On Monday the Internet Archive joined thousands of others in submitting comments to the US Copyright Office as part of its study on Copyright and Artificial Intelligence.
Our high level view is that copyright law has been adapting to disruptive technologies since its earliest days and our existing copyright law is adequate to meet the disruptions of today. In particular, copyright’s flexible fair use provision deals well with the fact-specific nature of new technologies, and has already addressed earlier innovations in machine learning and text-and-data mining. So while Generative AI presents a host of policy challenges that may prompt different kinds of legislative reform, we do not see that new copyright laws are needed to respond to Generative AI today.
Our comments are guided by three core principles.
First, regulation of Artificial Intelligence should be considered holistically–not solely through the isolated lens of copyright law. As explained in the Library Copyright Alliance Principles for Artificial Intelligence and Copyright, “AI has the potential to disrupt many professions, not just individual creators. The response to this disruption (e.g., support for worker retraining through institutions such as community colleges and public libraries) should be developed on an economy-wide basis, and copyright law should not be treated as a means for addressing these broader societal challenges.” Going down a typical copyright path of creating new rights and licensing markets could, for AI, serve to worsen social problems like inequality, surveillance and monopolistic behavior of Big Tech and Big Media.
Second, any new copyright regulation of AI should not negatively impact the public’s right and ability to access information, knowledge, and culture. A primary purpose of copyright is to expand access to knowledge. See Authors Guild v. Google, 804 F.3d 202, 212 (2d Cir. 2015) (“Thus, while authors are undoubtedly important intended beneficiaries of copyright, the ultimate, primary intended beneficiary is the public, whose access to knowledge copyright seeks to advance . . . .”). Proposals to amend the Copyright Act to address AI should be evaluated by the impact such new regulations would have on the public’s access to information, knowledge, and culture. In cases where proposals would have the effect of reducing public access, they should be rejected or balanced out with appropriate exceptions and limitations.
Third, universities, libraries, and other publicly-oriented institutions must be able to continue to ensure the public’s access to high quality, verifiable sources of news, scientific research and other information essential to their participation in our democratic society. Strong libraries and educational institutions can help mitigate some of the challenges to our information ecosystem, including those posed by AI. Libraries should be empowered to provide access to educational resources of all sorts– including the powerful Generative AI tools now being developed.
Today, on the Day of the Dead 2023, we at the Internet Archive honor the death of Python 2. Having mostly emerged from one of the greatest software upgrade SNAFU’s in history—the migration from Python 2 to Python 3—we now shed a tear for that old version that served us so well.
When Python 3 was launched in 2008, it contained a number of significant improvements which nevertheless broke compatibility with the previous version of Python at the syntax, string-handling, and library level. As terrible as this sounds, breaking changes are fairly normal for a major software upgrade.
Rather, the chaos that followed was rooted in the fact that unlike most software transitions of this sort, it could not be done incrementally. Instead of being offered a way to gradually upgrade, remaining compatible with both versions and spreading the incremental costs over time, developers were given a risky all-or-nothing choice. The result has been a reluctant, glacial, expensive migration that continues to plague the world.
At the Internet Archive, we did not begin our migration in earnest until 2021, starting with Open Library and then this year focusing on Archive.org and its underlying services. However, we are now happy to declare migration of our core storage service, S3, which underlies all of the millions of items stored in the Archive, complete. We are grateful for the intensive efforts over many months by Chris, Scott, and Tracey, and everyone who supported them!
There are just a few more projects to go, but we are nearly there. And come our next OS upgrade, Python 2 will be but the whisper of a memory, preserved in the Archive and honored on a day like today. Rest in peace, Python 2. And please stay dead.
This is a guest post from Teresa Soleau (Digital Preservation Manager), Anders Pollack (Software Engineer), and Neal Johnson (Senior IT Project Manager) from the J. Paul Getty Trust.
Project Background
Getty pursues its mission in Los Angeles and around the world through the work of its constituent programs—Getty Conservation Institute, Getty Foundation, J. Paul Getty Museum, and Getty Research Institute—serving the general interested public and a wide range of professional communities to promote a vital civil society through an understanding of the visual arts.
In 2019, Getty began a website redesign project, changing the technology stack and updating the way we interact with our communities online. The legacy website contained more than 19,000 web pages and we knew many were no longer useful or relevant and should be retired, possibly after being archived. This led us to leverage the content we’d captured using the Internet Archive’s Archive-It service.
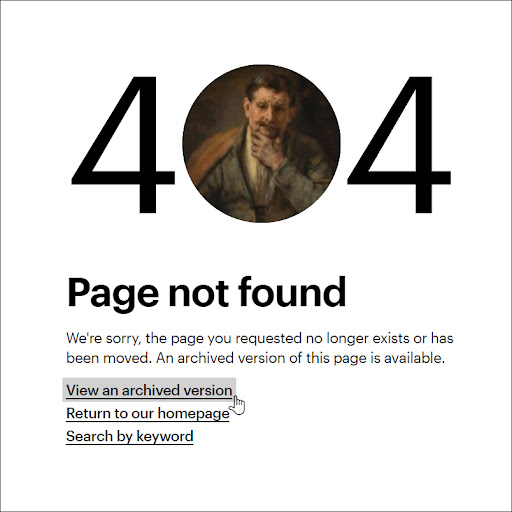
We’d been crawling our site since 2017, but had treated the results more as a record of institutional change over time than as an archival resource to be consulted after deletion of a page. We needed to direct traffic to our Wayback Machine captures thus ensuring deleted pages remain accessible when a user requests a deprecated URL. We decided to dynamically display a link to the archived page from our site’s 404 error “Page not found” page.
Getty.edu 404 error “Page not found” message including the dynamically generated instructions and Internet Archive page link.
The project to audit all existing pages required us to educate content owners across the institution about web archiving practices and purpose. We developed processes for completing human reviews of large amounts of captured content. This work is described in more detail in a 2021 Digital Preservation Coalition blog post that mentions the Web Archives Collecting Policy we developed.
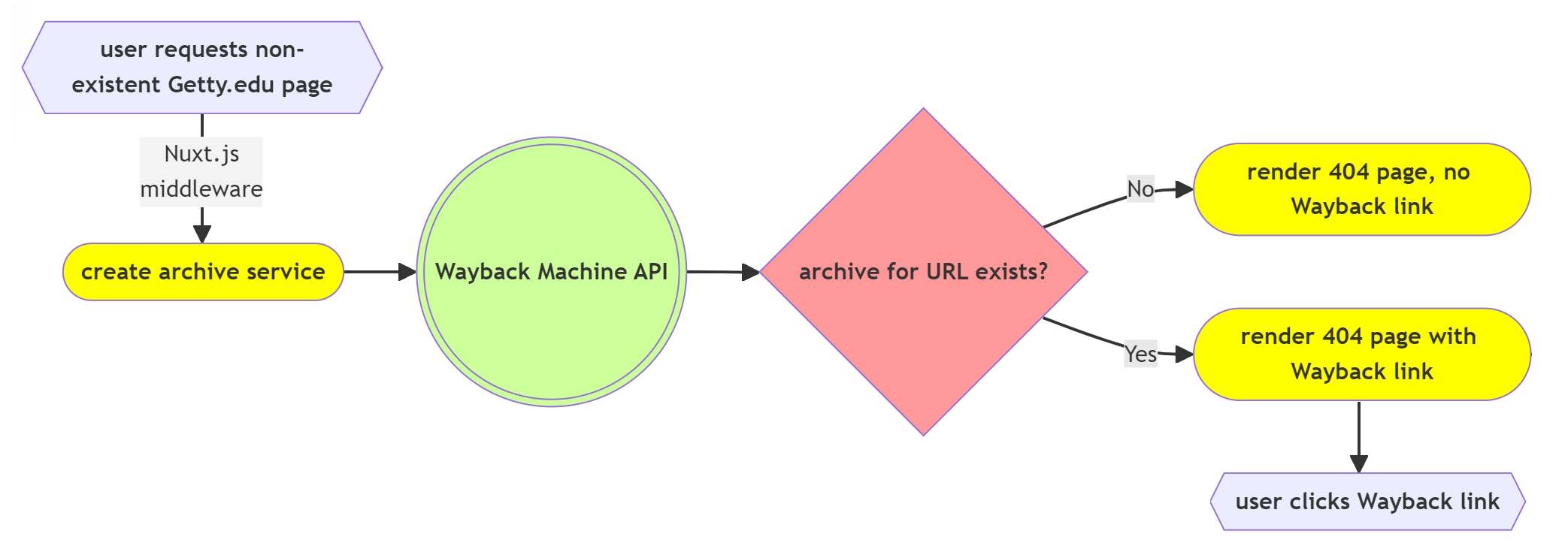
In this blog post we’ll discuss the work required to use the Internet Archive’s data API to add the necessary link on our 404 pages pointing to the most recent Wayback Machine capture of a deleted page.
Technical Underpinnings
Implementation of our Wayback Machine integration was very straightforward from a technical point of view. The first example provided in the Wayback Machine APIs documentation page provided the technical guidance needed for our use case to display a link to the most recent capture of any page deleted from our website. With no requirements for authentication or management of keys or platform-specific software development kit (SDK) dependencies, our development process was simplified. We chose to incorporate the Wayback API using Nuxt.js, the web framework used to build the new Getty.edu site.
Since the Wayback Machine API is highly performant for simple queries, with a typical response delay in milliseconds, we are able to query the API before rendering the page using a Nuxt route middleware module. API error handling and a request timeout were added to ensure that edge cases such as API failures or network timeouts do not block rendering of the 404 response page.
The only Internet Archive API feature missing for our initial list of requirements was access to snapshot page thumbnails in the JSON data payload received from the API. Access to these images would allow us to enhance our 404 page with a visual cue of archived page content.
Results and Next Steps
Our ability to include a link to an archived version of a deleted web page on our 404 response page helped ease the tough decisions content stakeholders were obliged to make about what content to archive and then delete from the website. We could guarantee availability of content in perpetuity without incurring the long term cost of maintaining the information ourselves.
The API brings back the most recent Wayback Machine capture by default which is sometimes not created by us and hasn’t necessarily passed through our archive quality assurance process. We intend to develop our application further so that we privilege the display of Getty’s own page captures. This will ensure we’re delivering the highest quality capture to users.
Google Analytics has been configured to report on traffic to our 404 pages and will track clicks on links pointing to Internet Archive pages, providing useful feedback on what portion of archived page traffic is referred from our 404 error page.
To work around the challenge of providing navigational affordances to legacy content and ensure web page titles of old content remains accessible to search engines, we intend to provide an up-to-date index of all archived getty.edu pages.
As we continue to retire obsolete website pages and complete this monumental content archiving and retirement effort, we’re grateful for the Internet Archive API which supports our goal of making archived content accessible in perpetuity.
This post is co-authored by Lila Bailey (Internet Archive) and Brandon Butler (Software Preservation Network)
Thomas Jefferson Building, Library of Congress, Washington, D.C. by Ron Cogswell. CC-BY 2.0.
The Internet Archive and the Software Preservation Network (SPN) support proposed revisions to the US Copyright Office electronic deposit rules as an important bulwark against vanishing culture.
The Library of Congress (the “Library”) is the world’s most comprehensive record of human creativity and knowledge. Deposits of published works made by creators when they register for copyright protection make up the core of the Library’s national collection, ensuring the long term preservation and public access of our collective cultural heritage. For decades, the number of creative works published in electronic formats has grown exponentially, but the Copyright Office and the Library did not have the policy or technical infrastructure to collect and preserve materials in these formats. Presently, the US Copyright Office is modernizing its systems, rules, and processes to ensure it can fulfill its important role in the copyright system, including providing copies of deposited works for inclusion in the Library’s collections. In the latest rulemaking on electronic deposits, the copyright industry lobby raised concerns about the Office’s proposal to expand the Library’s access to electronically-deposited works; as we explain below, those concerns are unfounded.
Under 37 Code of Federal Regulations § 202.18, the Library may provide limited on-site access to groups of newspapers electronically submitted for registration, as well as electronic serials and books submitted for mandatory deposit. The Copyright Office has proposed expanding the categories of electronic deposits covered by the regulation with the same limitations on access as are currently in place. Specifically, the works may only be accessed under the supervision of Library staff through computer terminals in the Library’s reading rooms. These terminals are not connected to the Internet and the input/output connections (USB, etc.) are disabled. Libraries support expanding on-site access rules to new categories of deposits to ensure that over time, the public can continue to access works in the Library’s collection.
During a public comment period for this proposed rule, groups representing rightsholders surfaced concerns about infringement, and urged the Office to heighten security and protection of electronic deposit copies before instituting its proposed rule. As SPN observes in its reply comments, there is no serious basis for these concerns, as the security measures in place already render electronic materials less accessible and less susceptible to misuse than traditional print formats.
Rightsholder groups also suggest that licenses are necessary when the Copyright Office transfers deposits to the Library, and when the Library provides digital access to works. The Internet Archive notes that a licensing regime is not necessary to permit access to the Library’s collections, explaining that “the Copyright Act has always allowed libraries to preserve and provide access to works in their collection without permission or authorization from rightsholders.” Indeed, “Congress has never required the Library of Congress, or any other library, to pay licensing fees to preserve or lend items in their collections.”
Not only are these security concerns and licensing proposals meritless, they are a distraction from the Library of Congress’ critical role as collector and preserver of our cultural heritage to benefit the public interest. The Software Preservation Network explains that while books, music, software, and other works are increasingly produced digitally and only available through licenses, “the Library of Congress is the only library in the United States with a statutory right to acquire and own copies that may otherwise be available only subject to a license.” If the Library were to abandon its role as “a collector and preserver consigning itself instead to the role of licensee, it could lead to a digital dark age in our national Library.” If the Library were required to license works, SPN cautions, the record of cultural history in the Library’s collection could be subjected to the whims of the marketplace, which has no incentive to preserve cultural works.
For all the reasons above, libraries strongly support adoption of the proposed rule.
Libraries around the world were forced to shut their doors in the spring of 2020 during the start of the COVID-19 pandemic. Temple University Libraries was no exception. While the Philadelphia institution’s physical buildings were closed, librarians got creative about how to remain open to students, faculty and staff.
Olivia Given Castello, social science librarian, Temple University
It was all about getting users connected with digital material. Library staff worked together to develop a simple new service—they added a “Get Help Finding a Digital Copy” button to their library catalog. When searching for resources in the library catalog, users can click on the button to request assistance finding a physical item in digital form, which creates a help ticket for library staff to field.
Within the first week of the button launch in April 2020, there were about 350 requests. Since then, the requests have surpassed 9,000.
“Our popular service helps users get access to resources they need quickly without economic hardship, and without having to travel to campus,” said Olivia Given Castello, a social science librarian and unit head in Temple Libraries’ Learning & Research Services department, who helped create the new service.
Temple relies on a variety of sources for its digital requests—including the Internet Archive. “It’s a valuable resource through which we help Temple library users find digital copies of inaccessible or inconveniently accessible items in our physical collection,” Given Castello said of the Internet Archive’s ebooks available through controlled digital lending (CDL).
Charles Library at Temple University
For a large research university, Temple’s library collections’ budget is modest, and it has been challenging to keep up with the rapidly rising costs of journals and monographs given the static library budget in recent years. Additionally, there are ebooks that the libraries are unable to provide. Commercial publishers want to maximize profits gained from ebook sales to individual students, so unlike with print books, there are many ebook titles they refuse to sell to libraries, or refuse to sell with adequate user licensing. Based on past requests, we estimate that just under 20% of the digital items that Temple finds through its new service is in the Internet Archive collection, said Given Castello.
“Our library serves a diverse user community that is socio-economically disadvantaged relative to those at many other R1 U.S. research universities,” she said. The R1 designation indicates a university that grants doctoral degrees and has very high research activity; the list of 146 institutions so designated include the wealthiest private universities in the U.S. “Our users’ ability to access ebooks through the Internet Archive’s controlled digital lending eases financial strain on them.”
“The actions of commercial publishers have put the academic publishing model at risk, pushing the boundaries in ways that prevent libraries from serving the role in society that they need to” Given Castello said. “We’re trying to cope with that. Services like the one we set up, and controlled digital lending for borrowing ebooks from Internet Archive are important in this challenging landscape”
“We can’t let commercial publishers’ short-term shareholder profits take such precedence that they get in the way of equitable access to information.”
“For any university that has a student body with significant economic challenges, organizations like the Internet Archive are just so important in helping make knowledge and information accessible to everyone, regardless of their economic privilege,” Given Castello said. “Libraries exist, in part, so that getting access to the information you need is not dependent on your personal wealth. Inequity of information access is bad for individuals and for society as a whole.”
If legal action were to diminish or shut down CDL, Given Castello said it would be “detrimental” to the university’s service.
She added: “We can’t let commercial publishers’ short-term shareholder profits take such precedence that they get in the way of equitable access to information. Eventually, that will have a long-term negative impact on knowledge creation, which hurts our society, companies, and the economy as well. Sometimes you have to think of the greater good.”
It’s 10 am and I’ve already been traveling for 20 hours — two planes and a long layover from California on my way to Ubatuba, a town 4-hours northeast of Sao Paulo, Brazil. I feel nervous. I’ve never been to Brazil before but the bus ride is serene. The city buildings give way to lush rainforest along the mountainside. It’s almost silent on the bus, a calm quiet. I take a cue from the locals, close my eyes and try to get some rest. I am on my way to DWeb+Coolab Camp Brazil.
View of buildings at Neos Institute where campers found cover from the elements. Photo by: Bruno Caldas Viannalicensed under CC BY-NC-ND 4.0 Deed
My phone buzzes. It’s Victor (Coolab) and Dana (Colnodo). They pick me up from the station and we’re off to Neos Institute, where we’ll spend the next five days together. Coolab Camp is a continuing experiment in the DWeb movement — weaving together technologists, dreamers, builders, and organizers in a beautiful outdoor setting, providing food and shelter for the week, then letting the sharing, imagination, and community building fly.
Gathering on the first day to talk about the themes of agriculture and ecology.
I arrive early to help set up parts of the camp, which is being hosted by the Neos Institute for Sociobiodiversity. They are a collective that has spent the last six years rebuilding this once dilapidated cultural center. One of Neos’ goals is to protect and conserve this area, the Brazilian Atlantic forest. Only about 10% of this forest remains in the wake of development.
This spirit of conservation overlays with the themes of Camp: agriculture, sustainability, and ecology. Coolab is bringing together farmers and organizers from Latin America with DWeb builders and technologists to discover how we can take care of both our digital and physical landscapes.
My roommate, Bruna, from the Transfeminist Network of Digital Care, shares their work on Pratododia. They use the metaphor of food to explain how we can practice healthier technology habits. For instance, just as we wash our hands before meals, it’s important to check our security and privacy settings online before tasting everything the internet offers us.
Papaya, mango, and watermelon served during our vegetarian meals.
Coolab Camp is more than a conference, it is an experiment in building a pop-up community. We start each day with a general meeting at the Casarão (Big House), where we forge acordos (agreements) about how to take care of the space and each other.
Alexandre from Coletivo Neos goes over the history of the Neos Institute.
Coolab Camp morning meetings are at once relaxed and energizing.
These acordos range from simple things: don’t feed the cats and take off your shoes — to strong expressions of our values: no oppression or discrimination of any kind based on class, race, gender, or sexual orientation. At the beginning of every meeting we reiterate these agreements and ask ourselves: do we still agree, does anything need to be changed, does anything need to be added?
This daily gathering is only possible because the event is small, about 80 people over the five days of Camp. That intimacy means we recognize familiar faces and at least exchange a friendly greeting (Bom dia!). There are no janitors to clean up during the event. We wash our own dishes and clean our own bathrooms.
A community member helps setup the mesh network.
Folks also volunteer to be the “olhos (eyes) ” and “ouvidos (ears)” of the community. The Olhos serve to watch out for any misbehavior. The Ouvidos are there to listen if someone has issues they are uncomfortable bringing up to the group. All of this adds to the building of our community.
Marcela and Tomate crafting posters and zines.
How do we communicate at Camp? First, we test some technological solutions like a Mumble server for multiple audio channels, then having AI do live translation. But in the end, the best solution is human: to have another person by our side.
A lot of the Brazilian campers speak both Portuguese and English, so volunteers translate whispering next to us English-only speakers. It is incredibly humbling to have community members put so much energy into making sure we are included in the conversations and know what is going on.
Creating our session schedule through unconference.
Next comes the fun part, the sessions and workshops! Sessions are organized through an unconference where everyone proposes sessions, determines their interests, and those garnering the most interest place themselves on the schedule. Workshops range from:
Learning programming with Scratch for kids and beginners
Working with a mesh network
ODD.SDK – a local-first framework for app development
An analog map of the camp site and where routers for the mesh network will go.
Campers gather around the firepit to share experiences working in cooperatives.
Luandro Viera from Digital Democracy shares the Earth Defender’s Toolkit.
One of my favorite sessions is with Ana, a Brazilian farmer and social researcher guiding us through a game called Sanctuaries of Attention. It happens on the last day. It is impromptu and they just ask around for people to join after breakfast.
Ana is able to lead the session in Portuguese, Spanish, and English. We spend two hours sharing stories of how our attention changes in different situations and which situations feel safe for us — ”sanctuaries” that we can rest in.
The unconference style suits DWeb+Coolab Camp, because it allows the time and space for sessions like these to happen organically, without constraints.
Ana guides participants through the Sanctuaries of Attention.
Nico teaches programming for beginners using Scratch.
Setting up network equipment for the mesh network on site.
Some sessions are discussions around topics like:
Experiences as a cooperative
How to organize groups using sociocracy
Sharing challenges and workarounds managing a community network
It doesn’t hurt that we can hold some of these discussions at the beach. There are also plenty of casual conversations over meals, on a couch, or lounging in a hammock.
Discussion on the beach about community networks.
One of the things I’ll keep with me from those conversations is a new way of understanding the saying, “The future is already here — it’s just not evenly distributed yet.”
Those of us from luckier circumstances fret about the end of the world. Those from different circumstances have already seen it happen. Their economic systems have collapsed or their environment is suffering through the worst of the climate catastrophe. The end of the world is already here — it’s just not evenly distributed yet.
But an end is just a new beginning. Here in Brazil, we meet in the forest with people who are already rebuilding, regenerating from the ruins. The contributions we make will remain. Regeneration is already here — it’s just not evenly distributed yet.
Creating improvised music with Música de Círculoaround the campfire.
Peixe (Fish) and Ondas (Waves), the spaces where sessions were held.
Farmers, organizers, designers and technologists at DWeb+Coolab Camp Brazil 2023.
We could have been anywhere, but we got the opportunity to be within the songs of the birds, the whispers of the trees, and the laughter of the sea. Within smiles and greetings, warm embraces and supportive shoulders. To all the people who gathered us together: Tania, Hiure, Marcela, Luandro, Victor, Dana, Bruno, Marcus, Colectivo Neos and anyone else I may have forgotten, thank you for showing us how to regenerate culture, environment and technology through community. Obrigado!
All photos by Melissa Rahal licensed under CC BY-NC-ND 4.0 Deedunless otherwise stated.
As Elena Rowan researches the ways that activist archivers gather and make sense of data, she often relies on the Internet Archive. She is a graduate student in sociology at Concordia University in Montreal, Canada, with an interest in the debate around copyright and e-books in public libraries.
Elena Rowan
“I look at why archives and libraries are important to society and culture as a whole,” said Rowan, who uses materials preserved in the Wayback Machine and the lnternet Archive. “Without the Internet Archive, so much of the knowledge and information on the Internet would be lost, and most of my research would be impossible.”
Rowan is in her second year of her master’s program and works as a research assistant at the Data Justice Hub. It is a collaborative research project that pursues data-related skills development for social activists, critical researchers and the general public, and aims to understand how data activists gather and make sense of data.
The Internet Archive has been valuable, she said, in providing information for the project and its podcast, Data Decoded.
For a recent class on sociology theory, Rowan said she’s found it useful to search for work by early researchers such as W.E.B. Du Bois in the Internet Archive’s collection. Her university library has a wealth of materials, but she says there are times when she can only find an older book through the Archive and, being digital, it’s easier to locate.
With an event sponsored by the Milieux Institute, which offers programs at the intersection of fine arts, digital culture, and information technology, Rowan leveraged the Internet Archive in another way. She created a one-hour Curating Nostalgia workshop where participants could explore resources in the digital collection to create their own personal nostalgia archive.
Logging into the Internet Archive, Rowan taught people how to search for historical documents and pop culture items. For example, she found a beloved video game that came in a cereal box from her childhood, as well as an audio walking tour of her neighborhood from a decade earlier before gentrification changed the landscape. Other workshop participants found books they read as kids, Club Penguin memorabilia and a Nancy Drew game.
“For scholarly work and nostalgia researchers, it’s a treasure trove of goodies,” Rowan says of the Internet Archive.
In her personal life, Rowan said she’s enjoyed perusing old magazines and obscure cookbooks. She’s found recipes for ambitious cakes, sewing patterns and vintage designs that give her ideas for how to pull together her eclectic mix of old furniture.
“The colors, writing and patterns of the past offer infinite inspiration for creative hobbies and help cultivate domestic bliss,” she said. “I am grateful to everyone at the Internet Archive for creating, maintaining and continuing to expand and fight for this truly amazing public resource!”
The Internet Archive is pleased to announce, through support from the Filecoin Foundation (FF) and Filecoin Foundation for the Decentralized Web (FFDW), that one petabyte of material has now been uploaded to the Filecoin network. Among the collections uploaded are the “End of Term Crawl” collections. These collections are composed of U.S. government websites which are crawled at the end of presidential administrations, before the ephemeral media may be lost to administrative turnover.
We are so grateful for the support we have received from the Filecoin Foundation (FF) and Filecoin Foundation for the Decentralized Web (FFDW) to make this work possible, and are enthusiastic about continuing this collaboration to ensure the ongoing accessibility of critical information like government materials.
To read more about this milestone, please visit the Filecoin Foundation’s announcement here. About the Filecoin Network: Filecoin is an open-source cloud storage marketplace, protocol, and incentive layer with a mission to store humanity’s most important information.
At this year’s annual celebration in San Francisco, the Internet Archive team showcased its innovative projects and rallied supporters around its mission of “Universal Access to All Knowledge.”
Brewster Kahle, Internet Archive’s founder and digital librarian, welcomes hundreds of guests to the annual celebration on October 12, 2023.
“People need libraries more than ever,” said Brewster Kahle, founder of the Internet Archive, at the October 12 event. “We have a set of forces that are making libraries harder and harder to happen—so we have to do something more about it.”
Efforts to ban books and defund libraries are worrisome trends, Kahle said, but there are hopeful signs and emerging champions.
Watch the full live stream of the celebration
Among the headliners of the program was Connie Chan, Supervisor of San Francisco’s District 1, who was honored with the 2023 Internet Archive Hero Award. In April, she authored and unanimously passed a resolution at the San Francisco Board of Supervisors, backing the Internet Archive and the digital rights of all libraries.
Chan spoke at the event about her experience as a first-generation, low-income immigrant who relied on books in Chinese and English at the public library in Chinatown.
Watch Supervisor Chan’s acceptance speech
“Having free access to information was a critical part of my education—and I know I was not alone,” said Chan, who is a supporter of the Internet Archive’s role as a digital, online library. “The Internet Archive is a hidden gem…It is very critical to humanity, to freedom of information, diversity of information and access to truth…We aren’t just fighting for libraries, we are fighting for our humanity.”
Several users shared testimonials about how resources from the Internet Archive have enabled them to advance their research, fact-check politicians’ claims, and inspire their creative works. Content in the collection is helping improve machine translation of languages. It is preserving international television news coverage and Ukrainian memes on social media during the war with Russia.
Quinn Dombrowski, of the Saving Ukrainian Cultural Heritage Online project, shows off Ukrainian memes preserved by the project.
Technology is changing things—some for the worse, but a lot for the better, said David McRaney, speaking via video to the audience in the auditorium at 300 Funston Ave. “And when [technology] changes things for the better, it’s going to expand the limited capabilities of human beings. It’s going to extend the reach of those capabilities, both in speed and scope,” he said. “It’s about a newfound freedom of mind, and time, and democratizing that freedom so everyone has access to it.”
Open Library developer Drini Cami explained how the Internet Archive is using artificial intelligence to improve access to its collections.
When a book is digitized, it used to be that photographs of pages had to be manually cropped by scanning operators. The Internet Archive recently trained a custom machine learning model to automatically suggest page boundaries—allowing staff to double the rate of process. Also, an open-source machine learning tool converts images into text, making it possible for books to be searchable, and for the collection to be available for bulk research, cross-referencing, text analysis, as well as read aloud to people with print disabilities.
Open Library developer Drini Cami.
“Since 2021, we’ve made 14 million books, documents, microfiche, records—you name it—discoverable and accessible in over 100 languages,” Cami said.
As AI technology advanced this year, Internet Archive engineers piloted a metadata extractor, a tool that automatically pulls key data elements from digitized books. This extra information helps librarians match the digitized book to other cataloged records, beginning to resolve the backlog of books with limited metadata in the Archive’s collection. AI is also being leveraged to assist in writing descriptions of magazines and newspapers—reducing the time from 40 to 10 minutes per item.
“Because of AI, we’ve been able to create new tools to streamline the workflows of our librarians and the data staff, and make our materials easier to discover, and work with patrons and researchers, Cami said. “With new AI capabilities being announced and made available at a breakneck rate, new ideas of projects are constantly being added.”
Jamie Joyce & AI hackathon participants.
A recent Internet Archive hackathon explored the risks and opportunities of AI by using the technology itself to generate content, said Jamie Joyce, project lead with the organization’s Democracy’s Library project. One of the hackathon volunteers created an autonomous research agent to crawl the web and identify claims related to AI. With a prompt-based model, the machine was able to generate nearly 23,000 claims from 500 references. The information could be the basis for creating economic, environmental and other arguments about the use of AI technology. Joyce invited others to get involved in future hackathons as the Internet Archive continues to expand its AI potential.
Peter Wang, CEO and co-founder at Anaconda, said interesting kinds of people and communities have emerged around cultures of sharing. For example, those who participate in the DWeb community are often both humanists and technologists, he said, with an understanding about the importance of reducing barriers to information for the future of humanity. Wang said rather than a scarcity mindset, he embraces an abundant approach to knowledge sharing and applying community values to technology solutions.
Peter Wang, CEO and co-founder at Anaconda.
“With information, knowledge and open-source software, if I make a project, I share it with someone else, they’re more likely to find a bug,” he said. “They might improve the documentation a little bit. They might adapt it for a novel use case that I can then benefit from. Sharing increases value.”
The Internet Archive’s Joy Chesbrough, director of philanthropy, closed the program by expressing appreciation for those who have supported the digital library, especially in these precarious times.
“We are one community tied together by the internet, this connected web of knowledge sharing. We have a commitment to an inclusive and open internet, where there are many winners, and where ethical approaches to genuine AI research are supported,” she said. “The real solution lies in our deep human connection. It inspires the most amazing acts of generosity and humanity.”
***
If you value the Internet Archive and our mission to provide “Universal Access to All Knowledge,” please consider making a donation today.
The Physical Archive in Richmond, California, was buzzing with activity the evening of October 11 as people gathered for a peek at how donations of books, film, and media of all kinds are preserved.
Some guests were long-time fans and others had recently donated or were considering giving their treasured items. Many shared a curiosity about how the Internet Archive operates the digital side of the research library.
“I’m a big believer in libraries—and this is one of the weirdest, coolest libraries,” said Jeremy Guillory of Oakland, California, as he toured the buildings and listened to stories behind the many donations on display.
Brewster Kahle, founder and digital librarian of the Internet Archive, gives a tour of the Physical Archive.
Curated collections from individuals included books from Stevanne “Dr. Toy” Auerbach, a pioneering mass media toy reviewer and early childhood studies author. There was also a set of rare dinosaur books and years of the Laugh Makers, a journal about magic and clowning.
Some large institutions, such as the Claremont School of Theology, donated papyrus fragments from ancient Egypt. Among the eight shipping containers of items from the Graduate Theological Union was a children’s hymnal written in Chinese from 1950.
“We get to explore and make available things that may not be able to be seen otherwise,” said Caslon Kahle, a donation coordinator, speaking to visitors at the event. “It’s important to have this historical record preserved for the public.”
Caslon Kahle gives a tour of the Physical Archive.
As they toured the facility, guests learned about the meticulous steps taken to sort materials (avoiding duplication), scan books (by people, turning one page at a time) and preserve fragile film (in a high-tech lab). Many expressed an appreciation for the vast and eclectic collections.
“I think it’s super awesome—all the knowledge in one place,” said Rachel Katz of Berkeley, California, who uses the Wayback Machine in their work at a nonprofit organization, researching the historic record of health equity, racial justice and environmental issues. “I don’t think I had thought about the political aspect—that when people want power they destroy knowledge, and library preservation is a hedge against that.”
Daniel Toman came to the event after he’d contributed items when his grandfather, a big amateur radio enthusiast, passed away a few years ago. “He had a bunch of equipment, catalogs and books around the house that nobody knew what to do with,” said Toman, who lives in San Francisco. “I told my family about [the Internet Archive] and they were all interested in donating some of his materials.”
Digitization manager Elizabeth MacLeod shows off an image captured from the Internet Archive’s Scribe digitization equipment.
Larry and Ann Byler drove from Sunnyvale, California, to get a first-hand look at the physical archive as they decide what to do with their books, records (78s, LPs, 45s), cassette tapes and home movies that they’ve accumulated over the years.
Ann, 81, said some of their film collection includes black-and-white images of trains that go back to the 1940s. She likes the idea that the Internet Archive could digitize the films at a high resolution.
“I want to get them out of the house—somewhere besides the trash bin,” said Larry, a retired computer programmer, of his wall of media items. “I have this ingrained abhorrence for throwing stuff away.”
At the event, noted film archivist Rick Prelinger provided guests with an inside look at preserving vintage film. “The process is not simple, but it’s achievable when you have resources, and we’re fortunate with the generosity of the Internet Archive that we have resources,” he said.
Kate Dollenmayer demos film digitization and preservation.
Linda Brettlen, an architect from Los Angeles, said she became familiar with the Archive through her daughter, who uses the collection when looking for primary sources in her documentary filmmaking. Brettlen has become a fan herself, particularly, the collection of old postcards of L.A. buildings that no longer exist.
“I love that it’s the best use of the Internet,” she said of the Internet Archive at the event. “This is a positive beacon.”
















 Ana guides participants through the Sanctuaries of Attention.
Ana guides participants through the Sanctuaries of Attention.


















