A post by the Archive-It team
Today Phase 1 of the 5.0 release of the Archive-It web application was released for use by the 326 partners using the Archive-It service.
In 1996 when the Internet Archive was founded, we used automated crawlers to capture the web, snapping up millions of web pages and preserving them for history. Ironically, our digital record of humankind was being driven by computer algorithms.
As the years went by, it became clear that we needed people and communities to capture and save what is really and truly important. So in February 2006 we launched the Archive-It service, 1.0, which allowed traditional librarians and archivists to become web archivists by initiating focused, curated crawls of the live web using a simple web application with partner/tech support. Launching Archive-It meant we could help our colleagues create their own web collections for their own libraries and also foster a community around web archiving to work together to build a global digital public library at www.archive.org.
Now, as we expand to the next generation of Archive-It with our 5.0 release, we hope to provide even greater tools for collection development. Released this week, 5.0 phase 1 highlights a shiny new user interface and significantly enhanced post-crawl reports that include infographics with visual representations of the data.
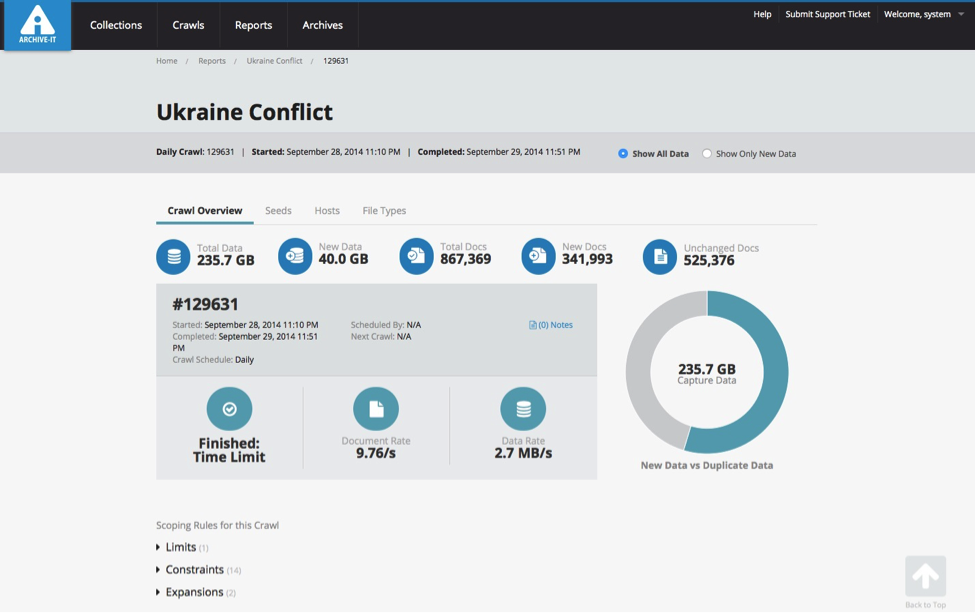
Figure 1: Screenshot from the Reports section of the new Archive-It 5.0 user interface
Back in 2006 there was little understanding of web archiving and many organizations were questioning whether this was a valid activity that could or should be a part of their larger institutional collecting strategies. After all, the challenges were staggering: the quality of web content was all over the map; conflicting policies and organizational structures posed challenges; no one had yet established best practices for selecting the content, how to handle metadata, or how to integrate this new type of content into other holdings and existing catalogs at the institution. Also, back then we could not have predicted the extent to which material that once existed in physical form would now only appear on the web in digital form.
We launched the Archive-It service with a small band of believers and supporters, among them librarians and archivists from Indiana University, University of Texas at Austin, Library of Virginia, Montana State Library, and North Carolina State Archives and State Library. Partners were very patient with us and with Archive-It 1.0, which was bare bones. Collaborating and working with the library and archive community has always been a top priority for the Internet Archive, and a defining characteristic of the Archive-It service. There have been many times during the past 8+ years when we have not known the answer to a question and we say: “Let’s ask the community and see what they think!” And the community has always gotten back to us with supportive answers – both illustrative and specific.
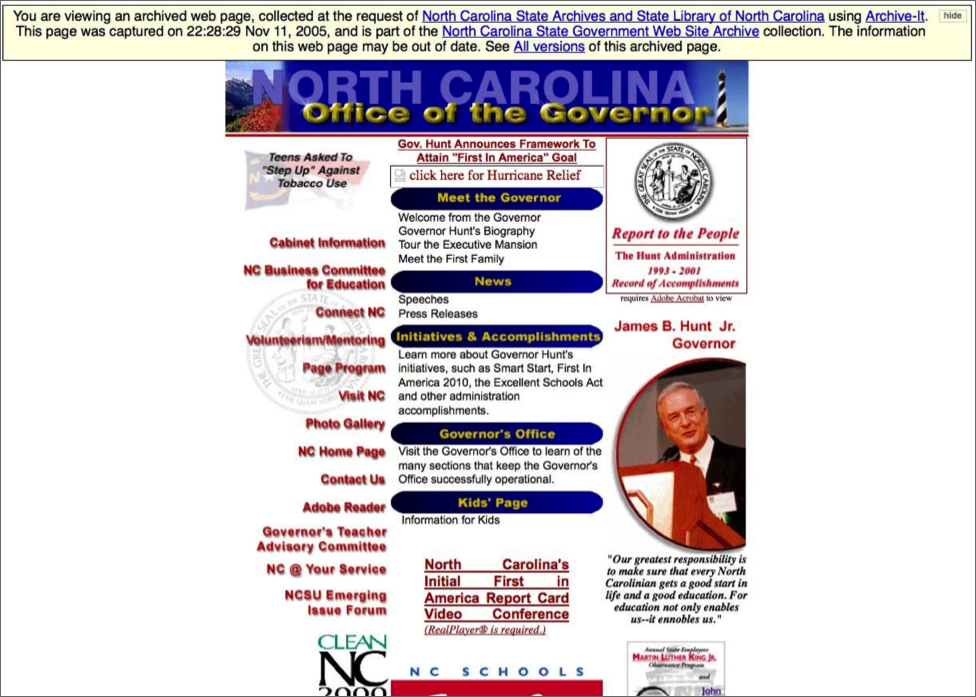
Figure 2: Screenshot from the North Carolina State Government Web Site Archive of the North Carolina State Archives and State Library of North Carolina.
As time went on, the community of web archivists grew and we were able to produce some compelling answers to the question: why web archive? Here are just a few:
- To create a thematic or topical web archive
- To fulfill a mandate to preserve institutional memory and history
- To archive state or local agency publications no longer being deposited in print form
- To archive records to meet university or government retention policies
- To preserve an historical record of an institution’s web and /or social media presence
- To capture a website before re-design or it is taken offline
- To archive online art, exhibitions, and artists’ materials
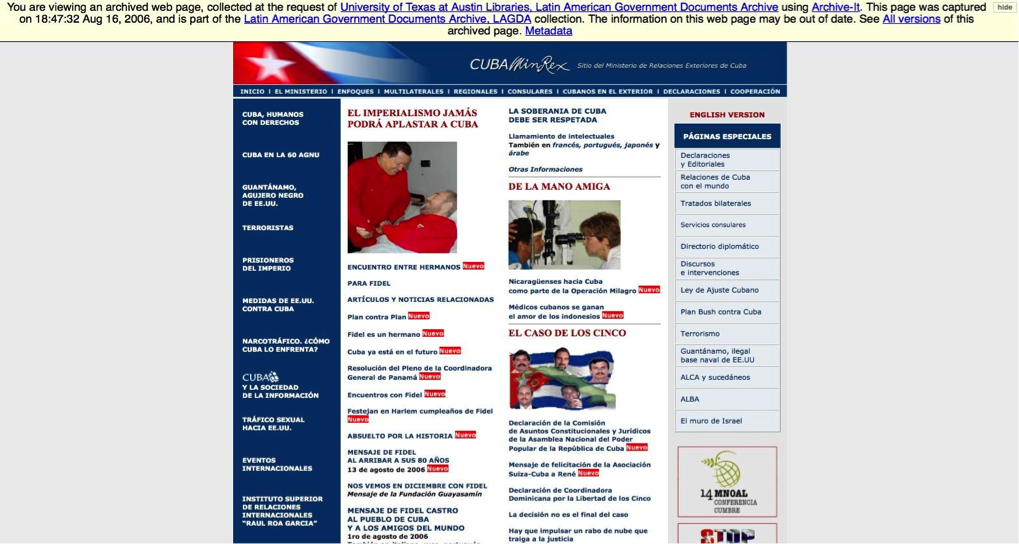
Figure 3: Screenshot from the Latin American Government Documents Archive, LAGDA of the University of Texas at Austin.
 Figure 4: Screenshot from the Catalogues Raisonnés collection of the New York Art Resources Consortium (NYARC).
Figure 4: Screenshot from the Catalogues Raisonnés collection of the New York Art Resources Consortium (NYARC).
To date in 2014, 326 Archive-It partners have created 2700 public collections on a diversity and range of topics, subjects, events and domains. These collections have become integral to these organizations’ collecting strategies and have helped to raise awareness and understanding about why web archiving is so important.
We like to say that the Archive-It service is both a partner and a vendor. We are a service provider and we strive to consistently deliver a high level of customer support — which we believe partners notice and appreciate. We also strive to be a partner to our community and work collaboratively on initiatives that we share together; a few of which are: a) collaborative efforts around archiving spontaneous events (like the 2011 Japanese Earthquake collection), b) teaching web archiving in graduate level MLIS programs and professional development workshops and c) the K12 Web Archiving program (now in its 7th year) where we work with 3rd to 12 graders around the county and ask them what they would like to archive for future generations. As one of the student archivists put it, “500 years from now, kids will think we were really cool.”
Many of the features and functionality that we see in the Archive-It service today are a direct result of a partner making a suggestion or request. Through face to face brainstorming sessions, online surveys, webinars, and support tickets, partners have expressed their ideas as well as offered constructive criticism. And we have listened. We hope that as the service continues to grow and we launch Archive-It 5.0 that many of our partners will see themselves in Archive-It. Their collections will continue to be valuable to researchers, historians, scholars and the general public for many years to come.
Here are some links to just a few of those collections on the Archive-It website:
Columbia University’s collection on Human Rights: https://archive-it.org/collections/1068
National Museum of Women in the Arts’s collection on Contemporary Women Artists on the Web: https://archive-it.org/collections/2973
University of Alberta’s Circumpolar Collection: https://archive-it.org/collections/2475
Brigham Young University’s Mormon Missionary Collection: https://archive-it.org/collections/3609
Stanford University’s collection on Freedom of Information (FOIA): https://archive-it.org/collections/924
As we continue down this road – excited for the future and what comes next – we know that it takes a community to archive the web and we look forward to working with our partners to build libraries together.
 Internet activist and founder of Public.Resource.org, Carl Malamud is launching a national campaign to free millions of court documents in PACER–Public Access to Court Electronic Records–the technologically backwards federal electronic system that charges Americans 10 cents per page to access court files in the public domain. This Friday, you can come by the Internet Archive “polling place” at 300 Funston Avenue., San Francisco from 8 a.m. to 5 p.m. to “cast your vote” for free court records. Carl will be on hand with inspiring postcards addressed to Chief Judge Thomas of the Ninth Circuit Court of Appeals. By sending His Honor hundreds of handwritten postcards asking him to grant a PACER fee-exemption, we can save tax-payers millions of dollars, while freeing court documents crucial to understanding and interpreting the law.
Internet activist and founder of Public.Resource.org, Carl Malamud is launching a national campaign to free millions of court documents in PACER–Public Access to Court Electronic Records–the technologically backwards federal electronic system that charges Americans 10 cents per page to access court files in the public domain. This Friday, you can come by the Internet Archive “polling place” at 300 Funston Avenue., San Francisco from 8 a.m. to 5 p.m. to “cast your vote” for free court records. Carl will be on hand with inspiring postcards addressed to Chief Judge Thomas of the Ninth Circuit Court of Appeals. By sending His Honor hundreds of handwritten postcards asking him to grant a PACER fee-exemption, we can save tax-payers millions of dollars, while freeing court documents crucial to understanding and interpreting the law. You can also send your postcard directly if you can’t make it to the Internet Archive on Friday:
You can also send your postcard directly if you can’t make it to the Internet Archive on Friday:
 As part of their
As part of their  Candidates for the Internet Archive Work Transition Program are men and women from BARM who have completed a 12-month sober living, drug counseling or domestic abuse crisis program and are ready to re-enter the job market. This group often lacks relevant job skills, recent work experience, interpersonal and work relationship skills, self-confidence and, a résumé that a national or local employer would find compelling enough to grant an interview. The curriculum for the Internet Archive Work Transition Program lasts 9 months and focuses on ‘Learning-to-Work’. This three-phase program was based on lessons learned from the 600+ staff that the Archive has hired over the past 8 years. From these lessons, a program of progressive responsibility, constant feedback and a merit badging system was built to meet this challenge. Miller notes that this is not a make-work program. The work is substantive and needs to be completed to help get content online to share with the global community. “The Internet Archive
Candidates for the Internet Archive Work Transition Program are men and women from BARM who have completed a 12-month sober living, drug counseling or domestic abuse crisis program and are ready to re-enter the job market. This group often lacks relevant job skills, recent work experience, interpersonal and work relationship skills, self-confidence and, a résumé that a national or local employer would find compelling enough to grant an interview. The curriculum for the Internet Archive Work Transition Program lasts 9 months and focuses on ‘Learning-to-Work’. This three-phase program was based on lessons learned from the 600+ staff that the Archive has hired over the past 8 years. From these lessons, a program of progressive responsibility, constant feedback and a merit badging system was built to meet this challenge. Miller notes that this is not a make-work program. The work is substantive and needs to be completed to help get content online to share with the global community. “The Internet Archive 
 To ‘grease the skids’ for the Work Transition Program graduates, Hammack and Miller contacted local companies, explaining that the program was not a handout and they weren’t looking for charity. They simply asked for a commitment from employers to grant the graduate an interview. Upon reviewing the program goals and expectations, local businesses including UPS, San Francisco Public library, Costco and others signed on. The first class graduates in February 2015, but already two of the candidates have secured part-time employment.
To ‘grease the skids’ for the Work Transition Program graduates, Hammack and Miller contacted local companies, explaining that the program was not a handout and they weren’t looking for charity. They simply asked for a commitment from employers to grant the graduate an interview. Upon reviewing the program goals and expectations, local businesses including UPS, San Francisco Public library, Costco and others signed on. The first class graduates in February 2015, but already two of the candidates have secured part-time employment. Rick Prelinger’s Lost Landscapes of San Francisco is back for one final performance this year! Now you can catch this perennially sold-out show and your ticket donation will benefit the Internet Archive, a nonprofit digital library which hosts the Prelinger Collection. Please give generously to support the effort.
Rick Prelinger’s Lost Landscapes of San Francisco is back for one final performance this year! Now you can catch this perennially sold-out show and your ticket donation will benefit the Internet Archive, a nonprofit digital library which hosts the Prelinger Collection. Please give generously to support the effort.
 This year’s LOST LANDSCAPES brings together familiar and unseen archival film clips showing San Francisco as it was and is no more. Blanketing the 20th-century city from the Bay to Ocean Beach and the Presidio to Bayview, this screening includes San Franciscans at work and play; early hippies in the Haight; a highly privileged walk on the unfinished Golden Gate Bridge;
This year’s LOST LANDSCAPES brings together familiar and unseen archival film clips showing San Francisco as it was and is no more. Blanketing the 20th-century city from the Bay to Ocean Beach and the Presidio to Bayview, this screening includes San Franciscans at work and play; early hippies in the Haight; a highly privileged walk on the unfinished Golden Gate Bridge;
 When the personal record collection of music producer Bob George hit 47,000 discs, he knew something had to be done. “I wanted to give them away, but they were mostly punk, reggae and hip-hop,” he recalled, “and no established library or archive was interested.” The only thing to do, it would seem, was to turn his collection into a non-profit archive in New York called the
When the personal record collection of music producer Bob George hit 47,000 discs, he knew something had to be done. “I wanted to give them away, but they were mostly punk, reggae and hip-hop,” he recalled, “and no established library or archive was interested.” The only thing to do, it would seem, was to turn his collection into a non-profit archive in New York called the  Powered by teams of volunteers, the two archives are partnering to digitize CDs and LPs and then use audio fingerprinting to match tracks with metadata from catalogs and other services. Using Internet Archive scanners, the ARC is digitizing its books and photographs at its New York facility. When complete, this music library will be a rich resource for historians, musicologists and the general public.
Powered by teams of volunteers, the two archives are partnering to digitize CDs and LPs and then use audio fingerprinting to match tracks with metadata from catalogs and other services. Using Internet Archive scanners, the ARC is digitizing its books and photographs at its New York facility. When complete, this music library will be a rich resource for historians, musicologists and the general public.
 Since 1985, George, the ARC’s co-founder and director, has run the organization in Tribeca, New York City, supported by friends in the music industry including Paul Simon, David Bowie and Nile Rodgers. The Rolling Stones guitarist Keith Richards endows a collection of blues and R&B recordings there. Filmmakers Martin Scorsese and Jonathan Demme stop by when trying to track down hard-to-find songs. Yet for most of its almost three decades, the ARC has been a decidedly “analog” experience: records, CDs and cassette tapes line its walls; to experience a song you usually have to drop a needle into a pristine vinyl groove. The collaboration with the web-based Internet Archive represents a new direction. “We feel that our primary mission, to collect and preserve this material, is near completion,” said Bob George. “Now we are seeking ways to allow greater access to this incredible collection.”
Since 1985, George, the ARC’s co-founder and director, has run the organization in Tribeca, New York City, supported by friends in the music industry including Paul Simon, David Bowie and Nile Rodgers. The Rolling Stones guitarist Keith Richards endows a collection of blues and R&B recordings there. Filmmakers Martin Scorsese and Jonathan Demme stop by when trying to track down hard-to-find songs. Yet for most of its almost three decades, the ARC has been a decidedly “analog” experience: records, CDs and cassette tapes line its walls; to experience a song you usually have to drop a needle into a pristine vinyl groove. The collaboration with the web-based Internet Archive represents a new direction. “We feel that our primary mission, to collect and preserve this material, is near completion,” said Bob George. “Now we are seeking ways to allow greater access to this incredible collection.”