As many of you have already seen, we are working on the next generation of the archive.org web site, which we call Version 2.0 (v2). It’s in beta right now, so go check it out!
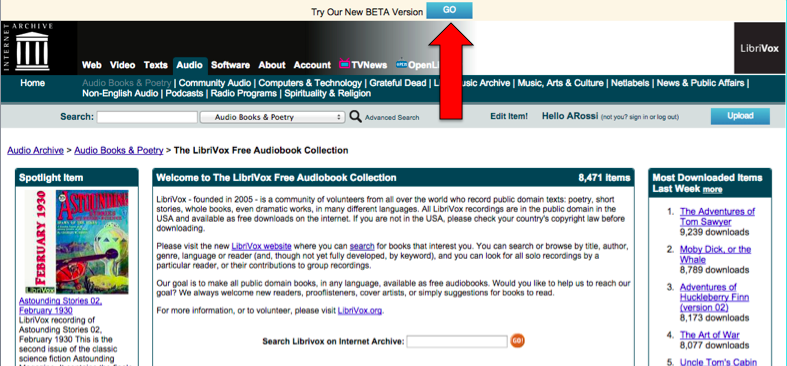
Version 1 (v1) showing the banner to try the BETA Version 2 (v2)
We get a lot of feedback from the people who have elected to try out v2, and we read ALL of it. As themes emerge about what people are having trouble with, we make changes to the design and then we pay attention to subsequent feedback to try to gauge whether we solved the problem (or not).
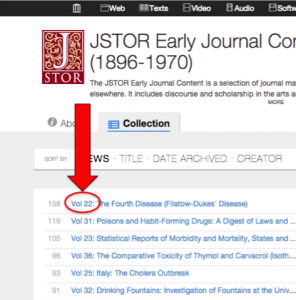
Volume prepended to title
The goal of this redesign is to make the site more inviting and easier to use. Right now our work is focused on how the site looks and how things are organized on the page. For the most part, everything that is available to you in Version 1 (v1) of the site is available to you in v2 – but those things may be in different places!
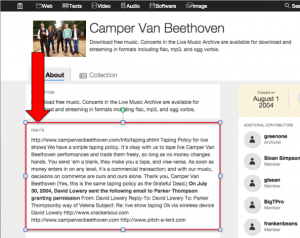
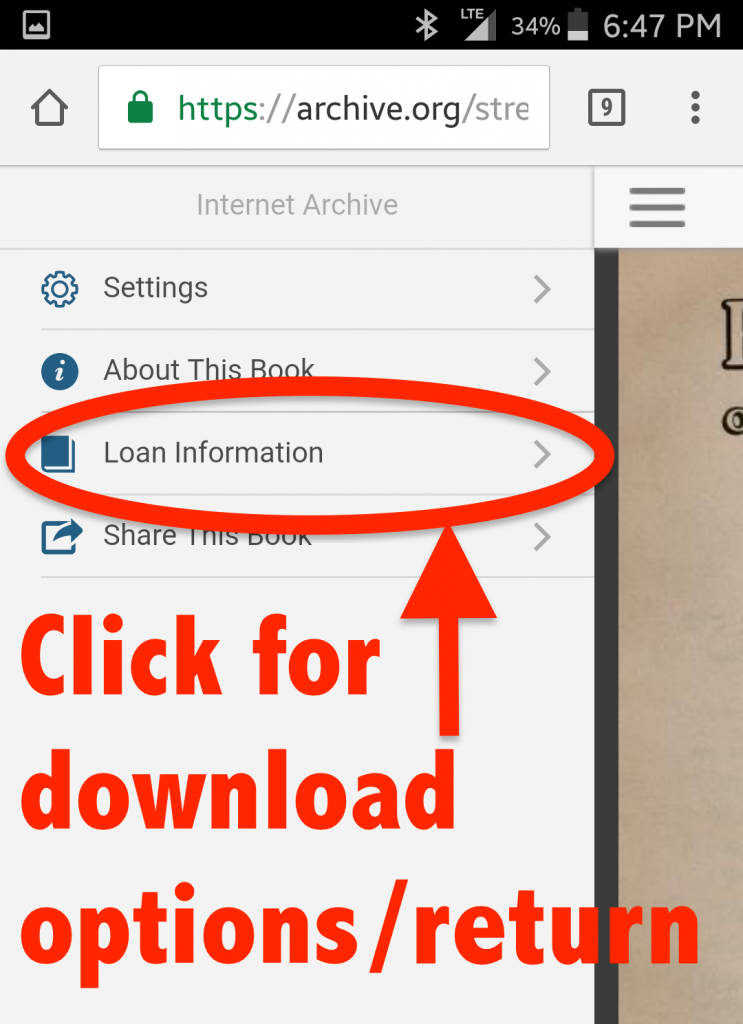
Rights information displayed in About tab
We have a lot of long-time users of the site, and we know that any major changes will cause them to have to relearn where things are and how to accomplish the things they already know how to do on v1. This kind of major change can be very annoying, so we’re working hard to make sure you only need to relearn things once. While we will be adding more features as time goes by, we expect those changes to be incremental and not to affect the basic layout of pages.
If you’ve been using v2, you’ve probably noticed some changes over the last few weeks. I’ll discuss some of those changes here, and some of them are highlighted in the included images.
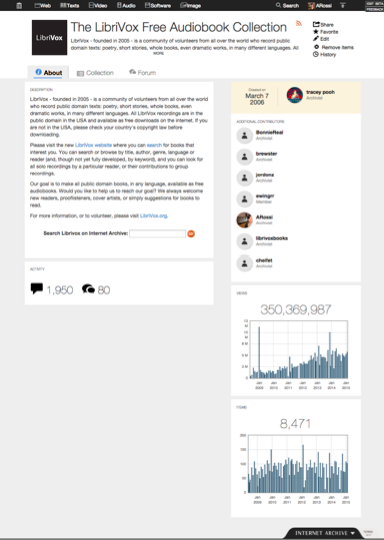
The collection About tab contains a longer description, info about contributors, and stats for reviews, forums, views and items
Volume information. We have a lot of journals and books with Volume information that was not showing in search, collection or account pages. The volume information is now prepended to the title for easier visual scanning within a collection.
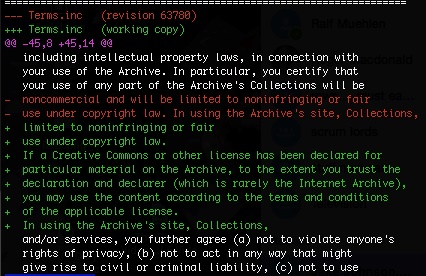
Live Music. Rights information for a collection is now displayed on the About tab. We also changed the way shows are described in band collections to list the date and venue before the band name, making it easier to visually scan the items in a collection.
Mobile. On most mobile devices we decreased the initial number of search results from 50 to 25 in order to lighten the page load time.
Collections Page
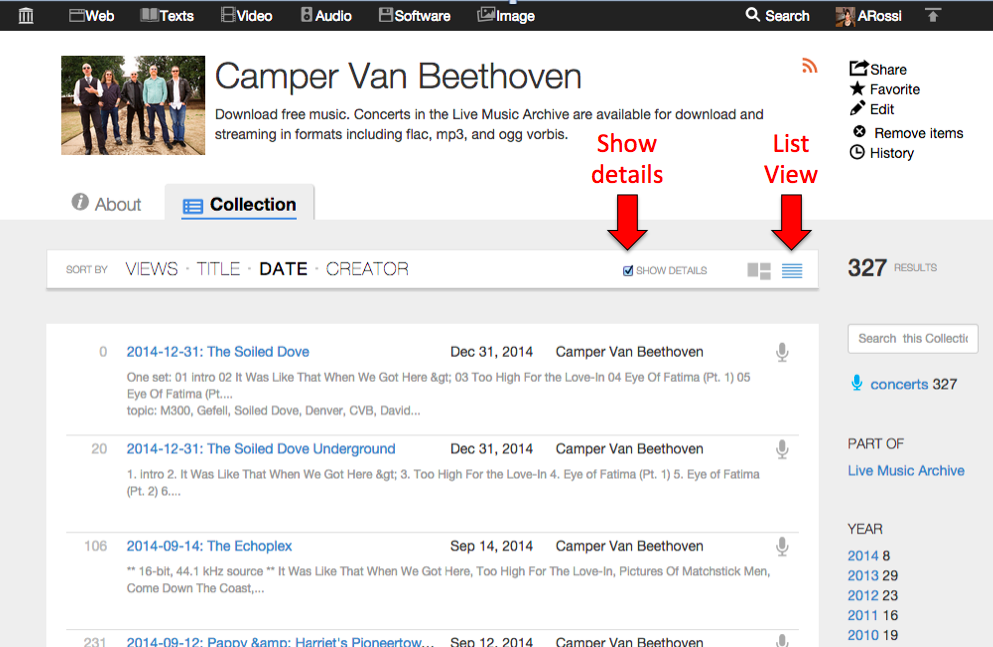
Go to list view for a collection and click the “Show details” checkbox
Collection description. The description area for the collection at the top of the page has been shortened. We encourage collection builders to add useful descriptions, and you can see the additional information in the new About tab.
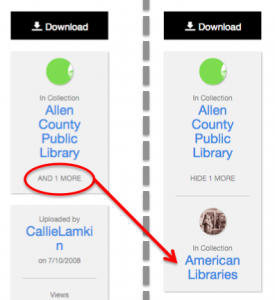
Click to see additional collections for an item
About tab. The About tab replaces the Contributors tab. We wanted to have a place for all of the information about a collection, and “Contributors” didn’t cover it. The new About tab contains the longer description for a collection, rights information (when it exists), data about how many reviews and forum posts are in that collection, and the content from the previous Contributors tab – the collection creator, people who have added to the collection, and charts for Views and Items over time. You will also find related collections listed on the About tab below the graphs. Parent collections and subcollections still show up in the Collections tab, since they are part of a collection’s direct hierarchy.
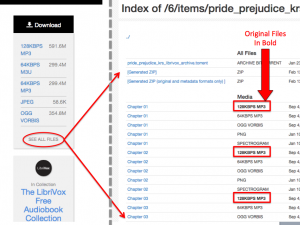
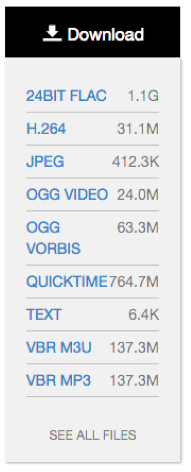
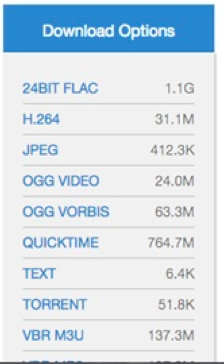
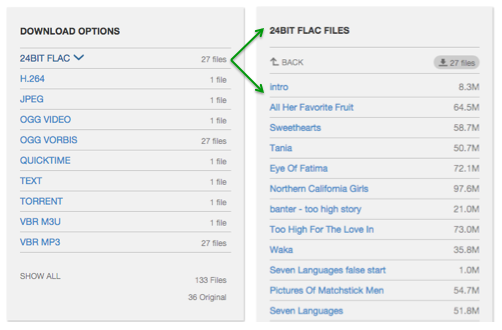
The See All Files page
Collection tab. The Collection tab has a few changes as well. In list view, you can now “show details” for each item if you want to see more information.
Item Pages
Additional collections. If an item belongs to more than one collection, you can choose to view those additional collections.
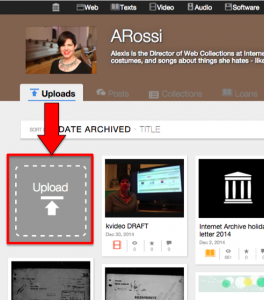
Upload tile on user account page
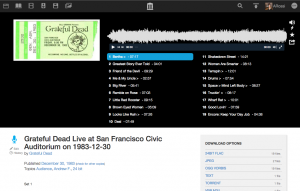
Stream only. When an item is not available for download, you will see a “Stream Only” notification where the “Download” button normally appears. We made some visual changes to this notification to make it seem less button-like.
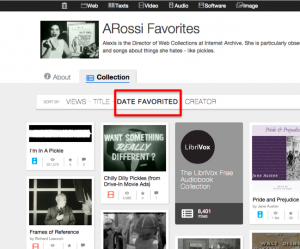
Favorites list sorted by Date Favorited
See All Files. In the “see all files” view, “playable” media files are pushed to the top, just under the “all files” options for torrent and zip. Files are grouped logically, with the original first and bolded and the derivative files listed below.
User Account Page
 Uploads. Your Uploads tab has a new “Upload” tile in it, just to make uploading easier to find. You can still upload from anywhere on the site by clicking the upload icon at the top of the page, of course.
Uploads. Your Uploads tab has a new “Upload” tile in it, just to make uploading easier to find. You can still upload from anywhere on the site by clicking the upload icon at the top of the page, of course.
Favorites. Your Favorites list (called bookmarks in v1) will now display your favorites sorted by “date favorited” so that you can see your most recently favorited items first.
Tell Us!
As always, please use the Beta feedback link in the top right corner to let us know what you think. Is everything awesome? Are you confused about where to find something? Tell us!
If you’re interested in a more detailed running log of changes from our lead developer, Tracey Jaquith, you can get the “nerd version” here: https://archive.org/CHANGELOG.txt
This project receives support from the John S. and James L. Knight Foundation’s Knight News Challenge.





































 Internet Archive’s
Internet Archive’s