Please join us on October 18th 6:00- 8:00 pm as we take a peek behind the doors of the Physical Archive in Richmond, California
In anticipation of launching Democracy’s Library on October 19th we are excited to offer a behind-the-scenes tour of our physical collections of books, music, film, and video in Richmond, California.
With this special insider event we are opening the doors to an often unseen place. See the lifecycle of physical books acquired by the Internet Archive — donation, preservation, digitization, and access. We’ll also present samples from generous donations and acquisitions of books, records, microfiche, and film, and demonstrate the Archive’s high-end motion-picture film scanner.
We look forward to offering this glimpse into a very important part of the Internet Archive in its mission to bring Universal Access to All Knowledge.
The Internet Archive is requesting donations of Ukrainian books and books useful to Ukrainians. The books will be preserved, digitized and lent (for free to one user at a time) over the Internet. The Internet Archive is prioritizing the digitization and hosting of relevant materials for Ukrainians.
25 years ago, Brewster Kahle founded the Internet Archive, now one of the world’s largest digital libraries.
NOTE: On October 21, 2021, the Internet Archive celebrated its 25th anniversary in a virtual event featuring this keynote address by Founder & Digital Librarian, Brewster Kahle. You can watch the talk here or read the transcript below.
Universal Access to All Knowledge has been the dream for millennia, from the Library of Alexandria on forward. The idea is that if you’re curious enough to want to know something, that you can get access to that information. That was the promise of the printing press or Andrew Carnegie’s public libraries — fueling so much citizenship and democracy in the United States. The Internet was the opportunity to really make this dream come true.
What we have is an opportunity that happens maybe only once a millennium. The opportunity that comes only when we change how knowledge is recorded and shared. From oral to manuscript, manuscript to printing, and now from printing to digital. I was lucky enough to be there in 1980 and thought: what a fantastic opportunity to try to influence that transition.
From Life magazine, Volume 19, Number 11, Sept 10, 1945
Of course, we were building on the vision of many before us. This dream of having an interlocking publishing system had been around for a long time. Vannevar Bush’s 1945 article “As We May Think” was very much on people’s minds in the 1980s. There was Ted Nelson’s Xanadu—a world of hypertext. Doug Engelbart’s way of annotating and enabling you to build on the works of others.
The key thing was not the computers. Actually, it was the network. It was the ability to communicate with each other. Sure, anybody could go and write word processing documents. That’s good. But can you make everybody a publisher? Can everyone find their voice and their community no matter where they are in the world? And can people write in a way that allows others to build on their work? By 1996, we had built that. It was the World Wide Web.
With this global publishing network, the Web, we could finally build the library. It was time to build the library. In 1996, I thought: Why don’t we just build this thing? I mean, how hard could it be? Sure, maybe we’re going to have to go and digitize a whole library, but that couldn’t be that hard, right?
And so, a group of us said, let’s do this. We started by archiving the most transient of media, which was the World Wide Web’s pages. We did that for five years before we even made the Wayback Machine. The idea was to record what people were publishing and be able to go and use that in new and different ways. Could we build a library to preserve all of that material, but then add computers to the mix, so that something new and magic happens? Could we connect people, connect ideas, build on each other’s concepts with computers and these new AI things that we knew were coming. Ultimately could we make the world smarter?
Could we make people smarter by being better connected? Not just because they could read what other people were writing, but because machines would help filter information, scan vast amounts of knowledge, emphasize what is most important, provide context to the deluge.
In many ways, we have achieved this, but not completely enough: now people are writing and sharing knowledge, but it is intermingled with misinformation — purposefully false information. We still don’t have the tools to filter out the lies, and in many ways, we have business models that prosper when misinformation is widely shared. So while the dream of access may be at hand, we lack the tools and responsible organizations to help us make good use of the flood of data now at our fingertips. Given how new our digital transition is, this may not be that surprising, but it is an urgent issue that faces us. We need to fight misinformation and build data-mining tools to leverage all this knowledge to help people make better decisions — to be smarter.
This is our challenge for our next 25 years.
When we started the Internet Archive, I felt this project needed to be done in the open and as a non-profit. We needed to have not just one or two search engines, we needed lots and lots of different organizations building their new ideas on top of the whole knowledge base of humanity. We could help by being a library for this new digital world.
Caslon & Brewster Kahle in front of the Carnegie Library in Pittsburgh, October 9, 2002.
The libraries I grew up with were vast and free, and came with librarians who helped me understand and find things I needed to know. In our new digital world, that future is not guaranteed. It may be that most people will just feed on what they can access for free, placed there because it’s promoted by somebody. If we don’t solve this–getting quality published material to the internet population–we’re going to bring up a generation educated on whatever dreck they can find online. So we have to build not only universal access to lots of webpages, but access to the right and best information– Universal Access to All Knowledge. That is going to require requiring changes to existing business models and adjustments by long standing institutions. We need an Internet with many winners. If we have an Internet with just a few winners, some big corporations and large governments that are controlling too much of what’s online, then we will all lose.
A library alone can not solve all of these issues, but it is a necessary component, needed infrastructure in a digital world.
On October 12, 2012, the Internet Archive reached 10 petabytes of data stored in its repository.
25 years ago, I thought building this new library would largely be a technological process, but I was wrong. It turns out that it’s mostly a people process. Crucially, the Internet Archive has been supported by hundreds of organizations. About 800 libraries have helped build the web collections that are in the Wayback Machine. Over 1000 libraries have contributed books to be digitized into the collections—now 5 million volumes strong. And beyond that, people with expertise in, say, railway timetables, Old Time Radio, 78 RPM records—they’ve been donating physical media and uploading digital files to our servers that you see here in this room. Last year, well over 100 million people used the resources of the Internet Archive, and over 100,000 people made a financial donation to support us. This has truly been a global project– the people’s library.
I love the weird and wacky stuff of the Internet, just the fun and frolicy things. You go online and see these things like, wow, that’s remarkable.
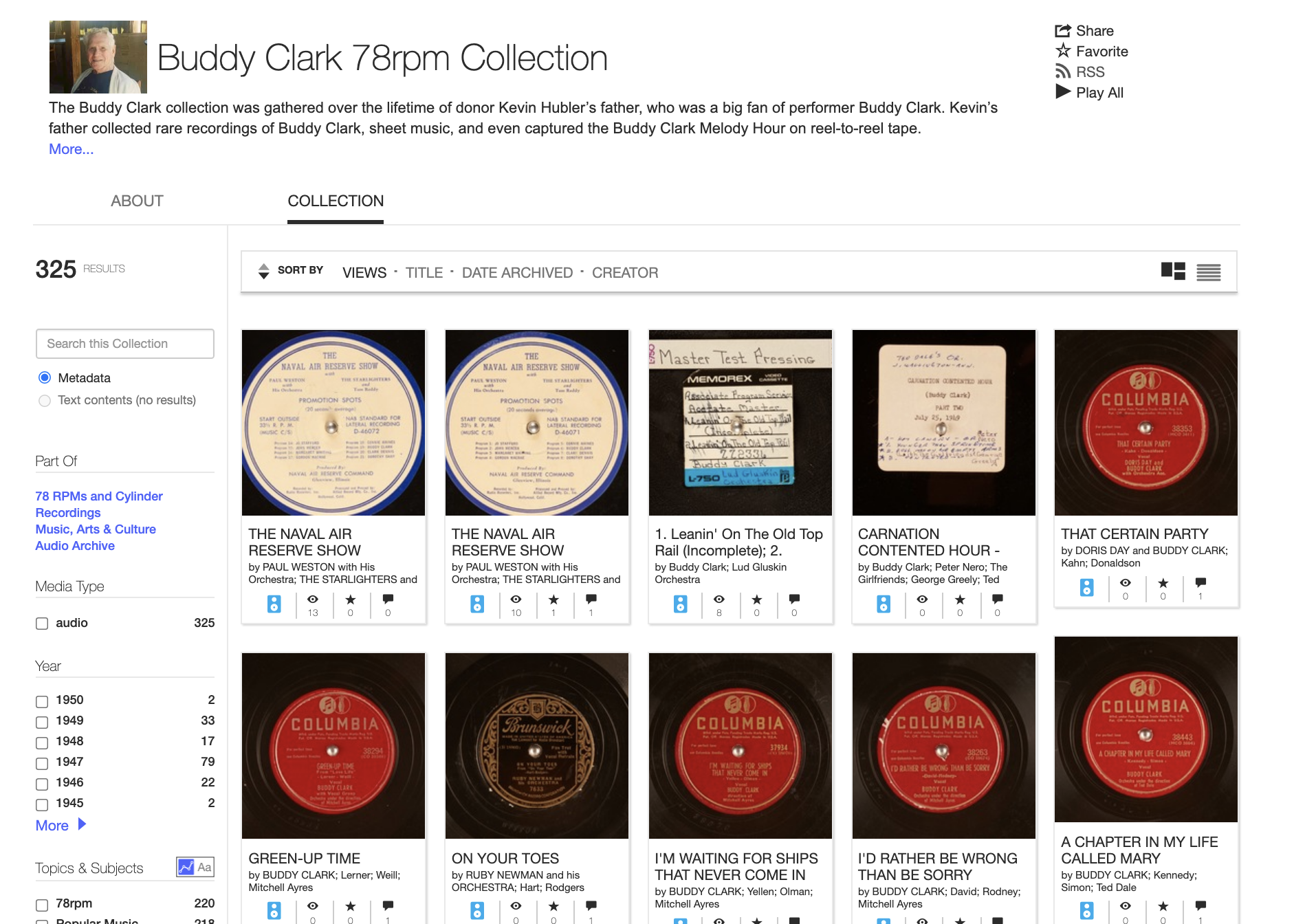
Yesterday, I was looking through the uploads from Kevin Hubler. He donated the collection his father built over his lifetime. His father collected everything a particular singer, Buddy Clark, had ever done. Clark was a 1940’s big band singer who died when he was 37. So I could listen to records, see sheet music, and dive into details, all thanks to Kevin Hubler. I love this– going down rabbit holes and learning something deeply. This was a tribute to Buddy Clark, but also to Kevin and his father– who prepared and preserved something they loved for the future.
That we’re able to enjoy each other and to express our wackiness– that’s the win of the World Wide Web! That’s the thing that you wouldn’t get if it were all just more channels of television. Yes, the internet and the World Wide Web are a bit of the Wild West, but would you want it any other way? Isn’t that where the fun and interesting things come from?
Today, it is still the people’s internet. That’s the internet that I wanted to support by starting the Internet Archive. The World Wide Web is an experiment in radical sharing where people feel that they’re better off, not worse off, building on other people’s works.
I’m hopeful and optimistic that we can build this next 25 years to be as interesting and fun as the last. That we can usher in another level of technology, another 25 years of blossoming, interesting ideas.
Douglas Lurton, Grandfather & Author
I want to end this talk with a personal story– my grandfather Douglas Lurton was a publisher and an author who died before I was born. Last weekend I searched for his name using full text search in the 20 million texts now on the Archive and found this quotation from him in a newspaper from West Sacramento: “Take the tools in hand and carve your own best life.” — Douglas Lurton
Now, I would like to extend my grandfather’s advice. “Let us all take our tools in hand, and together, carve our own best future.”
The Internet Archive is pleased to announce it has joined the The Information Delivery Services (IDS) Project, a mutually supportive resource-sharing cooperative whose 120 members include public and private academic libraries from across the country. As a member of the IDS Project, the Internet Archive expands its ability to support libraries and library patrons by providing access to two million monographs and three thousand periodicals in its physical collections available for non-returnable interlibrary loan (ILL) fulfillment.
“The Internet Archive is a wonderful addition to the IDS Project’s team of libraries. It is a great honor to be able to help IA reach more libraries and more patrons through the integration with IDS Logic,” said Mark Sullivan, Executive Director of the IDS Project.
If you want to learn more about the IDS Project and the Internet Archive, I will be speaking at the 17th Annual IDS Summer Conference on July 29th.
In addition to the IDS Project, the Internet Archive is also piloting a program with libraries through RapidILL. If there are other resource sharing efforts that we should investigate as we expand our ILL service, please reach out to me at brewster@archive.org.
Photo by Rory Mitchell, The Mercantile, 2020 – CC by 4.0
(L-R) Brewster Kahle, Tamiko Thiel, Carl Feynman at Thinking Machines, May 1985. Photo courtesy of Tamiko Thiel.
A Library of Everything
As a young man, I wanted to help make a new medium that would be a step forward from Gutenberg’s invention hundreds of years before.
By building a Library of Everything in the digital age, I thought the opportunity was not just to make it available to everybody in the world, but to make it better–smarter than paper. By using computers, we could make the Library not just searchable, but organizable; make it so that you could navigate your way through millions, and maybe eventually billions of web pages.
The first step was to make computers that worked for large collections of rich media. The next was to create a network that could tap into computers all over the world: the Arpanet that became the Internet. Next came augmented intelligence, which came to be called search engines. I then helped build WAIS–Wide Area Information Server–that helped publishers get online to anchor this new and open system, which came to be enveloped by the World Wide Web.
By 1996, it was time to start building the library.
This library would have all the published works of humankind. This library would be available not only to those who could pay the $1 per minute that LexusNexus charged, or only at the most elite universities. This would be a library available to anybody, anywhere in the world. Could we take the role of a library a step further, so that everyone’s writings could be included–not only those with a New York book contract? Could we build a multimedia archive that contains not only writings, but also songs, recipes, games, and videos? Could we make it possible for anyone to learn about their grandmother in a hundred years’ time?
From the San Francisco Chronicle, Business Section, May 7, 1988. Photo by Jerry Telfer.
Not about an Exit or an IPO
From the beginning, the Internet Archive had to be a nonprofit because it contains everybody else’s things. Its motives had to be transparent. It had to last a long time.
In Silicon Valley, the goal is to find a profitable exit, either through acquisition or IPO, and go off to do your next thing. That was never my goal. The goal of the Internet Archive is to create a permanent memory for the Web that can be leveraged to make a new Global Mind. To find patterns in the data over time that would provide us with new insights, well beyond what you could do with a search engine. To be not only a historical reference but a living part of the pulse of the Internet.
John Perry Barlow, lyricist for the Grateful Dead & founder of the Electronic Frontier Foundation, accepting the Internet Archive Hero Award, October 21, 2015. Photograph by Brad Shirakawa – CC by 4.0
Looking Way Back
My favorite things from the early era of the Web were the dreamers.
In the early Web, we saw people trying to make a more democratic system work. People tried to make publishing more inclusive.
We also saw the other parts of humanity: the pornographers, the scammers, the spammers, and the trolls. They, too, saw the opportunity to realize their dreams in this new world. At the end of the day, the Internet and the World Wide Web–it’s just us. It’s just a history of humankind. And it has been an experiment in sharing and openness.
The World Wide Web at its best is a mechanism for people to share what they know, almost always for free, and to find one’s community no matter where you are in the world.
Brewster Kahle speaking at the 2019 Charleston Library Conference. Photo by Corey Seeman– CC by 4.0
Looking Way Forward
Over the next 25 years, we have a very different challenge. It’s solving some of the big problems with the Internet that we’re seeing now. Will this be our medium or will it be theirs? Will it be for a small controlling set of organizations or will it be a common good, a public resource?
So many of us trust the Web to find recipes, how to repair your lawnmower, where to buy new shoes, who to date. Trust is perhaps the most valuable asset we have, and squandering that trust will be a global disaster.
We may not have achieved Universal Access to All Knowledge yet, but we still can.
In another 25 years, we can have writings from not a hundred million people, but from a billion people, preserved forever. We can have compensation systems that aren’t driven by advertising models that enrich only a few.
We can have a world with many winners, with people participating, finding communities of like-minded people they can learn from all over the world. We can create an Internet where we feel in control.
I believe we can build this future together. You have already helped the Internet Archive build this future. Over the last 25 years, we’ve amassed billions of pages, 70 petabytes of data to offer to the next generation. Let’s offer it to them in new and exciting ways. Let’s be the builders and dreamers of the next twenty-five years.
See a timeline of Key Moments in Access to Knowledge, videos & an invitation to our 25th Anniversary Virtual Celebration at anniversary.archive.org.
The pandemic has resulted in a renewed focus on resource sharing among libraries. In addition to joining resource sharing organizations like the Boston Library Consortium, the Internet Archive has started to participate in the longstanding library practice of interlibrary loan (ILL).
Internet Archive is now making two million monographs and three thousand periodicals in its physical collections available for non-returnable fulfillment through a pilot program with RapidILL, a prominent ILL coordination service. To date, more than seventy libraries have added the Internet Archive to their reciprocal lending list, and Internet Archive staff are responding to, on average, twenty ILL requests a day. If your library would like to join our pilot in Rapid, please reach out to Mike Richins at Mike.Richins@exlibrisgroup.com and request that Internet Archive be added to your library’s reciprocal lending list.
If there are other resource sharing efforts that we should investigate as we pilot our ILL service, please reach out to Brewster Kahle at brewster@archive.org.
The Internet Archive is wholly dependent on Ubuntu and the Linux communities that create a reliable, free (as in beer), free (as in speech), rapidly evolving operating system. It is hard to overestimate how important that is to creating services such as the Internet Archive.
When we started the Internet Archive in 1996, Sun and Oracle donated technology and we bought tape robots. By 1999, we shifted to inexpensive PC’s in a cluster, running varying Linux distributions.
At this point, almost everything that runs on the servers of the Internet Archive is free and open-source software. (I believe our JP2 compression library may be the only piece of proprietary software we use.)
For a decade now, we have been upgrading our operating system on the cluster to the long-term support server Linux distribution of Ubuntu. Thank you, thank you. And we have never paid anything for it, but we submit code patches as the need arises.
Does anyone know the number of contributors to all the Linux projects that make up the Ubuntu distribution? How many tens or hundreds of thousands? Staggering.
Ubuntu has ensured that every six months a better release comes out, and every two years a long-term release comes out. Like clockwork. Kudos. I am sure it is not easy, but it is inspiring, valuable and important to the world.
We started with Linux in 1997, we started with Ubuntu server release Warty Warthog in 2004 and are in the process of moving to Focal (Ubuntu 20.4).
Depending on free and open software is the smartest technology move the Internet Archive ever made.
Discogs has cracked the nut, struck the right balance, and is therefore an absolute Internet treasure– Thank you.
If you don’t know them, Discogs is a central resource for the LP/78/CD music communities, and as Wikipedia said “As of 28 August 2019 Discogs contained over 11.6 million releases, by over 6 million artists, across over 1.3 million labels, contributed from over 456,000 contributor user accounts—with these figures constantly growing…”
When I met the founder, Kevin Lewandowski, a year ago he said the Portland based company supports 80 employees and is growing. They make money by being a marketplace for buyers and sellers of discs. An LP dealer I met in Oklahoma sells most of his discs through discogs as well as going at record fairs.
The data about records is spectacularly clean. Compare it to Ebay, where the data is scattershot, and you have something quite different and reusable. It is the best parts of musicbrainz, CDDB, and Ebay– where users can catalog their collections and buy/sell records. By starting with the community function, Kevin said, the quality started out really good, and then adding the market place later led it to its success.
But there is something else Discogs does that sets it apart from many other commercial websites, and this makes All The Difference:
The Great 78 Project has leveraged this bulk database to help find the date of release for 78’s. Just yesterday, I downloaded the new dataset and added it to our 78rpm date database, and in last year 10’s of thousands more 78’s were added to discogs, and we found 1,500 more dates for our existing 78’s. Thank you!
The Internet Archive Lost Vinyl Project leverages the API’s by looking up records we will be digitizing to find track listings.
A donor to our CD project used the public price information to appraise the CDs he donated for a tax write-off.
We want to add links back from Discogs to the Internet Archive and they have not allowed that yet (please please), but there is always something more to do.
I hope other sites, even commercial ones, would allow bulk access to their data (an API is not enough).
I have never been more encouraged and thankful to Free and Open Source communities. Three months ago I posted a request for help with OCR’ing and processing 19th Century Newspapers and we got soooo many offers to help. Thank you, that was heart warming and concretely helpful– already based on these suggestions we are changing over our OCR and PDF software completely to FOSS, making big improvements, and building partnerships with FOSS developers in companies, universities, and as individuals that will propel the Internet Archive to have much better digitized texts. I am so grateful, thank you. So encouraging.
I posted a plea for help on the Internet Archive blog: Can You Help us Make the 19th Century Searchable? and we got many social media offers and over 50 comments the post– maybe a record response rate.
We are already changing over our OCR to Tesseract/OCRopus and leveraging many PDF libraries to create compressed, accessible, and archival PDFs.
Several people suggested the German government-lead initiative called OCR-D that has made production level tools for helping OCR and segment complex and old materials such as newspapers in the old German script Fraktur, or black letter. (The Internet Archive had never been able to process these, and now we are doing it at scale). We are also able to OCR more Indian languages which is fantastic. This Government project is FOSS, and has money for outreach to make sure others use the tools– this is a step beyond most research grants.
Tesseract has made a major step forward in the last few years. When we last evaluated the accuracy it was not as good as the proprietary OCR, but that has changed– we have done evaluations and it is just as good, and can get better for our application because of its new architecture.
Underlying the new Tesseract is a LSTM engine similar to the one developed for Ocropus2/ocropy, which was a project led by Tom Breuel (funded by Google, his former German University, and probably others– thank you!). He has continued working on this project even though he left academia. A machine learning based program is introducing us to GPU based processing, which is an extra win. It can also be trained on corrected texts so it can get better.
New one, based on free and open source software that is still faulty but better:
The time it takes on our cluster to compute is approximately the same, but if we add GPU’s we should be able to speed up OCR and PDF creation, maybe 10 times, which would help a great deal since we are processing millions of pages a day.
The PDF generation is a balance trying to achieve small file size as well as rendering quickly in browser implementations, have useful functionality (text search, page numbers, cut-and-paste of text), and comply with archival (PDF/A) and accessibility standards (PDF/UA). At the heart of the new PDF generation is the “archive-pdf-tools” Python library, which performs Mixed Raster Content (MRC) compression, creates a hidden text layer using a modified Tesseract PDF renderer that can read hOCR files as input, and ensures the PDFs are compatible with archival standards (VeraPDF is used to verify every PDF that we generate against the archival PDF standards). The MRC compression decomposes each image into a background, foreground and foreground mask, heavily compressing (and sometimes downscaling) each layer separately. The mask is compressed losslessly, ensuring that the text and lines in an image do not suffer from compression artifacts and look clear. Using this method, we observe a 10x compression factor for most of our books.
And best of all, we have expanded our community to include people all over the world that are working together to make cultural materials more available. We have a slack channel for OCR researchers and implementers now, that you can join if you would like (to join, drop an email to merlijn@archive.org). We look to contribute software and data sets to these projects to help them improve (lead by Merlijn Wajer and Derek Fukumori).
Next steps to fulfill the dream of Vanevar Bush’s Memex, Ted Nelson’s Xanadu, Michael Hart’s Project Gutenberg, Tim Berners-Lee’s World Wide Web, Raj Ready’s call for Universal Access to All Knowledge (and now the Internet Archive’s mission statement):
Find articles in periodicals, and get the titles/authors/footnotes
There are many computer science projects, decentralized storage, and digital humanties projects looking for data to play with. You came to the right place– the Internet Archive offers cultural information available to web users and dataminers alike.
While many of our collections have rights issues to them so require agreements and conversation, there are many that are openly available for public, bulk downloading.
Here are 3 collections, one of movies, another of audio books, and a third are scanned public domain books from the Library of Congress. If you have a macintosh or linux machine, you can use those to run these command lines. If you run each for a little while you can get just a few of the items (so you do not need to download terabytes).
These items are also available via bittorrent, but we find the Internet Archive command line tool is really helpful for this kind of thing:
$ curl -LOs https://archive.org/download/ia-pex/ia $ chmod +x ia $ ./ia download –search=”collection:prelinger” #17TB of public domain movies $ ./ia download –search=”collection:librivoxaudio” #20TB of public domain audiobooks $ ./ia download –search=”collection:library_of_congress” #166,000 public domain books from the Library of Congress (60TB)
Here is a way to figure out how much data is in each:
Sorry to say we do not yet have a support group for people using these tools or finding out what data is available, so for the time being you are pretty much on your own.























{kind=link}