Last summer, Internet Archive launched ARCH (Archives Research Compute Hub), a research service that supports creation, computational analysis, sharing, and preservation of research datasets from terabytes and even petabytes of data from digital collections – with an initial focus on web archive collections. In line with Internet Archive’s mission to provide “universal access to all knowledge” we aim to make ARCH as universally accessible as possible.
Computational research and education cannot remain solely accessible to the world’s most well-resourced organizations. With philanthropic support, Internet Archive is initiating Advancing Inclusive Computational Research with ARCH, a pilot program specifically designed to support an initial cohort of five less well-resourced organizations throughout the world.
Opportunity
Organizational access to ARCH for 1 year – supporting research teams, pedagogical efforts, and/or library, archive, and museum worker experimentation.
Access to thousands of curated web archive collections – abundant thematic range with potential to drive multidisciplinary research and education.
Enhanced Internet Archive training and support – expert synchronous and asynchronous support from Internet Archive staff.
Cohort experience – opportunities to share challenges and successes with a supportive group of peers.
Eligibility
Demonstrated need-based rationale for participation in Advancing Inclusive Computational Research with Archives Research Compute Hub: we will take a number of factors into consideration, including but not limited to stated organizational resources relative to peer organizations, ongoing experience contending with historic and contemporary inequities, as well as levels of national development as assessed by the United Nations Least Developed Countries effort and Human Development Index.
Organization type: universities, research institutes, libraries, archives, museums, government offices, non-governmental organizations.
At this year’s annual celebration in San Francisco, the Internet Archive team showcased its innovative projects and rallied supporters around its mission of “Universal Access to All Knowledge.”
Brewster Kahle, Internet Archive’s founder and digital librarian, welcomes hundreds of guests to the annual celebration on October 12, 2023.
“People need libraries more than ever,” said Brewster Kahle, founder of the Internet Archive, at the October 12 event. “We have a set of forces that are making libraries harder and harder to happen—so we have to do something more about it.”
Efforts to ban books and defund libraries are worrisome trends, Kahle said, but there are hopeful signs and emerging champions.
Watch the full live stream of the celebration
Among the headliners of the program was Connie Chan, Supervisor of San Francisco’s District 1, who was honored with the 2023 Internet Archive Hero Award. In April, she authored and unanimously passed a resolution at the San Francisco Board of Supervisors, backing the Internet Archive and the digital rights of all libraries.
Chan spoke at the event about her experience as a first-generation, low-income immigrant who relied on books in Chinese and English at the public library in Chinatown.
Watch Supervisor Chan’s acceptance speech
“Having free access to information was a critical part of my education—and I know I was not alone,” said Chan, who is a supporter of the Internet Archive’s role as a digital, online library. “The Internet Archive is a hidden gem…It is very critical to humanity, to freedom of information, diversity of information and access to truth…We aren’t just fighting for libraries, we are fighting for our humanity.”
Several users shared testimonials about how resources from the Internet Archive have enabled them to advance their research, fact-check politicians’ claims, and inspire their creative works. Content in the collection is helping improve machine translation of languages. It is preserving international television news coverage and Ukrainian memes on social media during the war with Russia.
Quinn Dombrowski, of the Saving Ukrainian Cultural Heritage Online project, shows off Ukrainian memes preserved by the project.
Technology is changing things—some for the worse, but a lot for the better, said David McRaney, speaking via video to the audience in the auditorium at 300 Funston Ave. “And when [technology] changes things for the better, it’s going to expand the limited capabilities of human beings. It’s going to extend the reach of those capabilities, both in speed and scope,” he said. “It’s about a newfound freedom of mind, and time, and democratizing that freedom so everyone has access to it.”
Open Library developer Drini Cami explained how the Internet Archive is using artificial intelligence to improve access to its collections.
When a book is digitized, it used to be that photographs of pages had to be manually cropped by scanning operators. The Internet Archive recently trained a custom machine learning model to automatically suggest page boundaries—allowing staff to double the rate of process. Also, an open-source machine learning tool converts images into text, making it possible for books to be searchable, and for the collection to be available for bulk research, cross-referencing, text analysis, as well as read aloud to people with print disabilities.
Open Library developer Drini Cami.
“Since 2021, we’ve made 14 million books, documents, microfiche, records—you name it—discoverable and accessible in over 100 languages,” Cami said.
As AI technology advanced this year, Internet Archive engineers piloted a metadata extractor, a tool that automatically pulls key data elements from digitized books. This extra information helps librarians match the digitized book to other cataloged records, beginning to resolve the backlog of books with limited metadata in the Archive’s collection. AI is also being leveraged to assist in writing descriptions of magazines and newspapers—reducing the time from 40 to 10 minutes per item.
“Because of AI, we’ve been able to create new tools to streamline the workflows of our librarians and the data staff, and make our materials easier to discover, and work with patrons and researchers, Cami said. “With new AI capabilities being announced and made available at a breakneck rate, new ideas of projects are constantly being added.”
Jamie Joyce & AI hackathon participants.
A recent Internet Archive hackathon explored the risks and opportunities of AI by using the technology itself to generate content, said Jamie Joyce, project lead with the organization’s Democracy’s Library project. One of the hackathon volunteers created an autonomous research agent to crawl the web and identify claims related to AI. With a prompt-based model, the machine was able to generate nearly 23,000 claims from 500 references. The information could be the basis for creating economic, environmental and other arguments about the use of AI technology. Joyce invited others to get involved in future hackathons as the Internet Archive continues to expand its AI potential.
Peter Wang, CEO and co-founder at Anaconda, said interesting kinds of people and communities have emerged around cultures of sharing. For example, those who participate in the DWeb community are often both humanists and technologists, he said, with an understanding about the importance of reducing barriers to information for the future of humanity. Wang said rather than a scarcity mindset, he embraces an abundant approach to knowledge sharing and applying community values to technology solutions.
Peter Wang, CEO and co-founder at Anaconda.
“With information, knowledge and open-source software, if I make a project, I share it with someone else, they’re more likely to find a bug,” he said. “They might improve the documentation a little bit. They might adapt it for a novel use case that I can then benefit from. Sharing increases value.”
The Internet Archive’s Joy Chesbrough, director of philanthropy, closed the program by expressing appreciation for those who have supported the digital library, especially in these precarious times.
“We are one community tied together by the internet, this connected web of knowledge sharing. We have a commitment to an inclusive and open internet, where there are many winners, and where ethical approaches to genuine AI research are supported,” she said. “The real solution lies in our deep human connection. It inspires the most amazing acts of generosity and humanity.”
***
If you value the Internet Archive and our mission to provide “Universal Access to All Knowledge,” please consider making a donation today.
We are just one week away from our annual celebration on Thursday, October 12! Party in the streets with us in person or celebrate with us online—however you choose to join in the festivities, be sure to grab your ticket now!
What’s in Store?
📚 Empowering Research: We’ll explore how research libraries like the Internet Archive are considering artificial intelligence in a live presentation, “AI @ IA: Research in the Age of Artificial Intelligence.” Come see how the Internet Archive is using AI to build new capabilities into our library, and how students and scholars all over the world use the Archive’s petabytes of data to inform their own research.
🏆 Internet Archive Hero Award: This year, we’re honored to recognize the incredible Connie Chan, our local District 1 supervisor, with the prestigious Internet Archive Hero Award. Supervisor Chan’s unwavering support for the digital rights of libraries culminated in a unanimously passed resolution at the Board of Supervisors, and we can’t wait to present her with this well-deserved honor live from our majestic Great Room. Join us in applauding her remarkable contributions!
🌮 Food Truck Delights: Arrive early and tantalize your taste buds with an assortment of treats from our gourmet food trucks.
💃 Street Party: After the ceremony, let loose and dance the night away to the tunes of local musicians, Hot Buttered Rum. Get ready to groove and celebrate under the starry San Francisco sky!
Internet Archive’s Annual Celebration Thursday, October 12 from 5pm – 10pm PT; program at 7pm PT 300 Funston Avenue, San Francisco Register now for in-person or online attendance
In August 2022, the UC Berkeley Library and Internet Archive were awarded a grant from the National Endowment for the Humanities (NEH) to study legal and ethical issues in cross-border text and data mining (TDM).
The project, entitled Legal Literacies for Text Data Mining – Cross-Border (“LLTDM-X”), supported research and analysis to address law and policy issues faced by U.S. digital humanities practitioners whose text data mining research and practice intersects with foreign-held or licensed content, or involves international research collaborations.
LLTDM-X is now complete, resulting in the publication of an instructive case study for researchers and white paper. Both resources are explained in greater detail below.
Project Origins
LLTDM-X built upon the previous NEH-sponsored institute, Building Legal Literacies for Text Data Mining. That institute provided training, guidance, and strategies to digital humanities TDM researchers on navigating legal literacies for text data mining (including copyright, contracts, privacy, and ethics) within a U.S. context.
A common challenge highlighted during the institute was the fact that TDM practitioners encounter expanding and increasingly complex cross-border legal problems. These include situations in which: (i) the materials they want to mine are housed in a foreign jurisdiction, or are otherwise subject to foreign database licensing or laws; (ii) the human subjects they are studying or who created the underlying content reside in another country; or, (iii) the colleagues with whom they are collaborating reside abroad, yielding uncertainty about which country’s laws, agreements, and policies apply.
Project Design
LLTDM-X was designed to identify and better understand the cross-border issues that digital humanities TDM practitioners face, with the aim of using these issues to inform prospective research and education. Secondarily, it was hoped that LLTDM-X would also suggest preliminary guidance to include in future educational materials. In early 2023, the project hosted a series of three online round tables with U.S.-based cross-border TDM practitioners and law and ethics experts from six countries.
The round table conversations were structured to illustrate the empirical issues that researchers face, and also for the practitioners to benefit from preliminary advice on legal and ethical challenges. Upon the completion of the round tables, the LLTDM-X project team created a hypothetical case study that (i) reflects the observed cross-border LLTDM issues and (ii) contains preliminary analysis to facilitate the development of future instructional materials.
The project team also charged the experts with providing responsive and tailored written feedback to the practitioners about how they might address specific cross-border issues relevant to each of their projects.
Extrapolating from the issues analyzed in the round tables, the practitioners’ statements, and the experts’ written analyses, the Project Team developed a hypothetical case study reflective of “typical” cross-border LLTDM issues that U.S.-based practitioners encounter. The case study provides basic guidance to support U.S. researchers in navigating cross-border TDM issues, while also highlighting questions that would benefit from further research.
The case study examines cross-border copyright, contracts, and privacy & ethics variables across two distinct paradigms: first, a situation where U.S.-based researchers perform all TDM acts in the U.S., and second, a situation where U.S.-based researchers engage with collaborators abroad, or otherwise perform TDM acts in both U.S. and abroad.
The LLTDM-X white paper provides a comprehensive description of the project, including origins and goals, contributors, activities, and outcomes. Of particular note are several project takeaways and recommendations, which the project team hopes will help inform future research and action to support cross-border text data mining. Project takeaways touched on seven key themes:
Uncertainty about cross-border LLTDM issues indeed hinders U.S. TDM researchers, confirming the need for education about cross-border legal issues;
The expansion of education regarding U.S. LLTDM literacies remains essential, and should continue in parallel to cross-border education;
Disparities in national copyright, contracts, and privacy laws may incentivize TDM researcher “forum shopping” and exacerbate research bias;
License agreements (and the concept of “contractual override”) often dominate the overall analysis of cross-border TDM permissibility;
Emerging lawsuits about generative artificial intelligence may impact future understanding of fair use and other research exceptions;
Research is needed into issues of foreign jurisdiction, likelihood of lawsuits in foreign countries, and likelihood of enforcement of foreign judgments in the U.S. However, the overall “risk” of proceeding with cross-border TDM research may remain difficult to quantify; and
Institutional review boards (IRBs) have an opportunity to explore a new role or build partnerships to support researchers engaged in cross-border TDM.
Gratitude & Next Steps
Thank you to the practitioners, experts, project team, and generous funding of the National Endowment for the Humanities for making this project a success.
We aim to broadly share our project outputs to continue helping U.S.-based TDM researchers navigate cross-border LLTDM hurdles. We will continue to speak publicly to educate researchers and the TDM community regarding project takeaways, and to advocate for legal and ethical experts to undertake the essential research questions and begin developing much-needed educational materials. And, we will continue to encourage the integration of LLTDM literacies into digital humanities curricula, to facilitate both domestic and cross-border TDM research.
Guest Post by Daniel Van Strien, Machine Learning Librarian, Hugging Face
Machine learning has many potential applications for working with GLAM (galleries, libraries, archives, museums) collections, though it is not always clear how to get started. This post outlines some of the possible ways in which open source machine learning tools from the Hugging Face ecosystem can be used to explore web archive collections made available via the Internet Archive’s ARCH (Archives Research Compute Hub). ARCH aims to make computational work with web archives more accessible by streamlining web archive data access, visualization, analysis, and sharing. Hugging Face is focused on the democratization of good machine learning. A key component of this is not only making models available but also doing extensive work around the ethical use of machine learning.
Below, I work with the Collaborative Art Archive (CARTA) collection focused on artist websites. This post is accompanied by an ARCH Image Dataset Explorer Demo. The goal of this post is to show how using a specific set of open source machine learning models can help you explore a large dataset through image search, image classification, and model training.
Later this year, Internet Archive and Hugging Face will organize a hands-on hackathon focused on using open source machine learning tools with web archives. Please let us know if you are interested in participating by filling out this form.
Choosing machine learning models
The Hugging Face Hub is a central repository which provides access to open source machine learning models, datasets and demos. Currently, the Hugging Face Hub has over 150,000 openly available machine learning models covering a broad range of machine learning tasks.
Rather than relying on a single model that may not be comprehensive enough, we’ll select a series of models that suit our particular needs.
A screenshot of the Hugging Face Hub task navigator presenting a way of filtering machine learning models hosted on the hub by the tasks they intend to solve. Example tasks are Image Classification, Token Classification and Image-to-Text.
Working with image data
ARCH currently provides access to 16 different “research ready” datasets generated from web archive collections. These include but are not limited to datasets containing all extracted text from the web pages in a collection, link graphs (showing how websites link to other websites), and named entities (for example, mentions of people and places). One of the datasets is made available as a CSV file, containing information about the images from webpages in the collection, including when the image was collected, when the live image was last modified, a URL for the image, and a filename.
Screenshot of the ARCH interface showing a preview for a dataset. This preview includes a download link and an “Open in Colab” button.
One of the challenges we face with a collection like this is being able to work at a larger scale to understand what is contained within it – looking through 1000s of images is going to be challenging. We address that challenge by making use of tools that help us better understand a collection at scale.
Building a user interface
Gradio is an open source library supported by Hugging Face that helps create user interfaces that allow other people to interact with various aspects of a machine learning system, including the datasets and models. I used Gradio in combination with Spacesto make an application publicly available within minutes, without having to set up and manage a server or hosting. See the docs for more information on using Spaces. Below, I show examples of using Gradio as an interface for applying machine learning tools to ARCH generated data.
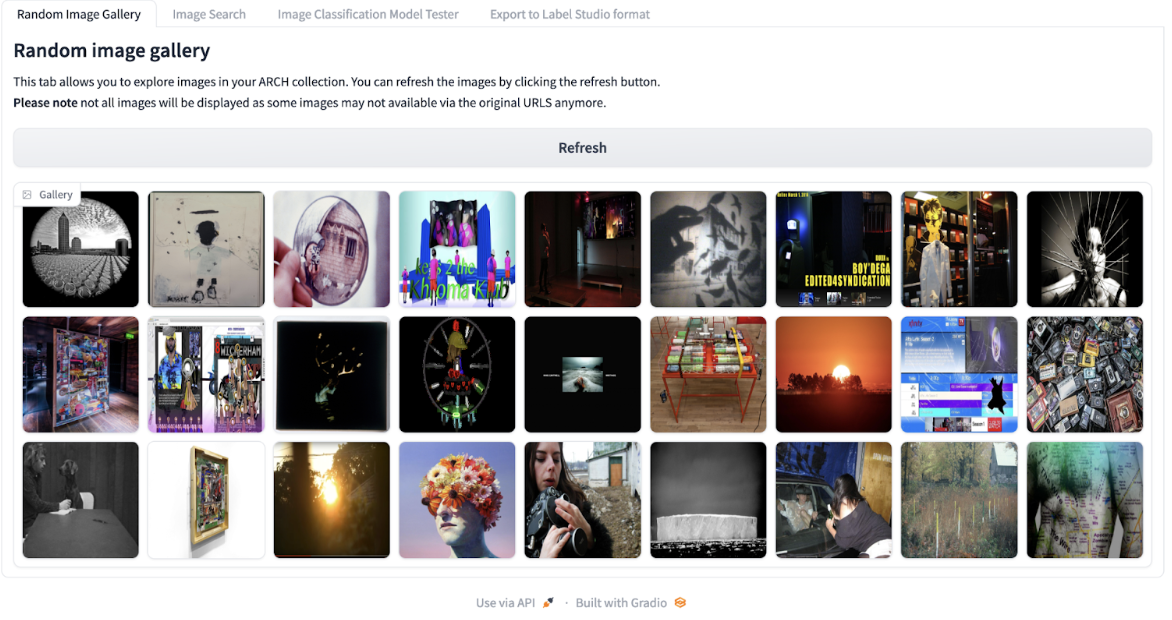
Exploring images
I use the Gradio tab for random images to begin assessing images in the dataset. Looking at a randomized grid of images gives a better idea of what kind of images are in the dataset. This begins to give us a sense of what is represented in the collection (e.g., art, objects, people, etc.).
Screenshot of the random image gallery showing a grid of images from the dataset.
Introducing image search models
Looking at snapshots of the collection gives us a starting point for exploring what kinds of images are included in the collection. We can augment our approach by implementing image search.
There are various approaches we could take which would allow us to search our images. If we have the text surrounding an image, we could use this as a proxy for what the image might contain. For example, we might assume that if the text next to an image contains the words “a picture of my dog snowy”, then the image contains a picture of a dog. This approach has limitations – text might be missing, unrelated or only capture a small part of what is in an image. The text “a picture of my dog snowy” doesn’t tell us what kind of dog the image contains or if other things are included in that photo.
Making use of an embedding model offers another path forward. Embeddings essentially take an input i.e. text or image, and return a bunch of numbers. For example, the text prompt: ‘an image of a dog’, would be passed through an embedding model, which ‘translates’ text into a matrix of numbers (essentially a grid of numbers). What is special about these numbers is that they should capture some semantic information about the input; the embedding for a picture of a dog should somehow capture the fact that there is a dog in the image. Since these embeddings consist of numbers, we can also compare one embedding to another to see how close they are to each other. We expect the embeddings for similar images to be closer to each other and the embeddings for images which are less similar to each other to be farther away. Without getting too much into the weeds of how this works, it’s worth mentioning that these embeddings don’t just represent one aspect of an image, i.e. the main object it contains but also other components, such as its aesthetic style. You can find a longer explanation of how this works in this post.
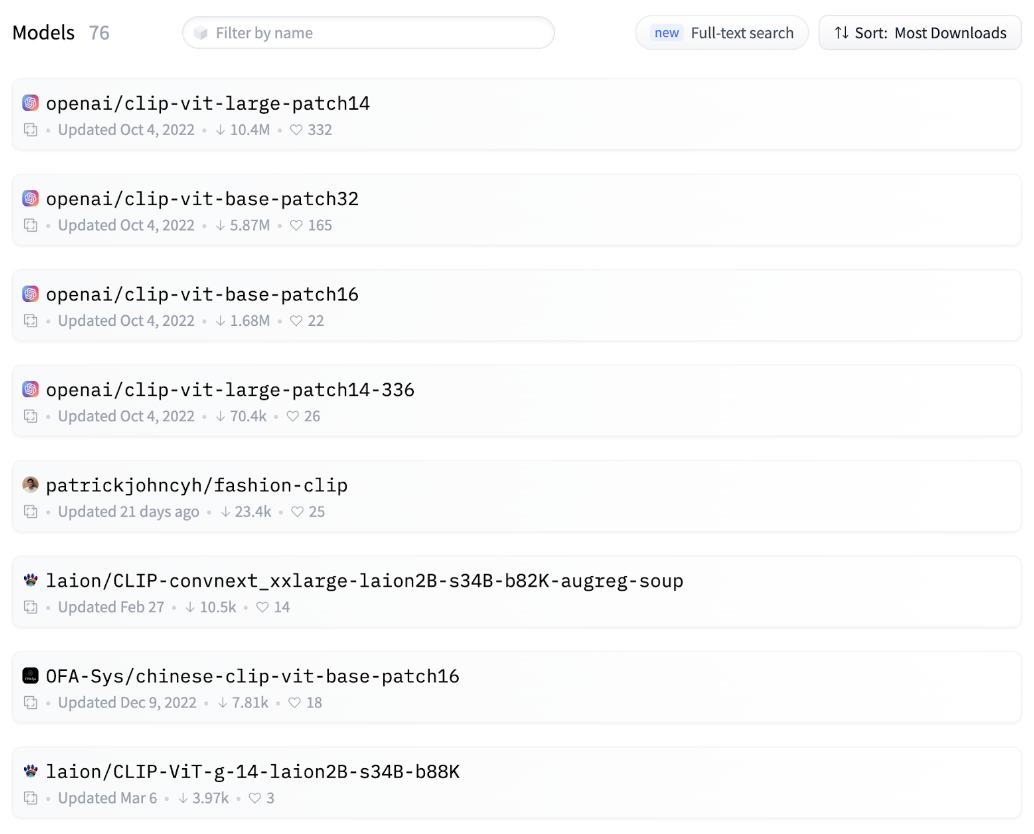
Finding a suitable image search model on the Hugging Face Hub
To create an image search system for the dataset, we need a model to create embeddings. Fortunately, the Hugging Face Hub makes it easy to find models for this.
The Hub has various models that support building an image search system.
Hugging Face Hub showing a list of hosted models.
All models will have various benefits and tradeoffs. For example, some models will be much larger. This can make a model more accurate but also make it harder to run on standard computer hardware.
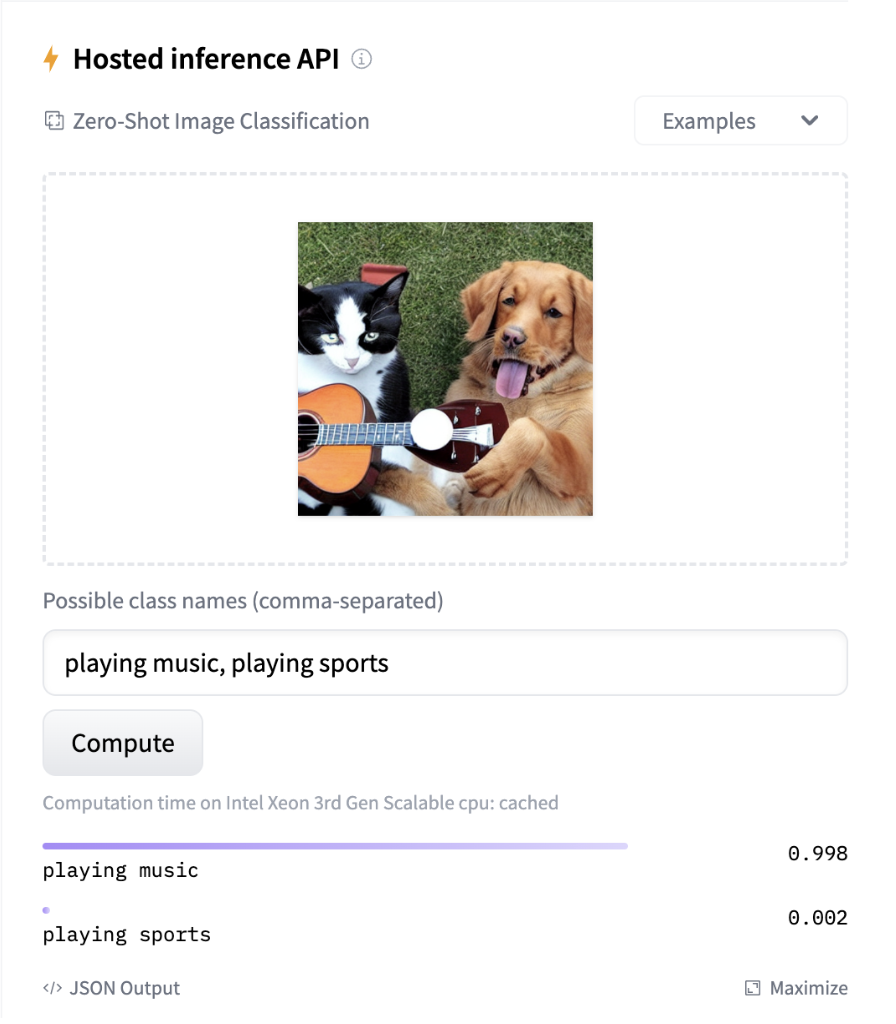
Hugging Face Hub provides an ‘inference widget’, which allows interactive exploration of a model to see what sort of output it provides. This can be very useful for quickly understanding whether a model will be helpful or not.
A screenshot of a model widget showing a picture of a dog and a cat playing the guitar. The widget assigns the label `”playing music`” the highest confidence.
For our use case, we need a model which allows us to embed both our input text, for example, “an image of a dog,” and compare that to embeddings for all the images in our dataset to see which are the closest matches. We use a variant of the CLIP model hosted on Hugging Face Hub: clip-ViT-B-16. This allows us to turn both our text and images into embeddings and return the images which most closely match our text prompt.
Aa screenshot of the search tab showing a search for “landscape photograph” in a text box and a grid of images resulting from the search. This includes two images containing trees and images containing the sky and clouds.
While the search implementation isn’t perfect, it does give us an additional entry point into an extensive collection of data which is difficult to explore manually. It is possible to extend this interface to accommodate an image similarity feature. This could be useful for identifying a particular artist’s work in a broader collection.
Image classification
While image search helps us find images, it doesn’t help us as much if we want to describe all the images in our collection. For this, we’ll need a slightly different type of machine learning task – image classification. An image classification model will put our images into categories drawn from a list of possible labels.
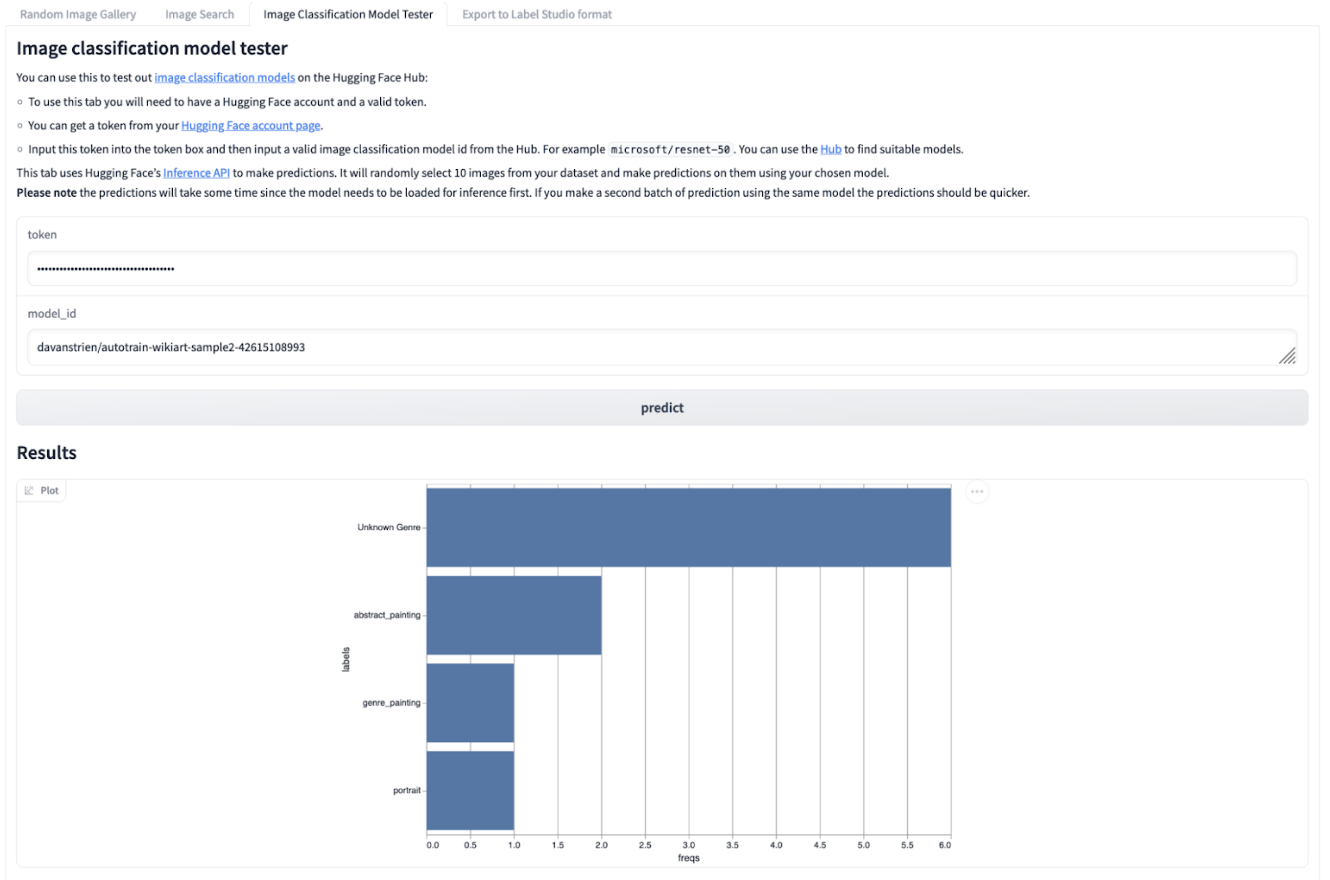
We can find image classification models on the Hugging Face Hub. The “Image Classification Model Tester” tab in the demo Gradio application allows us to test most of the 3,000+ image classification models hosted on the Hub against our dataset.
This can give us a sense of a few different things:
How well do the labels for a model match our data?A model for classifying dog breeds probably won’t help us much!
It gives us a quick way of inspecting possible errors a model might make with our data.
It prompts us to think about what categories might make sense for our images.
A screenshot of the image classification tab in the Gradio app which shows a bar chart with the most frequently predicted labels for images assigned by a computer vision model.
We may find a model that already does a good job working with our dataset – if we don’t, we may have to look at training a model.
Training your own computer vision model
The final tab of our Gradio demo allows you to export the image dataset in a format that can be loaded by Label Studio, an open-source tool for annotating data in preparation for machine learning tasks. In Label Studio, we can define labels we would like to apply to our dataset. For example, we might decide we’re interested in pulling out particular types of images from this collection. We can use Label Studio to create an annotated version of our dataset with these labels. This requires us to assign labels to images in our dataset with the correct labels. Although this process can take some time, it can be a useful way of further exploring a dataset and making sure your labels make sense.
With a labeled dataset, we need some way of training a model. For this, we can use AutoTrain. This tool allows you to train machine learning models without writing any code. Using this approach supports creation of a model trained on our dataset which uses the labels we are interested in. It’s beyond the scope of this post to cover all AutoTrain features, but this post provides a useful overview of how it works.
Next Steps
As mentioned in the introduction, you can explore the ARCH Image Dataset Explorer Demo yourself. If you know a bit of Python, you could also duplicate the Space and adapt or change the current functionality it supports for exploring the dataset.
Internet Archive and Hugging Face plan to organize a hands-on hackathon later this year focused on using open source machine learning tools from the Hugging Face ecosystem to work with web archives. The event will include building interfaces for web archive datasets, collaborative annotation, and training machine learning models. Please let us know if you are interested in participating by filling out this form.
Chatbots, like OpenIA’s ChatGPT, Google’s Bard and others, have a hallucination problem (their term, not ours). It can make something up and state it authoritatively. It is a real problem. But there can be an old-fashioned answer, as a parent might say: “Look it up!”
Imagine for a moment the Internet Archive, working with responsible AI companies and research projects, could automate “Looking it Up” in a vast library to make those services more dependable, reliable, and trustworthy. How?
The Internet Archive and AI companies could offer an anti-hallucination service ‘add-on’ to the chatbots that could cite supporting evidence and counter claims to chatbot assertions by leveraging the library collections at the Internet Archive (most of which were published before generative AI).
By citing evidence for and against assertions based on papers, books, newspapers, magazines, books, TV, radio, government documents, we can build a stronger, more reliable knowledge infrastructure for a generation that turns to their screens for answers. Although many of these generative AI companies are already, or are intending, to link their models to the internet, what the Internet Archive can uniquely offer is our vast collection of “historical internet” content. We have been archiving the web for 27 years, which means we have decades of human-generated knowledge. This might become invaluable in an age when we might see a drastic increase in AI-generated content. So an Internet Archive add-on is not just a matter of leveraging knowledge available on the internet, but also knowledge available on the history of the internet.
Is this possible? We think yes because we are already doing something like this for Wikipedia by hand and with special-purpose robots like Internet Archive Bot Wikipedia communities, and these bots, have fixed over 17 million broken links, and have linked one million assertions to specific pages in over 250,000 books. With the help of the AI companies, we believe we can make this an automated process that could respond to the customized essays their services produce. Much of the same technologies used for the chatbots can be used to mine assertions in the literature and find when, and in what context, those assertions were made.
The result would be a more dependable World Wide Web, one where disinformation and propaganda are easier to challenge, and therefore weaken.
Yes, there are 4 major publishers suing to destroy a significant part of the Internet Archive’s book corpus, but we are appealing this ruling. We believe that one role of a research library like the Internet Archive, is to own collections that can be used in new ways by researchers and the general public to understand their world.
What is required? Common purpose, partners, and money. We see a role for a Public AI Research laboratory that can mine vast collections without rights issues arising. While the collections are significant already, we see collecting, digitizing, and making available the publications of the democracies around the world to expand the corpus greatly.
We see roles for scientists, researchers, humanists, ethicists, engineers, governments, and philanthropists, working together to build a better Internet.
If you would like to be involved, please contact Mark Graham at mark@archive.org.
All too often, the formulation of copyright policy in the United States has been dominated by incumbent copyright industries. As Professor Jessica Litman explained in a recent Internet Archive book talk, copyright laws in the 20th century were largely “worked out by the industries that were the beneficiaries of copyright” to favor their economic interests. In these circumstances, Professor Litman has written, the Copyright Office “plays a crucial role in managing the multilateral negotiations and interpreting their results to Congress.” And at various times in history, the Office has had the opportunity to use this role to add balance to the policymaking process.
We at the Internet Archive are always pleased to see the Copyright Office invite a broad range of voices to discussions of copyright policy and to participate in such discussions ourselves. We did just that earlier this month, participating in a session at the United States Copyright Office on Copyright and Artificial Intelligence. This was the first in a series of sessions the Office will be hosting throughout the first half of 2023, as it works through its “initiative to examine the copyright law and policy issues raised by artificial intelligence (AI) technology.”
As we explained at the event, innovative machine learning and artificial intelligence technology is already helping us build our library. For example, our process for digitizing texts–including never-before-digitized government documents–has been significantly improved by the introduction of LSTM technology. And state-of-the-art AI tools have helped us improve our collection of 100 year-old 78 rpm records. Policymakers dazzled by the latest developments in consumer-facing AI should not forget that there are other uses of this general purpose technology–many of them outside the commercial context of traditional copyright industries–which nevertheless serve the purpose of copyright: “to increase and not to impede the harvest of knowledge.”
Traditional copyright policymaking also frequently excludes or overlooks the world of open licensing. But in this new space, many of the tools come from the open source community, and much of the data comes from openly-licensed sources like Wikipedia or Flickr Commons. Industry groups that claim to represent the voice of authors typically do not represent such creators, and their proposed solutions–usually, demands that payment be made to corporate publishers or to collective rights management organizations–often don’t benefit, and are inconsistent with, the thinking of the open world.
Moreover, even aside from openly licensed material, there are vast troves of technically copyrighted but not actively rights-managed content on the open web; these are also used to train AI models. Millions, if not billions, of individuals have contributed to these data sources, and because none of them are required to register their work for copyright to arise, it does not seem possible or sensible to try to identify all of the relevant copyright owners–let alone negotiate with each of them–before development can continue. Recognizing these and a variety of other concerns, the European Union has already codified copyright exceptions which permit the use of copyright-protected material as training data for generative AI models, subject to an opt-out in commercial situations and potential new transparency obligations.
To be sure, there are legitimate concerns over how generative AI could impact creative workers and cause other kinds of harm. But it is important for copyright policymakers to recognize that artificial intelligence technology has the potential to promote the progress of science and the useful arts on a tremendous scale. It is both sensible and lawful as a matter of US copyright law to let the robots read. Let’s make sure that the process described by Professor Litman does not get in the way of building AI tools that work for everyone.
A post in the series about how the Internet Archive is using AI to help build the library.
Freely available Artificial Intelligence tools are now able to extract words sung on 78rpm records. The results may not be full lyrics, but we hope it can help browsing, searching, and researching.
Whisper is an open source tool from OpenAI “that approaches human level robustness and accuracy on English speech recognition.” We were surprised how far it could get with recognizing spoken words on noisy disks and even words being sung.
For instance in As We Parted At The Gate (1915) by Donald Chalmers, Harvey Hindermyer, and E. Austin Keith, the tool found the words:
[…] we parted at the gate, I thought my heart would shrink. Often now I seem to hear her last goodbye. And the stars that tune at night will never die as bright as they did before we parted at the gate. Many years have passed and gone since I went away once more, leaving far behind the girl I love so well. But I wander back once more, and today I pass the door of the cottade well, my sweetheart, here to dwell. All the roads they flew at fair, but the faith is missing there. I hear a voice repeating, you’re to live. And I think of days gone by with a tear so from her eyes. On the evening as we parted at the gate, as we parted at the gate, I thought my heart would shrink. Often now I seem to hear her last goodbye. And the stars that tune at night will never die as bright as they did before we parted at the gate.
All of the extracted texts are now available– we hope it is useful for understanding these early recordings. Bear in mind these are historical materials so may be offensive and also possibly incorrectly transcribed.
How can public interest values shape the future of AI?
With the rise of generative artificial intelligence (AI), there has been increasing interest in how AI can be used in the description, preservation and dissemination of cultural heritage. While AI promises immense benefits, it also raises important ethical considerations.
WATCH SESSION RECORDING:
In this session, leaders from Internet Archive, Creative Commons and Wikimedia Foundation will discuss how public interest values can shape the development and deployment of AI in cultural heritage, including how to ensure that AI reflects diverse perspectives, promotes cultural understanding, and respects ethical principles such as privacy and consent.
Join us for a thought-provoking discussion on the future of AI in cultural heritage, and learn how we can work together to create a more equitable and responsible future.
For every ten minutes that TV cable news shows featured President Donald Trump’s face on the screen this past summer, the four congressional leaders’ visages were presented for one minute, according an analysis of Face-o-Matic downloadable, free data fueled by the Internet Archive’s TV News Archive and made available to the public today.
Face-o-Matic is an experimental service, developed in collaboration with the start-up Matroid, that tracks the faces of selected high level elected officials on major TV cable news channels: CNN, Fox News, MSNBC, and the BBC. First launched as a Slack app in July, the TV News Archive, after receiving feedback from journalists, is now making the underlying data available to the media, researchers, and the public. It will be updated daily here.
Unlike caption-based searches, Face-o-Matic uses facial recognition algorithms to recognize individuals on TV news screens. Face-o-Matic finds images of people when TV news shows use clips of the lawmakers speaking; frequently, however, the lawmakers’ faces also register if their photos or clips are being used to illustrate a story, or they appear as part of a montage as the news anchor talks. Alongside closed caption research, these data provide an additional metric to analyze how TV news cable networks present public officials to their millions of viewers.
Our concentration on public officials and our bipartisan tracking is purposeful; in experimenting with this technology, we strive to respect individual privacy and extract only information for which there is a compelling public interest, such as the role the public sees our elected officials playing through the filter of TV news. The TV News Archive is committed to doing this right by adhering to these Artificial Intelligence principles for ethical research developed by leading artificial intelligence researchers, ethicists, and others at a January 2017 conference organized by the Future of Life Institute. As we go forward with our experiments, we will continue to explore these questions in conversations with experts and the public.
What other faces would you like us to track? For example, should we start by adding the faces of foreign leaders, such as Russia’s Vladimir Putin and South Korea’s Kim Jong-un? Should we add former President Barack Obama and contender Hillary Clinton? Members of the White House staff? Other members of Congress?
Do you have any technical feedback? If so, please let us know what they are by contacting tvnews@archive.org or participating in the GitHub Face-o-Matic page.
Trump dominates, Pelosi gets little face-time
Overall, between July 13 through September 5, analysis of Face-o-Matic data show:
All together, we found 7,930 minutes, or some 132 hours, of face-time for President Donald Trump and the four congressional leaders. Of that amount, Trump dominated with 90 percent of the face-time. Collectively, the four congressional leaders garnered 15 hours of face-time.
House Minority leader Nancy Pelosi, D., Calif., got the least amount of time on the screen: just 1.4 hours over the whole period.
Of the congressional leaders, Senate Majority Leader Mitch McConnell’s face was found most often: 7.6 hours, compared to 3.8 hours for House Speaker Paul Ryan, R., Wis.; 1.7 hours for Senate Minority Leader Chuck Schumer, D., N.Y., and 1.4 hours for Pelosi.
The congressional leaders got bumps in coverage when they were at the center of legislative fights, such as in this clip of McConnell aired by CNN, in which the senator is shown speaking on July 25 about the upcoming health care reform vote. Schumer got coverage on the same date from the network in this clip of him talking about the Russia investigation. Ryan got a huge boost on CNN when the cable network aired his town hall on August 21.
Fox shows most face-time for Pelosi; MSNBC, most Trump and McConnell
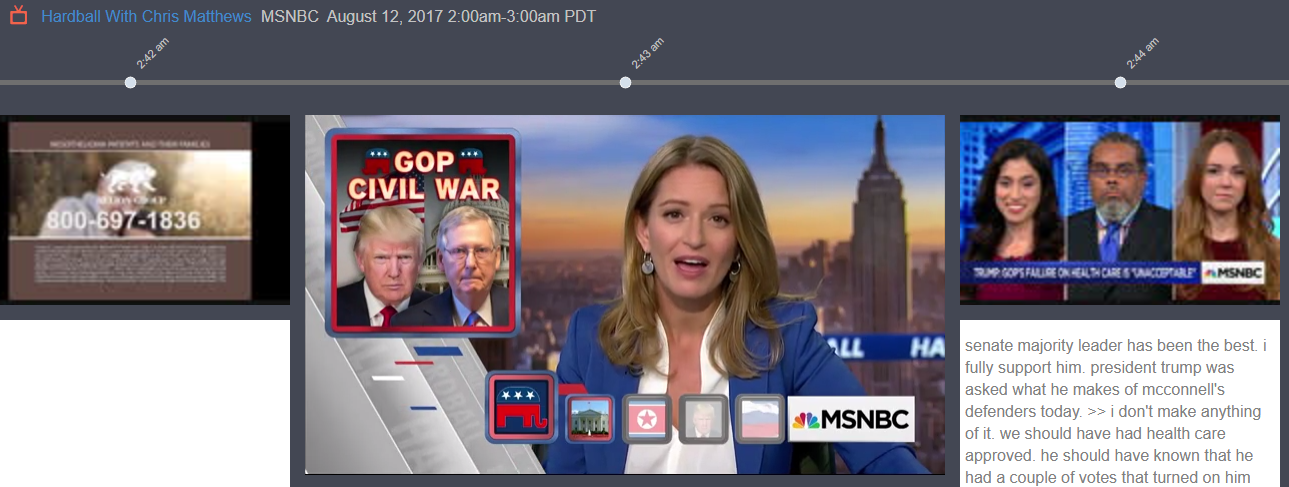
The liberal cable network MSNBC gave Trump more face-time than any other network. Ditto for McConnell. A number of these stories highlight tensions between the senate majority leader and the president. For example, here, on August 25, the network uses a photo of McConnell, and then a clip of both McConnell and Ryan, to illustrate a report on Trump “trying to distance himself” from GOP leaders. In this excerpt, from an August 21 broadcast, a clip of McConnell speaking is shown in the background to illustrate his comments that “most news is not fake,” which is interpreted as “seem[ing] to take a shot at the president.”
MSNBC uses photos of both Trump and McConnell in August 12 story on “feud” between the two.
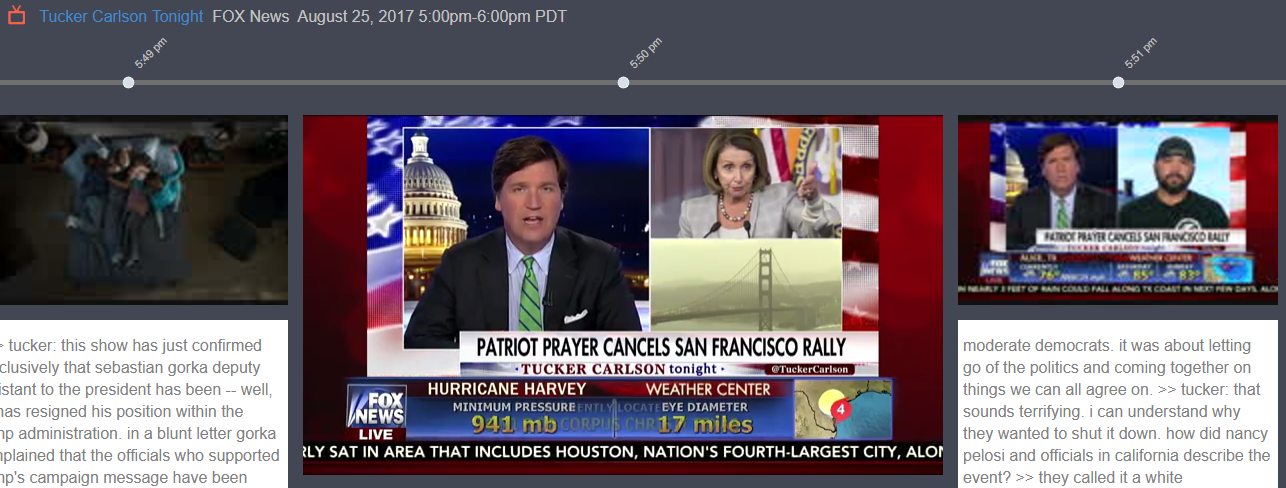
While Pelosi does not get much face-time on any of the cable news networks examined, Fox News shows her face more than any other. In this commentary report on August 20, Jesse Waters criticizes Pelosi for favoring the removal of confederate statues placed in the Capitol building. “Miss Pelosi has been in Congress for 30 years. Now she speaks up?” On August 8, “Special Report With Bret Baier” uses a clip of Pelosi talking in favor of women having a right to choose the size and timing of her family as an “acid test for party base.”
Example of Fox News using a photo of House Minority Leader Nancy Pelosi to illustrate a story, in this case about a canceled San Francisco rally.
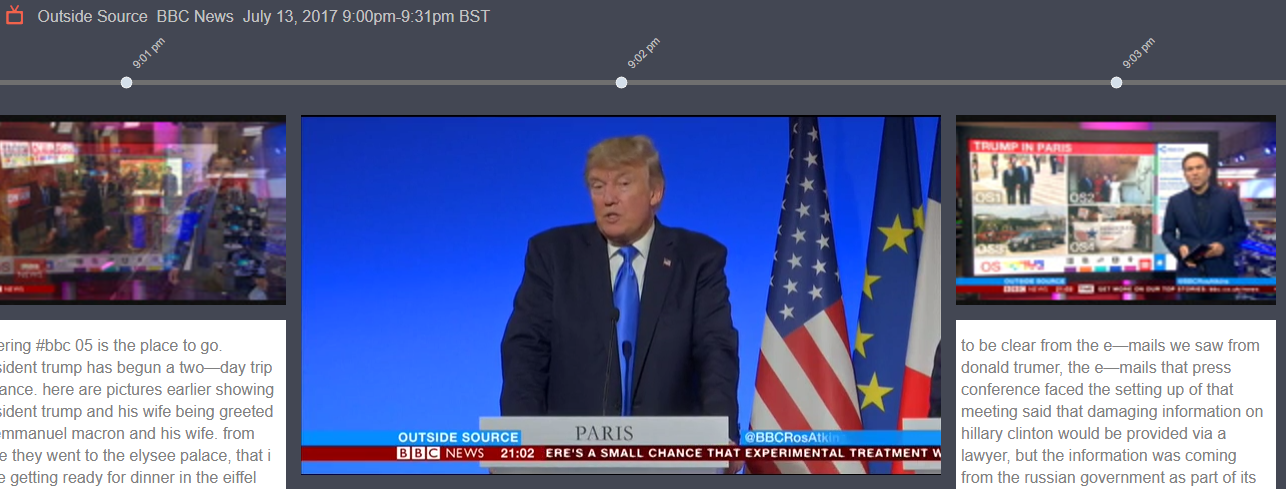
While the BBC gives some Trump face-time, it gives scant attention to the congressional leaders. Proportionately, however, the BBC gives Trump less face-time than any of the U.S. networks.
On July 13 the BBC’s “Outside Source” ran a clip of Trump talking about his son, Donald Trump, Jr.’s, meeting with a Russian lobbyist.
For details about the data available, please visit the Face-O-Matic page. The TV News Archive is an online, searchable, public archive of 1.4 million TV news programs aired from 2009 to the present.This service allows researchers and the public to use television as a citable and sharable reference. Face-O-Matic is part of ongoing experiments in generating metadata for reporters and researchers, enabling analysis of the messages that bombard us daily in public discourse.