Cultural Center, Broward County Library
Mike Furlough, Executive Director, HathiTrust
Harriett Green, Associate University Librarian for Digital Scholarship and Technology Services, Washington University Libraries
Session Details:
March 2 @ 11am PT / 2pm ET
Supporting Computational Use of Web Collections Jefferson Bailey, Internet Archive Helge Holzmann, Internet Archive
What can you do with billions of archived web pages? In our kickoff session, Jefferson Bailey, Internet Archive’s Director of Web Archiving & Data Services, and Helge Holzmann, Web Data Engineer, will take attendees on a tour of the methods and techniques available for analyzing web archives at scale.
Applications of Web Archive Research with the Archives Unleashed Cohort Program
Launched in 2020, the Cohort program is engaging with researchers in a year-long collaboration and mentorship with the Archives Unleashed Project and the Internet Archive, to support web archival research.
Web archives provide a rich resource for exploration and discovery! As such, this session will feature the program’s inaugural research teams, who will discuss the innovative ways they are exploring web archival collections to tackle interdisciplinary topics and methodologies. Projects from the Cohort program include:
AWAC2 — Analysing Web Archives of the COVID Crisis through the IIPC Novel Coronavirus dataset—Valérie Schafer (University of Luxembourg)
Everything Old is New Again: A Comparative Analysis of Feminist Media Tactics between the 2nd- to 4th Waves—Shana MacDonald (University of Waterloo)
Mapping and tracking the development of online commenting systems on news websites between 1996–2021—Robert Jansma (University of Siegen)
Crisis Communication in the Niagara Region during the COVID-19 Pandemic—Tim Ribaric (Brock University)
Viral health misinformation from Geocities to COVID-19—Shawn Walker (Arizona State University)
UPDATE: Quinn Dombrowski from Saving Ukrainian Cultural Heritage Online (SUCHO) will give an introductory presentation about the team of volunteers racing to archive Ukrainian digital cultural heritage.
Hundreds of Books, Thousands of Stories: A Guide to the Internet Archive’s African Folktales Laura Gibbs, Educator, writer & bibliographer Helen Nde, Historian & writer
Join educator & bibliographer Laura Gibbs and researcher, writer & artist Helen Nde as they give attendees a guided tour of the African folktales in the Internet Archive’s collection. Laura will share her favorite search tips for exploring the treasure trove of books at the Internet Archive, and how to share the treasures you find with colleagues, students, and fellow readers in the form of a digital bibliography guide. Helen will share how she uses the Internet Archive’s collections to tell the stories of individuals and cultures that aren’t often represented online through her work at Mythological Africans (@MythicAfricans). Helen will explore how she uses technology to continue the African storytelling tradition in spoken form, and she will discuss the impacts on the online communities that she is able to reach.
Television as Data: Opening TV News for Deep Analysis and New Forms of Interactive Search Roger MacDonald, Founder, TV News Archive Kalev Leetaru, Data Scientist, GDELT
How can treating television news as data create fundamentally new kinds of opportunities for both computational analysis of influential societal narratives and the creation of new kinds of interactive search tools? How could derived (non-consumptive) metadata be open-access and respectful of content creator concerns? How might specific segments be contextualized by linking them to related analysis, like professional journalist fact checking? How can tools like OCR, AI language analysis and knowledge graphs generate terabytes of annotations making it possible to search television news in powerful new ways?
For nearly a decade, the Internet Archive’s TV News Archive has enabled closed captioning keyword search of a growing archive that today spans nearly three million hours of U.S. local and national TV news (2,239,000+ individual shows) from mid-2009 to the present. This public interest library is dedicated to facilitating journalists, scholars, and the public to compare, contrast, cite, and borrow specific portions of the collection. Using a range of algorithmic approaches, users are moving beyond simple captioning search towards rich analysis of the visual side of television news. In this session, Roger Macdonald, founder of the TV News Archive, and Kalev Leetaru, collaborating data scientist and GDELT Project founder, will report on experiments applying full-screen OCR, machine vision, speech-to-text and natural language processing to assist exploration, analyses and data-visualization of this vast television repository. They will survey the resulting open metadata datasets and demonstrate the public search tools and APIs they’ve created that enable powerful new forms of interactive search of television news and what it looks like to ask questions of more than a decade of television news.
Analyzing Biodiversity Literature at Scale Martin R. Kalfatovic, Smithsonian Library & Archives JJ Dearborn, Biodiversity Heritage Library Data Manager
Imagine the great library of life, the library that Charles Darwin said was necessary for the “cultivation of natural science” (1847). And imagine that this library is not just hundreds of thousands of books printed from 1500 to the present, but also the data contained in those books that represents all that we know about life on our planet. That library is the Biodiversity Heritage Library (BHL) The Internet Archive has provided an invaluable platform for the BHL to liberate taxonomic names, species descriptions, habitat description and much more. Connecting and harnessing the disparate data from over five-centuries is now BHL’s grand challenge. The unstructured textual data generated at the point of digitization holds immense untapped potential. Tim Berners-Lee provided the world with a semantic roadmap to address this global deluge of dark data and Wikidata is now executing on his vision. As we speak, BHL’s data is undergoing rapid transformation from legacy formats into linked open data, fulfilling the promise to evaporate data silos and foster bioliteracy for all humankind.
Martin R. Kalfatovic (BHL Program Director and Associate Director, Smithsonian Library and Archives) and JJ Dearborn (BHL Data Manager) will explore how books in BHL become data for the larger biodiversity community.
Watch the video:
May 11 @ 11am PT / 2pm ET
Lightning Talks In this final session of the Internet Archive’s digital humanities expo, Library as Laboratory, you’ll hear from scholars in a series of short presentations about their research and how they’re using collections and infrastructure from the Internet Archive for their work.
Watch the session recording:
Talks include:
Forgotten Histories of the Mid-Century Coding Bootcamp, [watch] Kate Miltner (University of Edinburgh)
Japan As They Saw It, [watch] Tom Gally (University of Tokyo)
The Bibliography of Life, [watch] Rod Page (University of Glasgow)
Automated Hashtag Hierarchy Generation Using Community Detection and the Shannon Diversity Index, [watch] Spencer Torene (Thomson Reuters Special Services, LLC)
My Internet Archive Enabled Journey As A Digital Humanities Citizen Scientist, [watch] Jim Salmons
Web and cities: (early internet) geographies through the lenses of the Internet Archive, [watch] Emmanouil Tranos (University of Bristol)
Forgotten Novels of the 19th Century, [watch] Tom Gally (University of Tokyo)