The Internet Archive has transformed 130,000 references to books in Wikipedia into live links to 50,000 digitized Internet Archive books in several Wikipedia language editions including English, Greek, and Arabic. And we are just getting started. By working with Wikipedia communities and scanning more books, both users and robots will link many more book references directly into Internet Archive books. In these cases, diving deeper into a subject will be a single click.

“I want this,” said Brewster Kahle’s neighbor Carmen Steele, age 15, “at school I am allowed to start with Wikipedia, but I need to quote the original books. This allows me to do this even in the middle of the night.”
For example, the Wikipedia article on Martin Luther King, Jr cites the book To Redeem the Soul of America, by Adam Fairclough. That citation now links directly to page 299 inside the digital version of the book provided by the Internet Archive. There are 66 cited and linked books on that article alone.
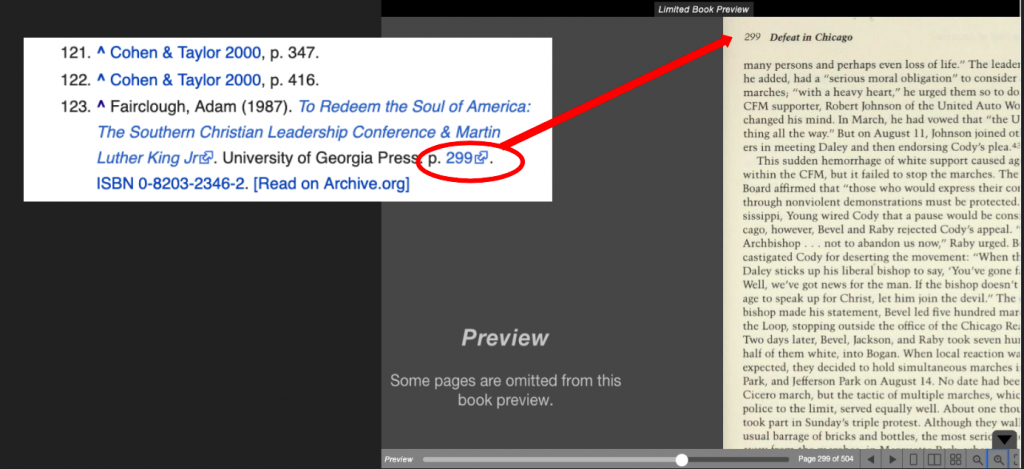
Readers can see a couple of pages to preview the book and, if they want to read further, they can borrow the digital copy using Controlled Digital Lending in a way that’s analogous to how they borrow physical books from their local library.
“What has been written in books over many centuries is critical to informing a generation of digital learners,” said Brewster Kahle, Digital Librarian of the Internet Archive. “We hope to connect readers with books by weaving books into the fabric of the web itself, starting with Wikipedia.”
You can help accelerate these efforts by sponsoring books or funding the effort. It costs the Internet Archive about $20 to digitize and preserve a physical book in order to bring it to Internet readers. The goal is to bring another 4 million important books online over the next several years. Please donate or contact us to help with this project.

“Together we can achieve Universal Access to All Knowledge,” said Mark Graham, Director of the Internet Archive’s Wayback Machine. “One linked book, paper, web page, news article, music file, video and image at a time.”