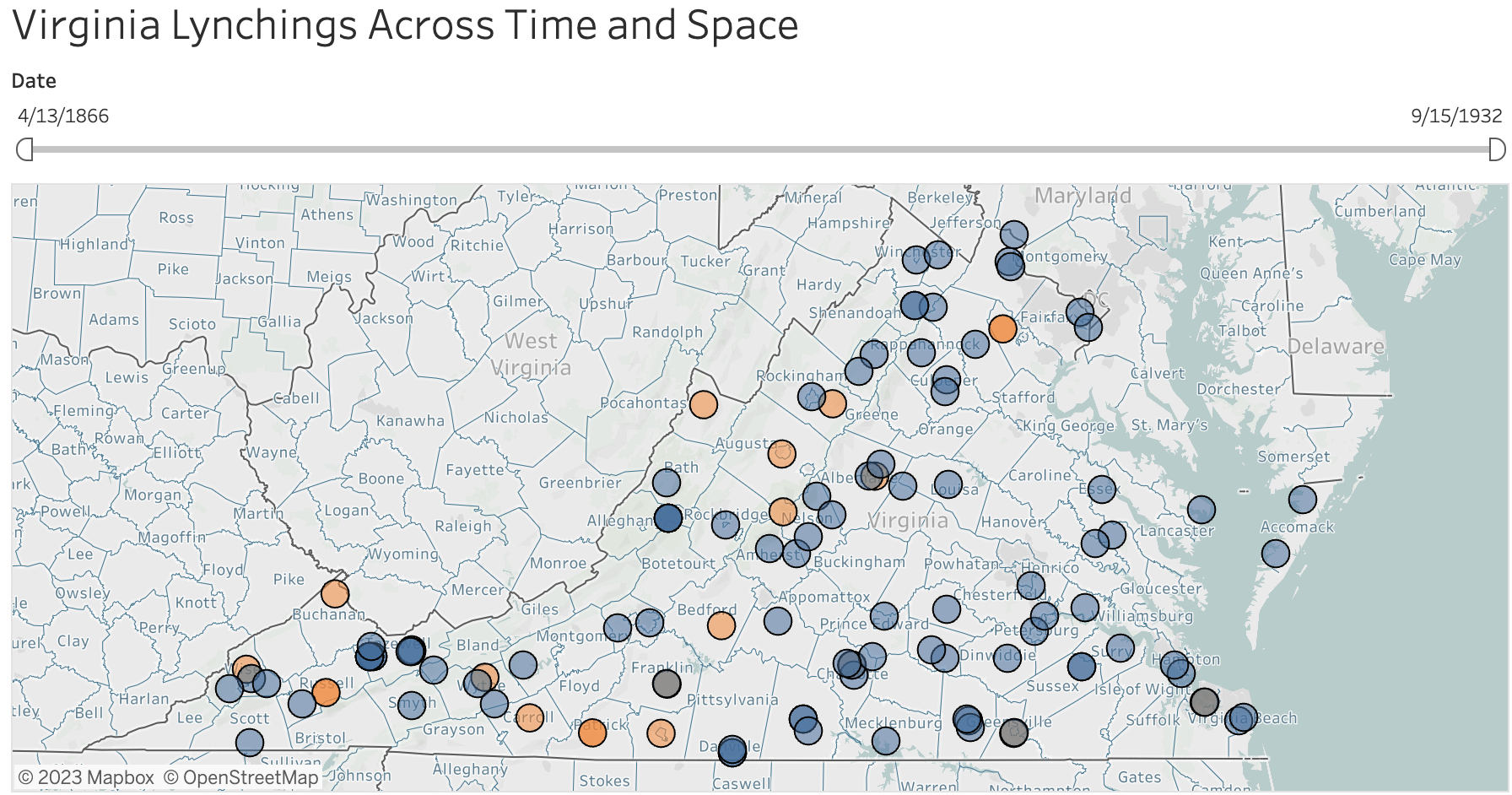
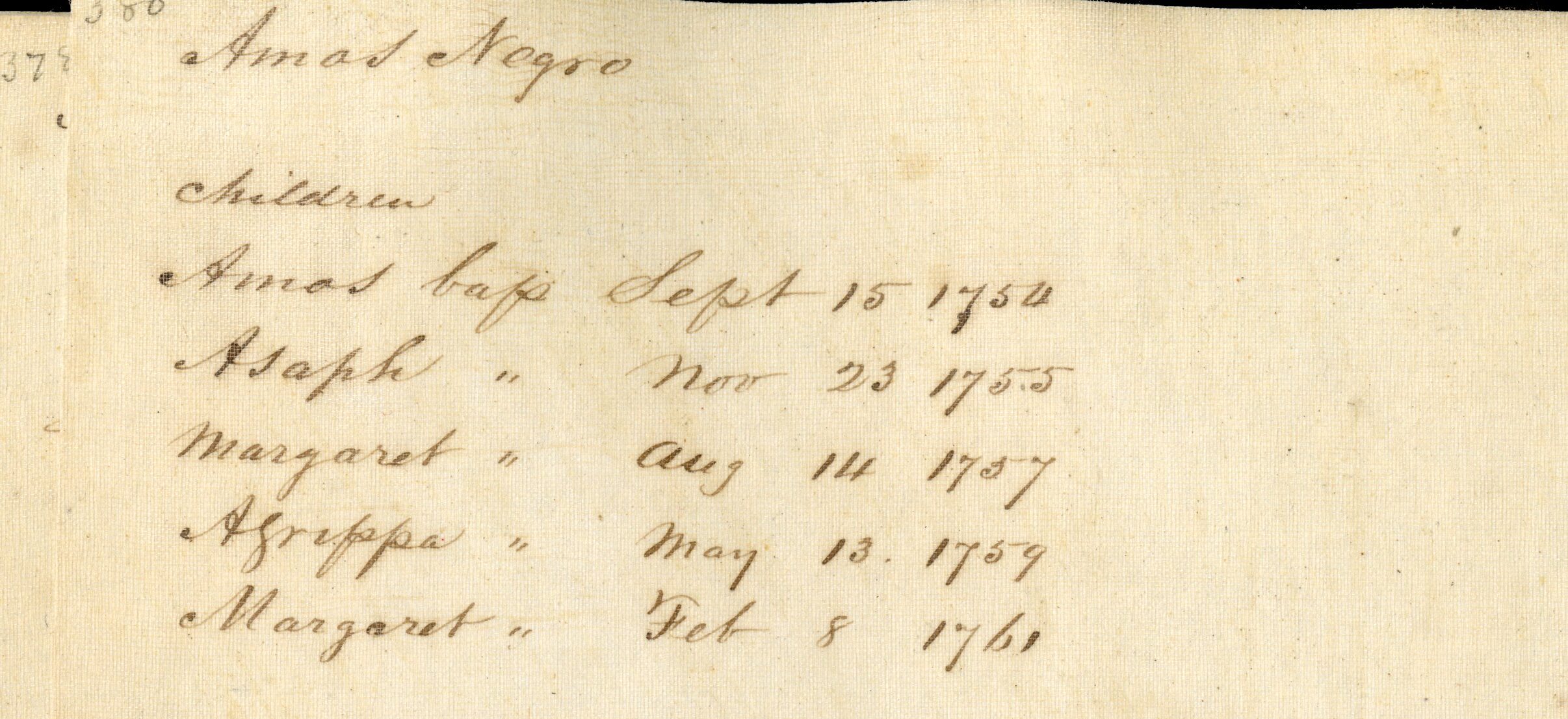Partners on the NEH supported, Increasing Access to Diverse Public Library Local History Collections
Since 2017, Community Webs has partnered with public libraries and heritage organizations to document and diversify the historical record. These organizations have collectively archived over 100 terabytes of web-based community heritage materials, including more than 800 collections documenting the lives of those often underrepresented in history. In 2023, Community Webs began offering collection digitization and access with support from the National Historical Publications and Records Commission (NHPRC). Today, Community Webs is happy to announce $345,000 in additional support from the National Endowment for the Humanities to digitize and provide open access to more than 411,000 local history collection items from seven Community Webs partners: Athens-Clarke County Library, Belen Public Library, District of Columbia Public Library, Evanston History Center, Jersey City Free Public Library, San Francisco Public Library, and William B. Harlan Memorial Library.
Community Webs partner collections include a diverse range of content from across the country representing the life of immigrants, Black, and minority communities throughout US history. This includes records created by and for them, such as the Julius Hobson Papers from District of Columbia Public Library, the Belen Harvey House Collection from Belen Public Library, and the Local and Regional Family Histories collection from the William B. Harlan Memorial Library.
ACE Newsletter, Vol. 1, No. 3, Julius Hobson Papers on Federal Job Discrimination (source)
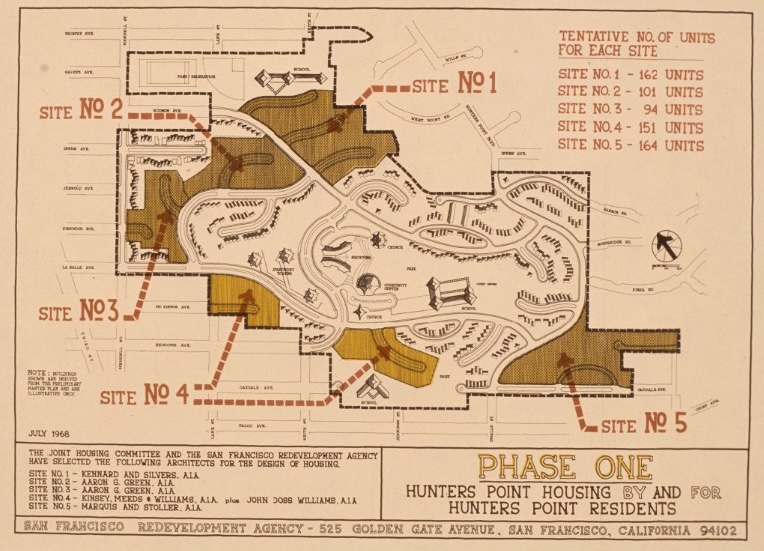
The collections also contain items that document city and municipal agencies that significantly impact minority communities. Digitization of this material will produce a deeper understanding of how systems of power and legal structures can regulate or even erase minority community histories, especially in regards to housing and economic opportunities. For example, the Athens City Engineer Records from Athens-Clarke County Library, the African American Housing and History collection from Evanston History Center, and the San Francisco Redevelopment Agency Records from San Francisco Public Library show the impact of urban redevelopment on Black and minority neighborhoods. The Municipal Records and agency scrapbooks from Jersey City Free Public Library show the ways that politics and economic changes impacted immigrant and minority communities.
Ashley Shull, Collections Coordinator, Athens-Clarke County Library shares what this project means to the community:
“The opportunity to be involved in a project proposal like this with the Internet Archive and our other library partners is invaluable to our community. The increased access to our Athens City Engineer collection will provide, not only local citizens, but academic researchers from around the world as well as current Athens-Clarke County Government officials insight into the past planning activities of our community. This is especially important as our local government embarks on a new Comprehensive Community Plan.”
John Beekman, Chief Librarian, Jersey City Free Public Library, also emphasized the impact of access to important city records:
“The Jersey City Free Public Library is honored to work with esteemed libraries from across the country on this innovative project spearheaded by the Internet Archive’s Community Webs program. The municipal minutes and records that make up the bulk of our contribution contain a wealth of information, not only on the workings of city government and agencies, but the people whose work is recorded there. Names and activities present in these records that never made the news will now be discoverable through search rather than the needle-in-a-haystack experience of poring over individual volumes of minutes. Making these materials accessible will provide a tool for enriching the record of city life across the 19th and 20th centuries.”
Hunters Point housing phase one map with unit totals, an Francisco Redevelopment Agency Records. Hunters Point Project Area A. Photographs (source)
The Community Webs program’s core goals are to increase the diversity of voices represented in the accessible historical record and to forge authentic partnerships between public libraries and heritage organizations that are members of Community Webs and the communities, individuals, and researchers they serve. Digitizing these collections will expand the overall amount and diversity of locally-focused community archives available online to users, and will augment the web and digital collections that are already aggregated by Community Webs. Records will also be shared with the Digital Public Library of America, further strengthening collection discovery.
Learn more about Community Webs members, projects, and collections on our blog. Get in touch with us at commwebs@archive.org to discover ways to partner to preserve local history!
A family in Hatfield, ca. 1889. L.H. Kingsley, photographer.
Guest post by Dylan Gaffney, Information Services Associate for Local History & Special Collections, Forbes Library.
This post is part of a series written by members of the Community Webs program. Community Webs advances the capacity for community-focused memory organizations to build web and digital archives documenting local histories and underrepresented voices. For more information, visit communitywebs.archive-it.org.
Forbes Library has been a member of Community Webs since its inception in 2017. At that time, we were hopeful that the program would allow us to create an archive which more fully represented the community in which we live, and provide a more diverse history/record of our region and the people we serve. This project inspired archives staff to examine the many silences in our archives, and make plans for the ethical collection and preservation of materials that would help fill in these gaps in our historical record. At the same time, the library had begun to shift its focus toward collaboration with other local historical and community organizations.
In the years following the kickoff of the Community Webs Project, Forbes library co-hosted multiple series of exhibits, films, workshops, walking tours, and community reads on themes of mass incarceration, the Underground Railroad, and the history of slavery in our region. These events, and the passionate response of the community to them, inspired us to continue seeking out collaborations, large and small, and solidified our view that surfacing stories of people who had been underrepresented in the archives should be a core value in our work as an institution.
This work inspired Forbes Library, Historic Northampton, UMass Amherst, and the Pioneer Valley History Network to take lead roles in the 2021 Documenting Early Black Lives in the Connecticut River Valley project, which seeks to gather the fragmentary information about Black lives from the wide range of sources and archives in Western Massachusetts so that a whole might be perceived that is larger than the sum of those parts. The project, to date, has surfaced over 3500 records or references to people of color, enslaved and free, in Western Massachusetts from the 17th through 19th centuries. These histories are being made available through the project’s database and on the project website. We contributed an essay titled Searching for Black History in a Public Library Archive to the Project Handbook on the experiences and takeaways of doing this work from a public librarian’s perspective.
We know too little about Black lives in rural and small-town New England, and the places Black residents were able to carve out for themselves in these communities. With this project, we hoped to uncover names, details of their lives, and some small sense of how people of color survived in the Connecticut River Valley before and after the abolition of slavery in Massachusetts in 1783. At the kickoff event for the project, UMass Amherst professor Gretchen Holbrook Gerzina mentioned challenging the assumptions of others (sometimes called Gatekeepers) who “might be quick to discourage a researcher interested in Black History, reporting that they don’t have much…or not thinking about ways that records of white families might be useful to this research” Gerzina remarked that researchers, curators, and librarians should ”start from the perspective of presence.”
As the Documenting Black Lives project was undertaken with grant funding, and the time thus limited, we needed to develop an approach that would be productive right away. We identified several collections in the library’s Hampshire Room for Local History that we expected could be productive resources for identifying enslaved people in the area. The most promising of these was the Judd Manuscript Collection, a collection of 60+ volumes created by local newspaper editor and historian Sylvester Judd in the 1840s. The manuscript was originally purchased from the Judd estate by local historian James Trumbull and subsequently sold to the trustees of the library. It has been the property of the library since 1904, but use has been limited to a small group of academics and local historians who were aware of the contents and could physically visit during our few open archives hours. Those who knew of its tremendous historical value had discovered that it features content documenting Indigenous lives, enslaved people, and free Black people in New England and had used it to research Indigenous culture, the history of colonial settlement, enslavement, and the early abolitionist movement in the area.
Public Historian and Author Marla Miller on the value of Judd:
“Sylvester Judd, in his transcriptions of historic documents as well as the conversations he described with local residents, preserves extraordinary details that survive nowhere else. Because of Judd’s meticulous, wide-ranging work, I was able to gain insight into the lives of laboring people that would never otherwise have been possible…Judd’s notes preserve genealogical information about enslaved people that is found nowhere else. The Judd manuscript is almost archaeological in nature, with shards of evidence that can be unearthed via careful scrutiny. As he records, for instance, who had the first piano in town, who laid the first carpet, the sound of the geese squawking through Sunday sermons, and a hundred other small details of daily life, a picture emerges that simply cannot be found in any other kind of more formal or systematic archival material. These pages, filled from edge to edge with his notes, cross references, sketches, and other materials, simply teem with the kinds of details that historians crave, but cannot hope to find—except in Northampton.”
If we start from an assumption of presence (of underrepresented people both in the community and in the archives), the primary obstacles to discovering and surfacing information in collections like ours, often revolve around issues of access, and methodologies for search and discovery. We had long dreamed of digitizing all 60+ bound volumes of the collection to make them available to a wider group of researchers and the public at large. When the Community Webs program began to explore funding for a digitization program dedicated to expanding the amount and diversity of locally-focused community archives available online to users, the Judd Manuscript Collection seemed a good fit.
Now that the volumes have been digitized, our mission is to spread the word about their value and availability, so that the materials within can inform and inspire new research and discovery. As an illustration of the value of the collection and its contents, it is useful to look at how the increased availability of this resource could lead to new discoveries in long hidden collections. As an example, I will examine how Judd enriched our understanding of one local Black family.
Judd devoted entire volumes to genealogies of local families, but the 600+ page volume on Northampton Genealogies contains, to our knowledge, only two Black families, both listed without last names. The work we had done in the Documenting Black Lives project enabled us to compile a list of 3500+ entries for Black residents of the region in the period between the 1650-1900. We recognized these names as those of Amos and Bathsheba Hull and their children. Bathsheba can be found elsewhere in our own archives as a member of the Church of Christ during Jonathan Edwards ministry between 1729-1750, in records recorded by Jonathan Edwards own hand.
This entry transcribed from a local merchant’s account book shows items purchased by Amos Hull, the services he would perform in exchange for goods received, and the rate at which he was paid. It notes that in 1761, the same year their daughter Margaret was born, Amos Hull died. Afterward, his widow Bathsheba paid for his and her accounts by washing. Bathsheba surely would have a difficult time supporting multiple children without her husband, and documents subsequently found elsewhere in our archives and in other institutions prove this to be the case.
By 1762, a document found elsewhere in our archives records their son Asaph indentured to Seth Pomeroy, who is well known for his service in the French and Indian War and would go onto fight at the Battle of Bunker Hill and achieve the rank of Major General.
Bathsheba and her family come up again in several entries in Judd, including multiple mentions of the town seizing her land and displacing her from it in 1765. This cruel act forces Bathsheba and her young children from the town. Bathsheba and her son Agrippa would relocate to Stockbridge, Massachusetts. It is in Stockbridge where Agrippa Hull would enlist in May of 1777, and served for the remainder of the Revolutionary War in the Continental Army, including witnessing the surrender of British General John Burgoyne at Saratoga, New York, enduring the winter of 1777-78 at Valley Forge and was part of the battle at Monmouth Courthouse, New Jersey in June 1778. He then served as a personal assistant for the famed Polish general, revolutionary and engineer Taddeusz Kosciuszko and became a close friend of the General, during their years of War Service together. Agrippa’s story and friendship with Kosciuszko, along with Kosciuszko’s friendship with Thomas Jefferson is examined in Gary Nash and Graham Hodge’s 2012 book “Friends of Liberty: Thomas Jefferson, Tadeusz Kosciuszko, and Agrippa Hull”.
Portrait of Agrippa Hull, Courtesy of the Stockbridge Library, Museum & Archives.
Agrippa Hull went on to become the most prominent black landowner in Stockbridge MA and is buried along with his wife and children in Stockbridge Cemetery. His brother Amos Hull, Jr. also fought in the Continental Army, and surfaces in Belchertown MA records recorded as part of the Documenting Black Lives project.
This is just one brief example of the elaborate web of information that can be revealed when we prioritize the surfacing of stories that had previously been hidden in our collections, increase access through digitization, and collaborate to research and promote the information within.
“ We can hardly wait to learn— alongside the many other academic and avocational historians whose work will be enriched and transformed by these records—what else remains to be discovered. Once available in digital form, available for scouring by researchers with their own wide range of questions, these materials will certainly spark, inform, and enrich generations of new research, from student papers to dissertations to academic monographs. It is almost impossible to predict all the ways the volumes might reshape historiography, as well as conventional historical wisdom, because the contents at present are comparatively difficult to ferret out. But to be sure, these volumes have the potential to transform local and regional historical understanding, and once digitized, will certainly come to the attention of researchers nationwide.”
The Internet Archive and Community Webs are thankful for the support from the National Historical Publications & Records Commission for Collaborative Access to Diverse Public Library Local History Collections, which will digitize and provide access to a diverse range of local history archives that represent the experiences of immigrant, indigenous, and African American communities throughout the United States.
Last summer, Internet Archive launched ARCH (Archives Research Compute Hub), a research service that supports creation, computational analysis, sharing, and preservation of research datasets from terabytes and even petabytes of data from digital collections – with an initial focus on web archive collections. In line with Internet Archive’s mission to provide “universal access to all knowledge” we aim to make ARCH as universally accessible as possible.
Computational research and education cannot remain solely accessible to the world’s most well-resourced organizations. With philanthropic support, Internet Archive is initiating Advancing Inclusive Computational Research with ARCH, a pilot program specifically designed to support an initial cohort of five less well-resourced organizations throughout the world.
Opportunity
Organizational access to ARCH for 1 year – supporting research teams, pedagogical efforts, and/or library, archive, and museum worker experimentation.
Access to thousands of curated web archive collections – abundant thematic range with potential to drive multidisciplinary research and education.
Enhanced Internet Archive training and support – expert synchronous and asynchronous support from Internet Archive staff.
Cohort experience – opportunities to share challenges and successes with a supportive group of peers.
Eligibility
Demonstrated need-based rationale for participation in Advancing Inclusive Computational Research with Archives Research Compute Hub: we will take a number of factors into consideration, including but not limited to stated organizational resources relative to peer organizations, ongoing experience contending with historic and contemporary inequities, as well as levels of national development as assessed by the United Nations Least Developed Countries effort and Human Development Index.
Organization type: universities, research institutes, libraries, archives, museums, government offices, non-governmental organizations.
In August 2022, the UC Berkeley Library and Internet Archive were awarded a grant from the National Endowment for the Humanities (NEH) to study legal and ethical issues in cross-border text and data mining (TDM).
The project, entitled Legal Literacies for Text Data Mining – Cross-Border (“LLTDM-X”), supported research and analysis to address law and policy issues faced by U.S. digital humanities practitioners whose text data mining research and practice intersects with foreign-held or licensed content, or involves international research collaborations.
LLTDM-X is now complete, resulting in the publication of an instructive case study for researchers and white paper. Both resources are explained in greater detail below.
Project Origins
LLTDM-X built upon the previous NEH-sponsored institute, Building Legal Literacies for Text Data Mining. That institute provided training, guidance, and strategies to digital humanities TDM researchers on navigating legal literacies for text data mining (including copyright, contracts, privacy, and ethics) within a U.S. context.
A common challenge highlighted during the institute was the fact that TDM practitioners encounter expanding and increasingly complex cross-border legal problems. These include situations in which: (i) the materials they want to mine are housed in a foreign jurisdiction, or are otherwise subject to foreign database licensing or laws; (ii) the human subjects they are studying or who created the underlying content reside in another country; or, (iii) the colleagues with whom they are collaborating reside abroad, yielding uncertainty about which country’s laws, agreements, and policies apply.
Project Design
LLTDM-X was designed to identify and better understand the cross-border issues that digital humanities TDM practitioners face, with the aim of using these issues to inform prospective research and education. Secondarily, it was hoped that LLTDM-X would also suggest preliminary guidance to include in future educational materials. In early 2023, the project hosted a series of three online round tables with U.S.-based cross-border TDM practitioners and law and ethics experts from six countries.
The round table conversations were structured to illustrate the empirical issues that researchers face, and also for the practitioners to benefit from preliminary advice on legal and ethical challenges. Upon the completion of the round tables, the LLTDM-X project team created a hypothetical case study that (i) reflects the observed cross-border LLTDM issues and (ii) contains preliminary analysis to facilitate the development of future instructional materials.
The project team also charged the experts with providing responsive and tailored written feedback to the practitioners about how they might address specific cross-border issues relevant to each of their projects.
Extrapolating from the issues analyzed in the round tables, the practitioners’ statements, and the experts’ written analyses, the Project Team developed a hypothetical case study reflective of “typical” cross-border LLTDM issues that U.S.-based practitioners encounter. The case study provides basic guidance to support U.S. researchers in navigating cross-border TDM issues, while also highlighting questions that would benefit from further research.
The case study examines cross-border copyright, contracts, and privacy & ethics variables across two distinct paradigms: first, a situation where U.S.-based researchers perform all TDM acts in the U.S., and second, a situation where U.S.-based researchers engage with collaborators abroad, or otherwise perform TDM acts in both U.S. and abroad.
The LLTDM-X white paper provides a comprehensive description of the project, including origins and goals, contributors, activities, and outcomes. Of particular note are several project takeaways and recommendations, which the project team hopes will help inform future research and action to support cross-border text data mining. Project takeaways touched on seven key themes:
Uncertainty about cross-border LLTDM issues indeed hinders U.S. TDM researchers, confirming the need for education about cross-border legal issues;
The expansion of education regarding U.S. LLTDM literacies remains essential, and should continue in parallel to cross-border education;
Disparities in national copyright, contracts, and privacy laws may incentivize TDM researcher “forum shopping” and exacerbate research bias;
License agreements (and the concept of “contractual override”) often dominate the overall analysis of cross-border TDM permissibility;
Emerging lawsuits about generative artificial intelligence may impact future understanding of fair use and other research exceptions;
Research is needed into issues of foreign jurisdiction, likelihood of lawsuits in foreign countries, and likelihood of enforcement of foreign judgments in the U.S. However, the overall “risk” of proceeding with cross-border TDM research may remain difficult to quantify; and
Institutional review boards (IRBs) have an opportunity to explore a new role or build partnerships to support researchers engaged in cross-border TDM.
Gratitude & Next Steps
Thank you to the practitioners, experts, project team, and generous funding of the National Endowment for the Humanities for making this project a success.
We aim to broadly share our project outputs to continue helping U.S.-based TDM researchers navigate cross-border LLTDM hurdles. We will continue to speak publicly to educate researchers and the TDM community regarding project takeaways, and to advocate for legal and ethical experts to undertake the essential research questions and begin developing much-needed educational materials. And, we will continue to encourage the integration of LLTDM literacies into digital humanities curricula, to facilitate both domestic and cross-border TDM research.
Kevin Hegg is Head of Digital Projects at James Madison University Libraries (JMU). Kevin has held many technology positions within JMU Libraries. His experience spans a wide variety of technology work, from managing computer labs and server hardware to developing a large open-source software initiative. We are thankful to Kevin for taking time to talk with us about his experience with ARCH (Archives Research Compute Hub), AI, and supporting research at JMU.
Thomas Padilla is Deputy Director, Archiving and Data Services.
Thomas: Thank you for agreeing to talk more about your experience with ARCH, AI, and supporting research. I find that folks are often curious about what set of interests and experiences prepares someone to work in these areas. Can you tell us a bit about yourself and how you began doing this kind of work?
Kevin: Over the span of 27 years, I have held several technology roles within James Madison University (JMU) Libraries. My experience ranges from managing computer labs and server hardware to developing a large open-source software initiative adopted by numerous academic universities across the world. Today I manage a small team that supports faculty and students as they design, implement, and evaluate digital projects that enhance, transform, and promote scholarship, teaching, and learning. I also co-manage Histories Along the Blue Ridgewhich hosts over 50,000 digitized legal documents from courthouses along Virginia’s Blue Ridge mountains.
Thomas: I gather that your initial interest in using ARCH was to see what potential it afforded for working with James Madison University’s Mapping Black Digital and Public Humanities project. Can you introduce the project to our readers?
Kevin: The Mapping the Black Digital and Public Humanities project began at JMU in Fall 2022. The project draws inspiration from established resources such as the Colored Convention Project and the Reviews in Digital Humanities journal. It employs Airtable for data collection and Tableau for data visualization. The website features a map that not only geographically locates over 440 Black digital and public humanities projects across the United States but also offers detailed information about each initiative. The project is a collaborative endeavor involving JMU graduate students and faculty, in close alliance with JMU Libraries. Over the past year, this interdisciplinary team has dedicated hundreds of hours to data collection, data visualization, and website development.
The project has achieved significant milestones. In Fall 2022, Mollie Godfrey and Seán McCarthy, the project leaders, authored, “Race, Space, and Celebrating Simms: Mapping Strategies for Black Feminist Biographical Recovery“, highlighting the value of such mapping projects. At the same time, graduate student Iliana Cosme-Brooks undertook a monumental data collection effort. During the winter months, Mollie and Seán spearheaded an effort to refine the categories and terms used in the project through comprehensive research and user testing. By Spring 2023, the project was integrated into the academic curriculum, where a class of graduate students actively contributed to its inaugural phase. Funding was obtained to maintain and update the database and map during the summer.
Looking ahead, the project team plans to present their work at academic conferences and aims to diversify the team’s expertise further. The overarching objective is to enhance the visibility and interconnectedness of Black digital and public humanities projects, while also welcoming external contributions for the initiative’s continual refinement and expansion.
Thomas: It sounds like the project adopts a holistic approach to experimenting with and integrating the functionality of a wide range of tools and methods (e.g., mapping, data visualization). How do you see tools like ARCH fitting into the project and research services more broadly? What tools and methods have you used in combination with ARCH?
Kevin: ARCH offers faculty and students an invaluable resource for digital scholarship by providing expansive, high-quality datasets. These datasets enable more sophisticated data analytics than typically encountered in undergraduate pedagogy, revealing patterns and trends that would otherwise remain obscured. Despite the increasing importance of digital humanities, a significant portion of faculty and students lack advanced coding skills. The advent of AI-assisted coding platforms like ChatGPT and GitHub CoPilot has democratized access to programming languages such as Python and JavaScript, facilitating their integration into academic research.
For my work, I employed ChatGPT and CoPilot to further process ARCH datasets derived from a curated sample of 20 websites focused on Black digital and public humanities. Utilizing PyCharm—an IDE freely available for educational purposes—and the CoPilot extension, my coding efficiency improved tenfold.
Next, I leveraged ChatGPT’s Advanced Data Analysis plugin to deconstruct visualizations from Stanford’s Palladio platform, a tool commonly used for exploratory data visualizations but lacking a means for sharing the visualizations. With the aid of ChatGPT, I developed JavaScript-based web applications that faithfully replicate Palladio’s graph and gallery visualizations. Specifically, I instructed ChatGPT to employ the D3 JavaScript library for ingesting my modified ARCH datasets into client-side web applications. The final products, including HTML, JavaScript, and CSV files, were made publicly accessible via GitHub Pages (see my graph and gallery on GitHub Pages)
Black Digital and Public Humanities websites, graph visualization
In summary, the integration of Python and AI-assisted coding tools has not only enhanced my use of ARCH datasets but also enabled the creation of client-side web applications for data visualization.
Thomas: Beyond pairing ChatGPT with ARCH, what additional uses are you anticipating for AI-driven tools in your work?
Kevin: AI-driven tools have already radically transformed my daily work. I am using AI to reduce or even eliminate repetitive, mindless tasks that take tens or hundreds of hours. For example, as part of the Mapping project, ChatGPT+ helped me transform an AirTable with almost 500 rows and two dozen columns into a series of 500 blog posts on a WordPress site. ChatGPT+ understands the structure of a WordPress export file. After a couple of hours of iterating through my design requirements with ChatGPT, I was able to import 500 blog posts into a WordPress website. Without this intervention, this task would have required over a hundred hours of tedious copying and pasting. Additionally, we have been using AI-enabled platforms like Otter and Descript to transcribe oral interviews.
I foresee AI-driven tools playing an increasingly pivotal role in many facets of my work. For instance, natural language processing could automate the categorization and summarization of large text-based datasets, making archival research more efficient and our analyses richer. AI can also be used to identify entities in large archival datasets. Archives hold a treasure trove of artifacts waiting to be described and discovered. AI offers tools that will supercharge our construction of finding aids and item-level metadata.
Lastly, AI could facilitate more dynamic and interactive data visualizations, like the ones I published on GitHub Pages. These will offer users a more engaging experience when interacting with our research findings. Overall, the potential of AI is vast, and I’m excited to integrate more AI-driven tools into JMU’s classrooms and research ecosystem.
Thomas: Thanks for taking the time Kevin. To close out, whose work would you like people to know more about?
Kevin: Engaging in Digital Humanities (DH) within the academic library setting is a distinct privilege, one that requires a collaborative ethos. I am fortunate to be a member of an exceptional team at JMU Libraries, a collective too expansive to fully acknowledge here. AI has introduced transformative tools that border on magic. However, loosely paraphrasing Immanuel Kant, it’s crucial to remember that technology devoid of content is empty. I will use this opportunity to spotlight the contributions of three JMU faculty whose work celebrates our local community and furthers social justice.
Mollie Godfrey (Department of English) and Seán McCarthy (Writing, Rhetoric, and Technical Communication) are the visionaries behind two inspiring initiatives: the Mapping Project and the Celebrating Simms Project. The latter serves as a digital, post-custodial archive honoring Lucy F. Simms, an educator born into enslavement in 1856 who impacted three generations of young students in our local community. Both Godfrey and McCarthy have cultivated deep, lasting connections within Harrisonburg’s Black community. Their work strikes a balance between celebration and reparation. Collaborating with them has been as rewarding as it is challenging.
Gianluca De Fazio (Justice Studies) spearheads the Racial Terror: Lynching in Virginia project, illuminating a grim chapter of Virginia’s past. His relentless dedication led to the installation of a historical marker commemorating the tragic lynching of Charlotte Harris. De Fazio, along with colleagues, has also developed nine lesson plans based on this research, which are now integrated into high school curricula. My collaboration with him was a catalyst for pursuing a master’s degree in American History.
Both the Celebrating Simms and Racial Terror projects are highlighted in the Mapping the Black Digital and Public Humanities initiative. The privilege of contributing to such impactful projects alongside such dedicated individuals has rendered my extensive tenure at JMU both meaningful and, I hope, enduring.
We are excited to announce the public availability of ARCH (Archives Research Compute Hub), a new research and education service that helps users easily build, access, and analyze digital collections computationally at scale. ARCH represents a combination of the Internet Archive’s experience supporting computational research for more than a decade by providing large-scale data to researchers and dataset-oriented service integrations like ARS (Archive-it Research Services) and a collaboration with the Archives Unleashed project of the University of Waterloo and York University. Development of ARCH was generously supported by the Mellon Foundation.
ARCH Dashboard
What does ARCH do?
ARCH helps users easily conduct and support computational research with digital collections at scale – e.g., text and data mining, data science, digital scholarship, machine learning, and more. Users can build custom research collections relevant to a wide range of subjects, generate and access research-ready datasets from collections, and analyze those datasets. In line with best practices in reproducibility, ARCH supports open publication and preservation of user-generated datasets. ARCH is currently optimized for working with tens of thousands of web archive collections, covering a broad range of subjects, events, and timeframes, and the platform is actively expanding to include digitized text and image collections. ARCH also works with various portions of the overall Wayback Machine global web archive totaling 50+ PB going back to 1996, representing an extensive archive of contemporary history and communication.
ARCH, In-Browser Visualization
Who is ARCH for?
ARCH is for any user that seeks an accessible approach to working with digital collections computationally at scale. Possible users include but are not limited to researchers exploring disciplinary questions, educators seeking to foster computational methods in the classroom, journalists tracking changes in web-based communication over time, to librarians and archivists seeking to support the development of computational literacies across disciplines. Recent research efforts making use of ARCH include but are not limited to analysis of COVID-19 crisis communications, health misinformation, Latin American women’s rights movements, and post-conflict societies during reconciliation.
ARCH, Generate Datasets
What are core ARCH features?
Build: Leverage ARCH capabilities to build custom research collections that are well scoped for specific research and education purposes.
Access: Generate more than a dozen different research-ready datasets (e.g., full text, images, pdfs, graph data, and more) from digital collections with the click of a button. Download generated datasets directly in-browser or via API.
Analyze: Easily work with research-ready datasets in interactive computational environments and applications like Jupyter Notebooks, Google CoLab, Gephi, and Voyant and produce in-browser visualizations.
Publish and Preserve: Openly publish datasets in line with best practices in reproducible research. All published datasets will be preserved in perpetuity.
Support: Make use of synchronous and asynchronous technical support, online trainings, and extensive help center documentation.
How can I learn more about ARCH?
To learn more about ARCH please reach out via the following form.
Art historians, critics, curators, humanities scholars and many others rely on the records of artists, galleries, museums, and arts organizations to conduct historical research and to understand and contextualize contemporary artistic practice. Yet, much of the art-related materials that were once published in print form are now available primarily or solely on the web and are thus ephemeral by nature. In response to this challenge, more than 40 art libraries spent the last 3 years developing a collective approach to preservation of web-based art materials at scale.
Supported by the Institute of Museum and Library Services and the National Endowment for the Humanities, The Collaborative ART Archive (CARTA) community has successfully aligned effort across libraries large and small, from Manoa, Hawaii to Toronto, Ontario and back resulting in preservation of and access to 800 web-based art resources, organized into 8 collections (art criticism, art fairs and events, art galleries, art history and scholarship, artists websites, arts education, arts organizations, auction houses), totalling nearly 9 TBs of data with continued growth. All collections are preserved in perpetuity by the Internet Archive.
Today, CARTA is excited to launch the CARTA portal – providing unified access to CARTA collections.
🎨 CARTA portal 🎨
The CARTA portal includes web archive collections developed jointly by CARTA members, as well as preexisting art-related collections from CARTA institutions, and non-CARTA member collections. CARTA portal development builds on the Internet Archive’s experience creating the COVID-19 Web Archive and Community Webs portal.
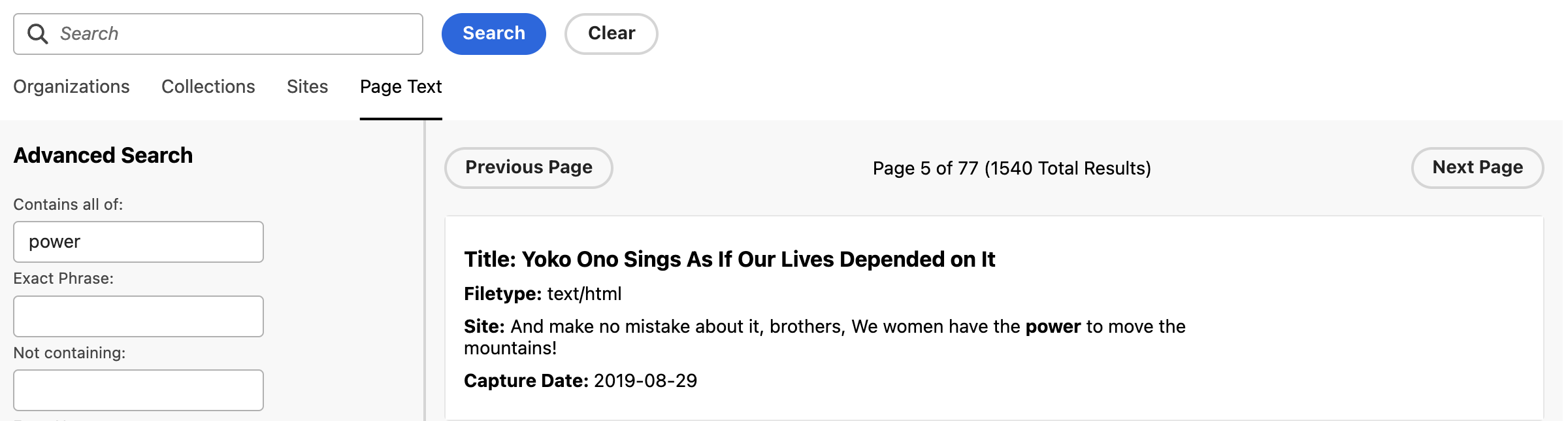
CARTA collections are searchable by contributing organization, collection, site, and page text. Advanced search supports more granular exploration by host, results per host, file types, and beginning and end dates.
🔭 CARTA search 🔭
In addition to the CARTA portal, CARTA has worked to promote research use of collections through a series of day long computational research workshops – Working to Advance Library Support for Web Archive Research – backed by ARCH (Archives Research Compute Hub). A call for applications for the next workshop, held concurrent to the annual Society of American Archivists meeting, is now open.
Moving forward CARTA aims to grow and diversify its membership in order to increase collective ability to preserve web-based art materials. If your art library would like to join CARTA please express interest here..
Guest Post by Daniel Van Strien, Machine Learning Librarian, Hugging Face
Machine learning has many potential applications for working with GLAM (galleries, libraries, archives, museums) collections, though it is not always clear how to get started. This post outlines some of the possible ways in which open source machine learning tools from the Hugging Face ecosystem can be used to explore web archive collections made available via the Internet Archive’s ARCH (Archives Research Compute Hub). ARCH aims to make computational work with web archives more accessible by streamlining web archive data access, visualization, analysis, and sharing. Hugging Face is focused on the democratization of good machine learning. A key component of this is not only making models available but also doing extensive work around the ethical use of machine learning.
Below, I work with the Collaborative Art Archive (CARTA) collection focused on artist websites. This post is accompanied by an ARCH Image Dataset Explorer Demo. The goal of this post is to show how using a specific set of open source machine learning models can help you explore a large dataset through image search, image classification, and model training.
Later this year, Internet Archive and Hugging Face will organize a hands-on hackathon focused on using open source machine learning tools with web archives. Please let us know if you are interested in participating by filling out this form.
Choosing machine learning models
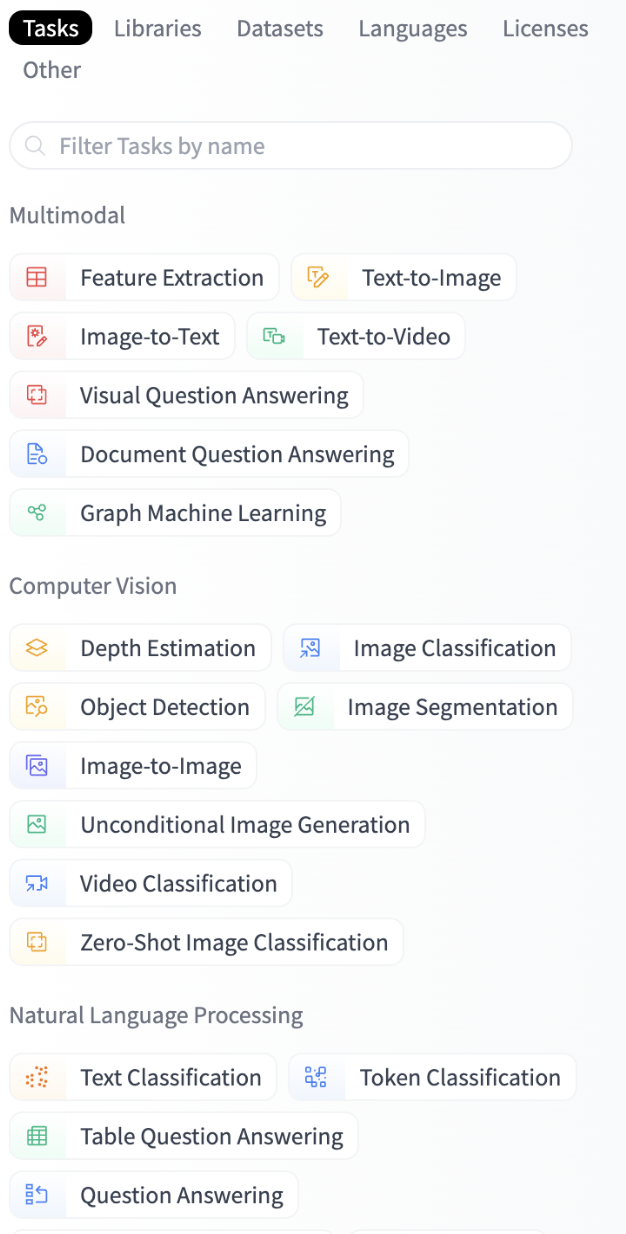
The Hugging Face Hub is a central repository which provides access to open source machine learning models, datasets and demos. Currently, the Hugging Face Hub has over 150,000 openly available machine learning models covering a broad range of machine learning tasks.
Rather than relying on a single model that may not be comprehensive enough, we’ll select a series of models that suit our particular needs.
A screenshot of the Hugging Face Hub task navigator presenting a way of filtering machine learning models hosted on the hub by the tasks they intend to solve. Example tasks are Image Classification, Token Classification and Image-to-Text.
Working with image data
ARCH currently provides access to 16 different “research ready” datasets generated from web archive collections. These include but are not limited to datasets containing all extracted text from the web pages in a collection, link graphs (showing how websites link to other websites), and named entities (for example, mentions of people and places). One of the datasets is made available as a CSV file, containing information about the images from webpages in the collection, including when the image was collected, when the live image was last modified, a URL for the image, and a filename.
Screenshot of the ARCH interface showing a preview for a dataset. This preview includes a download link and an “Open in Colab” button.
One of the challenges we face with a collection like this is being able to work at a larger scale to understand what is contained within it – looking through 1000s of images is going to be challenging. We address that challenge by making use of tools that help us better understand a collection at scale.
Building a user interface
Gradio is an open source library supported by Hugging Face that helps create user interfaces that allow other people to interact with various aspects of a machine learning system, including the datasets and models. I used Gradio in combination with Spacesto make an application publicly available within minutes, without having to set up and manage a server or hosting. See the docs for more information on using Spaces. Below, I show examples of using Gradio as an interface for applying machine learning tools to ARCH generated data.
Exploring images
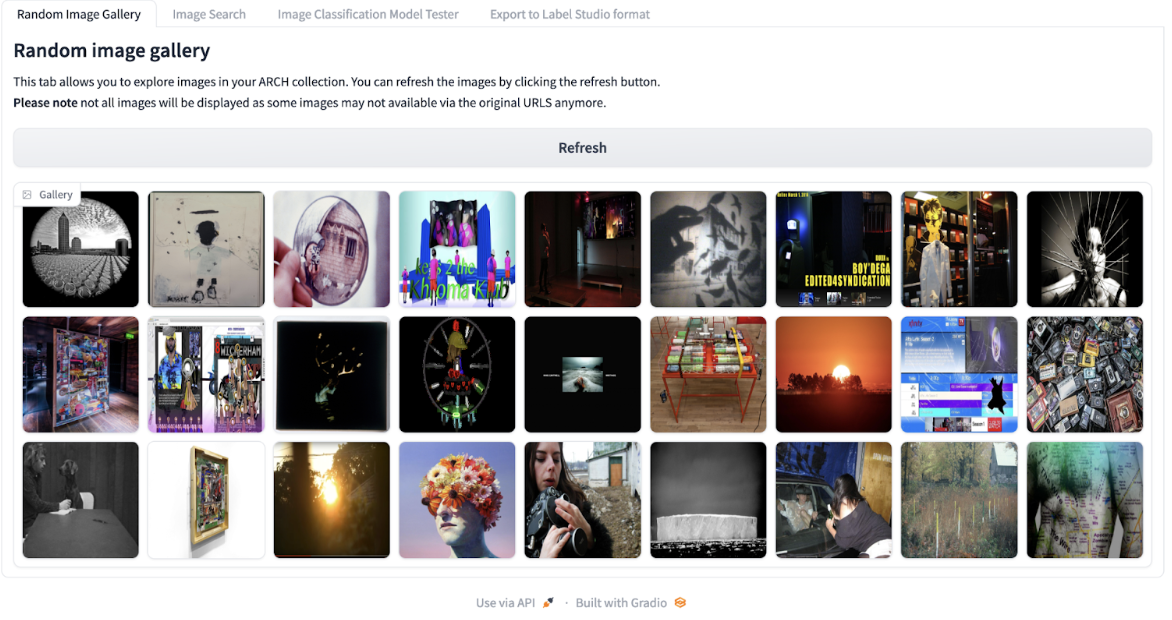
I use the Gradio tab for random images to begin assessing images in the dataset. Looking at a randomized grid of images gives a better idea of what kind of images are in the dataset. This begins to give us a sense of what is represented in the collection (e.g., art, objects, people, etc.).
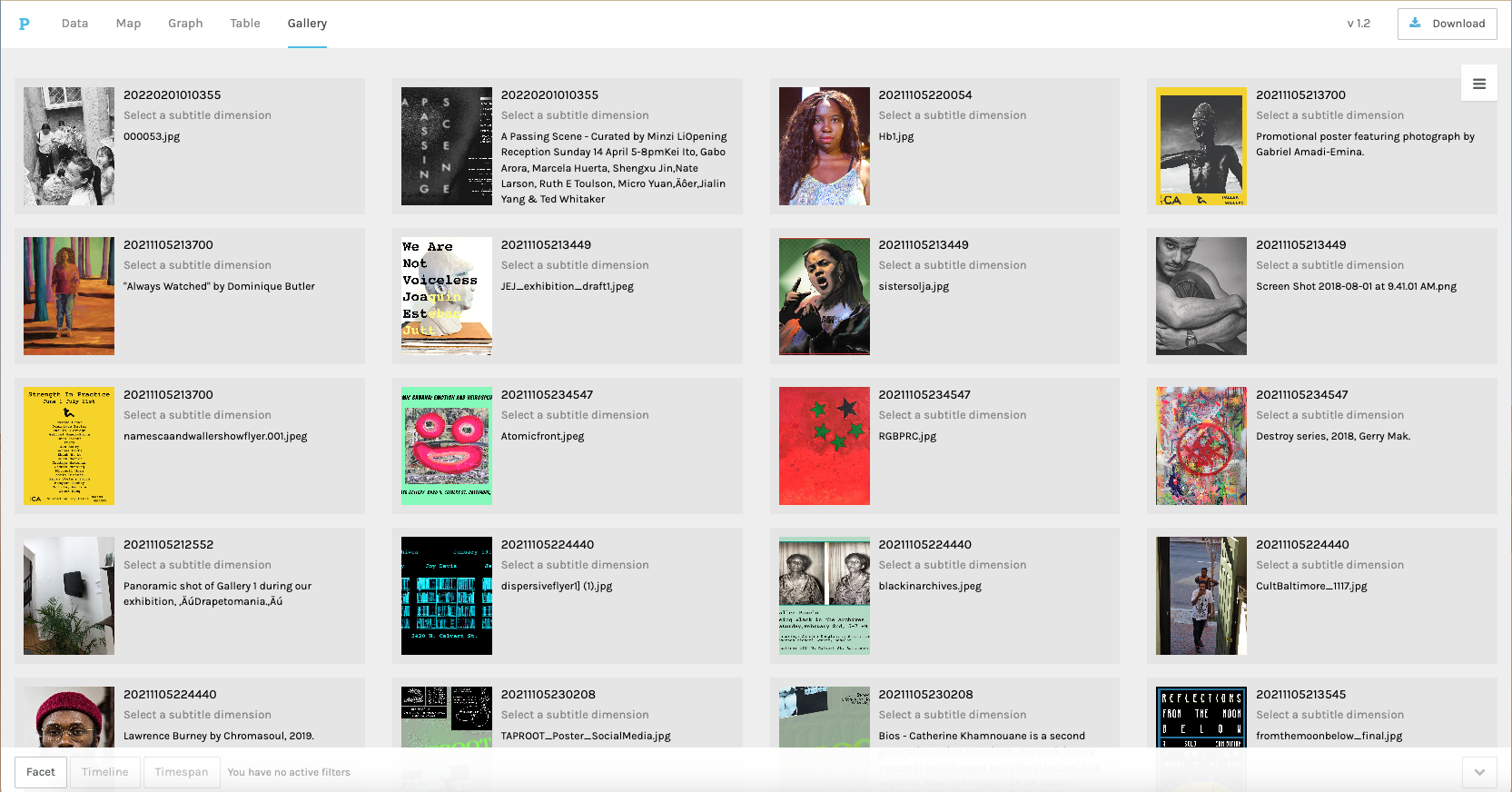
Screenshot of the random image gallery showing a grid of images from the dataset.
Introducing image search models
Looking at snapshots of the collection gives us a starting point for exploring what kinds of images are included in the collection. We can augment our approach by implementing image search.
There are various approaches we could take which would allow us to search our images. If we have the text surrounding an image, we could use this as a proxy for what the image might contain. For example, we might assume that if the text next to an image contains the words “a picture of my dog snowy”, then the image contains a picture of a dog. This approach has limitations – text might be missing, unrelated or only capture a small part of what is in an image. The text “a picture of my dog snowy” doesn’t tell us what kind of dog the image contains or if other things are included in that photo.
Making use of an embedding model offers another path forward. Embeddings essentially take an input i.e. text or image, and return a bunch of numbers. For example, the text prompt: ‘an image of a dog’, would be passed through an embedding model, which ‘translates’ text into a matrix of numbers (essentially a grid of numbers). What is special about these numbers is that they should capture some semantic information about the input; the embedding for a picture of a dog should somehow capture the fact that there is a dog in the image. Since these embeddings consist of numbers, we can also compare one embedding to another to see how close they are to each other. We expect the embeddings for similar images to be closer to each other and the embeddings for images which are less similar to each other to be farther away. Without getting too much into the weeds of how this works, it’s worth mentioning that these embeddings don’t just represent one aspect of an image, i.e. the main object it contains but also other components, such as its aesthetic style. You can find a longer explanation of how this works in this post.
Finding a suitable image search model on the Hugging Face Hub
To create an image search system for the dataset, we need a model to create embeddings. Fortunately, the Hugging Face Hub makes it easy to find models for this.
The Hub has various models that support building an image search system.
Hugging Face Hub showing a list of hosted models.
All models will have various benefits and tradeoffs. For example, some models will be much larger. This can make a model more accurate but also make it harder to run on standard computer hardware.
Hugging Face Hub provides an ‘inference widget’, which allows interactive exploration of a model to see what sort of output it provides. This can be very useful for quickly understanding whether a model will be helpful or not.
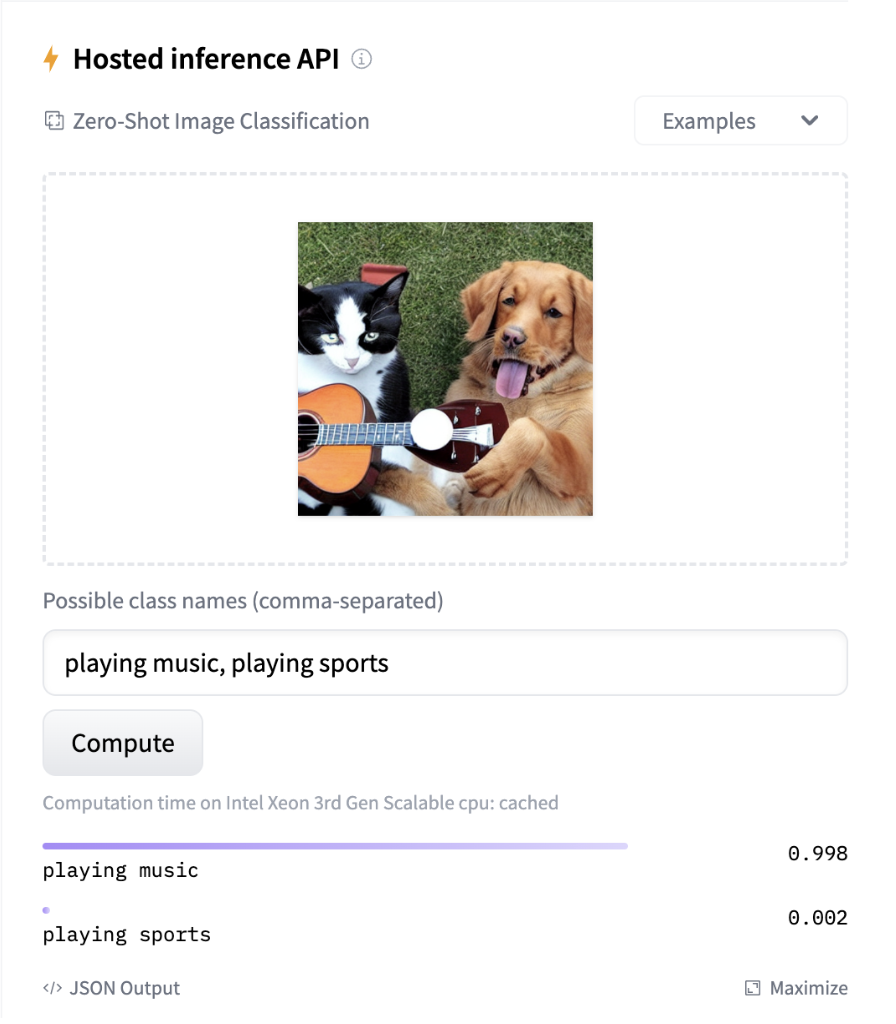
A screenshot of a model widget showing a picture of a dog and a cat playing the guitar. The widget assigns the label `”playing music`” the highest confidence.
For our use case, we need a model which allows us to embed both our input text, for example, “an image of a dog,” and compare that to embeddings for all the images in our dataset to see which are the closest matches. We use a variant of the CLIP model hosted on Hugging Face Hub: clip-ViT-B-16. This allows us to turn both our text and images into embeddings and return the images which most closely match our text prompt.
Aa screenshot of the search tab showing a search for “landscape photograph” in a text box and a grid of images resulting from the search. This includes two images containing trees and images containing the sky and clouds.
While the search implementation isn’t perfect, it does give us an additional entry point into an extensive collection of data which is difficult to explore manually. It is possible to extend this interface to accommodate an image similarity feature. This could be useful for identifying a particular artist’s work in a broader collection.
Image classification
While image search helps us find images, it doesn’t help us as much if we want to describe all the images in our collection. For this, we’ll need a slightly different type of machine learning task – image classification. An image classification model will put our images into categories drawn from a list of possible labels.
We can find image classification models on the Hugging Face Hub. The “Image Classification Model Tester” tab in the demo Gradio application allows us to test most of the 3,000+ image classification models hosted on the Hub against our dataset.
This can give us a sense of a few different things:
How well do the labels for a model match our data?A model for classifying dog breeds probably won’t help us much!
It gives us a quick way of inspecting possible errors a model might make with our data.
It prompts us to think about what categories might make sense for our images.
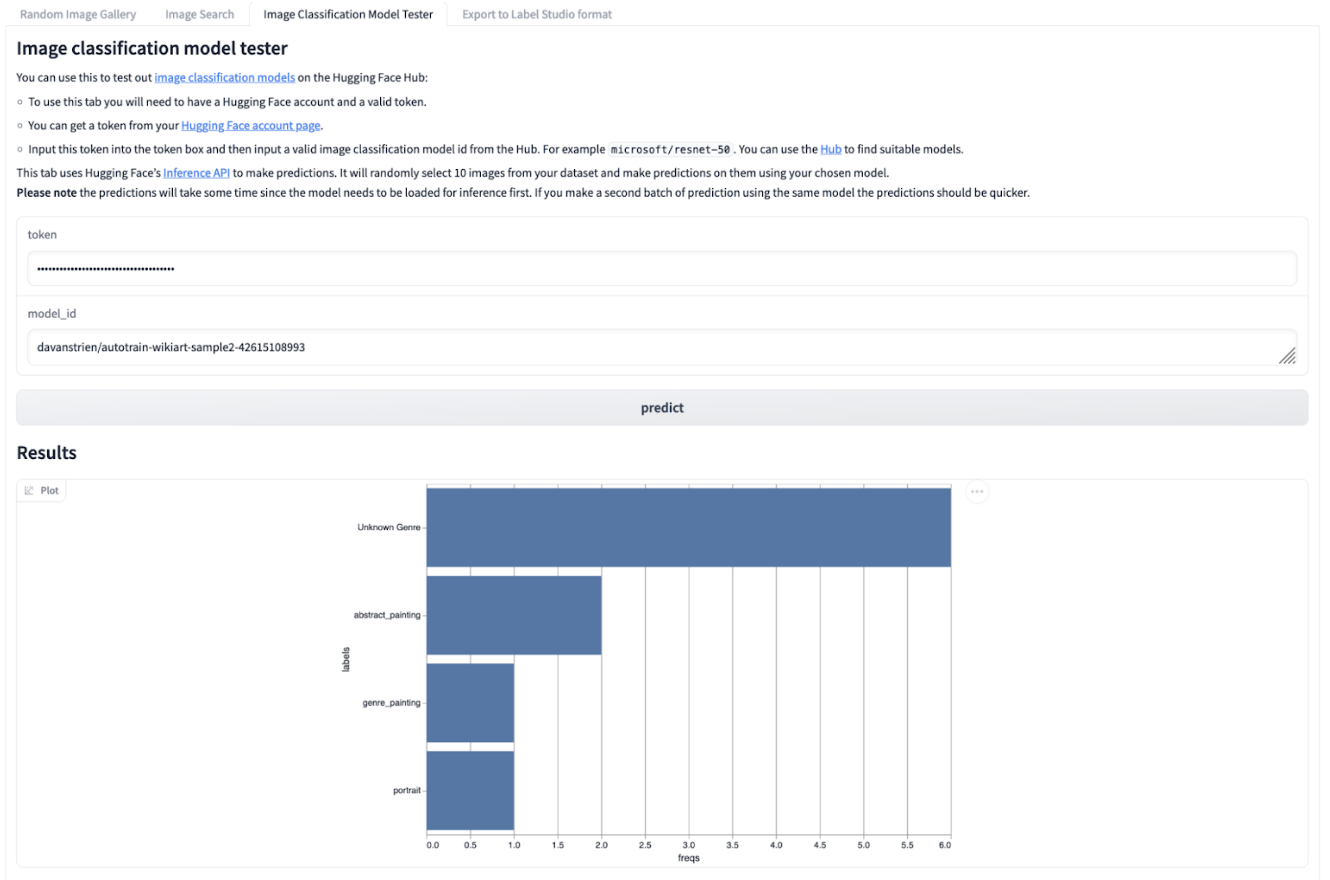
A screenshot of the image classification tab in the Gradio app which shows a bar chart with the most frequently predicted labels for images assigned by a computer vision model.
We may find a model that already does a good job working with our dataset – if we don’t, we may have to look at training a model.
Training your own computer vision model
The final tab of our Gradio demo allows you to export the image dataset in a format that can be loaded by Label Studio, an open-source tool for annotating data in preparation for machine learning tasks. In Label Studio, we can define labels we would like to apply to our dataset. For example, we might decide we’re interested in pulling out particular types of images from this collection. We can use Label Studio to create an annotated version of our dataset with these labels. This requires us to assign labels to images in our dataset with the correct labels. Although this process can take some time, it can be a useful way of further exploring a dataset and making sure your labels make sense.
With a labeled dataset, we need some way of training a model. For this, we can use AutoTrain. This tool allows you to train machine learning models without writing any code. Using this approach supports creation of a model trained on our dataset which uses the labels we are interested in. It’s beyond the scope of this post to cover all AutoTrain features, but this post provides a useful overview of how it works.
Next Steps
As mentioned in the introduction, you can explore the ARCH Image Dataset Explorer Demo yourself. If you know a bit of Python, you could also duplicate the Space and adapt or change the current functionality it supports for exploring the dataset.
Internet Archive and Hugging Face plan to organize a hands-on hackathon later this year focused on using open source machine learning tools from the Hugging Face ecosystem to work with web archives. The event will include building interfaces for web archive datasets, collaborative annotation, and training machine learning models. Please let us know if you are interested in participating by filling out this form.
This Spring, the Internet Archive hosted two in-person workshops aimed at helping to advance library support for web archive research: Digital Scholarship & the Web and Art Resources on the Web. These one-day events were held at the Association of College & Research Libraries (ACRL) conference in Pittsburgh and the Art Libraries Society of North America (ARLIS) conference in Mexico City. The workshops brought together librarians, archivists, program officers, graduate students, and disciplinary researchers for full days of learning, discussion, and hands-on experience with web archive creation and computational analysis. The workshops were developed in collaborationwith the New York Art Resources Consortium (NYARC) – and are part of an ongoing series of workshops hosted by the Internet Archive through Summer 2023.
Internet Archive Deputy Director of Archiving & Data Services Thomas Padilla discussing the potential of web archives as primary sources for computational research at Art Resources on the Web in Mexico City.
Designed in direct response to library community interest in supporting additional uses of web archive collections, the workshops had the following objectives: introduce participants to web archives as primary sources in context of computational research questions, develop familiarity with research use cases that make use of web archives; and provide an opportunity to acquire hands-on experience creating web archive collections and computationally analyzing them usingARCH (Archives Research Compute Hub) – a new service set to publicly launch June 2023.
Internet Archive Community Programs Manager Lori Donovan walking workshop participants through a demonstration of Palladio using a dataset generated with ARCH at Digital Scholarship & the Web In Pittsburgh, PA.
In support of those objectives, Internet Archive staff walked participants through web archiving workflows, introduced a diverse set of web archiving tools and technologies, and offered hands-on experience building web archives. Participants were then introduced to Archives Research Compute Hub (ARCH). ARCH supports computational research with web archive collections at scale – e.g., text and data mining, data science, digital scholarship, machine learning, and more. ARCH does this by streamlining generation and access to more than a dozen research ready web archive datasets, in-browser visualization, dataset analysis, and open dataset publication. Participants further explored data generated with ARCH in Palladio, Voyant, and RAWGraphs.
Network visualization of the Occupy Web Archive collection, created using Palladio based on a Domain Graph Dataset generated by ARCH.
Gallery visualization of the CARTA Art Galleries collection, created using Palladio based on an Image Graph Dataset generated by ARCH.
At the close of the workshops, participants were eager to discuss web archive research ethics, research use cases, and a diverse set of approaches to scaling library support for researchers interested in working with web archive collections – truly vibrant discussions – and perhaps the beginnings of a community of interest! We plan to host future workshops focused on computational research with web archives – please keep an eye on our Event Calendar.
We are excited to announce that the National Endowment for the Humanities (NEH) has awarded nearly $50,000 through its Digital Humanities Advancement Grant program to UC Berkeley Library and Internet Archive to study legal and ethical issues in cross-border text data mining research. NEH funding for the project, entitled Legal Literacies for Text Data Mining – Cross Border (LLTDM-X), will support research and analysis that addresses law and policy issues faced by U.S. digital humanities practitioners whose text data mining research and practice intersects with foreign-held or licensed content, or involves international research collaborations. LLTDM-X builds upon Building Legal Literacies for Text Data Mining Institute (Building LLTDM), previously funded by NEH. UC Berkeley Library directed BuildingLLTDM, bringing together expert faculty from across the country to train 32 digital humanities researchers on how to navigate law, policy, ethics, and risk within text data mining projects (results and impacts are summarized in the white paper here.)
Why is LLTDM-X needed?
Text data mining, or TDM, is an increasingly essential and widespread research approach. TDM relies on automated techniques and algorithms to extract revelatory information from large sets of unstructured or thinly-structured digital content. These methodologies allow scholars to identify and analyze critical social, scientific, and literary patterns, trends, and relationships across volumes of data that would otherwise be impossible to sift through. While TDM methodologies offer great potential, they also present scholars with nettlesome law and policy challenges that can prevent them from understanding how to move forward with their research. Building LLTDM trained TDM researchers and professionals on essential principles of licensing, privacy law, as well as ethics and other legal literacies —thereby helping them move forward with impactful digital humanities research. Further, digital humanities research in particular is marked by collaboration across institutions and geographical boundaries. Yet, U.S. practitioners encounter increasingly complex cross-border problems and must accordingly consider how they work with internationally-held materials and international collaborators.
How will LLTDM-X help?
Our long-term goal is to design instructional materials and institutes to support digital humanities TDM scholars facing cross-border issues. Through a series of virtual roundtable discussions, and accompanying legal research and analyses, LLTDM-X will surface these cross-border issues and begin to distill preliminary guidance to help scholars in navigating them. After the roundtables, we will work with the law and ethics experts to create instructive case studies that reflect the types of cross-border TDM issues practitioners encountered. Case studies, guidance, and recommendations will be widely-disseminated via an open access report to be published at the completion of the project. And most importantly, these resources will be used to inform our future educational offerings.
The LLTDM-X team is eager to get started. The project is co-directed by Thomas Padilla, Deputy Director, Archiving and Data Services at Internet Archive and Rachael Samberg, who leads UC Berkeley Library’s Office of Scholarly Communication Services. Stacy Reardon, Literatures and Digital Humanities Librarian, and Timothy Vollmer, Scholarly Communication and Copyright Librarian, both at UC Berkeley Library, round out the team.
We would like to thank NEH’s Office of Digital Humanities again for funding this important work. The full press release is available at UC Berkeley Library’s website. We invite you to contact us with any questions.