Guest Post by Daniel Van Strien, Machine Learning Librarian, Hugging Face
Machine learning has many potential applications for working with GLAM (galleries, libraries, archives, museums) collections, though it is not always clear how to get started. This post outlines some of the possible ways in which open source machine learning tools from the Hugging Face ecosystem can be used to explore web archive collections made available via the Internet Archive’s ARCH (Archives Research Compute Hub). ARCH aims to make computational work with web archives more accessible by streamlining web archive data access, visualization, analysis, and sharing. Hugging Face is focused on the democratization of good machine learning. A key component of this is not only making models available but also doing extensive work around the ethical use of machine learning.
Below, I work with the Collaborative Art Archive (CARTA) collection focused on artist websites. This post is accompanied by an ARCH Image Dataset Explorer Demo. The goal of this post is to show how using a specific set of open source machine learning models can help you explore a large dataset through image search, image classification, and model training.
Later this year, Internet Archive and Hugging Face will organize a hands-on hackathon focused on using open source machine learning tools with web archives. Please let us know if you are interested in participating by filling out this form.
Choosing machine learning models
The Hugging Face Hub is a central repository which provides access to open source machine learning models, datasets and demos. Currently, the Hugging Face Hub has over 150,000 openly available machine learning models covering a broad range of machine learning tasks.
Rather than relying on a single model that may not be comprehensive enough, we’ll select a series of models that suit our particular needs.
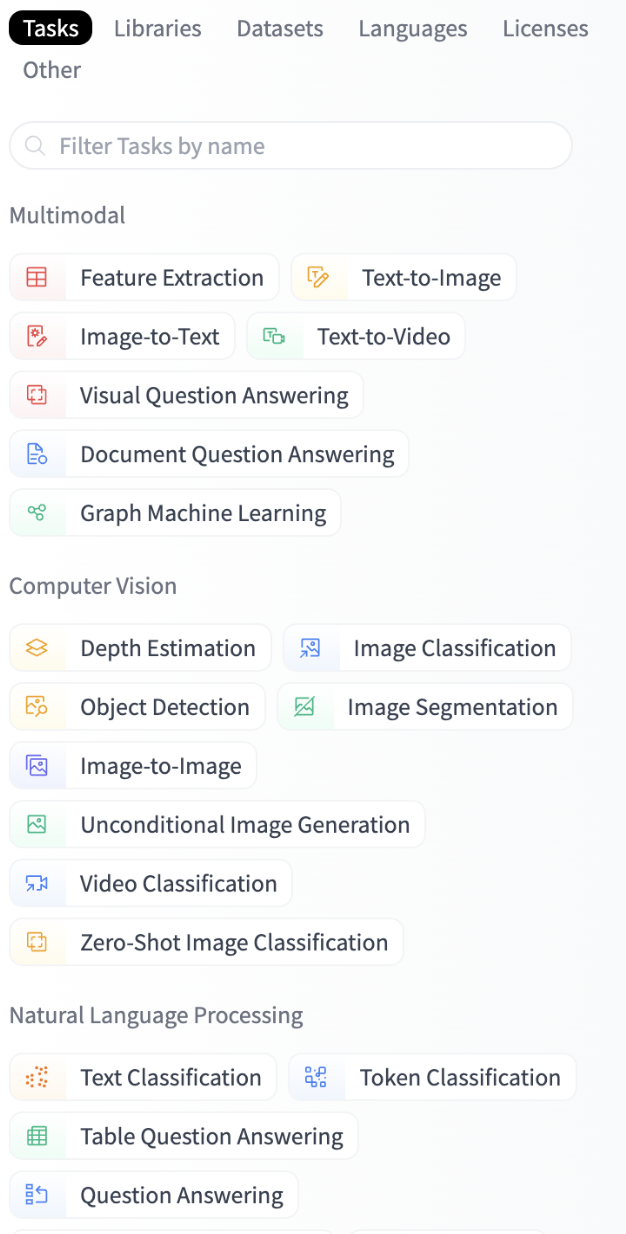
A screenshot of the Hugging Face Hub task navigator presenting a way of filtering machine learning models hosted on the hub by the tasks they intend to solve. Example tasks are Image Classification, Token Classification and Image-to-Text.
Working with image data
ARCH currently provides access to 16 different “research ready” datasets generated from web archive collections. These include but are not limited to datasets containing all extracted text from the web pages in a collection, link graphs (showing how websites link to other websites), and named entities (for example, mentions of people and places). One of the datasets is made available as a CSV file, containing information about the images from webpages in the collection, including when the image was collected, when the live image was last modified, a URL for the image, and a filename.

Screenshot of the ARCH interface showing a preview for a dataset. This preview includes a download link and an “Open in Colab” button.
One of the challenges we face with a collection like this is being able to work at a larger scale to understand what is contained within it – looking through 1000s of images is going to be challenging. We address that challenge by making use of tools that help us better understand a collection at scale.
Building a user interface
Gradio is an open source library supported by Hugging Face that helps create user interfaces that allow other people to interact with various aspects of a machine learning system, including the datasets and models. I used Gradio in combination with Spaces to make an application publicly available within minutes, without having to set up and manage a server or hosting. See the docs for more information on using Spaces. Below, I show examples of using Gradio as an interface for applying machine learning tools to ARCH generated data.
Exploring images
I use the Gradio tab for random images to begin assessing images in the dataset. Looking at a randomized grid of images gives a better idea of what kind of images are in the dataset. This begins to give us a sense of what is represented in the collection (e.g., art, objects, people, etc.).
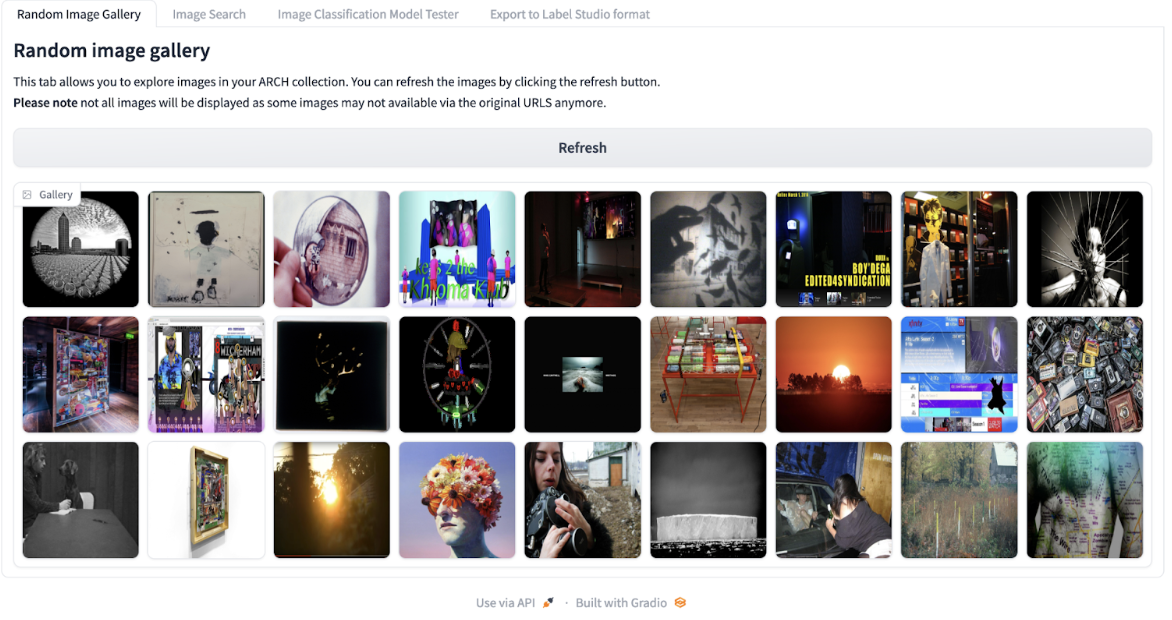
Screenshot of the random image gallery showing a grid of images from the dataset.
Introducing image search models
Looking at snapshots of the collection gives us a starting point for exploring what kinds of images are included in the collection. We can augment our approach by implementing image search.
There are various approaches we could take which would allow us to search our images. If we have the text surrounding an image, we could use this as a proxy for what the image might contain. For example, we might assume that if the text next to an image contains the words “a picture of my dog snowy”, then the image contains a picture of a dog. This approach has limitations – text might be missing, unrelated or only capture a small part of what is in an image. The text “a picture of my dog snowy” doesn’t tell us what kind of dog the image contains or if other things are included in that photo.
Making use of an embedding model offers another path forward. Embeddings essentially take an input i.e. text or image, and return a bunch of numbers. For example, the text prompt: ‘an image of a dog’, would be passed through an embedding model, which ‘translates’ text into a matrix of numbers (essentially a grid of numbers). What is special about these numbers is that they should capture some semantic information about the input; the embedding for a picture of a dog should somehow capture the fact that there is a dog in the image. Since these embeddings consist of numbers, we can also compare one embedding to another to see how close they are to each other. We expect the embeddings for similar images to be closer to each other and the embeddings for images which are less similar to each other to be farther away. Without getting too much into the weeds of how this works, it’s worth mentioning that these embeddings don’t just represent one aspect of an image, i.e. the main object it contains but also other components, such as its aesthetic style. You can find a longer explanation of how this works in this post.
Finding a suitable image search model on the Hugging Face Hub
To create an image search system for the dataset, we need a model to create embeddings. Fortunately, the Hugging Face Hub makes it easy to find models for this.
The Hub has various models that support building an image search system.
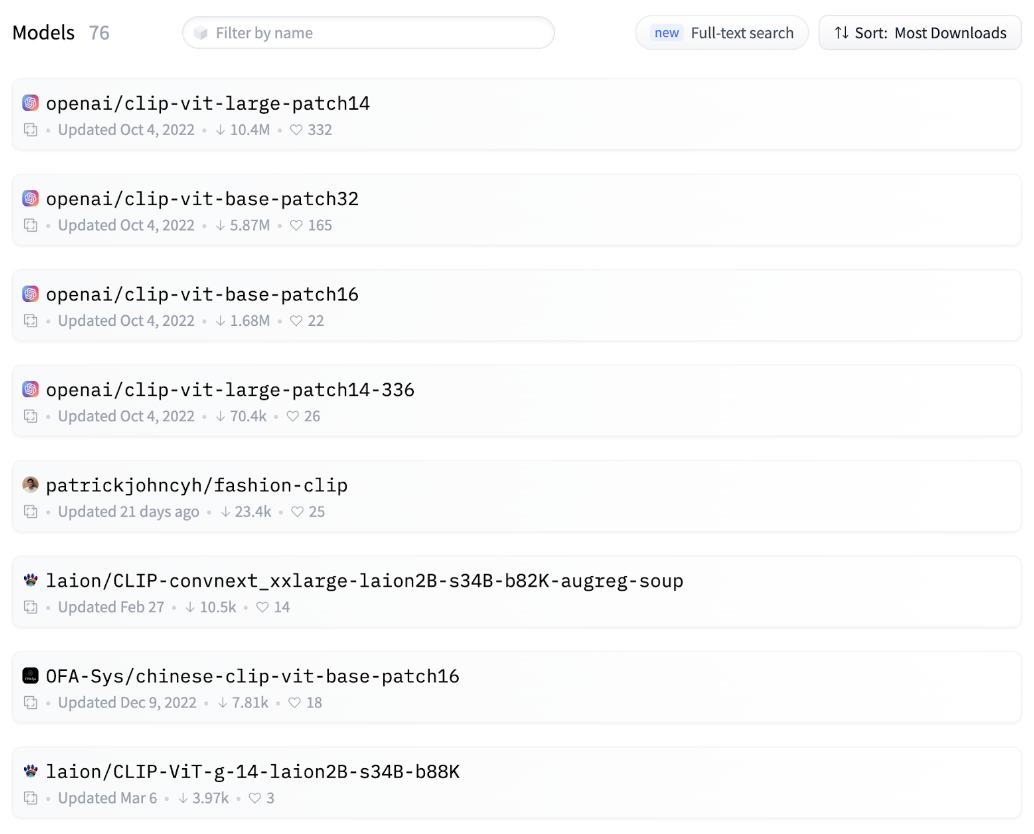
Hugging Face Hub showing a list of hosted models.
All models will have various benefits and tradeoffs. For example, some models will be much larger. This can make a model more accurate but also make it harder to run on standard computer hardware.
Hugging Face Hub provides an ‘inference widget’, which allows interactive exploration of a model to see what sort of output it provides. This can be very useful for quickly understanding whether a model will be helpful or not.
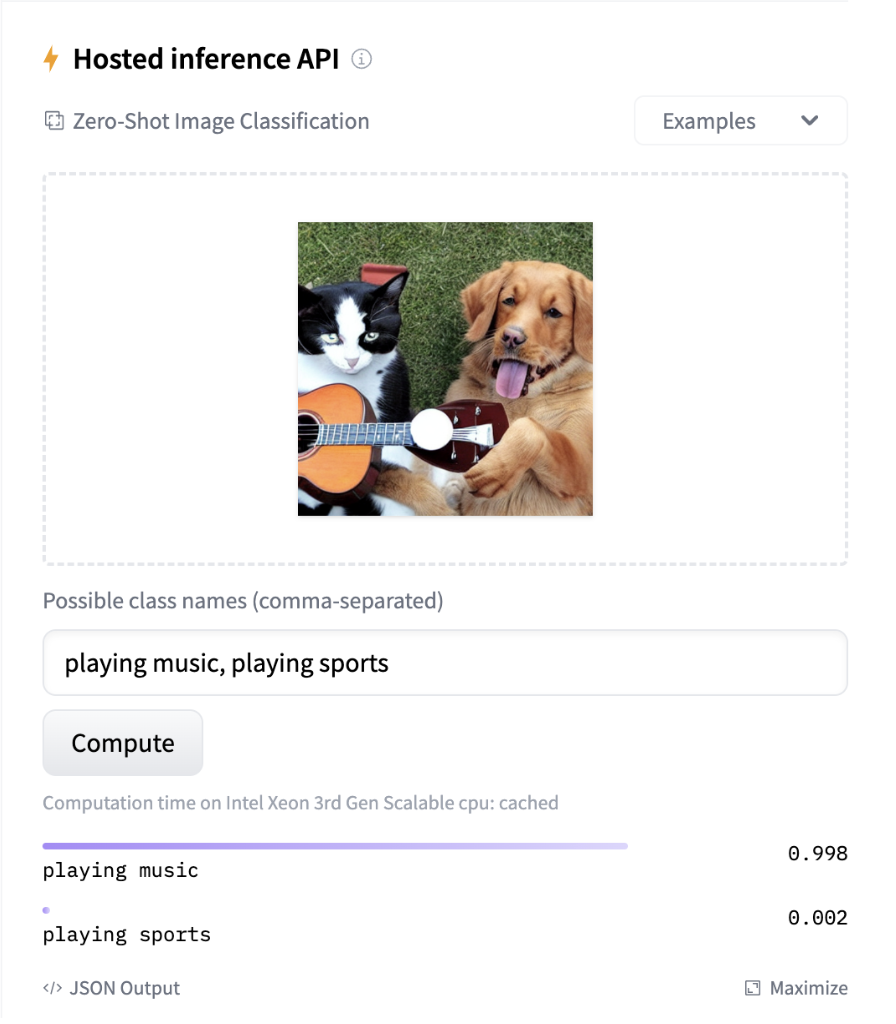
A screenshot of a model widget showing a picture of a dog and a cat playing the guitar. The widget assigns the label `”playing music`” the highest confidence.
For our use case, we need a model which allows us to embed both our input text, for example, “an image of a dog,” and compare that to embeddings for all the images in our dataset to see which are the closest matches. We use a variant of the CLIP model hosted on Hugging Face Hub: clip-ViT-B-16. This allows us to turn both our text and images into embeddings and return the images which most closely match our text prompt.

Aa screenshot of the search tab showing a search for “landscape photograph” in a text box and a grid of images resulting from the search. This includes two images containing trees and images containing the sky and clouds.
While the search implementation isn’t perfect, it does give us an additional entry point into an extensive collection of data which is difficult to explore manually. It is possible to extend this interface to accommodate an image similarity feature. This could be useful for identifying a particular artist’s work in a broader collection.
Image classification
While image search helps us find images, it doesn’t help us as much if we want to describe all the images in our collection. For this, we’ll need a slightly different type of machine learning task – image classification. An image classification model will put our images into categories drawn from a list of possible labels.
We can find image classification models on the Hugging Face Hub. The “Image Classification Model Tester” tab in the demo Gradio application allows us to test most of the 3,000+ image classification models hosted on the Hub against our dataset.
This can give us a sense of a few different things:
- How well do the labels for a model match our data?A model for classifying dog breeds probably won’t help us much!
- It gives us a quick way of inspecting possible errors a model might make with our data.
- It prompts us to think about what categories might make sense for our images.
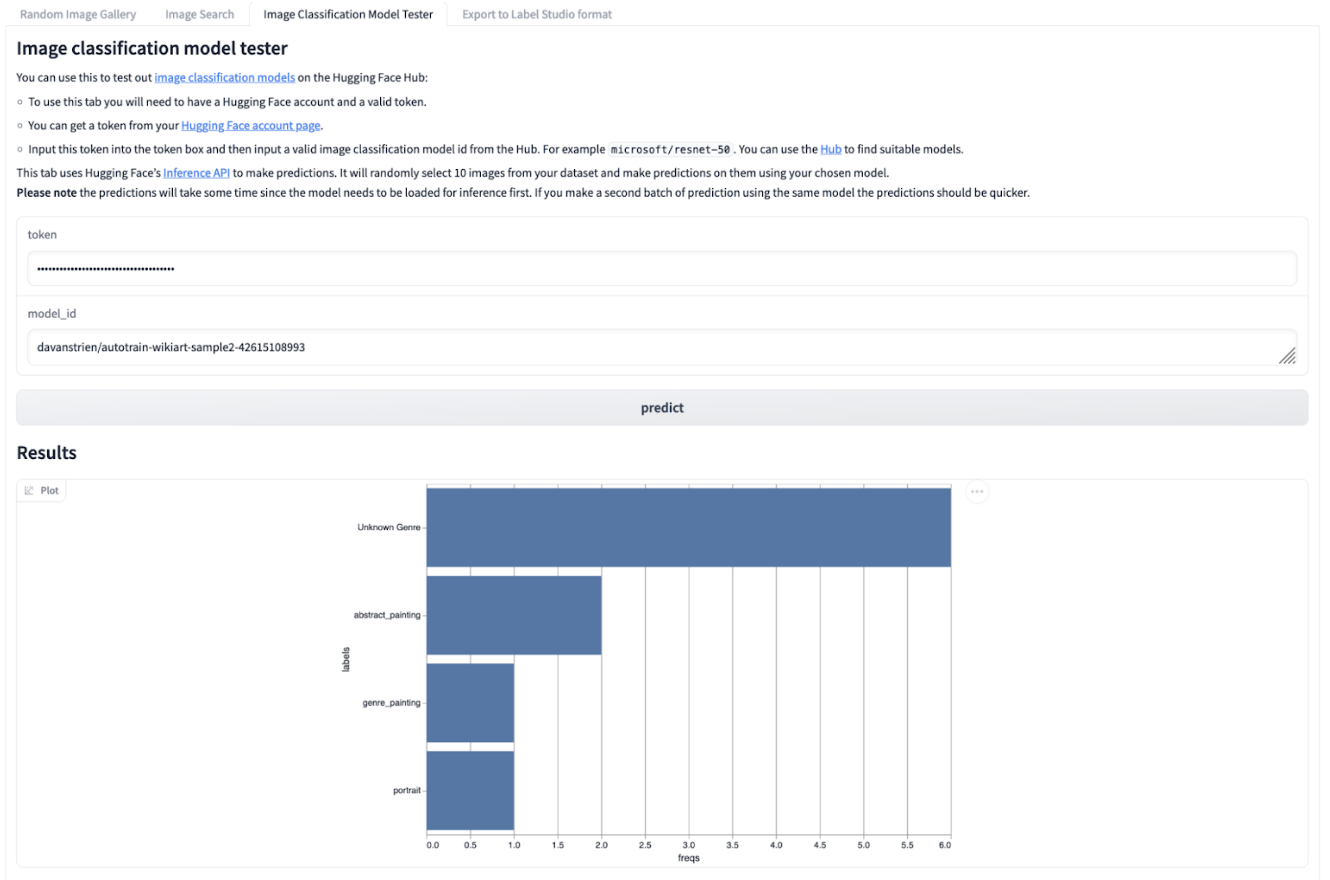
A screenshot of the image classification tab in the Gradio app which shows a bar chart with the most frequently predicted labels for images assigned by a computer vision model.
We may find a model that already does a good job working with our dataset – if we don’t, we may have to look at training a model.
Training your own computer vision model
The final tab of our Gradio demo allows you to export the image dataset in a format that can be loaded by Label Studio, an open-source tool for annotating data in preparation for machine learning tasks. In Label Studio, we can define labels we would like to apply to our dataset. For example, we might decide we’re interested in pulling out particular types of images from this collection. We can use Label Studio to create an annotated version of our dataset with these labels. This requires us to assign labels to images in our dataset with the correct labels. Although this process can take some time, it can be a useful way of further exploring a dataset and making sure your labels make sense.
With a labeled dataset, we need some way of training a model. For this, we can use AutoTrain. This tool allows you to train machine learning models without writing any code. Using this approach supports creation of a model trained on our dataset which uses the labels we are interested in. It’s beyond the scope of this post to cover all AutoTrain features, but this post provides a useful overview of how it works.
Next Steps
As mentioned in the introduction, you can explore the ARCH Image Dataset Explorer Demo yourself. If you know a bit of Python, you could also duplicate the Space and adapt or change the current functionality it supports for exploring the dataset.
Internet Archive and Hugging Face plan to organize a hands-on hackathon later this year focused on using open source machine learning tools from the Hugging Face ecosystem to work with web archives. The event will include building interfaces for web archive datasets, collaborative annotation, and training machine learning models. Please let us know if you are interested in participating by filling out this form.