![]() The lives and activities of communities are increasingly documented online; local news, events, disasters, celebrations — the experiences of citizens are now largely shared via social media and web platforms. As these primary sources about community life move to the web, the need to archive these materials becomes an increasingly important activity of the stewards of community memory. And in many communities across the nation, public libraries, as one of their many responsibilities to their patrons, serve the vital role of stewards of local history. Yet public libraries have historically been a small fraction of the growing national and international web archiving community.
The lives and activities of communities are increasingly documented online; local news, events, disasters, celebrations — the experiences of citizens are now largely shared via social media and web platforms. As these primary sources about community life move to the web, the need to archive these materials becomes an increasingly important activity of the stewards of community memory. And in many communities across the nation, public libraries, as one of their many responsibilities to their patrons, serve the vital role of stewards of local history. Yet public libraries have historically been a small fraction of the growing national and international web archiving community.
 With generous support from the Institute of Museum and Library Services, as well as the Kahle/Austin Foundation and the Archive-It service, the Internet Archive and 27 public library partners representing 17 different states have launched a new program: Community Webs: Empowering Public Libraries to Create Community History Web Archives. The program will provide education, applied training, cohort network development, and web archiving services for a group of public librarians to develop expertise in web archiving for the purpose of local memory collecting. Additional partners in the program include OCLC’s WebJunction training and education service and the public libraries of Queens, Cleveland and San Francisco will serve as “lead libraries” in the cohort. The program will result in dozens of terabytes of public library administered local history web archives, a range of open educational resources in the form of online courses, videos, and guides, and a nationwide network of public librarians with expertise in local history web archiving and the advocacy tools to build and expand the network. A full listing of the participating public libraries is below and on the program website.
With generous support from the Institute of Museum and Library Services, as well as the Kahle/Austin Foundation and the Archive-It service, the Internet Archive and 27 public library partners representing 17 different states have launched a new program: Community Webs: Empowering Public Libraries to Create Community History Web Archives. The program will provide education, applied training, cohort network development, and web archiving services for a group of public librarians to develop expertise in web archiving for the purpose of local memory collecting. Additional partners in the program include OCLC’s WebJunction training and education service and the public libraries of Queens, Cleveland and San Francisco will serve as “lead libraries” in the cohort. The program will result in dozens of terabytes of public library administered local history web archives, a range of open educational resources in the form of online courses, videos, and guides, and a nationwide network of public librarians with expertise in local history web archiving and the advocacy tools to build and expand the network. A full listing of the participating public libraries is below and on the program website.
 In November 2017, the cohort gathered together at the Internet Archive for a kickoff meeting of brainstorming, socializing, and, of course, talking all things web archiving. Partners shared details on their existing local history programs and ideas for collection development around web materials. Attendees talked about building collections documenting their demographic diversity or focusing on local issues, such as housing availability or changes in community profile. As an example, Abbie Zeltzer from the Patagonia Public Library, spoke about the changes in her community of 913 residents as the town redevelops a long dormant mining industry. Zeltzer intends on developing a web archive documenting this transition and the related community reaction and changes.
In November 2017, the cohort gathered together at the Internet Archive for a kickoff meeting of brainstorming, socializing, and, of course, talking all things web archiving. Partners shared details on their existing local history programs and ideas for collection development around web materials. Attendees talked about building collections documenting their demographic diversity or focusing on local issues, such as housing availability or changes in community profile. As an example, Abbie Zeltzer from the Patagonia Public Library, spoke about the changes in her community of 913 residents as the town redevelops a long dormant mining industry. Zeltzer intends on developing a web archive documenting this transition and the related community reaction and changes.
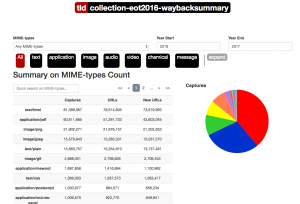
 Since the kickoff meeting, the Community Webs cohort has been actively building collections, from hyper-local media sites in Kansas City, to neighborhood blogs in Washington D.C., to Mardi Gras in East Baton Rouge. In addition, program staff, cohort members, and WebJunction have been building out an extensive online course space with educational materials for training on web archiving for local history. The full course space and all open educational resources will be released in early 2019 and a second full in-person meeting of the cohort will take place in Fall 2018.
Since the kickoff meeting, the Community Webs cohort has been actively building collections, from hyper-local media sites in Kansas City, to neighborhood blogs in Washington D.C., to Mardi Gras in East Baton Rouge. In addition, program staff, cohort members, and WebJunction have been building out an extensive online course space with educational materials for training on web archiving for local history. The full course space and all open educational resources will be released in early 2019 and a second full in-person meeting of the cohort will take place in Fall 2018.
For further information on the Community Webs program, contact Maria Praetzellis, Program Manager, Web Archiving [maria at archive.org] or Jefferson Bailey, Director, Web Archiving [jefferson at archive.org].
| Public Library | City | State |
| Athens Regional Library System | Athens | GA |
| Birmingham Public Library | Birmingham | AL |
| Brooklyn Public Library – Brooklyn Collection | New York City | NY |
| Buffalo & Erie County Public Library | Buffalo | NY |
| Cleveland Public LIbrary | Cleveland | OH |
| Columbus Metropolitan Library | Columbus | OH |
| County of Los Angeles Public Library | Los Angeles | CA |
| DC Public Library | Washington | DC |
| Denver Public Library – Western History and Genealogy Department and Blair-Caldwell African American Research Library | Denver | CO |
| East Baton Rouge Parish Library | East Baton Rouge | LA |
| Forbes Library | Northampton | MA |
| Grand Rapids Public Library | Grand Rapids | MI |
| Henderson District Public Libraries | Henderson | NV |
| Kansas City Public Library | Kansas City | MO |
| Lawrence Public Library | Lawrence | KS |
| Marshall Lyon County Library | Marshall | MN |
| New Brunswick Free Public Library | New Brunswick | NJ |
| Schomburg Center for Research in Black Culture (NYPL) | New York City | NY |
| Patagonia Library | Patagonia | AZ |
| Pollard Memorial Library | Lowell | MA |
| Queens Library | New York City | NY |
| San Diego Public Library | San Diego | CA |
| San Francisco Public Library | San Francisco | CA |
| Sonoma County Public Library | Santa Rosa | CA |
| The Urbana Free Library | Urbana | IL |
| West Hartford Public Library | West Hartford | CT |
| Westborough Public Library | Westborough | MA |



















{kind=link}