The Beta Wayback Machine has some new features including searching to find a website and a summary of types of media on a website.
How can I use the Wayback Machine’s Site Search to find websites? The Site Search feature of the Wayback Machine is based on an index built by evaluating terms from hundreds of billions of links to the homepages of more than 350 million sites. Search results are ranked by the number of captures in the Wayback and the number of relevant links to the site’s homepage.
Can I find sites by searching for words that are in their pages? No, at least not yet. Site Search for the Wayback Machine will help you find the homepages of sites, based on words people have used to describe those sites, as opposed to words that appear on pages from sites.
Can I search sites with text from multiple languages? Yes! In fact, you can search for any unicode character, e.g. you can search for ❤ (try clicking on it). If you can generate characters with your computer, you should be able to use them to search for sites via the Wayback Machine. Go ahead, try searching for правда
Can I still find sites in the Wayback Machine if I just know the URL? Yes, just enter a domain or URL the way you have in the past and press the “Browse History” button.
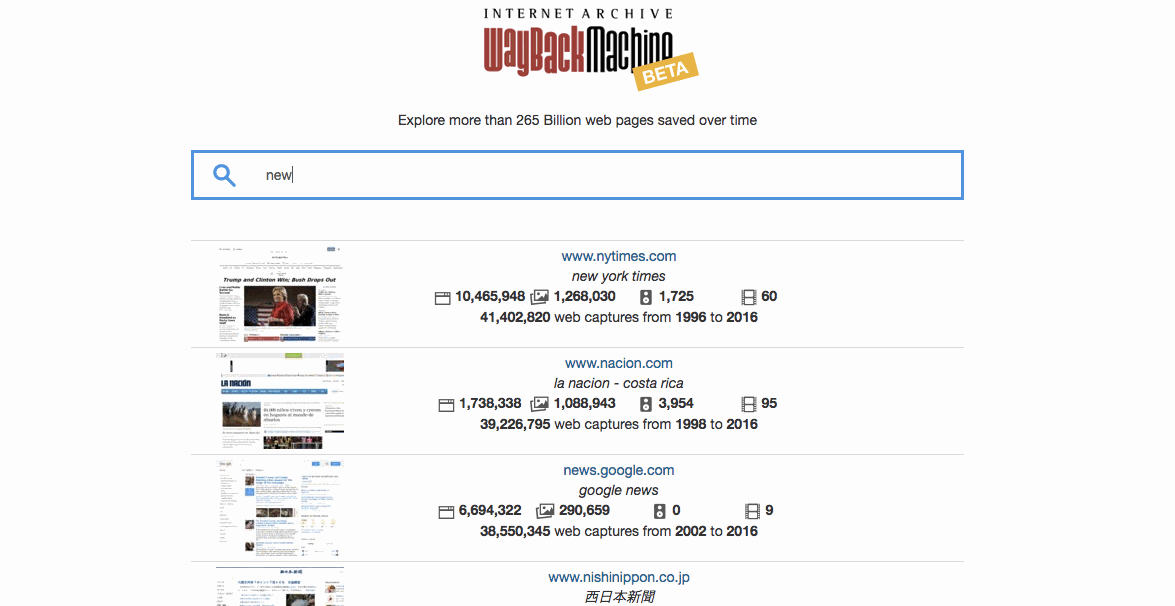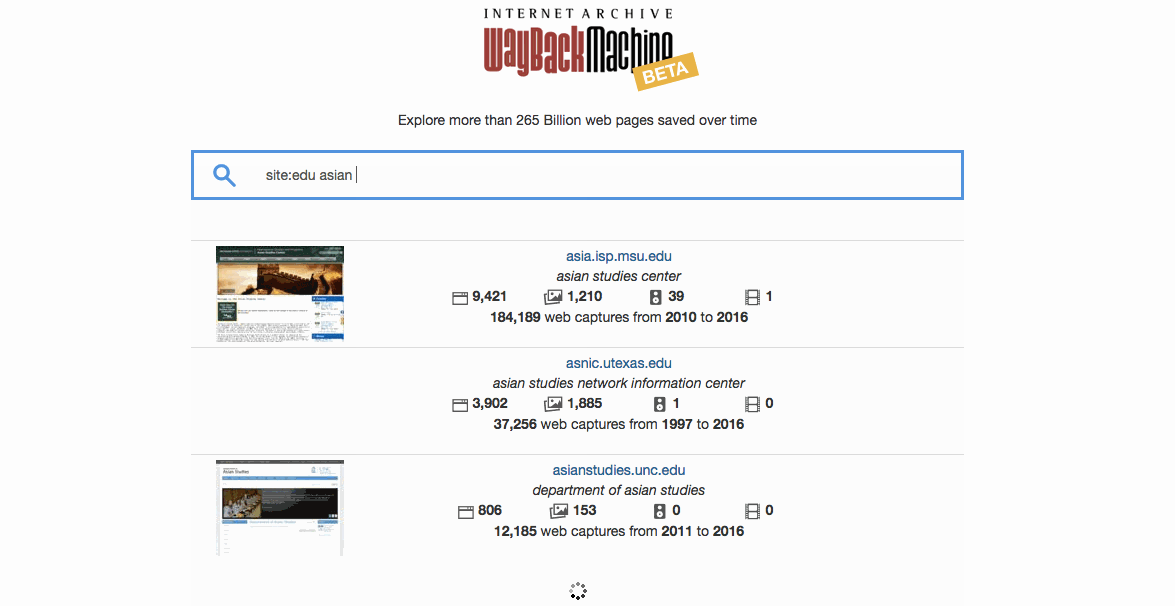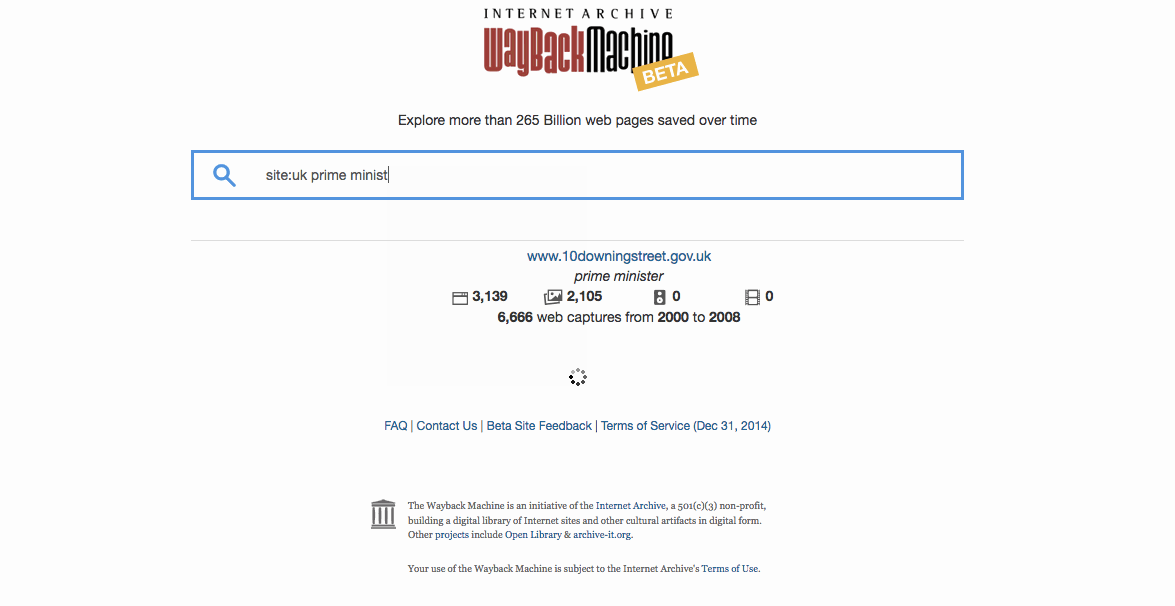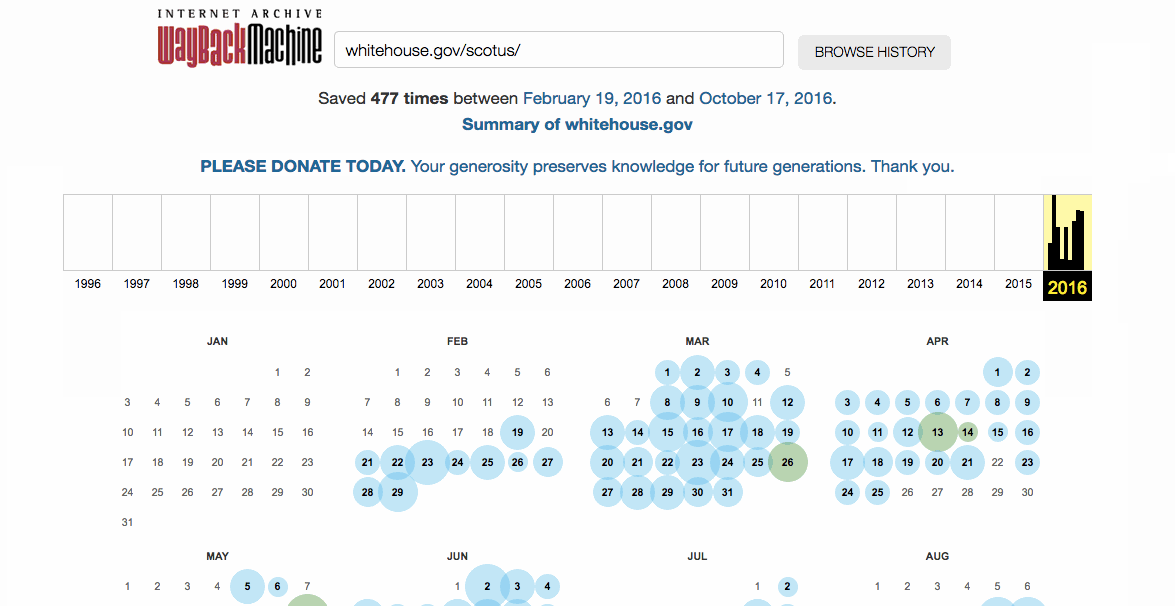
What is the “Summary of <site>” link above the graph on the calendar page telling me? It shows you the breakdown of the web captures for a given domain by content type (text, images, videos, PDFs, etc.) In addition, it shows the number of captures, URLs and new URLs, by year for all the years available via the Wayback Machine, so you can see how a certain site has changed over time.
What are the sources of your captures? When you roll over individual web captures (that pop-up when you roll over the dots on the calendar page for a URL) you may notice some text links shows up above the calendar, along with the word “why”. Those links will take you to the Collection of web captures associated with the specific web crawl the capture came from. Every day hundreds of web crawls contribute to the web captures available via the Wayback Machine. Behind each, there is a story about factors like who, why, when and how.
Why are some of the dots on the calendar page different colors? We color the dots, and links, associated with individual web captures, or multiple web captures, for a given day. Blue means the web server result code the crawler got for the related capture was a 2nn (good); Green means the crawlers got a status code 3nn (redirect); Orange means the crawler got a status code 4nn (client error), and Red means the crawler saw a 5nn (server error). Most of the time you will probably want to select the blue dots or links.
Can I find sites by searching for a word specific to that site? Yes, by adding in “site:<domain>” your results will be restricted to the specified domain. E.g. “site:gov clinton” will search for sites related to the term “clinton” in the domain “gov”.