In celebration of National Library Week, we’d like to introduce you to some of the professional librarians who work at the Internet Archive and in projects closely associated with our programs. Over the next two weeks, you’ll hear from librarians and other information professionals who are using their education and training in library science and related fields to support the Internet Archive’s patrons.
What draws librarians to work at the Internet Archive? From patron services to collection management to web archiving, the answers are as varied as the departments in which these professionals work. But a common theme emerges from the profiles—that of professionals wanting to use their skills and knowledge in support of the Internet Archive’s mission: “Universal Access to All Knowledge.”
We hope that over these next two weeks you’ll learn something about the librarians working behind the scenes at the Internet Archive, and you’ll come to appreciate the training and dedication that influence their daily work. We’re pleased to help you “Meet the Librarians” during this National Library Week and beyond:
Jessamyn West, accessibility – Vermont Mutual Aid Society
As the war intensifies in Ukraine, volunteers from around the world are working to archive digital content at risk of destruction or manipulation. The Internet Archive is supporting several preservation efforts including the Saving Ukrainian Cultural Heritage Online (SUCHO) initiative launched in early March.
“When we think about the internet, we think the data is always going to be there. But all this data exists on physical servers and they can get destroyed just like buildings and monuments,” said Quinn Dombrowski, academic technology specialist at Stanford University and co-founder of SUCHO. “A tremendous amount of effort and energy has gone into the development of these websites and digitized collections. The people of Ukraine put them together for a reason. They wanted to share their history, culture, language and literature with the world.”
Watch:
More than 1,200 volunteers with SUCHO have saved 10 terabytes of data including 14,000 uploaded items (images and PDFs) and captured parts of 2,300 websites so far. This includes material from Ukrainian museums, library websites, digital exhibits, open access publications and elsewhere.
The initiative is using a combination of technologies to crawl and archive sites and content. Some of the information is stored at the Internet Archive, where it can be discovered and accessed using open-source software.
Staff at the Internet Archive are committed to assisting with the effort, which aligns with the organization’s mission of universal access to knowledge, and aim to make the web more useful and reliable, said Mark Graham, director of the Wayback Machine.
“This is a pivotal time in history,” he said. “We’re seeing major powers engaged in a war and it’s happening in the internet age where the platforms for information sharing and access we have built, and rely on, the Internet and the Web, are at risk.”
The Internet Archive is documenting and making information accessible that might not otherwise be available, Graham said. For years, the Wayback Machine has been archiving about 950 Russian news sites and 350 Ukrainian news sites. Stories that are deleted or altered are being archived for the historical record.
“We’re seeing major powers engaged in a war and it’s happening in the internet age where the platforms for information sharing and access…are at risk.”
Mark Graham, director, Wayback Machine
Recognizing the urgency of this moment, Dombrowski has been stunned by the response to help from archivists, scholars, librarians involved in cultural heritage and the general public. Volunteers need not have technical expertise or special language skills to be of value in the project.
“Many people were spending the days before they got involved with SUCHO scrolling the news and feeling helpless and wishing they could do something to contribute more directly towards helping out with the situation,” Dombrowski said. “It’s been really inspiring hearing the stories that people have told about what it’s meant to them to be able to be part of something like this.”
Gudrun Wirtz, head of the East European Department of the Bavarian State Library (Bayerische Staatsbibliothek) in Munich, was archiving on a smaller scale when she and other colleagues began to collaborate with SUCHO.
“We are committed to Ukraine’s heritage and horrified by this war against the people and their rich culture and the distorting of history going on,” Wirtz said. “As Germans we are especially shocked and reminded of our historical responsibility, because last time Ukraine was invaded it was 1941 by Nazi-Germany. We try to do everything we can at the moment.”
Anna Kiljas, Tufts University
The invasion of Ukraine hits particularly close to home for Anna Kijas, a librarian at Tufts University and co-founder of SUCHO, who is a Polish immigrant with family members who lived through Soviet occupation following WWII.
“Contributing to the SUCHO effort is something tangible that I can do and bring my expertise as a librarian and digital humanist in order to help preserve as much of the cultural heritage of the Ukrainian people as is possible,” said Kijas.
The third co-founder SUCHO, Sebastian Majstorovic, is with the Austrian Centre for Digital Humanities and Cultural Heritage.
The Internet Archive is providing technical support, tools and training to assist volunteers, including those with SUCHO, who are giving of their time.
Through Archive-It, a customizable self-service web archiving platform that captures, stores, and provides access to web-based content, free online accounts have been offered to volunteer archivists. Mirage Berry, business development manager for Archive-It, has coordinated support with other preservation partners including the Harvard Ukrainian Research Institute, the Center for Urban History of East Central Europe, and East European & Central Asian Studies Collections librarian Liladhar Pendse at University of California, Berkeley.
“It’s so incredible how quickly all of these archivists have pulled together to do this,” Berry said. “Everyone wants to do something. You don’t need to have a ton of technical experience. For anyone who is willing to learn, it’s a great jumping off point for web archiving.”
SUCHO organizers anticipate after the immediate emergency of website archiving is over, there will be an ongoing need to stay vigilant with data curation of Ukrainian material. To learn more and get involved, visit http://www.sucho.org.
In July, we announced our partnership with the Archives Unleashed project as part of our ongoing effort to make new services available for scholars and students to study the archived web. Joining the curatorial power of our Archive-It service, our work supporting text and data mining, and Archives Unleashed’s in-browser analysis tools will open up new opportunities for understanding the petabyte-scale volume of historical records in web archives.
As part of our partnership, we are releasing a series of publicly available datasets created from archived web collections. Alongside these efforts, the project is also launching a Cohort Program providing funding and technical support for research teams interested in studying web archive collections. These twin efforts aim to help build the infrastructure and services to allow more researchers to leverage web archives in their scholarly work. More details on the new public datasets and the cohorts program are below.
Early Web Datasets
Our first in a series of public datasets from the web collections are oriented around the theme of the early web. These are, of course, datasets intended for data mining and researchers using computational tools to study large amounts of data, so are absent the informational or nostalgia value of looking at archived webpages in the Wayback Machine. If the latter is more your interest, here is an archived Geocities page with unicorn GIFs.
GeoCities Collection (1994–2009)
As one of the first platforms for creating web pages without expertise, Geocities lowered the barrier of entry for a new generation of website creators. There were at least 38 million pages displayed by GeoCities before it was terminated by Yahoo! in 2009. This dataset collection contains a number of individual datasets that include data such as domain counts, image graph and web graph data, and binary file information for a variety of file formats like audio, video, and text and image files. A graphml file is also available for the domain graph.
Friendster was an early and widely used social media networking site where users were able to establish and maintain layers of shared connections with other users. This dataset collection contains graph files that allow data-driven research to explore how certain pages within Friendster linked to each other. It also contains a dataset that provides some basic metadata about the individual files within the archival collection.
These two related datasets were generated from the Internet Archive’s global web archive collection. The first dataset, “Parallel Language Records of the Early Web (1996–1999)” provides a dataset of multilingual records, or URLs of websites that have the same text represented in multiple languages. Such multi-language text from websites are a rich source for parallel language corpora and can be valuable in machine translation. The second dataset, “Language Annotations of the Early Web (1996–1999)” is another metadata set that annotates the language of over four million websites using Compact Language Detector (CLD3).
Applications are now being accepted from research teams interested in performing computational analysis of web archive data. Five cohorts teams of up to five members each will be selected to participate in the program from July 2021 to June 2022. Teams will:
Participate in cohort events, training, and support, with a closing event held at Internet Archive, in San Francisco, California, USA tentatively in May 2022. Prior events will be virtual or in-person, depending on COVID-19 restrictions
Receive bi-monthly mentorship via support meetings with the Archives Unleashed team
Work in the Archive-It Research Cloud to generate custom datasets
Receive funding of $11,500 CAD to support project work. Additional support will be provided for travel to the Internet Archive event
Looking for a research paper but can’t find a copy in your library’s catalog or popular search engines? Give Internet Archive Scholar a try! We might have a PDF from a “vanished” Open Access publisher in our web archive, an author’s pre-publication manuscript from their archived faculty webpage, or a digitized microfilm version of an older publication.
We hope Internet Archive Scholar will aid researchers and librarians looking for specific open access papers that may not be otherwise available to them. Judith van Stegeren (@jd7g on Twitter), a PhD candidate in the Netherlands, encountered just such a situation recently when sharing a workshop paper on procedural generation in computer games: “Towards Qualitative Procedural Generation” by Mark R. Johnson, originally presented at the Computational Creativity & Games Workshop in 2016. The papers for this particular year of the workshop are not indexed in the usual bibliographic catalogs, and the original workshop website hosting the Open Access papers is no longer accessible. Fortunately, copies of all the 2016 workshop papers were captured in the Wayback Machine, and can be found today by searching IA Scholar by title or conference name.
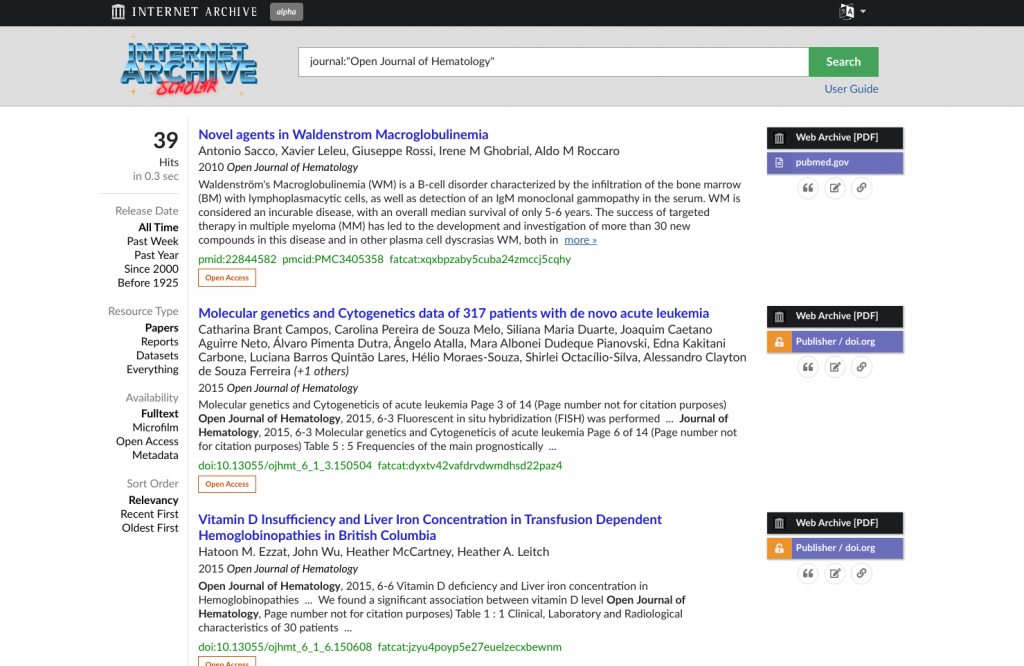
As another example, dozens of papers from the Open Journal of Hematology are no longer resolvable via DOI. As mentioned in a previous blog post, the publisher’s website vanished and has been replaced with unrelated advertisements. But before that happened, the papers were captured in the Wayback Machine, indexed in our catalog, and can now be searched in full:
IA Scholar Search Results
IA Scholar is a simple, access-oriented interface to content identified across several Internet Archive collections, including web archives, archive.org files, and digitized print materials. The full text of articles is searchable for users that are hunting for particular phrases or keywords. This complements our existing full-text search index of millions of digitized books and other documents on archive.org.
The service builds on Fatcat, an open catalog we have developed to identify at-risk and web-published open scholarly outputs that can benefit from long-term preservation, additional metadata, and perpetual access. Fatcat includes resources that may be useful to librarians and archivists, such as bulk metadata dumps, a read/write API, command-line tool, and file-level archival metadata. If you are interested in collaborating with us, or are a researcher interested in text analysis applications, we have a public chat channel or can be contacted by email at info@archive.org.
IA Scholar marks a milestone in our work initiated in 2018 to leverage the automation and scale of web and API harvesting in providing open infrastructure for the preservation of and perpetual access to scholarly materials from the public web. We particularly want to thank the Mellon Foundation for their original and ongoing support of this work, our many current partners, and the other collaborators, contributors, and volunteers.
All of this is possible because of the incredible open research ecosystem built and collectively maintained by Open Access advocates. Thank you to the DOAJ and other groups for helping catalog open access journals which has aided preservation. Thank you to the Biodiversity Heritage Library and its supporters for digitizing print journal literature. And thank you to the many other organizations we have worked with, integrated, or whose services we have utilized, including open web indices (Unpaywall, CORE, CiteseerX, Microsoft Academic, Semantic Scholar), directories of open journals (DOAJ, ROADSHERPA/ROMEO, JURN, Wikidata), and open bibliographic catalogs (Crossref, Datacite, J-STAGE, Pubmed, dblp).
Internet Archive has archived and identified 9 million open access journal articles– the next 5 million is getting harder
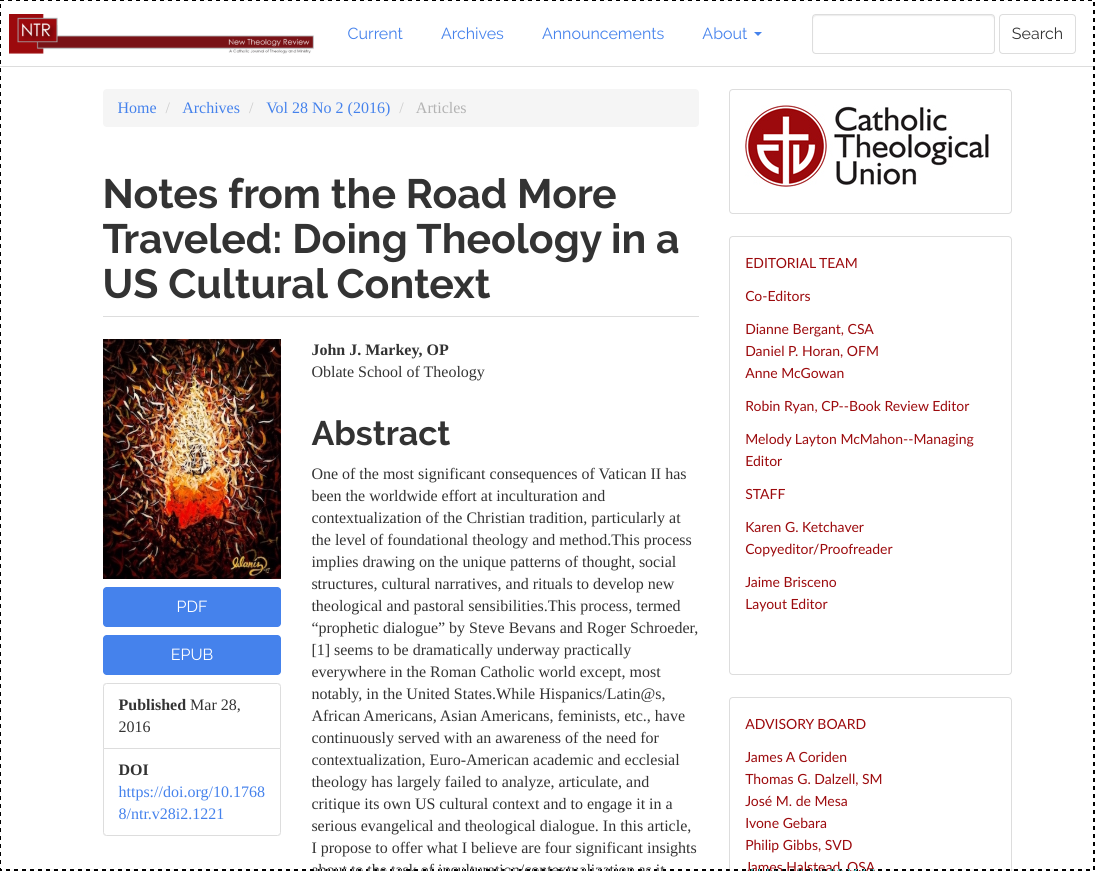
Open Access journals, such as New Theology Review (ISSN: 0896-4297) and Open Journal of Hematology (ISSN: 2075-907X), made their research articles available for free online for years. With a quick click or a simple query, students anywhere in the world could access their articles, and diligent Wikipedia editors could verify facts against original articles on vitamin deficiency and blood donation.
But some journals, such as these titles, are no longer available from the publisher’s websites, and are only available through the Internet Archive’s Wayback Machine. Since 2017, the Internet Archive joined others in concentrating on archiving all scholarly literature and making it permanently accessible.
The World Wide Web has made it easier than ever for scholars to collaborate, debate, and share their research. Unfortunately, the structure of today’s web means that content can disappear just as easily: as of today the official publisher websites and DOI redirects for both of the above journals go nowhere or have been replaced with unrelated content.
Wayback Machine captures of Open Access journals now “vanished” from publisher websites
Vigilant librarians saw this problem coming decades ago, when the print-to-digital migration was getting started. They insisted that commercial publishers work with contract digital preservation organizations (such as Portico, LOCKSS, and CLOCKSS) to ensure long-term access to expensive journal subscription content. Efforts have been made to preserve open articles as well, such as Public Knowledge Project’s Private LOCKSS Network for OJS journals and national hosting platforms like the SciELO network. But a portion of all scholarly articles continues to fall through the cracks.
Researchers found that 176 open access journals have already vanished from their publishers’ website over the past two decades, according to a recent preprint article by Mikael Laakso, Lisa Matthias, and Najko Jahn. These periodicals were from all regions of the world and represented all major disciplines — sciences, humanities and social sciences. There are over 14,000 open access journals indexed by the Directory of Open Access Journals and the paper suggests another 900 of those are inactive and at risk of disappearing. The pre-print has struck a nerve, receiving news coverage in Nature and Science.
In 2017, with funding support from the Andrew Mellon Foundation and the Kahle/Austin Foundation, the Internet Archive launched a project focused on preserving all publicly accessible research documents, with a particular focus on open access materials. Our first job was to quantify the scale of the problem.
Monitoring independent preservation of Open Access journal articles published from 1996 through 2019. Categories are defined in the article text.
Of the 14.8 million known open access articles published since 1996, the Internet Archive has archived, identified, and made available through the Wayback Machine 9.1 million of them (“bright” green in the chart above). In the jargon of Open Access, we are counting only “gold” and “hybrid” articles which we expect to be available directly from the publisher, as opposed to preprints, such as in arxiv.org or institutional repositories. Another 3.2 million are believed to be preserved by one or more contracted preservation organizations, based on records kept by Keepers Registry (“dark” olive in the chart). These copies are not intended to be accessible to anybody unless the publisher becomes inaccessible, in which case they are “triggered” and become accessible.
This leaves at least 2.4 million Open Access articles at risk of vanishing from the web (“None”, red in the chart). While many of these are still on publisher’s websites, these have proven difficult to archive.
One of our goals is to archive as many of the articles on the open web as we can, and to keep up with the growing stream of new articles published every day. Another is to look back over the vast petabytes of web content in the Wayback Machine, back to 1996, and find any content we might already have but is not easily findable or discoverable. Both of these projects are amenable to software automation, but made more difficult by the evolving nature of HTML and PDFs and their diverse character sets and encodings. To that end, we have approached this project not just as a technical one, but also as a collaborative one that aims to add another piece to the distributed infrastructure supporting open scholarship.
To expand our reach, we built an editable catalog (https://fatcat.wiki) with an open API to allow anybody to contribute. As the software is free and open source, as is the data, we invite others to reuse and link to the content we have archived. We have also indexed and made searchable much of the literature to help manage our work and help others find if we have archived particular articles. We want to make scholarly material permanently available, and available in new ways– including via large datasets for analysis and “meta research.”
We also want to acknowledge the many partnerships and collaborations that have supported this work, many of which are key parts of the open scholarly infrastructure, including ISSN, DOAJ, LOCKSS, Unpaywall, Semantic Scholar, CiteSeerX, Crossref, Datacite, and many others. We also want to acknowledge the many Internet Archive staff and volunteers that have contributed to this work, including Bryan Newbold, Martin Czygan, Paul Baclace, Jefferson Bailey, Kenji Nagahashi, David Rosenthal, Victoria Reich, Ellen Spertus, and others.
If you would like to participate in this project, please contact the Internet Archive at webservices@archive.org.
Archived web data and collections are increasingly important to scholarly practice, especially to those scholars interested in data mining and computational approaches to analyzing large sets of data, text, and records from the web. For over a decade Internet Archive has worked to support computational use of its web collections through a variety of services, from making raw crawl data available to researchers, performing customized extraction and analytic services supporting network or language analysis, to hosting web data hackathons and having dataset download features in our popular suite of web archiving services in Archive-It. Since 2016, we have also collaborated with the Archives Unleashed project to support their efforts to build tools, platforms, and learning materials for social science and humanities scholars to study web collections, including those curated by the 700+ institutions using Archive-It.
We are excited to announce a significant expansion of our partnership. With a generous award of $800,000 (USD) to the University of Waterloo from The Andrew W. Mellon Foundation, Archives Unleashed and Archive-It will broaden our collaboration and further integrate our services to provide easy-to-use, scalable tools to scholars, researchers, librarians, and archivists studying and stewarding web archives. Further integration of Archives Unleashed and Archive-It’s Research Services (and IA’s Web & Data Services more broadly) will simplify the ability of scholars to analyze archived web data and give digital archivists and librarians expanded tools for making their collections available as data, as pre-packaged datasets, and as archives that can be analyzed computationally. It will also offer researchers a best-of-class, end-to-end service for collecting, preserving, and analyzing web-published materials.
The Archives Unleashed team brings together a team of co-investigators. Professor Ian Milligan, from the University of Waterloo’s Department of History, Jimmy Lin, Professor and Cheriton Chair at Waterloo’s Cheriton School of Computer Science, and Nick Ruest, Digital Assets Librarian in the Digital Scholarship Infrastructure department of York University Libraries, along with Jefferson Bailey, Director of Web Archiving & Data Services at the Internet Archive, will all serve as co-Principal Investigators on the “Integrating Archives Unleashed Cloud with Archive-It” project. This project represents a follow-on to the Archives Unleashed project that began in 2017, also funded by The Andrew W. Mellon Foundation.
“Our first stage of the Archives Unleashed Project,” explains Professor Milligan, “built a stand-alone service that turns web archive data into a format that scholars could easily use. We developed several tools, methods and cloud-based platforms that allow researchers to download a large web archive from which they can analyze all sorts of information, from text and network data to statistical information. The next logical step is to integrate our service with the Internet Archive, which will allow a scholar to run the full cycle of collecting and analyzing web archival content through one portal.”
“Researchers, from both the sciences and the humanities, are finally starting to realize the massive trove of archived web materials that can support a wide variety of computational research,” said Bailey. “We are excited to scale up our collaboration with Archives Unleashed to make the petabytes of web and data archives collected by Archive-It partners and other web archiving institutions around the world more useful for scholarly analysis.”
The project begins in July 2020 and will begin releasing public datasets as part of the integration later in the year. Upcoming and future work includes technical integration of Archives Unleashed and Archive-It, creation and release of new open-source tools, datasets, and code notebooks, and a series of in-person “datathons” supporting a cohort of scholars using archived web data and collections in their data-driven research and analysis. We are grateful to The Andrew W. Mellon Foundation for their support of this integration and collaboration in support of critical infrastructure supporting computational scholarship and its use of the archived web.
Primary contacts: IA – Jefferson Bailey, Director of Web Archiving & Data Services, jefferson [at] archive.org AU – Ian Milligan, Professor of History, University of Waterloo, i2milligan [at] uwaterloo.ca
The Internet Archive’s Archive-It service is collaborating with the International Internet Preservation Consortium’s (IIPC) Content Development Group (CDG) to archive web-published resources related to the ongoing Novel Coronavirus (Covid-19) outbreak. The IIPC Content Development Group consists of curators and professionals from dozens of libraries and archives from around the world that are preserving and providing access to the archived web. The Internet Archive is a co-founder and longtime member of the IIPC. The project will include both subject-expert curation by IIPC members as well as the inclusion of websites nominated by the public (see the nomination form link below).
Due to the urgency of the outbreak, archiving of nominated web content will commence immediately and continue as needed depending on the course of the outbreak and its containment. Web content from all countries and in any language is in scope. Possible topics to guide nominations and collections:
A special thanks to Alex Thurman of Columbia University and Nicola Bingham of the British Library, the co-chairs of the IIPC CDG, and to other IIPC members participating in the project. Thanks as well to any and all public nominators assisting with identifying and archiving records about this significant global event.
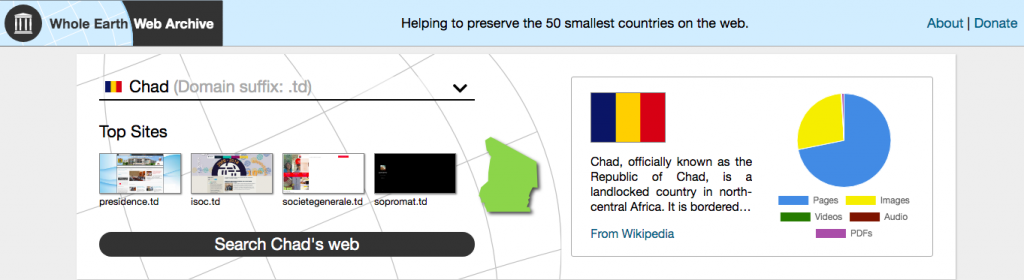
As part of the many releases and announcements for our October Annual Event, we created The Whole Earth Web Archive. The Whole Earth Web Archive (WEWA) is a proof-of-concept to explore ways to improve access to the archived websites of underrepresented nations around the world. Starting with a sample set of 50 small nations we extracted their archived web content from the Internet Archive’s web archive, built special search and access features on top of this subcollection, and created a dedicated discovery portal for searching and browsing. Further work will focus on improving IA’s harvesting of the national webs of these and other underrepresented countries as well as expanding collaborations with libraries and heritage organizations within these countries, and via international organizations, to contribute technical capacity to local experts who can identify websites of value that document the lives and activities of their citizens.
Archived materials from the web play an increasingly necessary role in representation, evidence, historical documentation, and accountability. However, the web’s scale is vast, it changes and disappears quickly, and it requires significant infrastructure and expertise to collect and make permanently accessible. Thus, the community of National Libraries and Governments preserving the web remains overwhelmingly represented by well-resourced institutions from Europe and North America. We hope the WEWA project helps provide enhanced access to archived material otherwise hard to find and browse in the massive 20+ petabytes of the Wayback Machine. More importantly, we hope the project provokes a broader reflection upon the lack of national diversity in institutions collecting the web and also spurs collective action towards diminishing the overrepresentation of “first world” nations and peoples in the overall global web archive.
As with prior special projects by the Web Archiving & Data Services team, such as GifCities (search engine for animated Gifs from the Geocities web collection) or Military Industrial Powerpoint Complex (ebooks of Powerpoints from the archive of the .mil (military) web domain), the project builds on our exploratory work to provide improved access to valuable subsets of the web archive. While our Archive-It service gives curators the tools to build special collections of the web, we also work to build unique collections from the pre-existing global web archive.
The preliminary set of countries in WEWA were determined by selecting the 50 “smallest” countries as measured by number of websites registered on their national web domain (aka ccTLD) — a somewhat arbitrary measurement, we acknowledge. The underlying search index is based on internally-developed tools for search of both text and media. Indices are built from features like page titles or descriptive hyperlinks from other pages, with relevance ranking boosted by criteria such as number of inbound links and popularity and include a temporal dimension to account for the historicity of web archives. Additional technical information on search engineering can be found in “Exploring Web Archives Through Temporal Anchor Texts.”
We intend both to do more targeted, high-quality archiving of these and other smaller national webs and also have undertaking active outreach to national and heritage institutions in these nations, and to related international organizations, to ensure this work is guided by broader community input. If you are interested in contributing to this effort or have any questions, feel free to email us at webservices [at] archive [dot] org. Thanks for browsing the WEWA!
The Internet Archive has transformed 130,000 references to books in Wikipedia into live links to 50,000 digitized Internet Archive books in several Wikipedia language editions including English, Greek, and Arabic. And we are just getting started. By working with Wikipedia communities and scanning more books, both users and robots will link many more book references directly into Internet Archive books. In these cases, diving deeper into a subject will be a single click.
“I want this,” said Brewster Kahle’s neighbor Carmen Steele, age 15, “at school I am allowed to start with Wikipedia, but I need to quote the original books. This allows me to do this even in the middle of the night.”
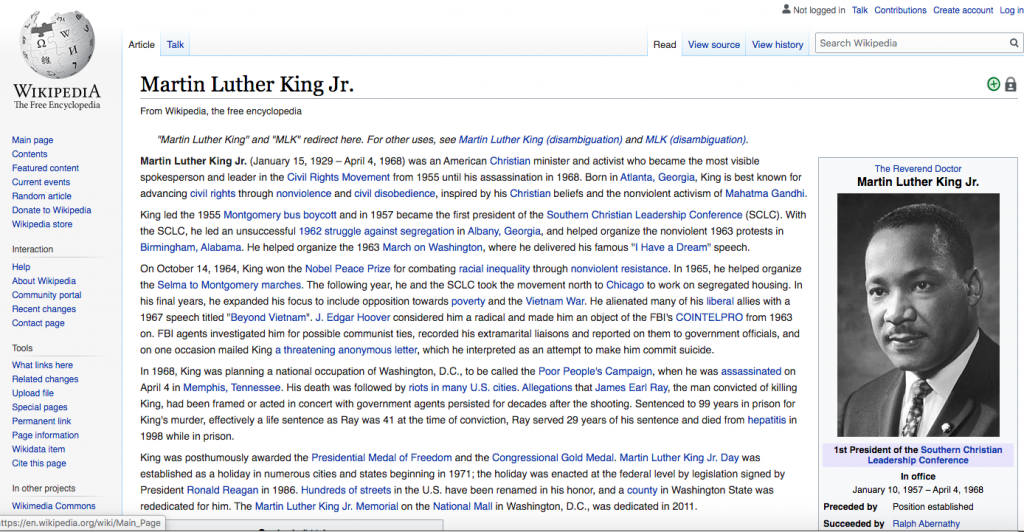
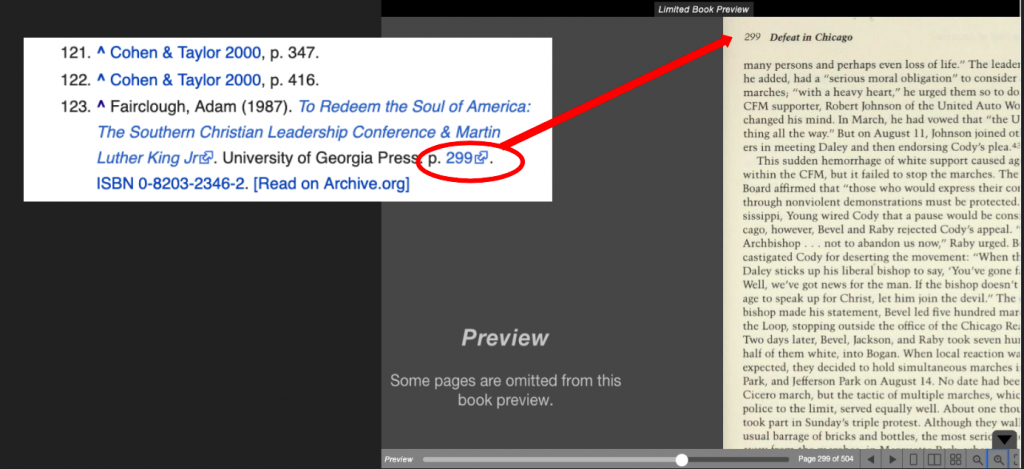
For example, the Wikipedia article on Martin Luther King, Jr cites the book To Redeem the Soul of America, by Adam Fairclough. That citation now links directly to page 299 inside the digital version of the book provided by the Internet Archive. There are 66 cited and linked books on that article alone.
In the Martin Luther King, Jr. article of Wikipedia, page references can now take you directly to the book.
Readers can see a couple of pages to preview the book and, if they want to read further, they can borrow the digital copy using Controlled Digital Lending in a way that’s analogous to how they borrow physical books from their local library.
“What has been written in books over many centuries is critical to informing a generation of digital learners,” said Brewster Kahle, Digital Librarian of the Internet Archive. “We hope to connect readers with books by weaving books into the fabric of the web itself, starting with Wikipedia.”
You can help accelerate these efforts by sponsoring books or funding the effort. It costs the Internet Archive about $20 to digitize and preserve a physical book in order to bring it to Internet readers. The goal is to bring another 4 million important books online over the next several years. Please donate or contact us to help with this project.
“Together we can achieve Universal Access to All Knowledge,” said Mark Graham, Director of the Internet Archive’s Wayback Machine. “One linked book, paper, web page, news article, music file, video and image at a time.”
The Internet Archive will provide portions of its web archive to the University of Edinburgh to support the School of Informatics’ work building open data and tools for advancing machine translation, especially for low-resource languages. Machine translation is the process of automatically converting text in one language to another.
The ParaCrawl project is mining translated text from the web in 29 languages. With over 1 million translated sentences available for several languages, ParaCrawl is often the largest open collection of translations for each language. The project is a collaboration between the University of Edinburgh, University of Alicante, Prompsit, TAUS, and Omniscien with funding from the EU’s Connecting Europe Facility. Internet Archive data is vastly expanding the data mined by ParaCrawl and therefore the amount of translated sentences collected. Lead by Kenneth Heafield of the University of Edinburgh, the overall project will yield open corpora and open-source tools for machine translation as well as the processing pipeline.
Archived web data from IA’s general web collections will be used in the project. Because translations are particularly scarce for Icelandic, Croatian, Norwegian, and Irish, the IA will also use customized internal language classification tools to prioritize and extract data in these languages from archived websites in its collections.
The partnership expands on IA’s ongoing effort to provide computational research services to large-scale data mining projects focusing on open-source technical developments for furthering the public good and open access to information and data. Other recent collaborations include providing web data for assessing the state of local online news nationwide, analyzing historical corporate industry classifications, and mapping online social communities. As well, IA is expanding its work in making available custom extractions and datasets from its 20+ years of historical web data. For further information on IA’s web and data services, contact webservices at archive dot org.