
For the last 15 years, users of the Wayback Machine have browsed past versions of websites by entering in URLs into the main search box and clicking on Browse History. With the generous support of The Laura and John Arnold Foundation, we’re adding an exciting new feature to this search box: keyword search!
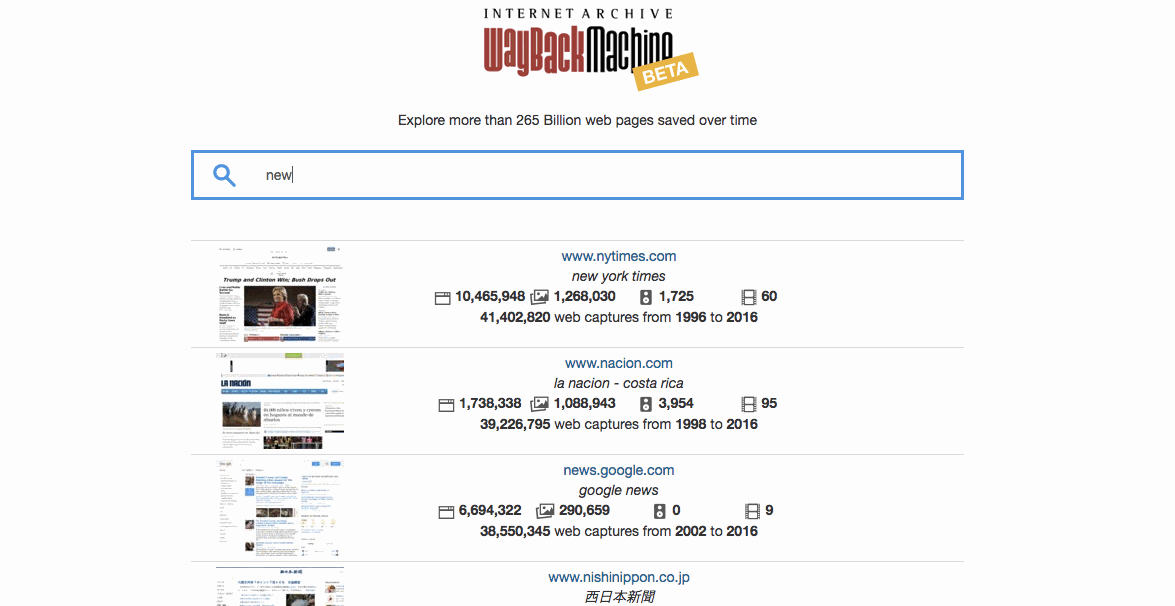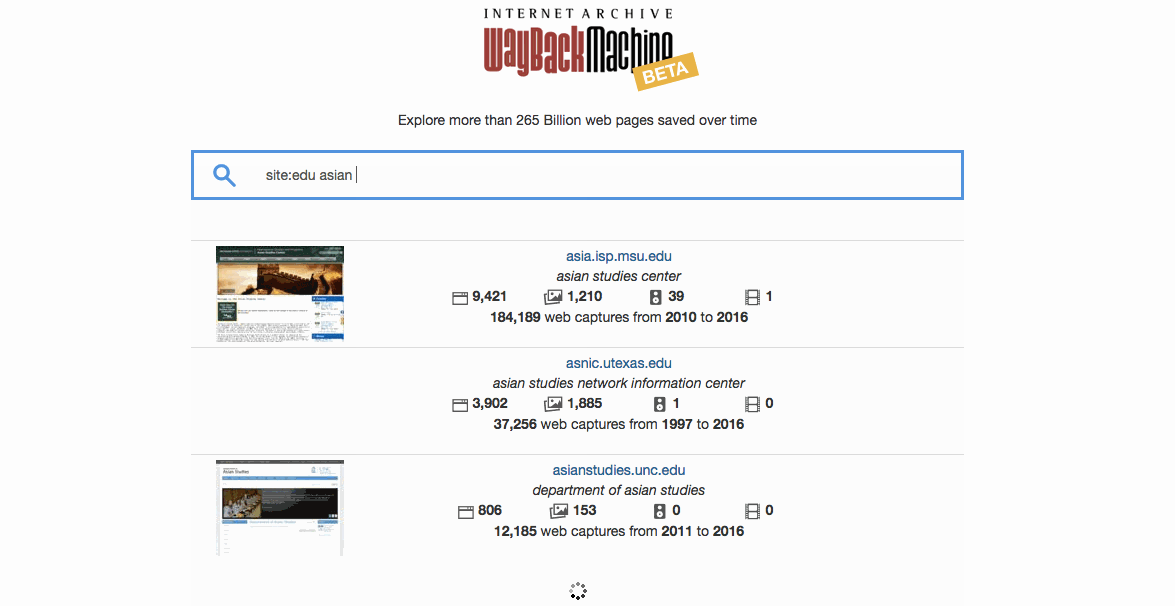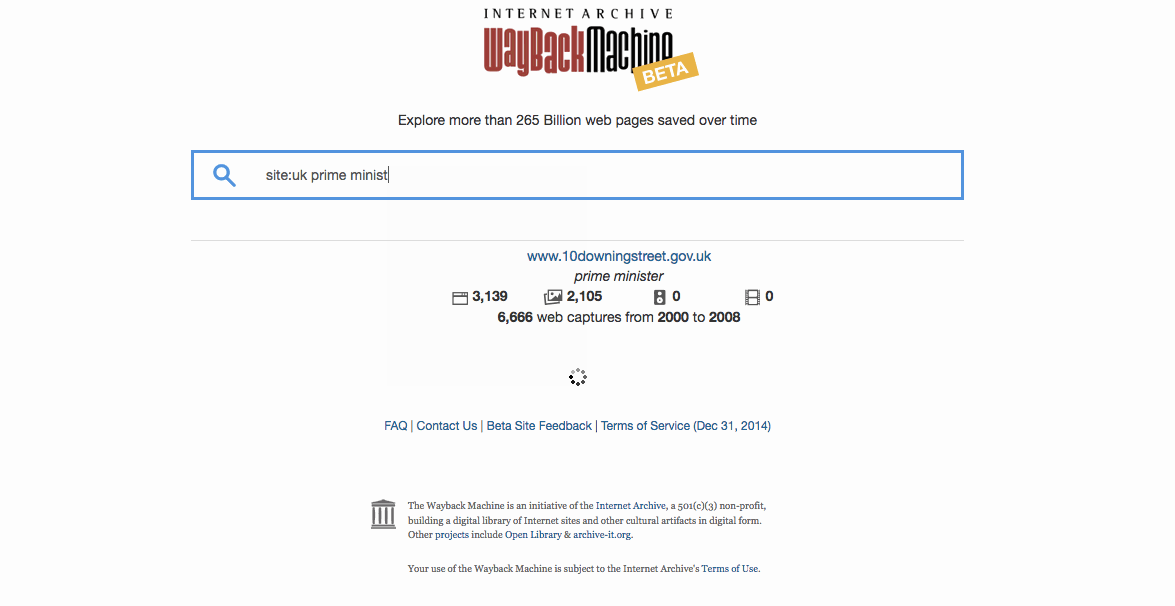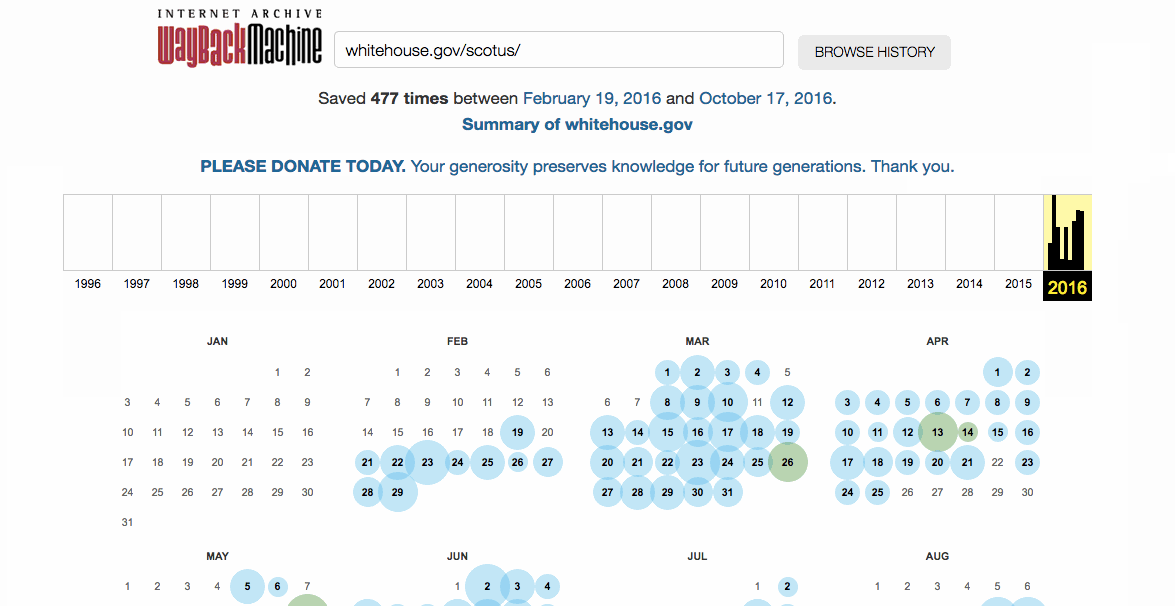
With this new beta search service, users will now be able to find the home pages of over 361 Million websites preserved in the Wayback Machine just by typing in keywords that describe these sites (e.g. “new york times”). As they type keywords into the search box, they will be presented with a list of relevant archived websites with snippets containing:
- a link to the archived versions of the site’s home page in the Wayback Machine
- a thumbnail image of the site’s homepage (when available)
- a short description of the site’s homepage
- a capture summary of the site
- number of unique URLs by content type (webpage, image, audio, video)
- number of valid web captures over the associated time period
Key Features
- Search as you type
- Instant results as you type — predictive, interactive and speedy
- Multilingual
- Search in any language or using symbols — expanding scope and utility
- Site-based Filtering
- Limit results to certain websites or domains using the site: operator (e.g. site:edu)
- Limit results to certain websites or domains using the site: operator (e.g. site:edu)
Behind the Scenes
- Search index was built by processing over 250 billion webpages archived over 20 years
- Index contains more than a billion terms collected from over 400 billion hyperlinks to the homepages of websites
- Search results are ranked based on the number of relevant hyperlinks to the site’s homepage and the total number of web captures from the site
Example queries
- Websites related to academic journals — academic journals
- Searching in Greek to find websites related to Aristotle — Αριστοτέλειο
- Government websites related to climate change — site:gov climate change
- Stanford websites related to Asian studies — site:stanford.edu asian studies
We hope that this service, to search and discover archived web resources through time, will create new opportunities for scholarly work and innovation.
A big Thank You to: Vinay Goel, Kenji Nagahashi, Mark Graham, Bill Lubanovic, John Lekashman, Greg Lindahl, Vangelis Banos, Richard Caceres, Zijian He, Eugene Krevenets, Benjamin Mandel, Rakesh Pandey, Wendy Hanamura and Brewster Kahle
