Started in 2017, our Community Webs program has over 175 public libraries and local cultural organizations working to build digital archives documenting the experiences of their communities, especially those patrons often underrepresented in traditional archives. Participating public libraries have created over 1,400 collections documenting local civic life totaling nearly 100 terabytes and tens of millions of individual documents, images, audio/video files, blogs, websites, social media, and more. You can browse many of these collections at the Community Webs website. Participants have also collaborated on digitization efforts to bring minority newspapers online, held public programming and outreach events, and formed local partnerships to help preservation efforts at other mission-aligned organizations. The program has conducted numerous workshops and national symposia to help public librarians gain expertise in digital preservation and cohort members have done dozens of presentations at professional conferences showcasing their work. In the past, Community Webs has received support from the Institute of Museum and Library Services, the Mellon Foundation, the Kahle Austin Foundation, and the National Historical Publications and Records Commission.
We are excited to announce that Community Webs has received $750,000 in funding from The Mellon Foundation to continue expanding the program. The award will allow additional public libraries to join the program and will enable new and existing members to continue their web archiving collection building using our Archive-It service. In addition, the funding will also provide members access to Internet Archive’s new Vault digital preservation service, enabling them to build and preserve collections of any type of digital materials. Lastly, leveraging members’ prior success in local partnerships, Community Webs will now include an “Affiliates” program so member public libraries can nominate local nonprofit partners that can also receive access to archiving services and resources. Funding will also support the continuation of the program’s professional development training in digital preservation and community archiving and its overall cohort and community building activities of workshops, events, and symposia.
We thank The Andrew W. Mellon Foundation for their generous support of Community Webs. We are excited to continue to expand the program and empower hundreds of public librarians to build archives that document the voices, lives, and events of their communities and to ensure this material is permanently available to patrons, students, scholars, and citizens.
This is a guest post from Teresa Soleau (Digital Preservation Manager), Anders Pollack (Software Engineer), and Neal Johnson (Senior IT Project Manager) from the J. Paul Getty Trust.
Project Background
Getty pursues its mission in Los Angeles and around the world through the work of its constituent programs—Getty Conservation Institute, Getty Foundation, J. Paul Getty Museum, and Getty Research Institute—serving the general interested public and a wide range of professional communities to promote a vital civil society through an understanding of the visual arts.
In 2019, Getty began a website redesign project, changing the technology stack and updating the way we interact with our communities online. The legacy website contained more than 19,000 web pages and we knew many were no longer useful or relevant and should be retired, possibly after being archived. This led us to leverage the content we’d captured using the Internet Archive’s Archive-It service.
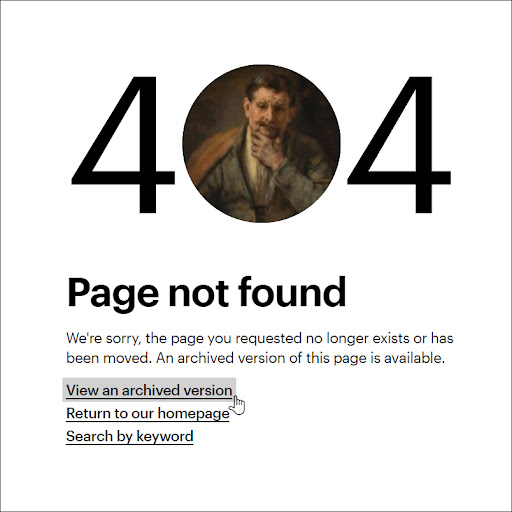
We’d been crawling our site since 2017, but had treated the results more as a record of institutional change over time than as an archival resource to be consulted after deletion of a page. We needed to direct traffic to our Wayback Machine captures thus ensuring deleted pages remain accessible when a user requests a deprecated URL. We decided to dynamically display a link to the archived page from our site’s 404 error “Page not found” page.
Getty.edu 404 error “Page not found” message including the dynamically generated instructions and Internet Archive page link.
The project to audit all existing pages required us to educate content owners across the institution about web archiving practices and purpose. We developed processes for completing human reviews of large amounts of captured content. This work is described in more detail in a 2021 Digital Preservation Coalition blog post that mentions the Web Archives Collecting Policy we developed.
In this blog post we’ll discuss the work required to use the Internet Archive’s data API to add the necessary link on our 404 pages pointing to the most recent Wayback Machine capture of a deleted page.
Technical Underpinnings
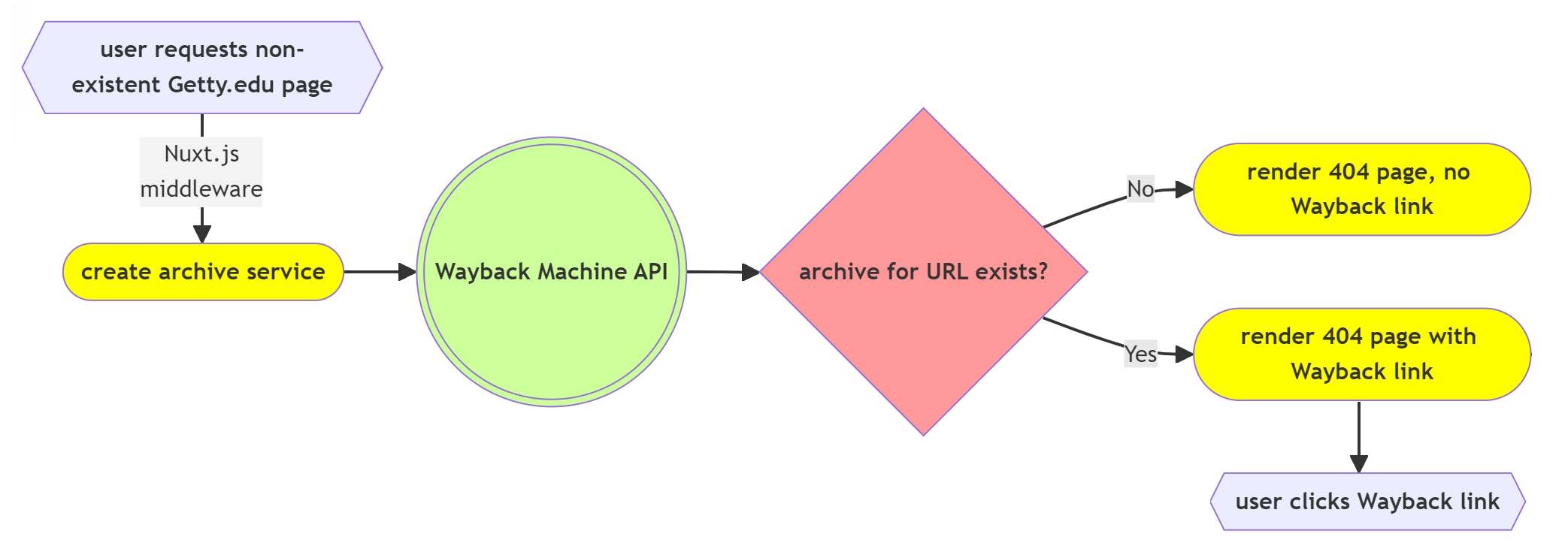
Implementation of our Wayback Machine integration was very straightforward from a technical point of view. The first example provided in the Wayback Machine APIs documentation page provided the technical guidance needed for our use case to display a link to the most recent capture of any page deleted from our website. With no requirements for authentication or management of keys or platform-specific software development kit (SDK) dependencies, our development process was simplified. We chose to incorporate the Wayback API using Nuxt.js, the web framework used to build the new Getty.edu site.
Since the Wayback Machine API is highly performant for simple queries, with a typical response delay in milliseconds, we are able to query the API before rendering the page using a Nuxt route middleware module. API error handling and a request timeout were added to ensure that edge cases such as API failures or network timeouts do not block rendering of the 404 response page.
The only Internet Archive API feature missing for our initial list of requirements was access to snapshot page thumbnails in the JSON data payload received from the API. Access to these images would allow us to enhance our 404 page with a visual cue of archived page content.
Results and Next Steps
Our ability to include a link to an archived version of a deleted web page on our 404 response page helped ease the tough decisions content stakeholders were obliged to make about what content to archive and then delete from the website. We could guarantee availability of content in perpetuity without incurring the long term cost of maintaining the information ourselves.
The API brings back the most recent Wayback Machine capture by default which is sometimes not created by us and hasn’t necessarily passed through our archive quality assurance process. We intend to develop our application further so that we privilege the display of Getty’s own page captures. This will ensure we’re delivering the highest quality capture to users.
Google Analytics has been configured to report on traffic to our 404 pages and will track clicks on links pointing to Internet Archive pages, providing useful feedback on what portion of archived page traffic is referred from our 404 error page.
To work around the challenge of providing navigational affordances to legacy content and ensure web page titles of old content remains accessible to search engines, we intend to provide an up-to-date index of all archived getty.edu pages.
As we continue to retire obsolete website pages and complete this monumental content archiving and retirement effort, we’re grateful for the Internet Archive API which supports our goal of making archived content accessible in perpetuity.
Kevin Hegg is Head of Digital Projects at James Madison University Libraries (JMU). Kevin has held many technology positions within JMU Libraries. His experience spans a wide variety of technology work, from managing computer labs and server hardware to developing a large open-source software initiative. We are thankful to Kevin for taking time to talk with us about his experience with ARCH (Archives Research Compute Hub), AI, and supporting research at JMU.
Thomas Padilla is Deputy Director, Archiving and Data Services.
Thomas: Thank you for agreeing to talk more about your experience with ARCH, AI, and supporting research. I find that folks are often curious about what set of interests and experiences prepares someone to work in these areas. Can you tell us a bit about yourself and how you began doing this kind of work?
Kevin: Over the span of 27 years, I have held several technology roles within James Madison University (JMU) Libraries. My experience ranges from managing computer labs and server hardware to developing a large open-source software initiative adopted by numerous academic universities across the world. Today I manage a small team that supports faculty and students as they design, implement, and evaluate digital projects that enhance, transform, and promote scholarship, teaching, and learning. I also co-manage Histories Along the Blue Ridgewhich hosts over 50,000 digitized legal documents from courthouses along Virginia’s Blue Ridge mountains.
Thomas: I gather that your initial interest in using ARCH was to see what potential it afforded for working with James Madison University’s Mapping Black Digital and Public Humanities project. Can you introduce the project to our readers?
Kevin: The Mapping the Black Digital and Public Humanities project began at JMU in Fall 2022. The project draws inspiration from established resources such as the Colored Convention Project and the Reviews in Digital Humanities journal. It employs Airtable for data collection and Tableau for data visualization. The website features a map that not only geographically locates over 440 Black digital and public humanities projects across the United States but also offers detailed information about each initiative. The project is a collaborative endeavor involving JMU graduate students and faculty, in close alliance with JMU Libraries. Over the past year, this interdisciplinary team has dedicated hundreds of hours to data collection, data visualization, and website development.
The project has achieved significant milestones. In Fall 2022, Mollie Godfrey and Seán McCarthy, the project leaders, authored, “Race, Space, and Celebrating Simms: Mapping Strategies for Black Feminist Biographical Recovery“, highlighting the value of such mapping projects. At the same time, graduate student Iliana Cosme-Brooks undertook a monumental data collection effort. During the winter months, Mollie and Seán spearheaded an effort to refine the categories and terms used in the project through comprehensive research and user testing. By Spring 2023, the project was integrated into the academic curriculum, where a class of graduate students actively contributed to its inaugural phase. Funding was obtained to maintain and update the database and map during the summer.
Looking ahead, the project team plans to present their work at academic conferences and aims to diversify the team’s expertise further. The overarching objective is to enhance the visibility and interconnectedness of Black digital and public humanities projects, while also welcoming external contributions for the initiative’s continual refinement and expansion.
Thomas: It sounds like the project adopts a holistic approach to experimenting with and integrating the functionality of a wide range of tools and methods (e.g., mapping, data visualization). How do you see tools like ARCH fitting into the project and research services more broadly? What tools and methods have you used in combination with ARCH?
Kevin: ARCH offers faculty and students an invaluable resource for digital scholarship by providing expansive, high-quality datasets. These datasets enable more sophisticated data analytics than typically encountered in undergraduate pedagogy, revealing patterns and trends that would otherwise remain obscured. Despite the increasing importance of digital humanities, a significant portion of faculty and students lack advanced coding skills. The advent of AI-assisted coding platforms like ChatGPT and GitHub CoPilot has democratized access to programming languages such as Python and JavaScript, facilitating their integration into academic research.
For my work, I employed ChatGPT and CoPilot to further process ARCH datasets derived from a curated sample of 20 websites focused on Black digital and public humanities. Utilizing PyCharm—an IDE freely available for educational purposes—and the CoPilot extension, my coding efficiency improved tenfold.
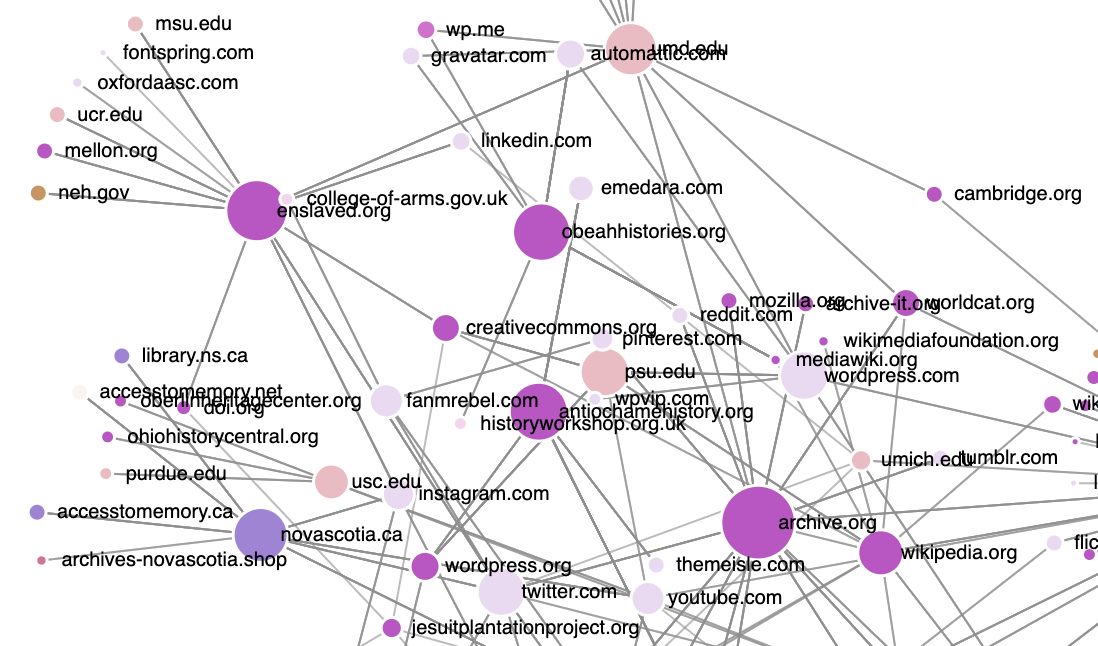
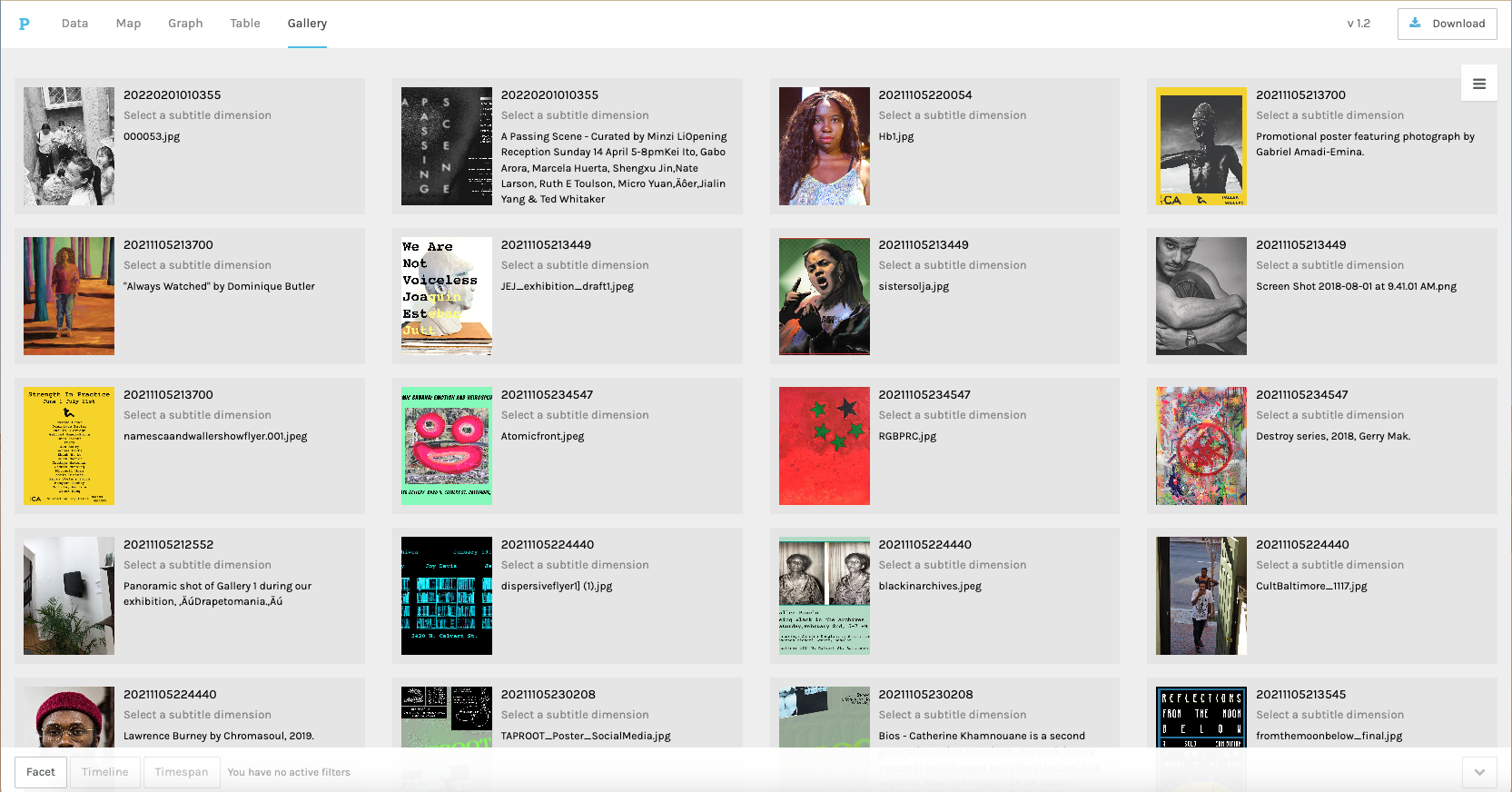
Next, I leveraged ChatGPT’s Advanced Data Analysis plugin to deconstruct visualizations from Stanford’s Palladio platform, a tool commonly used for exploratory data visualizations but lacking a means for sharing the visualizations. With the aid of ChatGPT, I developed JavaScript-based web applications that faithfully replicate Palladio’s graph and gallery visualizations. Specifically, I instructed ChatGPT to employ the D3 JavaScript library for ingesting my modified ARCH datasets into client-side web applications. The final products, including HTML, JavaScript, and CSV files, were made publicly accessible via GitHub Pages (see my graph and gallery on GitHub Pages)
Black Digital and Public Humanities websites, graph visualization
In summary, the integration of Python and AI-assisted coding tools has not only enhanced my use of ARCH datasets but also enabled the creation of client-side web applications for data visualization.
Thomas: Beyond pairing ChatGPT with ARCH, what additional uses are you anticipating for AI-driven tools in your work?
Kevin: AI-driven tools have already radically transformed my daily work. I am using AI to reduce or even eliminate repetitive, mindless tasks that take tens or hundreds of hours. For example, as part of the Mapping project, ChatGPT+ helped me transform an AirTable with almost 500 rows and two dozen columns into a series of 500 blog posts on a WordPress site. ChatGPT+ understands the structure of a WordPress export file. After a couple of hours of iterating through my design requirements with ChatGPT, I was able to import 500 blog posts into a WordPress website. Without this intervention, this task would have required over a hundred hours of tedious copying and pasting. Additionally, we have been using AI-enabled platforms like Otter and Descript to transcribe oral interviews.
I foresee AI-driven tools playing an increasingly pivotal role in many facets of my work. For instance, natural language processing could automate the categorization and summarization of large text-based datasets, making archival research more efficient and our analyses richer. AI can also be used to identify entities in large archival datasets. Archives hold a treasure trove of artifacts waiting to be described and discovered. AI offers tools that will supercharge our construction of finding aids and item-level metadata.
Lastly, AI could facilitate more dynamic and interactive data visualizations, like the ones I published on GitHub Pages. These will offer users a more engaging experience when interacting with our research findings. Overall, the potential of AI is vast, and I’m excited to integrate more AI-driven tools into JMU’s classrooms and research ecosystem.
Thomas: Thanks for taking the time Kevin. To close out, whose work would you like people to know more about?
Kevin: Engaging in Digital Humanities (DH) within the academic library setting is a distinct privilege, one that requires a collaborative ethos. I am fortunate to be a member of an exceptional team at JMU Libraries, a collective too expansive to fully acknowledge here. AI has introduced transformative tools that border on magic. However, loosely paraphrasing Immanuel Kant, it’s crucial to remember that technology devoid of content is empty. I will use this opportunity to spotlight the contributions of three JMU faculty whose work celebrates our local community and furthers social justice.
Mollie Godfrey (Department of English) and Seán McCarthy (Writing, Rhetoric, and Technical Communication) are the visionaries behind two inspiring initiatives: the Mapping Project and the Celebrating Simms Project. The latter serves as a digital, post-custodial archive honoring Lucy F. Simms, an educator born into enslavement in 1856 who impacted three generations of young students in our local community. Both Godfrey and McCarthy have cultivated deep, lasting connections within Harrisonburg’s Black community. Their work strikes a balance between celebration and reparation. Collaborating with them has been as rewarding as it is challenging.
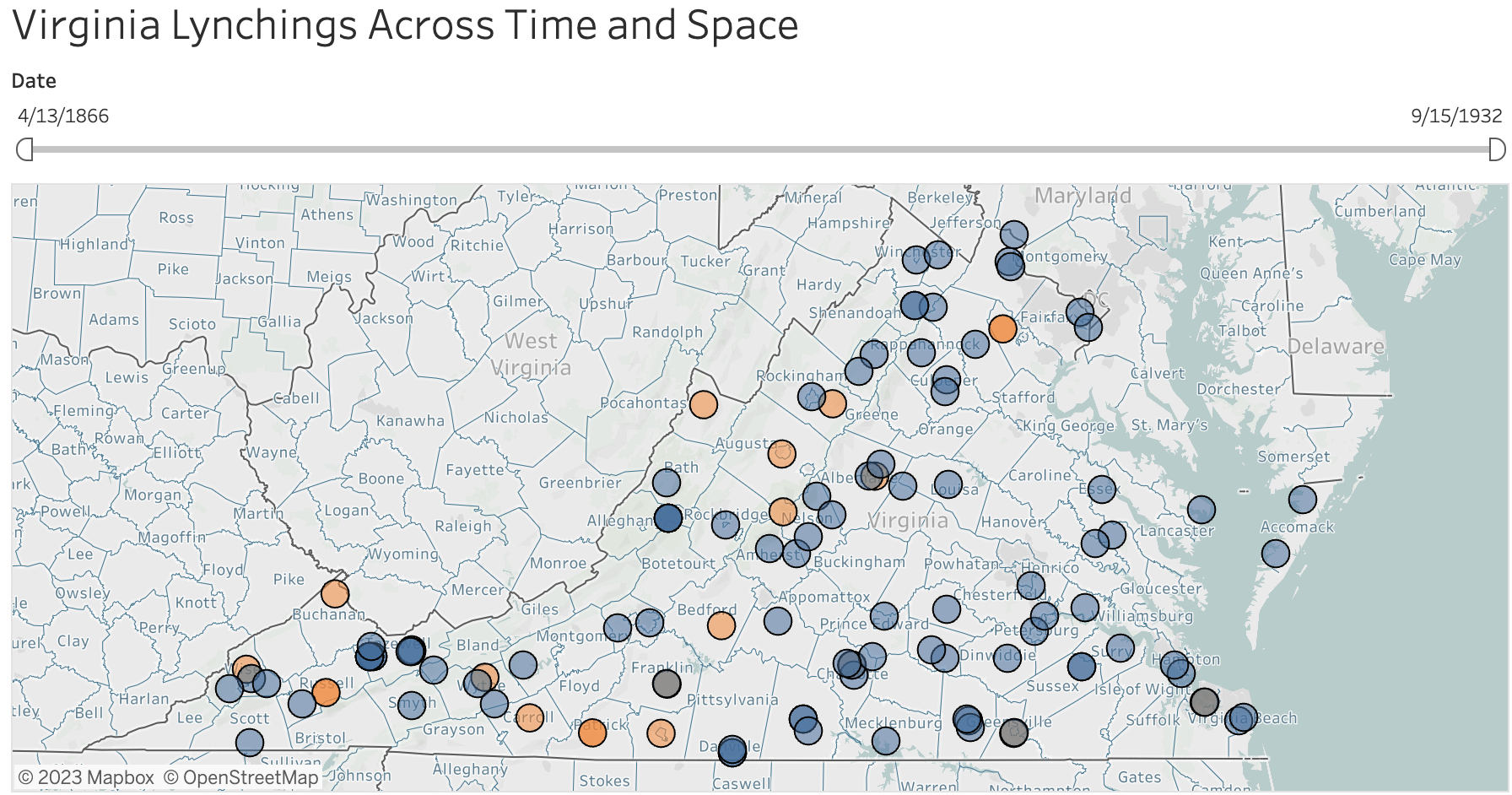
Gianluca De Fazio (Justice Studies) spearheads the Racial Terror: Lynching in Virginia project, illuminating a grim chapter of Virginia’s past. His relentless dedication led to the installation of a historical marker commemorating the tragic lynching of Charlotte Harris. De Fazio, along with colleagues, has also developed nine lesson plans based on this research, which are now integrated into high school curricula. My collaboration with him was a catalyst for pursuing a master’s degree in American History.
Both the Celebrating Simms and Racial Terror projects are highlighted in the Mapping the Black Digital and Public Humanities initiative. The privilege of contributing to such impactful projects alongside such dedicated individuals has rendered my extensive tenure at JMU both meaningful and, I hope, enduring.
As a doctoral student in anthropology at Yale University, Spencer Kaplan often relies on the Internet Archive for his research. He is an anthropologist of technology who studies virtual communities. Kaplan said he uses the Wayback Machine to create a living archive of data that he can analyze.
Doctoral student Spencer Kaplan
Last summer, Kaplan studied the blockchain community, which is active on Twitter and constantly changing. As people were sharing their views of the market and helping one another, he needed a way to save the data before their accounts disappeared. A failed project might have prompted the users to take down the information, but Kaplan used the Wayback Machine to preserve the social media exchanges.
In his research, Kaplan said he discovered an environment of mistrust online in the blockchain community and an abundance of scams. He followed how people were navigating the scams, warning one another online to be careful, and actually building trust in some cases. While blockchain is trying to build technologies that avoid trust in social interaction, Kaplan said it was interesting to observe blockchain enthusiasts engaging in trusting connections. He takes the texts of tweets to build a corpus that he can then code and analyze the data to track or show trends.
The Wayback Machine can be helpful, Kaplan said, in finding preserved discussions on Twitter, early versions of company websites or pages that have been taken down altogether—a start-up company that went out of business, for example. “It’s important to be able to hold on to that [information] because our research takes place at a very specific moment in time and we want to be able to capture that specific moment,” Kaplan said.
The Internet Archive’s Open Library has also been essential in Kaplan’s work. When he was recently researching the invention of the “corporate culture” concept, he had trouble finding the first editions of many business books written in the late 80s and early 90s. His campus library often bought updated volumes, but Kaplan needed the originals. “I needed the first edition because I needed to know exactly what they said first and I was able to find that on the Internet Archive,” Kaplan said.
A part of a series: The Internet Archive as Research Library
Written by Caralee Adams
When gathering evidence for a court case or researching human rights violations, Lili Siri Spira often found that the material she needed was preserved by the Internet Archive.
In Spira’s work, the Wayback Machine has played an integral role in providing stamped artifacts and metadata.
For example, when researching the Bolivian coup in 2019, she wanted to learn more about the sentiment of indigenous people toward political leadership. Spira used the Wayback Machine to examine how indigenous Bolivian websites had changed since 2009. She discovered after initial criticism, some websites seemed to have disappeared.
“The great thing about the Internet Archive is that it really protects the chain of custody,” Spira said. “It’s not only that you look back, but you can even find a website now and capture it in time with the metadata.”
In 2020, The Berkeley Protocol on Digital Open Source Violations provided global guidelines for using public digital information as evidence in international criminal and human rights investigations. Spira said this allows preserved website data to be used in court proceedings to hold parties accountable.
On other occasions, Spira has investigated companies suspected of unethical practices. Sometimes executives openly admitted to certain behaviors, only to later deny their action. Companies may attempt to erase past communication, but Spira said she can uncover the previous versions of websites through the Wayback Machine.
“Our knowledge is not being held sacred by many people in this country and around the world,” Spira said. “It’s incredibly important for research work in any field to have access to preserved [digital] information—especially when that research is making certain allegations against powerful entities and corporations.”
We thank Lili and her colleagues for sharing their story for how they use the Internet Archive’s collections in their work.
This Spring, the Internet Archive hosted two in-person workshops aimed at helping to advance library support for web archive research: Digital Scholarship & the Web and Art Resources on the Web. These one-day events were held at the Association of College & Research Libraries (ACRL) conference in Pittsburgh and the Art Libraries Society of North America (ARLIS) conference in Mexico City. The workshops brought together librarians, archivists, program officers, graduate students, and disciplinary researchers for full days of learning, discussion, and hands-on experience with web archive creation and computational analysis. The workshops were developed in collaborationwith the New York Art Resources Consortium (NYARC) – and are part of an ongoing series of workshops hosted by the Internet Archive through Summer 2023.
Internet Archive Deputy Director of Archiving & Data Services Thomas Padilla discussing the potential of web archives as primary sources for computational research at Art Resources on the Web in Mexico City.
Designed in direct response to library community interest in supporting additional uses of web archive collections, the workshops had the following objectives: introduce participants to web archives as primary sources in context of computational research questions, develop familiarity with research use cases that make use of web archives; and provide an opportunity to acquire hands-on experience creating web archive collections and computationally analyzing them usingARCH (Archives Research Compute Hub) – a new service set to publicly launch June 2023.
Internet Archive Community Programs Manager Lori Donovan walking workshop participants through a demonstration of Palladio using a dataset generated with ARCH at Digital Scholarship & the Web In Pittsburgh, PA.
In support of those objectives, Internet Archive staff walked participants through web archiving workflows, introduced a diverse set of web archiving tools and technologies, and offered hands-on experience building web archives. Participants were then introduced to Archives Research Compute Hub (ARCH). ARCH supports computational research with web archive collections at scale – e.g., text and data mining, data science, digital scholarship, machine learning, and more. ARCH does this by streamlining generation and access to more than a dozen research ready web archive datasets, in-browser visualization, dataset analysis, and open dataset publication. Participants further explored data generated with ARCH in Palladio, Voyant, and RAWGraphs.
Network visualization of the Occupy Web Archive collection, created using Palladio based on a Domain Graph Dataset generated by ARCH.
Gallery visualization of the CARTA Art Galleries collection, created using Palladio based on an Image Graph Dataset generated by ARCH.
At the close of the workshops, participants were eager to discuss web archive research ethics, research use cases, and a diverse set of approaches to scaling library support for researchers interested in working with web archive collections – truly vibrant discussions – and perhaps the beginnings of a community of interest! We plan to host future workshops focused on computational research with web archives – please keep an eye on our Event Calendar.
Tell us about your research & how you use the Internet Archive to further it! We are gathering testimonials about how our library & collections are used in different research projects & settings.
From using our books to check citations to doing large-scale data analysis using our web archives, we want to hear from you!
As Twitter has entered the Musk era, many people are leaving the platform or rethinking its role in their lives. Whether they join another platform like Mastodon (as I have) or continue on at Twitter, the instability occasioned by Twitter’s change in ownership has revealed an underlying instability in our digital information ecosystem.
Many have now seen how, when someone deletes their Twitter account, their profile, their tweets, even their direct messages, disappear. According to the MIT Technology Review, around a million people have left so far, and all of this information has left the platform along with them. The mass exodus from Twitter and the accompanying loss of information, while concerning in its own right, shows something fundamental about the construction of our digital information ecosystem: Information that was once readily available to you—that even seemed to belong to you—can disappear in a moment.
Losing access to information of private importance is surely concerning, but the situation is more worrying when we consider the role that digital networks play in our world today. Governments make official pronouncements online. Politicians campaign online. Writers and artists find audiences for their work and a place for their voice. Protest movements find traction and fellow travelers. And, of course, Twitter was a primary publishing platform of a certain U.S. president.
If Twitter were to fail entirely, all of this information could disappear from their site in an instant. This is an important part of our history. Shouldn’t we be trying to preserve it?
I’ve been working on these kinds of questions, and building solutions to some of them, for a long time. That’s part of why, over 25 years ago, I founded the Internet Archive. You may have heard of our “Wayback Machine,” a free service anyone can use to view archived web pages from the mid-1990’s to the present. This archive of the web has been built in collaboration with over a thousand libraries around the world, and it holds hundreds of billions of archived webpages today–including those presidential tweets (and many others). In addition, we’ve been preserving all kinds of important cultural artifacts in digital form: books, television news, government records, early sound and film collections, and much more.
The scale and scope of the Internet Archive can give it the appearance of something unique, but we are simply doing the work that libraries and archives have always done: Preserving and providing access to knowledge and cultural heritage. For thousands of years, libraries and archives have provided this important public service. I started the Internet Archive because I strongly believed that this work needed to continue in digital form and into the digital age.
While we have had many successes, it has not been easy. Like the record labels, many book publishers didn’t know what to make of the internet at first, but now they see new opportunities for financial gain. Platforms, too, tend to put their commercial interests first. Don’t get me wrong: Publishers and platforms continue to play an important role in bringing the work of creators to market, and sometimes assist in the preservation task. But companies close, and change hands, and their commercial interests can cut against preservation and other important public benefits.
Traditionally, libraries and archives filled this gap. But in the digital world, law and technology make their job increasingly difficult. For example, while a library could always simply buy a physical book on the open market in order to preserve it on their shelves, many publishers and platforms try to stop libraries from preserving information digitally. They may even use technical and legal measures to prevent libraries from doing so. While we strongly believe that fair use law enables libraries to perform traditional functions like preservation and lending in the digital environment, many publishers disagree, going so far as to sue libraries to stop them from doing so.
We should not accept this state of affairs. Free societies need access to history, unaltered by changing corporate or political interests. This is the role that libraries have played and need to keep playing. This brings us back to Twitter.
In 2010, Twitter had the tremendous foresight of engaging in a partnership with the Library of Congress to preserve old tweets. At the time, the Library of Congress had been tasked by Congress “to establish a national digital information infrastructure and preservation program.” It appeared that government and private industry were working together in search of a solution to the digital preservation problem, and that Twitter was leading the way.
It was not long before the situation broke down. In 2011, the Library of Congress issued a report noting the need for “legal and regulatory changes that would recognize the broad public interest in long-term access to digital content,” as well as the fact that “most libraries and archives cannot support under current funding” the necessary digital preservation infrastructure.” But no legal and regulatory changes have been forthcoming, and even before the 2011 report, Congress pulled tens of millions of dollars out of the preservation program. In these circumstances, it is perhaps unsurprising that, by 2017, the Library of Congress had ceased preserving most old tweets, and the National Digital Information Infrastructure and Preservation Program (NDIIPP) is no longer an active program at the Library of Congress. Furthermore, it is not clear whether Twitter’s new ownership will take further steps of its own to address the situation.
Whatever Musk does, the preservation of our digital cultural heritage should not have to rely on the beneficence of one man. We need to empower libraries by ensuring that they have the same rights with respect to digital materials that they have in the physical world. Whether that means archiving old tweets, lending books digitally, or even something as exciting (to me!) as 21st century interlibrary loan, what’s important is that we have a nationwide strategy for solving the technical and legal hurdles to getting this done.
Internet Archive has begun gathering content for the Digital Library of Amateur Radio and Communications (DLARC), which will be a massive online library of materials and collections related to amateur radio and early digital communications. The DLARC is funded by a significant grant from the Amateur Radio Digital Communications (ARDC), a private foundation, to create a digital library that documents, preserves, and provides open access to the history of this community.
The library will be a free online resource that combines archived digitized print materials, born-digital content, websites, oral histories, personal collections, and other related records and publications. The goals of the DLARC are to document the history of amateur radio and to provide freely available educational resources for researchers, students, and the general public. This innovative project includes:
A program to digitize print materials, such as newsletters, journals, books, pamphlets, physical ephemera, and other records from both institutions, groups, and individuals.
A digital archiving program to archive, curate, and provide access to “born-digital” materials, such as digital photos, websites, videos, and podcasts.
A personal archiving campaign to ensure the preservation and future access of both print and digital archives of notable individuals and stakeholders in the amateur radio community.
Conducting oral history interviews with key members of the community.
Preservation of all physical and print collections donated to the Internet Archive.
The DLARC project is looking for partners and contributors with troves of ham radio, amateur radio, and early digital communications related books, magazines, documents, catalogs, manuals, videos, software, personal archives, and other historical records collections, no matter how big or small. In addition to physical material to digitize, we are looking for podcasts, newsletters, video channels, and other digital content that can enrich the DLARC collections. Internet Archive will work directly with groups, publishers, clubs, individuals, and others to ensure the archiving and perpetual access of contributed collections, their physical preservation, their digitization, and their online availability and promotion for use in research, education, and historical documentation. All collections in this digital library will be universally accessible to any user and there will be a customized access and discovery portal with special features for research and educational uses.
We are extremely grateful to ARDC for funding this project and are very excited to work with this community to explore a multi-format digital library that documents and ensures access to the history of a specific, noteworthy community. Anyone with material to contribute to the DLARC library, questions about the project, or interest in similar digital library building projects for other professional communities, please contact:
Kay Savetz, K6KJN Program Manager, Special Collections kay@archive.org Twitter: @KaySavetz
This post is part of a series written by members of the Internet Archive’s Community Webs program. Community Webs advances the capacity for community-focused memory organizations to build web and digital archives documenting local histories and underrepresented voices. For more information, visit communitywebs.archive-it.org/
What is an archivist to do when items of public record, which have been systematically added to publicly accessible collections for over a century, suddenly turn from paper into bits and bytes that disappear from the web, or even get stuck behind paywalls? Like many in my profession, I’ve been grappling with this question for a while. Having no real training in digital archiving and facing this quandary as a lone arranger, it’s sometimes hard to keep that grappling from turning into low-key panicking that my inaction has been causing information to be lost forever.
Imagine my excitement, then, when I learned about the Community Webs program – access to and training for Archive-It, collaboration with the Internet Archive, and a network of others like me to bounce ideas off and get inspiration from? Yes please! With the blessing of my boss, I applied right away and my library joined the program in April 2021.
The outside of the Waltham Public Library. Photo by C. Sowa.
(This might be a good point for a quick introduction. I work as the archivist/local history librarian at the Waltham Public Library (WPL) in Waltham, Massachusetts. Waltham is a city about 10 miles west of Boston, and is home to an ethnically and economically diverse population of just over 62,000 people. The WPL is a fully-funded community hub, fostering a healthy democratic society by providing a wealth of current informational, educational, and recreational resources free of charge to all members of the community. The library is known throughout the area for its knowledgeable and friendly staff, welcoming and safe environment, accessibility, convenience, current technology, and helpful assistance.)
I eagerly dove into the program and used our first web-archive collection – Waltham Public Library – as a testing ground, a place to gain familiarity with both Archive-It and the whole process of web archiving. I’ve been trying to capture content that aligns with the material found in the library’s analog records – annual reports, policies, announcements, event flyers, records from our Friends group, etc. – by doing a weekly crawl of the library website, our Friends website, and the library’s Twitter feed. For the most part this collection has been thankfully pretty straightforward.
Our largest collection so far is COVID-19 in Waltham, which makes up a portion of the library’s very first born-digital archival collection. That collection began in April 2020, when the WPL (like most other places) was closed to help “flatten the curve.” A month or two prior, as the pandemic was building steam, I had become fascinated with the 1918 influenza. A poke through our archives for the topic had been disappointing, as there wasn’t too much beyond a couple of newspaper clippings, brief mentions in the library trustees’ minutes, and a few pages in the records of the local nurses’ association. I was hoping to put together a better picture of what it was like to live in Waltham during the flu, perhaps to give myself a glimpse of what I could expect in the coming weeks (heh… how naïve I was).
Scrapbook page showing newspaper clippings from the early days of the 1918 flu. Scrapbook is part of the records of the Waltham Public Library. Photo by D. Hamlin.
I put out a call via the library’s social media for those who lived, worked, and/or went to school in Waltham to share their stories, hoping to build the kind of collection I wanted and failed to find from 1918. There was an initial rush of Google Form submissions, a handful of photos, and one video, and then nothing. I was pleased we had received some materials, but still wanted to paint a broader picture of Waltham under Covid. Enter Community Webs! For the past several months I’ve been working to collect retroactively what I was hoping to capture at the time – news articles, videos, the city website, information from the schools, and so on. While it’s not as comprehensive as it might have been if I’d been able to gather it all as it happened, I’ve been able to save over 500 GB of data that will help those in the future to better imagine what it was like to live in Waltham during Covid.
Screenshot from a WPL Instagram post sharing a patron’s submission to our COVID-19 in Waltham collection.Screenshot examples of Covid-related content captured retroactively with Archive-It.
Finally, related to the quandary in the first paragraph of this post, our most complicated collection is the Waltham News Tribune. The WPL has microfilm copies of the paper going back to its earliest iteration in the 1860s, and part of my job has been to collect each issue and send yearly batches to a vendor for microfilming. However, as of this past May, the publisher has moved the paper entirely online, with some content requiring a paid subscription to view. The WPL has a subscription so that we can continue to provide free access to our patrons, but what happens to our archive of back issues? Does it just stop abruptly in May 2022, even as time and local news continue to march on? As it is, our microfilm is heavily used, especially since the paper’s offices burned down in 1999, making ours the only existing archive.
Drawers full of microfilmed newspapers at the WPL. Photo by D. Hamlin.
Thanks to web archiving, we’re able to continue to fulfill our unofficial role as the repository for the city newspaper, at least in theory. In practice, I look at the daily crawls of the digital edition of the paper and can’t help but see that it is no longer the type of local news we’ve been archiving for over a century. The corporate publisher of the paper has consolidated ours with those from several other local cities and towns, and has sacrificed true local news coverage for more generic topics, many of which aren’t even related specifically to Massachusetts. This is a problem that sits well outside of my archives wheelhouse, but at least I feel I can do my due diligence by capturing what local news does trickle through.
I’ve had a slower go of web archiving than I’d like so far, thanks to several months of parental leave in 2021 and a very packed part-time work schedule. Nevertheless, I’ve been chipping away at our collections and planning for more, with an eye to add more diverse voices than those that make up much of our analog collections. I’m grateful for the encouragement and help I’ve received from Community Webs staff and peers, and want to give a special shout-out to the Archive-It folks who hold office hours to assist us with technical issues! This really is a fantastic program, and I’m so glad my library is part of it.