In recent days many people have shown interest in making sure the Wayback Machine has copies of the web pages they care about most. These saved pages can be cited, shared, linked to – and they will continue to exist even after the original page changes or is removed from the web.
There are several ways to save pages and whole sites so that they appear in the Wayback Machine. Here are 6 of them.
1. Save Page Now
Put a URL into the form, press the button, and we save the page. You will instantly have a permanent URL for your page.
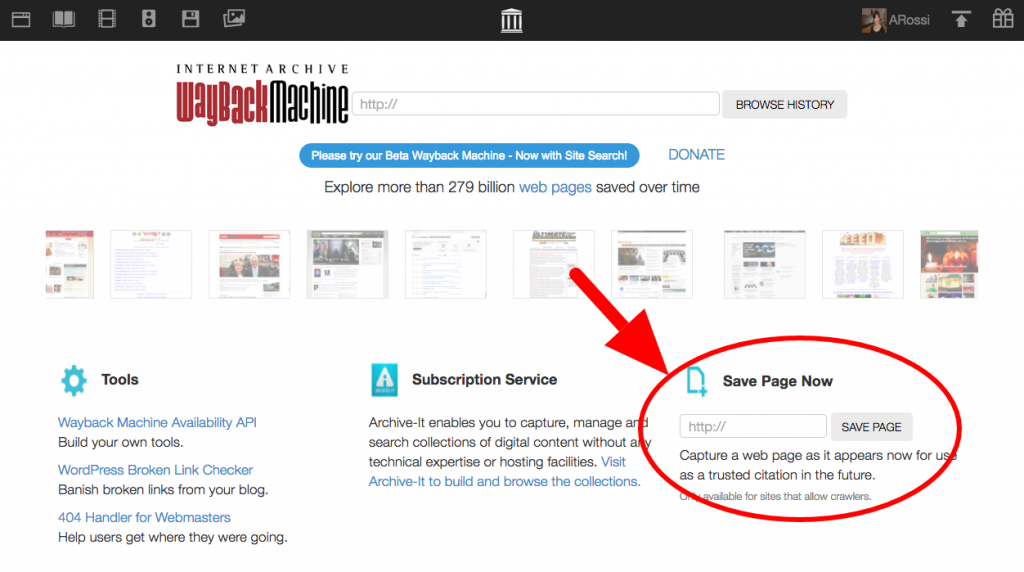
At the moment, there are a few exceptions for this method – some sites prohibit crawling, a few have SSL (security) settings that make it break – but this method will work for most pages. The feature saves the page you enter including the images and CSS. It does not save any of the outlinks, and can’t be used to initiate a crawl of an entire web site. We do not keep your IP address, so your submission is anonymous.
2. Chrome extension
Install the Wayback Machine Chrome extension in your browser. Go to a page you want to archive, click the icon in your toolbar, and select Save Page Now. We will save the page and give you a permanent URL.
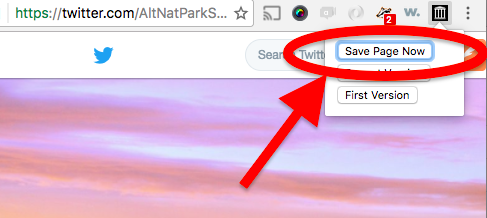
The same provisos from “Save Page Now” apply – there are some pages where it won’t work, and it only saves one page at a time. One plus to installing the extension though is that now as you surf around, when you run into a missing page we will alert you if we have a saved copy.
We also have a “Wayback Machine” Firefox add-on
A “Wayback Machine” Safari Extension
A “Wayback Machine” iOS app
And a “Wayback Machine” Android app
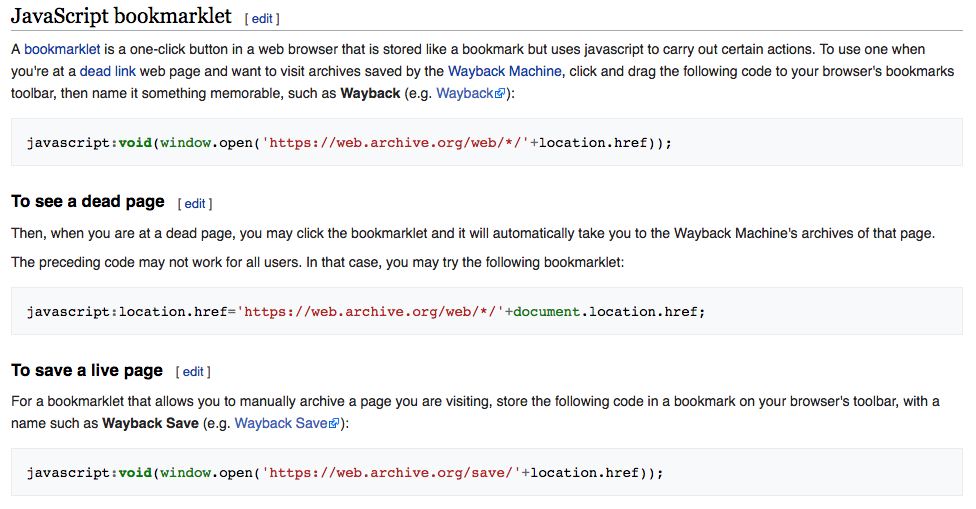
3. Wikipedia JavaScript Bookmarklet
Nobody loves a primary source more than a Wikipedia editor. To that end, they offer a Wayback Machine JavaScript Bookmarklet that allows you to quickly save a web page from any browser.
4. Volunteer for Archive Team
Archive Team is an entirely volunteer driven group who are interested in saving Internet history. Many of the sites and pages they save end up in the Wayback Machine. Visit the Archive Team site to learn more about how to volunteer with them.
5. Sign up for an Archive-It Account
Archive-It is a subscription service provided by Internet Archive that allows you to run your own crawling projects without any technical expertise. Tell us what to crawl and how often to crawl it, and we execute the crawl and put the results in the Wayback Machine.
Archive-It is a paid subscription service with technical and web archivist support. This option is most appropriate for organizations that have a mandate to save certain types or categories of web content on a regular basis. If your institution is a current Archive-It partner, contact them for how you can contribute.
6. End of Term Archive
Every time the US government administration changes, Internet Archive works with partners to make a copy of government-related sites and web presences. We call it the End of Term Archive. You can help us discover new government sites by using the Nomination Tool to suggest pages or sites. These nominations are added to the crawl and end up in the Wayback Machine.
The Internet Archive has been saving web pages for 20 years. This archive has been built by thousands of people, and we would like you to help. Use one of the methods above to make sure we have the pages you care about.
I use the Wayback Machine JavaScript Bookmarklets on Firefox. I have two bookmarks on my browser, one to save web pages (called WB-S) and other one to retrieve missing pages or old versions of the web (called WB). They are really useful and easy to use. When I find a page with interesting information that I would like to save, I never forget to click on WB-S.
Thank you for the Archive!
Have you guys seen Wakelet.com?
It does pretty much this but is very advanced. I’ve built huge science archives on here, together with other volunteers our section has tens of thousands of links alone. I have some collections on politics as well: https://wakelet.com/@UCP
Unfortunately, many data-rich web pages are built dynamically just before they are served.
I’m afraid that saving a page without saving the data source may not accomplish much.
Can anyone with expertise (which I do not have) confirm/deny/explain?
You can’t save a database because it is a password and user ID needed to access the database server. You can save the web pages as static HTML files, but you won’t have the database saved with it. You’d need the permission of the administrator to get the database info.
For example, Kuro5hin went down, offered to give the Internet Archive the Scoop software and Database dump to archive it. It never happened as far I as know and Kuro5hin has been down for almost a year now.
How about a 7th way: donate!
Pingback: Weekly Roundup of Web Design and Development News: January 27, 2017
@malkie It is true that many pages you see in your browser are assembled on-the-fly, built from whatever happens to be in the database at that moment.
This is especially true of sites which retrieve changing data. For a simple example, think of your favorite weather forecasting site or a major news site. If you visit it several times in a day you will likely see different values presented for current local temperature, or different headline news.
If you wanted to take a snapshot of all the changes of this kind of site you would have to set the frequency to a fairly short duration. In these cases it would probably be better to archive the source database itself on a less frequent basis (perhaps daily or several times a day), as the data from each automated temperature probe or each news story is typically stored as separate entries.
Many other sites depend on databases as well (for instance, any websites run on ‘content management systems’ [CMSs] such as WordPress, Joomla, or Drupal), but a good number of them don’t update as often as a news or weather site and frequency of archiving can be tuned to match the frequency of their updates.
Pingback: Archiving Information in a Digital Age – ProfHacker - Blogs - The Chronicle of Higher Education
Pingback: This week’s crème de la crème — January 28, 2017 | Genealogy à la carte
You forgot the Firefox extension! https://addons.mozilla.org/pt-BR/firefox/addon/archive-webextension/
Pingback: If You See Something, Save Something – 6 Ways to Save Pages In the Wayback Machine | Internet Archive Blogs - Blastar Global Technical News
Pingback: On-Demand WayBack URLs | Adrian Roselli
Thanks for the handy buttons!
Now, about archive.org’s back-up policy…
Are you still running a parallel server in Alexandria? (Was that ever really a good idea?)
How resilient will archive.org be in the event of… events?