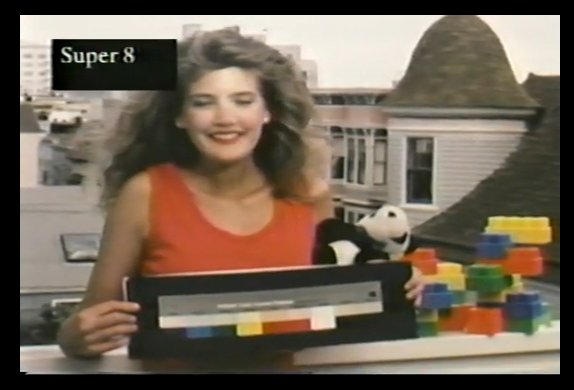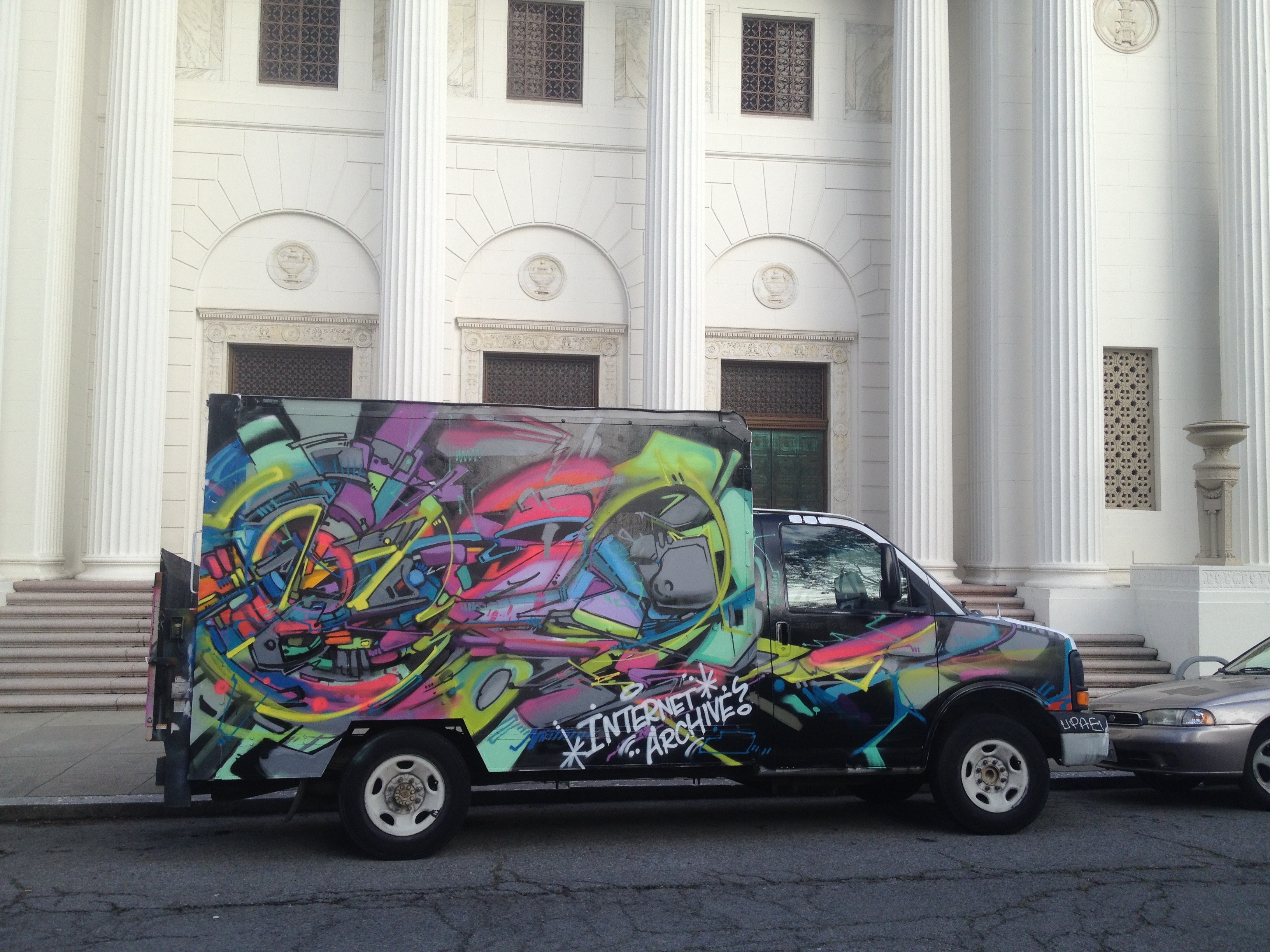The audio archive contains recordings ranging from alternative news programming, to Grateful Dead concerts, to Old Time Radio shows, to book and poetry readings, to original music uploaded by our users.
Founded in 2005, Librivox is a community of volunteers from all over the world who record audio versions of public domain texts: poetry, short stories, whole books, even dramatic works, in many different languages.
The Live Music Archive is a community committed to providing the highest quality live concerts in a lossless, downloadable format, along with the convenience of on-demand streaming.
The Internet Arcade is a web-based library of arcade (coin-operated) video games from the 1970s through to the 1990s, emulated in JSMAME, part of the JSMESS software package. Containing hundreds of games ranging through many different genres and styles, the Arcade provides research, comparison, and entertainment in the realm of the Video Game Arcade.
Many items are added to the Internet Archive’s collections every month, by us and by our patrons. Here’s a round up of some of the new media you might want to check out. Logging in might be required to borrow certain items.
Notable new collections:
Shakemore Festival (2007-present) Maryland: The Shakemore Music Festival is an annual weekend event comprised of 20 to 30 acts, featuring frequent appearances from what has become a large Shakemore family of bands (including Bang Bang Lulu, Caching Behavior, Cigarbox Planetarium, Go Pills, Weird Paul Rock Band, and many others).
Quantum Leap Podcast: The Quantum Leap Podcast talks about every episode of the cult hit time travel program, as well as the novels and comic books it inspired.
This month we’ve added books on varied subjects in more than 20 languages. Click through to explore, but here are a few interesting items to start with:
The audio archive contains recordings ranging from alternative news programming, to Grateful Dead concerts, to Old Time Radio shows, to book and poetry readings, to original music uploaded by our users.
Founded in 2005, Librivox is a community of volunteers from all over the world who record audiobooks of public domain texts in many different languages.
The Live Music Archive is a community committed to providing the highest quality live concerts in a lossless, downloadable format, along with the convenience of on-demand streaming (all with artist permission).
This collection hosts complete, freely downloadable/streamable, often Creative Commons-licensed catalogs of ‘virtual record labels’. These ‘netlabels’ are non-profit, community-built entities dedicated to providing high quality, non-commercial, freely distributable MP3/OGG-format music for online download in a multitude of genres.
By 1922 we were solidly in the Jazz Age – F. Scott Fitzgerald’s Tales of the Jazz Age was published in 1922, and the term was already in popular usage. Jazz migrated from Black American communities in New Orleans into the rest of the United States, having evolved from its roots in rag time, blues and Creole music. In fact, 1922 was the year Louis Armstrong left New Orleans to join King Oliver’s Creole Jazz Band in Chicago.
Alexander’s Ragtime Band (1911) written by Irving Berlin and performed by Collins and Harlan
Early recordings by Bert Williams (the first Black American on Broadway and the first Black man to star in a film), Fanny Brice (the real-life ‘Funny Girl’), Enrico Caruso (the legendary Italian operatic tenor), and so many others give life and flavor to our imaginings of the early 20th century.
Here are some of the top songs from 1922, to give you a taste:
But personally when I “flip through” these records I’m always drawn to the novelty songs.
There’s a whole genre of sound imitations, like Violin Mimicry where a violin is used to imitate people talking, Jingles from the Marsh Birds with a man imitating birds imitating popular songs (just as confusing as it sounds), and A Cat-astrophe with people imitating rather catastrophic cats to music.
As usual, we are also welcoming some new books, movies, journals, and sheet music – this time from 1926! (Read about 1925, 1924, and 1923 in previous posts.)
The Clothes We Wear (1926) by Frank and Frances Carpenter
Other interesting books from 1926 that you might want to explore include Show Boat by Edna Ferber which was made into the musical Show Boat in 1927 with music by Jerome Kern, The Clothes We Wear by Frank and Frances Carpenter which is a child friendly exploration of how clothes are made all the way from the field through weaving and into sewing, or The Art of Kissing by Clement Wood which is pretty self explanatory.
We invite you to explore some of the other items dated 1926 in our collections to find your own fun items that may now be in the public domain.
Virtual Party for the Public Domain
Please join us for a virtual party on January 20, 2022 at 1pm Pacific/4pm Eastern time with a keynote from Senator Ron Wyden, champion of the Music Modernization Act and a bunch of musical acts, dancers, historians, librarians, academics, activists and other leaders from the Open world! (And yes, we DO have a book from 1926 about how to throw the world’s best party.)
On January 1st, 2021, many books, movies and other media from 1925 will enter the public domain in the United States. Some of them are quite famous — jump ahead to see lists of those well known books and movies that you can enjoy on the Internet Archive — or take the scenic route with me.
What does this all mean? Essentially, many items created in 1925 in the US that are still under copyright will become free and open for people to use in any way they see fit in the new year. But check out Duke Law’s Center for the Study of the Public Domain article for a more in-depth explanation.
As part of this yearly ritual, I explore our collections to unearth these newly freed items, and I invariably run across a few things that hit a nerve. This year, it started with this intertitle in “Isn’t Life Terrible?” Less than 20 seconds into this 1925 film, and suddenly I’m dumped back into 2020.
Rude, right? I don’t even have a front yard to enjoy during shelter in place.
Gondolas still glide under the Bridge of Sighs, and the Tower of Pisa is still leaning, but the 1925 version of the Colosseum certainly lacks today’s fake gladiator photo ops.
Looking at the past with the eyes of today
Every toe dipped into the past has the potential to surprise or shock. The story of a pantry shelf, an outline history of grocery specialties is only mildly interesting on the surface. Essentially, it’s a sales pitch to food manufacturers encouraging them to advertise in a set of women’s magazines. The book contains short case histories of successful food brands like Maxwell House Coffee, Campbell Soup, Coca Cola, etc. (all of whom advertise with them, naturally).
The book gives you a glimpse of why people were so enthusiastic about mass produced, packaged foods. Unsanitary conditions, bugs in your sugar, milk going bad over night; things modern shoppers never think about.
It puts this glowing praise of Kraft Cheese into perspective: “…a pasteurized product, blended to obtain a uniformity of quality and flavor, a thing greatly lacking in ordinary types of cheese.” (page 149)
That’s pretty entertaining if you’re a cheese lover. I think most people would agree that Kraft cheese is no longer on the cutting edge.
But keep poking around and you find a much deeper cultural divergence. While The story of a pantry shelf is extolling the virtues of the home economics training available at Cornell, you stumble across this horrifying sentence (page 12).
I was not expecting to read about orphaned babies being used as “learning aids” while flipping through stories about Jell-O. Intellectually, I know that attitudes towards children have changed over the years — the Fair Labor Standards Act, which set federal standards for child labor, wasn’t even passed until 1938. But this casual aside tossed in amongst the marketing hype still packs an emotional punch. It’s important to remember how far we have come.
Even writing that was forward-thinking for the time, like the booklet Homo-sexual life, is terribly backward according to today’s standards. It’s from the Little Blue Book series — we have many that were published in 1925, and the publisher was quite prolific for many years. The series provided working class people with inexpensive access to all kinds of topics including philosophy, sexuality, science, religion, law, and government. Post WWII, they published criticism of J. Edgar Hoover and the founder was subsequently targeted by the FBI for tax evasion. But in 1925, they were going strong and one of their prolific writers was Clarence Darrow.
Controversies of the Age
Darrow was writing about prohibition for the Little Blue Book series in 1925, but that is also the year he defended John T. Scopes for teaching evolution in his Tennessee classroom. The Scopes Trial generated a huge amount of publicity, pitting religion against science, and even giving rise to popular songs like these two 78rpm recordings from 1925.
Like the Scopes trial, prohibition had its passionate adherents and detractors. This was the “Roaring 20s” — the year The Great Gatsby was published — with speakeasies and flappers and iconic cocktails. And yet the pro-prohibition silent film Episodes in the Life of a Gin Bottle follows a bottle around as it lures people into a state of dissolution.
And the most unchanging part of this particular season, of course — children still anticipate the arrival of Santa Claus with questions, wishes and schemes.
The silent film Santa Claus features two children who want to know where Saint Nick lives and how he spends his time. We follow him to the North Pole (Alaska in disguise) to see Santa’s workshop, snow castle, reindeer, and friends and neighbors. Jack Frost, introduced around 14:20, appears to be wearing the prototype for Ralphie’s bunny suit in “A Christmas Story” (but with a magic wand). Stick around for the sleigh crash at 20:45, and right around 22:20 Santa wipes out on the ice.
And just in case you’re still doing your holiday shopping, I feel like I should pass on a recommendation from this ad in a 1925 The Billboard magazine: Armadillo Baskets make beautiful Christmas gifts. And you can still buy vintage versions online – trust me, I looked. You’re welcome.
Juneteenth celebrates when enslaved people actually became free in 1865. The date, June 19th, commemorates General Gordon Granger of the Union Army announcing the executive order in Galveston, Texas, freeing all enslaved people in Texas.
Community access TV stations around the country have shown local celebrations of Juneteenth for years, and we thought this 2013 talk by Dr. Shennette Garrett-Scott at the Allen Public Library in Texas (via Allen City TV) was particularly helpful in understanding the history of this important day.
You could listen to multiple people recite the first 50 digits of pi in various styles, including to the tune of the Battle Hymn of the Republic (my personal favorite), in the voice of Bullwinkle, as an infomercial, in Latin, while laughing, in Morse Code, and while eating actual pie.
Commercial radio broadcasting began in the 1920s, bringing entertainment, news and music into people’s homes. Now, instead of needing to play a 78rpm disc on your phonograph, you could just tune in to listen to popular songs.
But why are we focusing on 1923? Because for the first time in 20 years, new works are entering the public domain in the United States (read more: 1,2, 3). And those works were all published in, you guessed it, 1923.
Jason Scott, free-range archivist, reporting in as 2017 draws to a close.
As part of our end-of-year fundraising drive, I thought it might be fun to tweet highlighted parts of the vast stacks of content that the Internet Archive makes available for free to millions. A lot of folks know about our Wayback Machine and its 20+ years of website history, but there’s petabytes of media and works available to see throughout the site. I called it “30 Days of Stuff”, and for the last 30 days I’ve been pointing out great items at the Archive, once a day.
You won’t have to swim upstream through my tweets; here on the last day, I’ve compiled the highlighted items in this entry. Enjoy these jewels in the Archive’s collection, a small sample of the wide range of items we provide.
Books and Texts
The Latch Key of my Bookhouse was one of the first books scanned by the Internet Archive in its book scanner tests, and it’s a 1921 directory of Children’s Literature that is filled with really nice illustrations that came out great.
Also in the DTIC collection is The Battalion Commander’s Handbook 1980, which besides the crazy front page of stamps, approvals and sign-offs, is basically a manager’s handbook written from the point of view of the US Army.
There are hundreds of tractor manuals at the Archive. Hundreds! Of all types, languages (a lot of them Russian) and level of information. Tractors are one of those tools that can last generations and keeping the maintenance on them in the field can make a huge difference in livelihood.
A lovely 1904 catalog for plums called The Maynard Plum Catalogue was scanned in with one of our partner organizations and it’s a breathless and inspiring declaration of the future wonder of the plums this wizard of plum-growing, Luther Burbank, was bringing to the world.
Xerox Corporation released “A Metamorphosis of Creative Copying” in 1964, which seems to function as both promotion for Xerox and a weird gift to give to your kids to color in.
In 2014, a short zine called The Tao of Bitcoin was released, telling people the dream of $10,000 bitcoin would be real.
The 1888 chapbook Goody Two-Shoes has lovely illustrations, and a fine short story.
Inside that directory was an ad for a school of whistling that said it taught using the methods of Agnes Woodward, and a quick scan of the Archive’s stacks showed that we had an entire copy of her book Whistling as an Art!
The medical treatise Sleep and Its Derangements, from 1869, is William A. Hammond, MD’s overview of sleep, and what can go wrong. Scanned from the Francis A. Countway Library of Medicine, it’s one of many thousands of books we’ve scanned with partners.
Let Hartman Feather Your Nest could be described as “A furniture catalog” in the same way the Sistine Chapel could be described as “a place of worship”. The catalog is a thundering, fist-pounding declaration of the superiority of the Hartman enterprise and the quality and breadth of furniture and service that will arrive at your door and be backed up to the far reaches of time.
Magazines
Photoplay considered itself the magazine for the motion picture industry in the first part of the 20th century, and this multi-volume compilation of photos, articles and advertisements is a truly lovely overview.
There’s over 140 issues of the classic Maximum RockNRoll zine, truly the king of music zines for a very long time. On its newsprint pages are howls and screeches of all manner of punk, rock and the needs of musicians.
A magazine created by the Walt Disney Company to trumpet various parts of Disneyland and its attractions was called Vacationland, and this Fall 1965 issue covers all sorts of stuff about the park’s first decade.
Movies
Rescued from a warehouse years ago, a collection of Hollywood movie “B-Roll”, unused secondary scenes often filmed by different crew, has been digitized. My personal favorite is [Western Film Scenes], which is circa 1950s footage of a Western Town, all of it utterly fake but feeling weirdly real, to be used in a western. Don’t miss everyone standing around looking right at you and looking like they agree quite energetically with you!
No compilation could be complete without the legendary Duck and Cover, a cartoon/PSA that explained the simple ways to avoid injury in a nuclear blast. Just lie down! It’ll be fine. Please note: This Probably Won’t Work. But the song is very catchy.
The very weird Electric Film Format Acid Test from 1990 has a semi-interested model holding up a color bar plate in a wide, wide variety of film and video formats. Filmed just a few blocks away from the Internet Archive’s current headquarters.
I snuck in a 1992 interview with the Archive’s founder, Brewster Kahle, back when he was 33 and working at WAIS, a company or two before the Archive and where he is asked about his thoughts on information and gathering of data. It’s quite interesting to hear the consistency of thought.
The Office of War Information worked with Disney to create “Dental Health“, a film to show to troops about proper dental care. It’s a combination of straightforward animation and industrial film-making worth enjoying.
Audio
We have a collection of hours of the radio show The Shadow from 1938-1939, starring Orson Welles at 23, at the height of his performance powers, playing the dual main role.
For Christmas Eve, we pointed to “Christmas Chopsticks”, a 1953 78rpm record of “Twas the Night Before Christmas” performed to the tune of the classic piano piece “Chopsticks”; one of tens of thousands of 78rpm records the Archive has been adding this year.
On Christmas, a user of the Archive uploaded two obscure albums he’d purchased on eBay – remnants of the S. S. Kresge Company, which became K-Mart, and which were played over the PA system for shoppers. He got his hands on Albums #261 and #294.
Earlier in the month before the user uploaded those Christmas albums, I linked to a different holiday collection of K-Mart items, a 1974 Reel-to-Reel that started with a K-Mart jingle and went full holiday from there.
Before he was a (retired) talk show host, and before he was a stand-up comedian, David Letterman worked and trained in radio. Happily, we have recordings of Dave Letterman, DJ, from when he was 22, at Ball State University.
Ron “Boogiemonster” Gerber has been hosting his weekly pop music recycling radio show, “Crap from the Past”, for over 25 years, and he’s been uploading and cataloging his show to the Archive for well over 10 of those years, including all the way back to the beginning of his show. The full Crap From The Past archive is up and is hundreds of hours of fun.
The truly weird “Conquer the Video Craze” is a 1982 record album with straightforward descriptions of how to beat games like Centipede, Defender, Stargate, Dig Dug, and more. This album has been sampled from by multiple DJs to bring that extra spice to a track.
Over 3,000 shows at the DNA Lounge are at the archive, including “Bootie: Gamer Night“, which combines mash-up tracks and video games. Bootie has been playing at DNA Lounge for years, and puts the audio from one song with the singing from another, and… it’s quite addicting, like games. This night was for the nearby Game Developers’ Conference being held the same week.
Software
In 2011, as part of a “retrocomputing” competition, we saw the release of “Paku-Paku”, a pac-clone program which ran in an obscure early PC-Compatible graphics mode that was very colorful and very small (160×100) and was built perfectly for it. You can play the game in your browser by clicking here.
Psion Chess is a game for the Macintosh that can play both you and itself with pretty high levels of skill and really sharp and crisp black and white graphics. It makes a really great screensaver in self-playing mode.
People often overuse a phrase like “Barely scratched the surface”, but I assure you there are millions of amazing items in the archive, and it’s been a pleasure to bring some to light. While the 30 Days of Stuff was a fun way to stretch out a month of fundraising with stuff to see every day, we’re here 24/7 to bring you all these items, and welcome you finding jewels, gems and clunkers throughout our hard drives whenever you want.
The work continues to expand the emulated systems and refresh what titles are available, but a project we’ve had going on the side for a while just came to fruition.
Among the organizations that turned out to benefit from having our browser-based emulations was X-Arcade, manufacturers of high-quality joysticks and control panels for use with computers and software. Meant to have the original Arcade feel, a few examples of these controllers were gifted to the Archive and we’ve used them pretty extensively in demonstration days and special events.
Last year, X-Arcade announced an old-school full-sized arcade machine case for sale, and generously offered to send one to the Archive as well. We contacted an excellent artist, Mar Williams of Sudux.com, who has done excellent art for the DEFCON hacking conference and many other events, and she put together custom Internet Archive-themed arcade side art for the machine. Here’s what she came up with:
The machine has made its way through shipping and moving companies and arrived at the Internet Archive’s 300 Funston Avenue headquarters in great shape, along with all the electronics and parts to make it go soon.
It’s one thing to see a mockup, and another to see the actual machine in your lobby:
Over the next few weeks, the system will be set up to run with the Internet Archive systems and provide a really nice demonstration station for the many guests and visitors we see. It really jazzes up the place!
When one of our employees came out of his home over the weekend, he saw an empty parking space. Granted, in San Francisco, that’s a pretty precious thing, but since this empty parking space had held the Internet Archive Truck for the previous two days, he was not feeling particularly lucky.
A staff conversation then ensued, the city was called to see if the truck had been towed, and after a short time, it became obvious that no, somebody had stolen the Truck.
This in itself is not news: thousands of vehicles are stolen in the Bay Area every year. But what makes this unusual was the nature of the vehicle stolen… the Truck is a pretty unique looking vehicle.
Once the report was filed with the police and a few more checks were made to ensure that the truck was absolutely, positively missing and presumed stolen, the truck’s theft was announced on Twitter, which garnered tens of thousands of views and the news being spread very far. Thanks to everyone who got the word out.
What was not expected, besides the initial theft, was that a lot of people wondered why the Internet Archive, essentially a website, would have a truck. So, here’s a little bit about why.
Besides the providing of older websites, books, movies, music, software and other materials to millions of visitors a day, the Internet Archive also has buildings for physical storage located in Richmond, just outside the limits of San Francisco. In these buildings, we hold copies of books we’ve scanned, audio recordings, software boxes, films, and a variety of other materials that we are either turning digital or holding for the future. It turns out you can’t be a 100% online experience – physical life just gets in the way. We also have multiple data centers and the need to transport equipment between them.
Therefore, we’ve had a hard-working vehicle for getting these materials around: a 2003 GMC Savana Cutaway G3500, often parked out front of the Archive’s 300 Funston Avenue address and making up to several trips a week between our various locations.
In a touch of whimsy, the truck has had a unique paint job for most of its life with the Archive. Notably, this isn’t even the first mural it had on its sides; here is a shot with the previous mural:
We’re not sure of the motivation in stealing this rather unique and noticeable vehicle, and there seems to be some evidence it was driven around the city for a while after it was taken. But yesterday, we were contacted by the San Francisco Police Department with really great news:
The Truck has been recovered!
Left abandoned by the side of the road, the truck was found and is about to be returned to the Archive, and with good luck, back and in service helping us prepare and transport materials related to our mission: to bring the world’s knowledge to everyone.
Again, thanks to everyone who sounded out the original call for the truck’s return, and to the SFPD for getting a hold of the truck so quickly after it was gone.