Partners on the NEH supported, Increasing Access to Diverse Public Library Local History Collections
Since 2017, Community Webs has partnered with public libraries and heritage organizations to document and diversify the historical record. These organizations have collectively archived over 100 terabytes of web-based community heritage materials, including more than 800 collections documenting the lives of those often underrepresented in history. In 2023, Community Webs began offering collection digitization and access with support from the National Historical Publications and Records Commission (NHPRC). Today, Community Webs is happy to announce $345,000 in additional support from the National Endowment for the Humanities to digitize and provide open access to more than 411,000 local history collection items from seven Community Webs partners: Athens-Clarke County Library, Belen Public Library, District of Columbia Public Library, Evanston History Center, Jersey City Free Public Library, San Francisco Public Library, and William B. Harlan Memorial Library.
Community Webs partner collections include a diverse range of content from across the country representing the life of immigrants, Black, and minority communities throughout US history. This includes records created by and for them, such as the Julius Hobson Papers from District of Columbia Public Library, the Belen Harvey House Collection from Belen Public Library, and the Local and Regional Family Histories collection from the William B. Harlan Memorial Library.
ACE Newsletter, Vol. 1, No. 3, Julius Hobson Papers on Federal Job Discrimination (source)
The collections also contain items that document city and municipal agencies that significantly impact minority communities. Digitization of this material will produce a deeper understanding of how systems of power and legal structures can regulate or even erase minority community histories, especially in regards to housing and economic opportunities. For example, the Athens City Engineer Records from Athens-Clarke County Library, the African American Housing and History collection from Evanston History Center, and the San Francisco Redevelopment Agency Records from San Francisco Public Library show the impact of urban redevelopment on Black and minority neighborhoods. The Municipal Records and agency scrapbooks from Jersey City Free Public Library show the ways that politics and economic changes impacted immigrant and minority communities.
Ashley Shull, Collections Coordinator, Athens-Clarke County Library shares what this project means to the community:
“The opportunity to be involved in a project proposal like this with the Internet Archive and our other library partners is invaluable to our community. The increased access to our Athens City Engineer collection will provide, not only local citizens, but academic researchers from around the world as well as current Athens-Clarke County Government officials insight into the past planning activities of our community. This is especially important as our local government embarks on a new Comprehensive Community Plan.”
John Beekman, Chief Librarian, Jersey City Free Public Library, also emphasized the impact of access to important city records:
“The Jersey City Free Public Library is honored to work with esteemed libraries from across the country on this innovative project spearheaded by the Internet Archive’s Community Webs program. The municipal minutes and records that make up the bulk of our contribution contain a wealth of information, not only on the workings of city government and agencies, but the people whose work is recorded there. Names and activities present in these records that never made the news will now be discoverable through search rather than the needle-in-a-haystack experience of poring over individual volumes of minutes. Making these materials accessible will provide a tool for enriching the record of city life across the 19th and 20th centuries.”
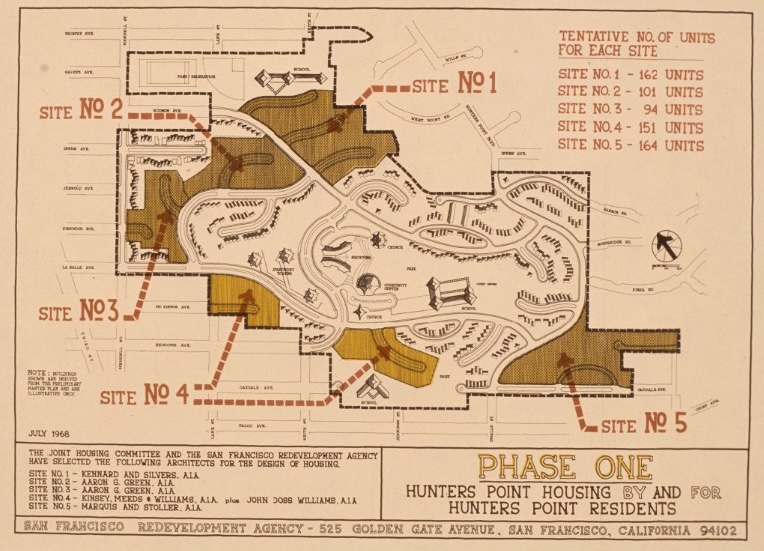
Hunters Point housing phase one map with unit totals, an Francisco Redevelopment Agency Records. Hunters Point Project Area A. Photographs (source)
The Community Webs program’s core goals are to increase the diversity of voices represented in the accessible historical record and to forge authentic partnerships between public libraries and heritage organizations that are members of Community Webs and the communities, individuals, and researchers they serve. Digitizing these collections will expand the overall amount and diversity of locally-focused community archives available online to users, and will augment the web and digital collections that are already aggregated by Community Webs. Records will also be shared with the Digital Public Library of America, further strengthening collection discovery.
Learn more about Community Webs members, projects, and collections on our blog. Get in touch with us at commwebs@archive.org to discover ways to partner to preserve local history!
Started in 2017, our Community Webs program has over 175 public libraries and local cultural organizations working to build digital archives documenting the experiences of their communities, especially those patrons often underrepresented in traditional archives. Participating public libraries have created over 1,400 collections documenting local civic life totaling nearly 100 terabytes and tens of millions of individual documents, images, audio/video files, blogs, websites, social media, and more. You can browse many of these collections at the Community Webs website. Participants have also collaborated on digitization efforts to bring minority newspapers online, held public programming and outreach events, and formed local partnerships to help preservation efforts at other mission-aligned organizations. The program has conducted numerous workshops and national symposia to help public librarians gain expertise in digital preservation and cohort members have done dozens of presentations at professional conferences showcasing their work. In the past, Community Webs has received support from the Institute of Museum and Library Services, the Mellon Foundation, the Kahle Austin Foundation, and the National Historical Publications and Records Commission.
We are excited to announce that Community Webs has received $750,000 in funding from The Mellon Foundation to continue expanding the program. The award will allow additional public libraries to join the program and will enable new and existing members to continue their web archiving collection building using our Archive-It service. In addition, the funding will also provide members access to Internet Archive’s new Vault digital preservation service, enabling them to build and preserve collections of any type of digital materials. Lastly, leveraging members’ prior success in local partnerships, Community Webs will now include an “Affiliates” program so member public libraries can nominate local nonprofit partners that can also receive access to archiving services and resources. Funding will also support the continuation of the program’s professional development training in digital preservation and community archiving and its overall cohort and community building activities of workshops, events, and symposia.
We thank The Andrew W. Mellon Foundation for their generous support of Community Webs. We are excited to continue to expand the program and empower hundreds of public librarians to build archives that document the voices, lives, and events of their communities and to ensure this material is permanently available to patrons, students, scholars, and citizens.
Last summer, Internet Archive launched ARCH (Archives Research Compute Hub), a research service that supports creation, computational analysis, sharing, and preservation of research datasets from terabytes and even petabytes of data from digital collections – with an initial focus on web archive collections. In line with Internet Archive’s mission to provide “universal access to all knowledge” we aim to make ARCH as universally accessible as possible.
Computational research and education cannot remain solely accessible to the world’s most well-resourced organizations. With philanthropic support, Internet Archive is initiating Advancing Inclusive Computational Research with ARCH, a pilot program specifically designed to support an initial cohort of five less well-resourced organizations throughout the world.
Opportunity
Organizational access to ARCH for 1 year – supporting research teams, pedagogical efforts, and/or library, archive, and museum worker experimentation.
Access to thousands of curated web archive collections – abundant thematic range with potential to drive multidisciplinary research and education.
Enhanced Internet Archive training and support – expert synchronous and asynchronous support from Internet Archive staff.
Cohort experience – opportunities to share challenges and successes with a supportive group of peers.
Eligibility
Demonstrated need-based rationale for participation in Advancing Inclusive Computational Research with Archives Research Compute Hub: we will take a number of factors into consideration, including but not limited to stated organizational resources relative to peer organizations, ongoing experience contending with historic and contemporary inequities, as well as levels of national development as assessed by the United Nations Least Developed Countries effort and Human Development Index.
Organization type: universities, research institutes, libraries, archives, museums, government offices, non-governmental organizations.
This is a guest post from Teresa Soleau (Digital Preservation Manager), Anders Pollack (Software Engineer), and Neal Johnson (Senior IT Project Manager) from the J. Paul Getty Trust.
Project Background
Getty pursues its mission in Los Angeles and around the world through the work of its constituent programs—Getty Conservation Institute, Getty Foundation, J. Paul Getty Museum, and Getty Research Institute—serving the general interested public and a wide range of professional communities to promote a vital civil society through an understanding of the visual arts.
In 2019, Getty began a website redesign project, changing the technology stack and updating the way we interact with our communities online. The legacy website contained more than 19,000 web pages and we knew many were no longer useful or relevant and should be retired, possibly after being archived. This led us to leverage the content we’d captured using the Internet Archive’s Archive-It service.
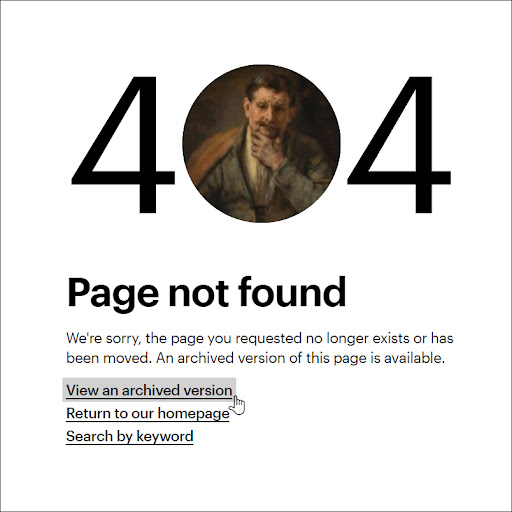
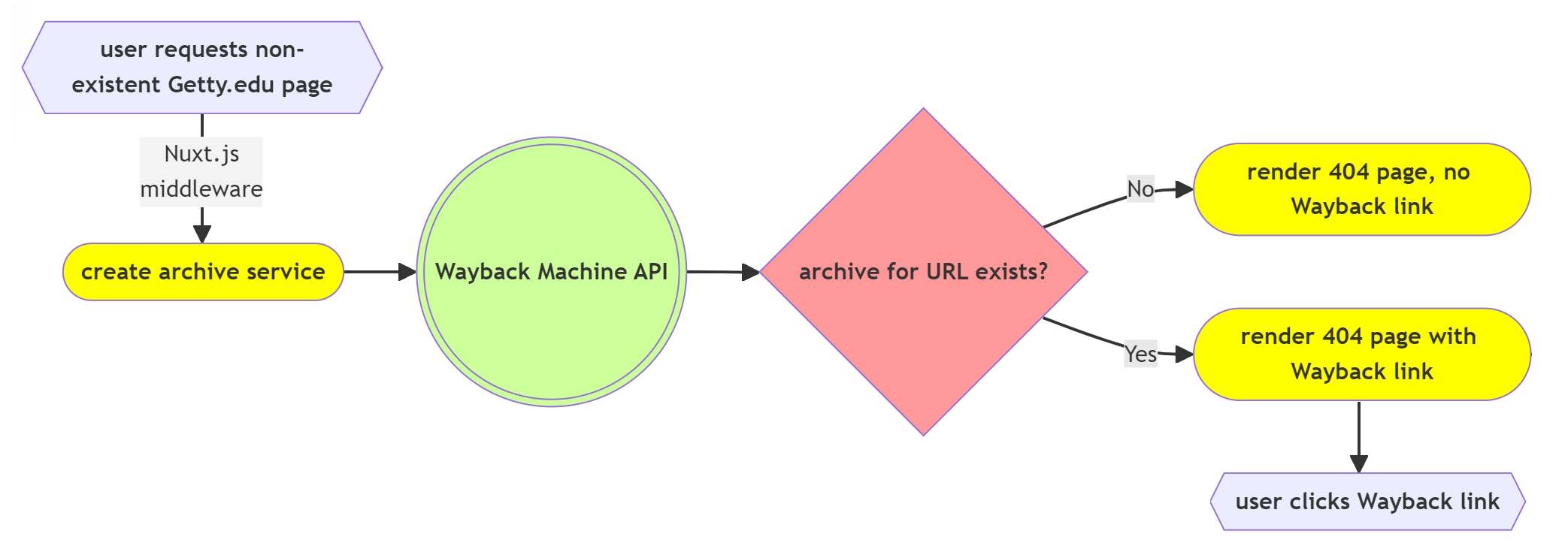
We’d been crawling our site since 2017, but had treated the results more as a record of institutional change over time than as an archival resource to be consulted after deletion of a page. We needed to direct traffic to our Wayback Machine captures thus ensuring deleted pages remain accessible when a user requests a deprecated URL. We decided to dynamically display a link to the archived page from our site’s 404 error “Page not found” page.
Getty.edu 404 error “Page not found” message including the dynamically generated instructions and Internet Archive page link.
The project to audit all existing pages required us to educate content owners across the institution about web archiving practices and purpose. We developed processes for completing human reviews of large amounts of captured content. This work is described in more detail in a 2021 Digital Preservation Coalition blog post that mentions the Web Archives Collecting Policy we developed.
In this blog post we’ll discuss the work required to use the Internet Archive’s data API to add the necessary link on our 404 pages pointing to the most recent Wayback Machine capture of a deleted page.
Technical Underpinnings
Implementation of our Wayback Machine integration was very straightforward from a technical point of view. The first example provided in the Wayback Machine APIs documentation page provided the technical guidance needed for our use case to display a link to the most recent capture of any page deleted from our website. With no requirements for authentication or management of keys or platform-specific software development kit (SDK) dependencies, our development process was simplified. We chose to incorporate the Wayback API using Nuxt.js, the web framework used to build the new Getty.edu site.
Since the Wayback Machine API is highly performant for simple queries, with a typical response delay in milliseconds, we are able to query the API before rendering the page using a Nuxt route middleware module. API error handling and a request timeout were added to ensure that edge cases such as API failures or network timeouts do not block rendering of the 404 response page.
The only Internet Archive API feature missing for our initial list of requirements was access to snapshot page thumbnails in the JSON data payload received from the API. Access to these images would allow us to enhance our 404 page with a visual cue of archived page content.
Results and Next Steps
Our ability to include a link to an archived version of a deleted web page on our 404 response page helped ease the tough decisions content stakeholders were obliged to make about what content to archive and then delete from the website. We could guarantee availability of content in perpetuity without incurring the long term cost of maintaining the information ourselves.
The API brings back the most recent Wayback Machine capture by default which is sometimes not created by us and hasn’t necessarily passed through our archive quality assurance process. We intend to develop our application further so that we privilege the display of Getty’s own page captures. This will ensure we’re delivering the highest quality capture to users.
Google Analytics has been configured to report on traffic to our 404 pages and will track clicks on links pointing to Internet Archive pages, providing useful feedback on what portion of archived page traffic is referred from our 404 error page.
To work around the challenge of providing navigational affordances to legacy content and ensure web page titles of old content remains accessible to search engines, we intend to provide an up-to-date index of all archived getty.edu pages.
As we continue to retire obsolete website pages and complete this monumental content archiving and retirement effort, we’re grateful for the Internet Archive API which supports our goal of making archived content accessible in perpetuity.
In June, we announced the official launch of Archives Research Compute Hub (ARCH) our platform for supporting computational research with digital collections. The Archiving & Data Services group at IA has long provided computational research services via collaborations, dataset services, product features, and other partnerships and software development. In 2020, in partnership with our close collaborators at the Archives Unleashed project, and with funding from the Mellon Foundation, we pursued cooperative technical and community work to make text and data mining services available to any institution building, or researcher using, archival web collections. This led to the release of ARCH, with more than 35 libraries and 60 researchers and curators participating in beta testing and early product pilots. Additional work supported expanding the community of scholars doing computational research using contemporary web collections by providing technical and research support to multi-institutional research teams.
We are pleased to announce that ARCH recently received funding from the Institute of Museum and Library Services (IMLS), via their National Leadership Grants program, supporting ARCH expansion. The project, “Expanding ARCH: Equitable Access to Text and Data Mining Services,” entails two broad areas of work. First, the project will create user-informed workflows and conduct software development that enables a diverse set of partner libraries, archives, and museums to add digital collections of any format (e.g., image collections, text collections) to ARCH for users to study via computational analysis. Working with these partners will help ensure that ARCH can support the needs of organizations of any size that aim to make their digital collections available in new ways. Second, the project will work with librarians and scholars to expand the number and types of data analysis jobs and resulting datasets and data visualizations that can be created using ARCH, including allowing users to build custom research collections that are aggregated from the digital collections of multiple institutions. Expanding the ability for scholars to create aggregated collections and run new data analysis jobs, potentially including artificial intelligence tools, will enable ARCH to significantly increase the type, diversity, scope, and scale of research it supports.
Collaborators on the Expanding ARCH project include a set of institutional partners that will be closely involved in guiding functional requirements, testing designs, and using the newly-built features intended to augment researcher support. Primary institutional partners include University of Denver, University of North Carolina at Chapel Hill, Williams College Museum of Art, and Indianapolis Museum of Art, with additional institutional partners joining in the project’s second year.
Thousands of libraries, archives, museums, and memory organizations work with Internet Archive to build and make openly accessible digitized and born-digital collections. Making these collections available to as many users in as many ways as possible is critical to providing access to knowledge. We are thankful to IMLS for providing the financial support that allows us to expand the ARCH platform to empower new and emerging types of access and research.
We are excited to announce the public availability of ARCH (Archives Research Compute Hub), a new research and education service that helps users easily build, access, and analyze digital collections computationally at scale. ARCH represents a combination of the Internet Archive’s experience supporting computational research for more than a decade by providing large-scale data to researchers and dataset-oriented service integrations like ARS (Archive-it Research Services) and a collaboration with the Archives Unleashed project of the University of Waterloo and York University. Development of ARCH was generously supported by the Mellon Foundation.
ARCH Dashboard
What does ARCH do?
ARCH helps users easily conduct and support computational research with digital collections at scale – e.g., text and data mining, data science, digital scholarship, machine learning, and more. Users can build custom research collections relevant to a wide range of subjects, generate and access research-ready datasets from collections, and analyze those datasets. In line with best practices in reproducibility, ARCH supports open publication and preservation of user-generated datasets. ARCH is currently optimized for working with tens of thousands of web archive collections, covering a broad range of subjects, events, and timeframes, and the platform is actively expanding to include digitized text and image collections. ARCH also works with various portions of the overall Wayback Machine global web archive totaling 50+ PB going back to 1996, representing an extensive archive of contemporary history and communication.
ARCH, In-Browser Visualization
Who is ARCH for?
ARCH is for any user that seeks an accessible approach to working with digital collections computationally at scale. Possible users include but are not limited to researchers exploring disciplinary questions, educators seeking to foster computational methods in the classroom, journalists tracking changes in web-based communication over time, to librarians and archivists seeking to support the development of computational literacies across disciplines. Recent research efforts making use of ARCH include but are not limited to analysis of COVID-19 crisis communications, health misinformation, Latin American women’s rights movements, and post-conflict societies during reconciliation.
ARCH, Generate Datasets
What are core ARCH features?
Build: Leverage ARCH capabilities to build custom research collections that are well scoped for specific research and education purposes.
Access: Generate more than a dozen different research-ready datasets (e.g., full text, images, pdfs, graph data, and more) from digital collections with the click of a button. Download generated datasets directly in-browser or via API.
Analyze: Easily work with research-ready datasets in interactive computational environments and applications like Jupyter Notebooks, Google CoLab, Gephi, and Voyant and produce in-browser visualizations.
Publish and Preserve: Openly publish datasets in line with best practices in reproducible research. All published datasets will be preserved in perpetuity.
Support: Make use of synchronous and asynchronous technical support, online trainings, and extensive help center documentation.
How can I learn more about ARCH?
To learn more about ARCH please reach out via the following form.
Art historians, critics, curators, humanities scholars and many others rely on the records of artists, galleries, museums, and arts organizations to conduct historical research and to understand and contextualize contemporary artistic practice. Yet, much of the art-related materials that were once published in print form are now available primarily or solely on the web and are thus ephemeral by nature. In response to this challenge, more than 40 art libraries spent the last 3 years developing a collective approach to preservation of web-based art materials at scale.
Supported by the Institute of Museum and Library Services and the National Endowment for the Humanities, The Collaborative ART Archive (CARTA) community has successfully aligned effort across libraries large and small, from Manoa, Hawaii to Toronto, Ontario and back resulting in preservation of and access to 800 web-based art resources, organized into 8 collections (art criticism, art fairs and events, art galleries, art history and scholarship, artists websites, arts education, arts organizations, auction houses), totalling nearly 9 TBs of data with continued growth. All collections are preserved in perpetuity by the Internet Archive.
Today, CARTA is excited to launch the CARTA portal – providing unified access to CARTA collections.
🎨 CARTA portal 🎨
The CARTA portal includes web archive collections developed jointly by CARTA members, as well as preexisting art-related collections from CARTA institutions, and non-CARTA member collections. CARTA portal development builds on the Internet Archive’s experience creating the COVID-19 Web Archive and Community Webs portal.
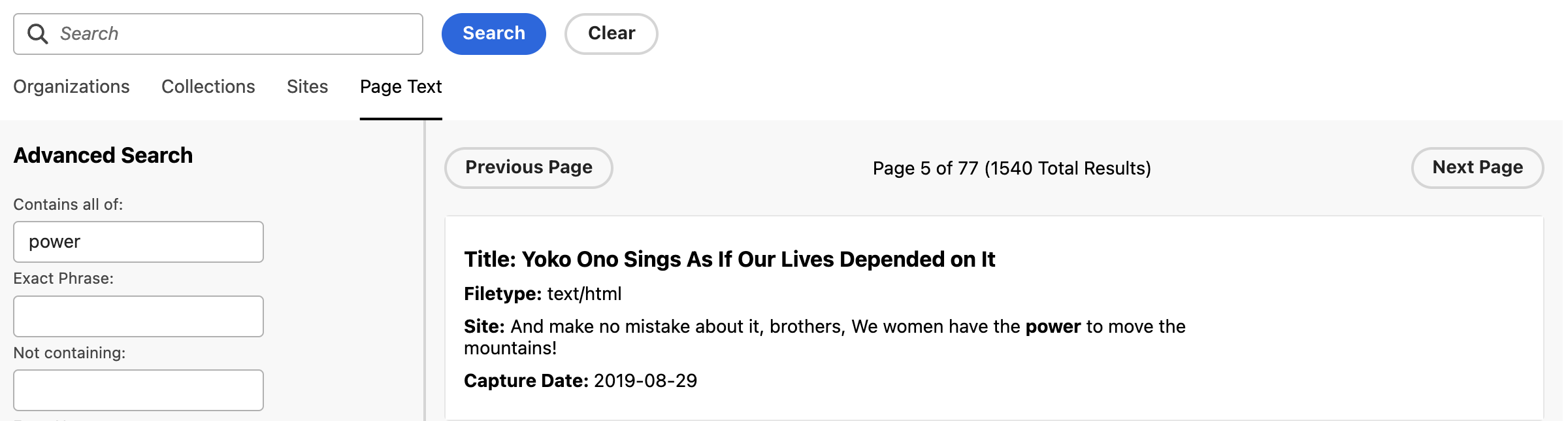
CARTA collections are searchable by contributing organization, collection, site, and page text. Advanced search supports more granular exploration by host, results per host, file types, and beginning and end dates.
🔭 CARTA search 🔭
In addition to the CARTA portal, CARTA has worked to promote research use of collections through a series of day long computational research workshops – Working to Advance Library Support for Web Archive Research – backed by ARCH (Archives Research Compute Hub). A call for applications for the next workshop, held concurrent to the annual Society of American Archivists meeting, is now open.
Moving forward CARTA aims to grow and diversify its membership in order to increase collective ability to preserve web-based art materials. If your art library would like to join CARTA please express interest here..
Guest Post by Daniel Van Strien, Machine Learning Librarian, Hugging Face
Machine learning has many potential applications for working with GLAM (galleries, libraries, archives, museums) collections, though it is not always clear how to get started. This post outlines some of the possible ways in which open source machine learning tools from the Hugging Face ecosystem can be used to explore web archive collections made available via the Internet Archive’s ARCH (Archives Research Compute Hub). ARCH aims to make computational work with web archives more accessible by streamlining web archive data access, visualization, analysis, and sharing. Hugging Face is focused on the democratization of good machine learning. A key component of this is not only making models available but also doing extensive work around the ethical use of machine learning.
Below, I work with the Collaborative Art Archive (CARTA) collection focused on artist websites. This post is accompanied by an ARCH Image Dataset Explorer Demo. The goal of this post is to show how using a specific set of open source machine learning models can help you explore a large dataset through image search, image classification, and model training.
Later this year, Internet Archive and Hugging Face will organize a hands-on hackathon focused on using open source machine learning tools with web archives. Please let us know if you are interested in participating by filling out this form.
Choosing machine learning models
The Hugging Face Hub is a central repository which provides access to open source machine learning models, datasets and demos. Currently, the Hugging Face Hub has over 150,000 openly available machine learning models covering a broad range of machine learning tasks.
Rather than relying on a single model that may not be comprehensive enough, we’ll select a series of models that suit our particular needs.
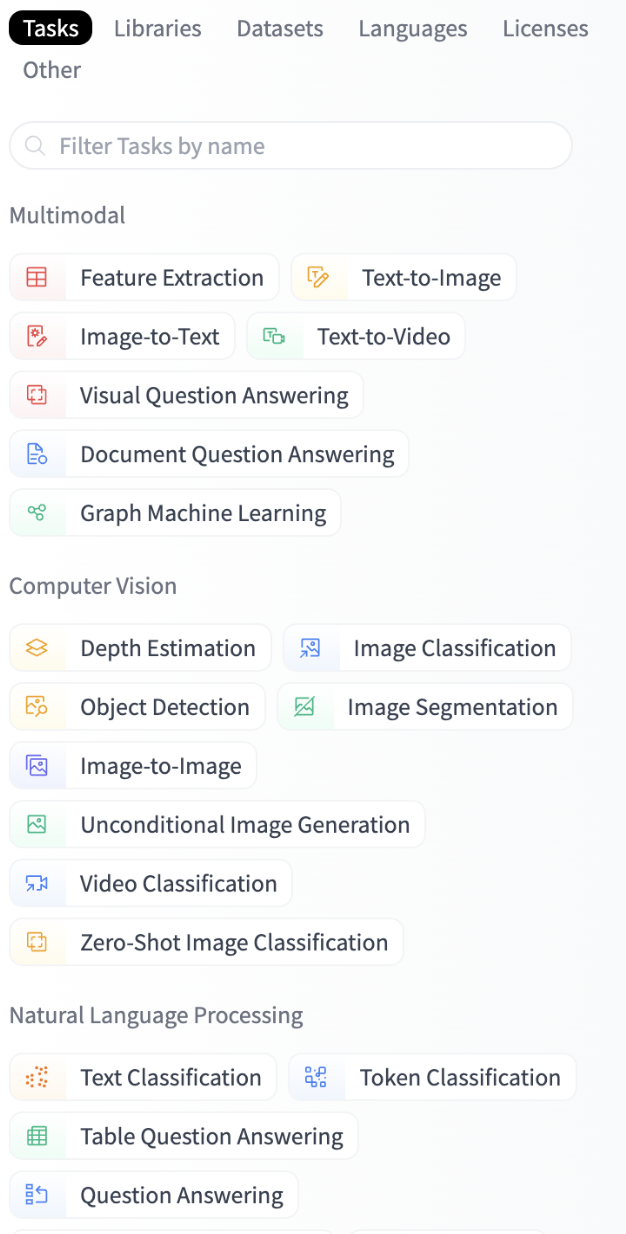
A screenshot of the Hugging Face Hub task navigator presenting a way of filtering machine learning models hosted on the hub by the tasks they intend to solve. Example tasks are Image Classification, Token Classification and Image-to-Text.
Working with image data
ARCH currently provides access to 16 different “research ready” datasets generated from web archive collections. These include but are not limited to datasets containing all extracted text from the web pages in a collection, link graphs (showing how websites link to other websites), and named entities (for example, mentions of people and places). One of the datasets is made available as a CSV file, containing information about the images from webpages in the collection, including when the image was collected, when the live image was last modified, a URL for the image, and a filename.
Screenshot of the ARCH interface showing a preview for a dataset. This preview includes a download link and an “Open in Colab” button.
One of the challenges we face with a collection like this is being able to work at a larger scale to understand what is contained within it – looking through 1000s of images is going to be challenging. We address that challenge by making use of tools that help us better understand a collection at scale.
Building a user interface
Gradio is an open source library supported by Hugging Face that helps create user interfaces that allow other people to interact with various aspects of a machine learning system, including the datasets and models. I used Gradio in combination with Spacesto make an application publicly available within minutes, without having to set up and manage a server or hosting. See the docs for more information on using Spaces. Below, I show examples of using Gradio as an interface for applying machine learning tools to ARCH generated data.
Exploring images
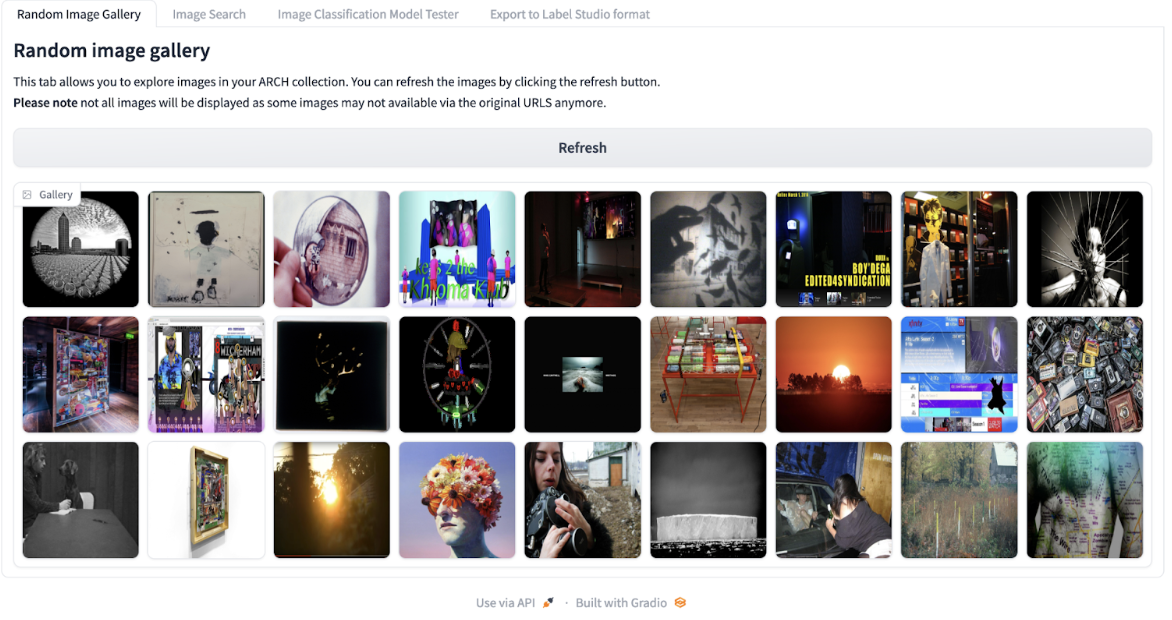
I use the Gradio tab for random images to begin assessing images in the dataset. Looking at a randomized grid of images gives a better idea of what kind of images are in the dataset. This begins to give us a sense of what is represented in the collection (e.g., art, objects, people, etc.).
Screenshot of the random image gallery showing a grid of images from the dataset.
Introducing image search models
Looking at snapshots of the collection gives us a starting point for exploring what kinds of images are included in the collection. We can augment our approach by implementing image search.
There are various approaches we could take which would allow us to search our images. If we have the text surrounding an image, we could use this as a proxy for what the image might contain. For example, we might assume that if the text next to an image contains the words “a picture of my dog snowy”, then the image contains a picture of a dog. This approach has limitations – text might be missing, unrelated or only capture a small part of what is in an image. The text “a picture of my dog snowy” doesn’t tell us what kind of dog the image contains or if other things are included in that photo.
Making use of an embedding model offers another path forward. Embeddings essentially take an input i.e. text or image, and return a bunch of numbers. For example, the text prompt: ‘an image of a dog’, would be passed through an embedding model, which ‘translates’ text into a matrix of numbers (essentially a grid of numbers). What is special about these numbers is that they should capture some semantic information about the input; the embedding for a picture of a dog should somehow capture the fact that there is a dog in the image. Since these embeddings consist of numbers, we can also compare one embedding to another to see how close they are to each other. We expect the embeddings for similar images to be closer to each other and the embeddings for images which are less similar to each other to be farther away. Without getting too much into the weeds of how this works, it’s worth mentioning that these embeddings don’t just represent one aspect of an image, i.e. the main object it contains but also other components, such as its aesthetic style. You can find a longer explanation of how this works in this post.
Finding a suitable image search model on the Hugging Face Hub
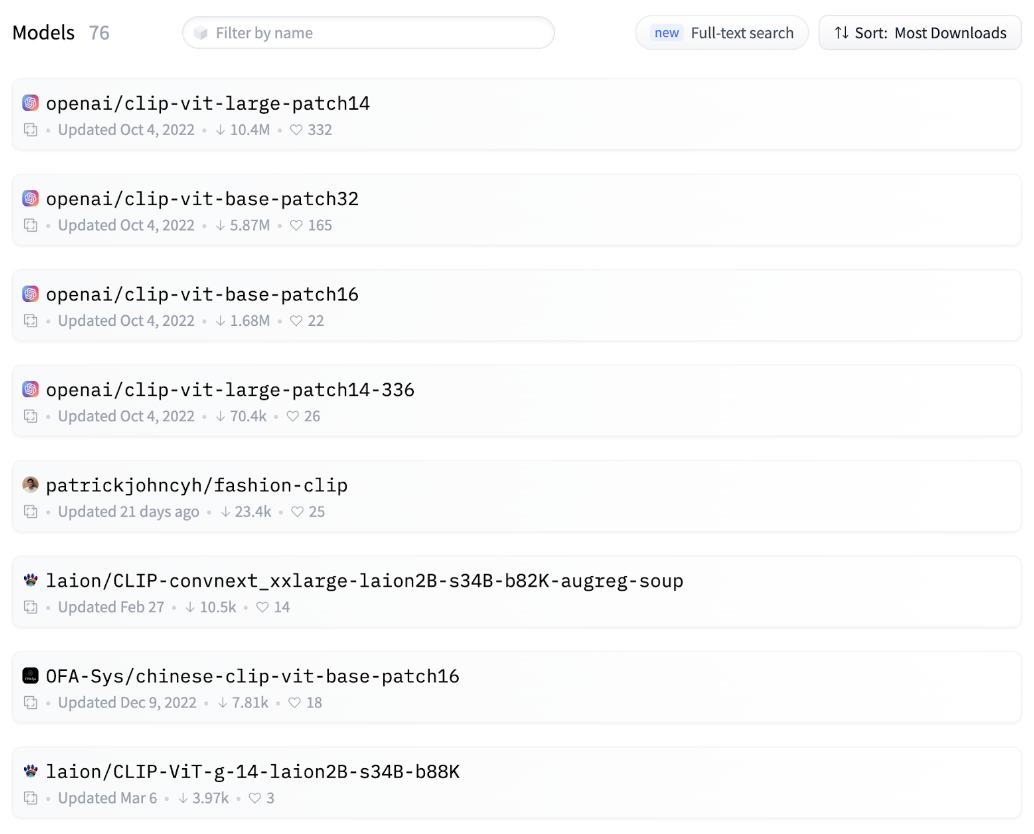
To create an image search system for the dataset, we need a model to create embeddings. Fortunately, the Hugging Face Hub makes it easy to find models for this.
The Hub has various models that support building an image search system.
Hugging Face Hub showing a list of hosted models.
All models will have various benefits and tradeoffs. For example, some models will be much larger. This can make a model more accurate but also make it harder to run on standard computer hardware.
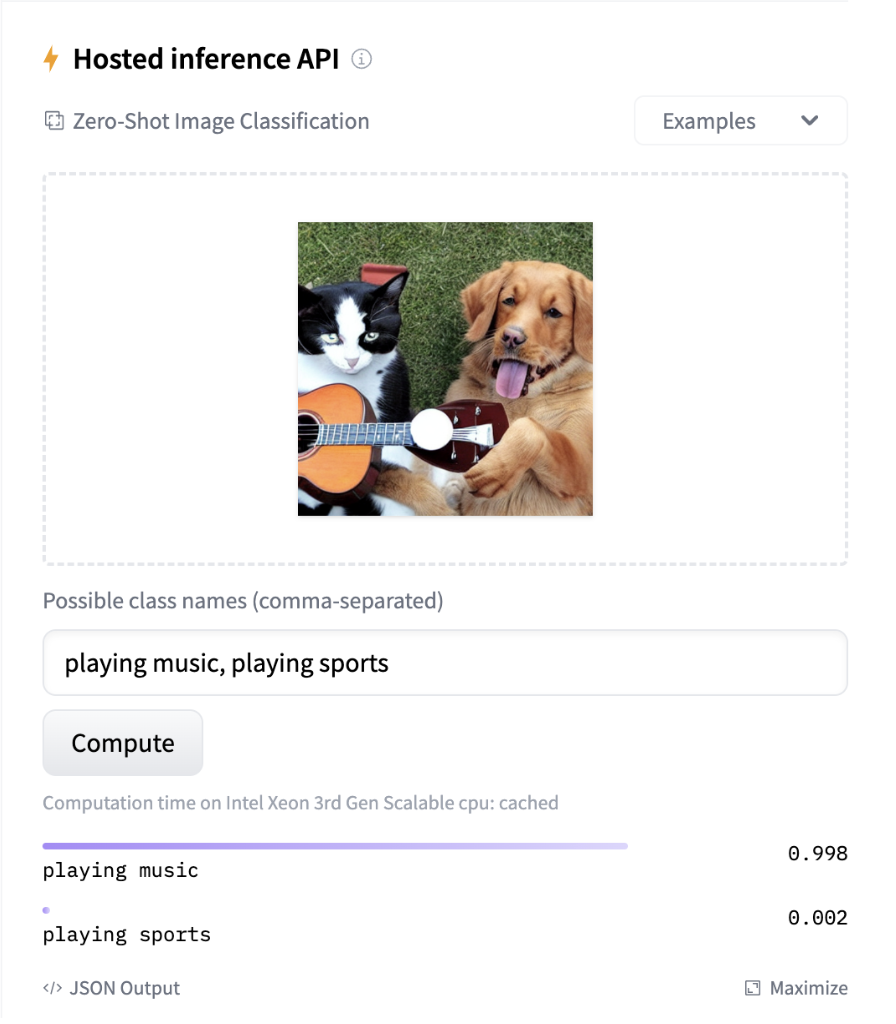
Hugging Face Hub provides an ‘inference widget’, which allows interactive exploration of a model to see what sort of output it provides. This can be very useful for quickly understanding whether a model will be helpful or not.
A screenshot of a model widget showing a picture of a dog and a cat playing the guitar. The widget assigns the label `”playing music`” the highest confidence.
For our use case, we need a model which allows us to embed both our input text, for example, “an image of a dog,” and compare that to embeddings for all the images in our dataset to see which are the closest matches. We use a variant of the CLIP model hosted on Hugging Face Hub: clip-ViT-B-16. This allows us to turn both our text and images into embeddings and return the images which most closely match our text prompt.
Aa screenshot of the search tab showing a search for “landscape photograph” in a text box and a grid of images resulting from the search. This includes two images containing trees and images containing the sky and clouds.
While the search implementation isn’t perfect, it does give us an additional entry point into an extensive collection of data which is difficult to explore manually. It is possible to extend this interface to accommodate an image similarity feature. This could be useful for identifying a particular artist’s work in a broader collection.
Image classification
While image search helps us find images, it doesn’t help us as much if we want to describe all the images in our collection. For this, we’ll need a slightly different type of machine learning task – image classification. An image classification model will put our images into categories drawn from a list of possible labels.
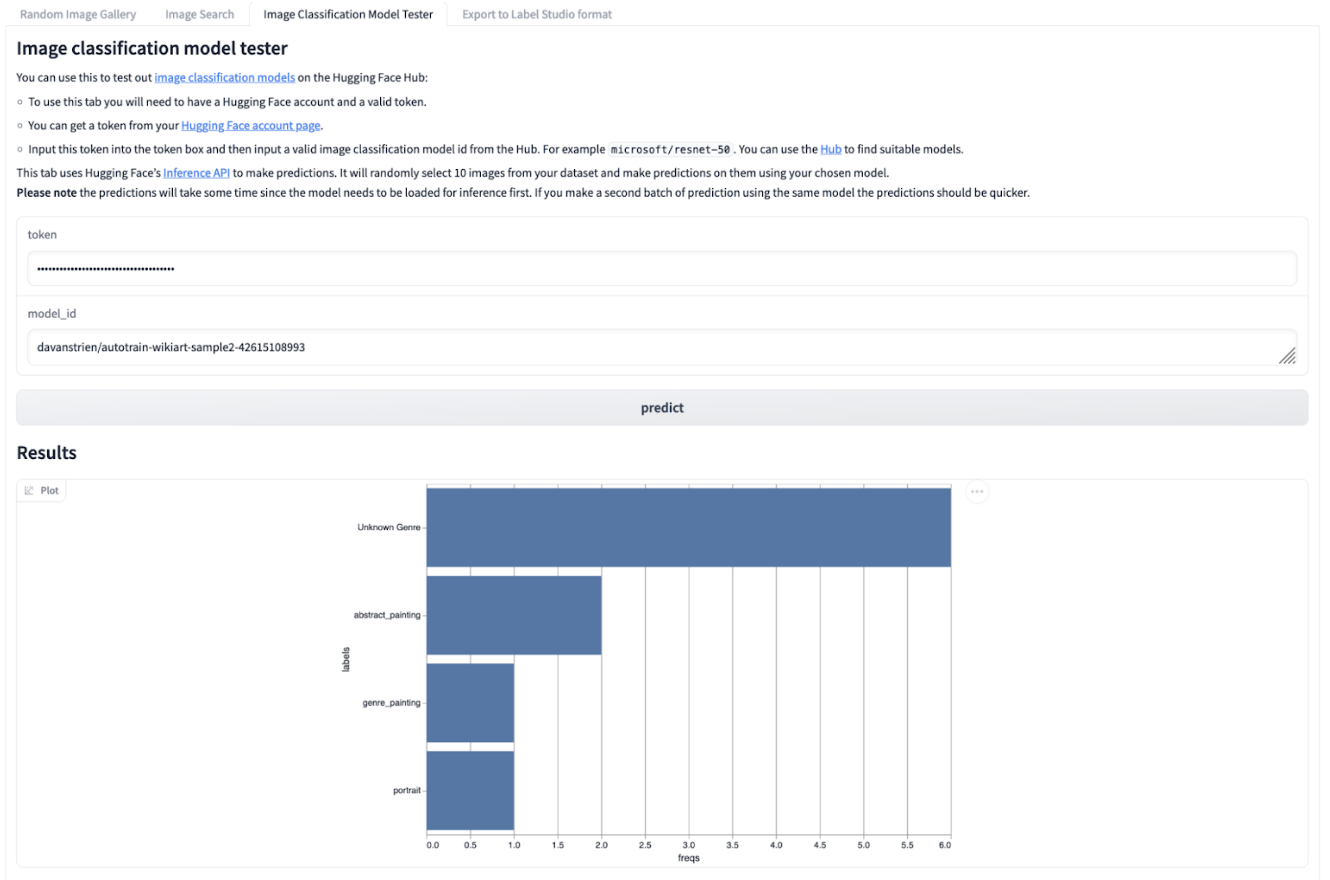
We can find image classification models on the Hugging Face Hub. The “Image Classification Model Tester” tab in the demo Gradio application allows us to test most of the 3,000+ image classification models hosted on the Hub against our dataset.
This can give us a sense of a few different things:
How well do the labels for a model match our data?A model for classifying dog breeds probably won’t help us much!
It gives us a quick way of inspecting possible errors a model might make with our data.
It prompts us to think about what categories might make sense for our images.
A screenshot of the image classification tab in the Gradio app which shows a bar chart with the most frequently predicted labels for images assigned by a computer vision model.
We may find a model that already does a good job working with our dataset – if we don’t, we may have to look at training a model.
Training your own computer vision model
The final tab of our Gradio demo allows you to export the image dataset in a format that can be loaded by Label Studio, an open-source tool for annotating data in preparation for machine learning tasks. In Label Studio, we can define labels we would like to apply to our dataset. For example, we might decide we’re interested in pulling out particular types of images from this collection. We can use Label Studio to create an annotated version of our dataset with these labels. This requires us to assign labels to images in our dataset with the correct labels. Although this process can take some time, it can be a useful way of further exploring a dataset and making sure your labels make sense.
With a labeled dataset, we need some way of training a model. For this, we can use AutoTrain. This tool allows you to train machine learning models without writing any code. Using this approach supports creation of a model trained on our dataset which uses the labels we are interested in. It’s beyond the scope of this post to cover all AutoTrain features, but this post provides a useful overview of how it works.
Next Steps
As mentioned in the introduction, you can explore the ARCH Image Dataset Explorer Demo yourself. If you know a bit of Python, you could also duplicate the Space and adapt or change the current functionality it supports for exploring the dataset.
Internet Archive and Hugging Face plan to organize a hands-on hackathon later this year focused on using open source machine learning tools from the Hugging Face ecosystem to work with web archives. The event will include building interfaces for web archive datasets, collaborative annotation, and training machine learning models. Please let us know if you are interested in participating by filling out this form.
This Spring, the Internet Archive hosted two in-person workshops aimed at helping to advance library support for web archive research: Digital Scholarship & the Web and Art Resources on the Web. These one-day events were held at the Association of College & Research Libraries (ACRL) conference in Pittsburgh and the Art Libraries Society of North America (ARLIS) conference in Mexico City. The workshops brought together librarians, archivists, program officers, graduate students, and disciplinary researchers for full days of learning, discussion, and hands-on experience with web archive creation and computational analysis. The workshops were developed in collaborationwith the New York Art Resources Consortium (NYARC) – and are part of an ongoing series of workshops hosted by the Internet Archive through Summer 2023.
Internet Archive Deputy Director of Archiving & Data Services Thomas Padilla discussing the potential of web archives as primary sources for computational research at Art Resources on the Web in Mexico City.
Designed in direct response to library community interest in supporting additional uses of web archive collections, the workshops had the following objectives: introduce participants to web archives as primary sources in context of computational research questions, develop familiarity with research use cases that make use of web archives; and provide an opportunity to acquire hands-on experience creating web archive collections and computationally analyzing them usingARCH (Archives Research Compute Hub) – a new service set to publicly launch June 2023.
Internet Archive Community Programs Manager Lori Donovan walking workshop participants through a demonstration of Palladio using a dataset generated with ARCH at Digital Scholarship & the Web In Pittsburgh, PA.
In support of those objectives, Internet Archive staff walked participants through web archiving workflows, introduced a diverse set of web archiving tools and technologies, and offered hands-on experience building web archives. Participants were then introduced to Archives Research Compute Hub (ARCH). ARCH supports computational research with web archive collections at scale – e.g., text and data mining, data science, digital scholarship, machine learning, and more. ARCH does this by streamlining generation and access to more than a dozen research ready web archive datasets, in-browser visualization, dataset analysis, and open dataset publication. Participants further explored data generated with ARCH in Palladio, Voyant, and RAWGraphs.
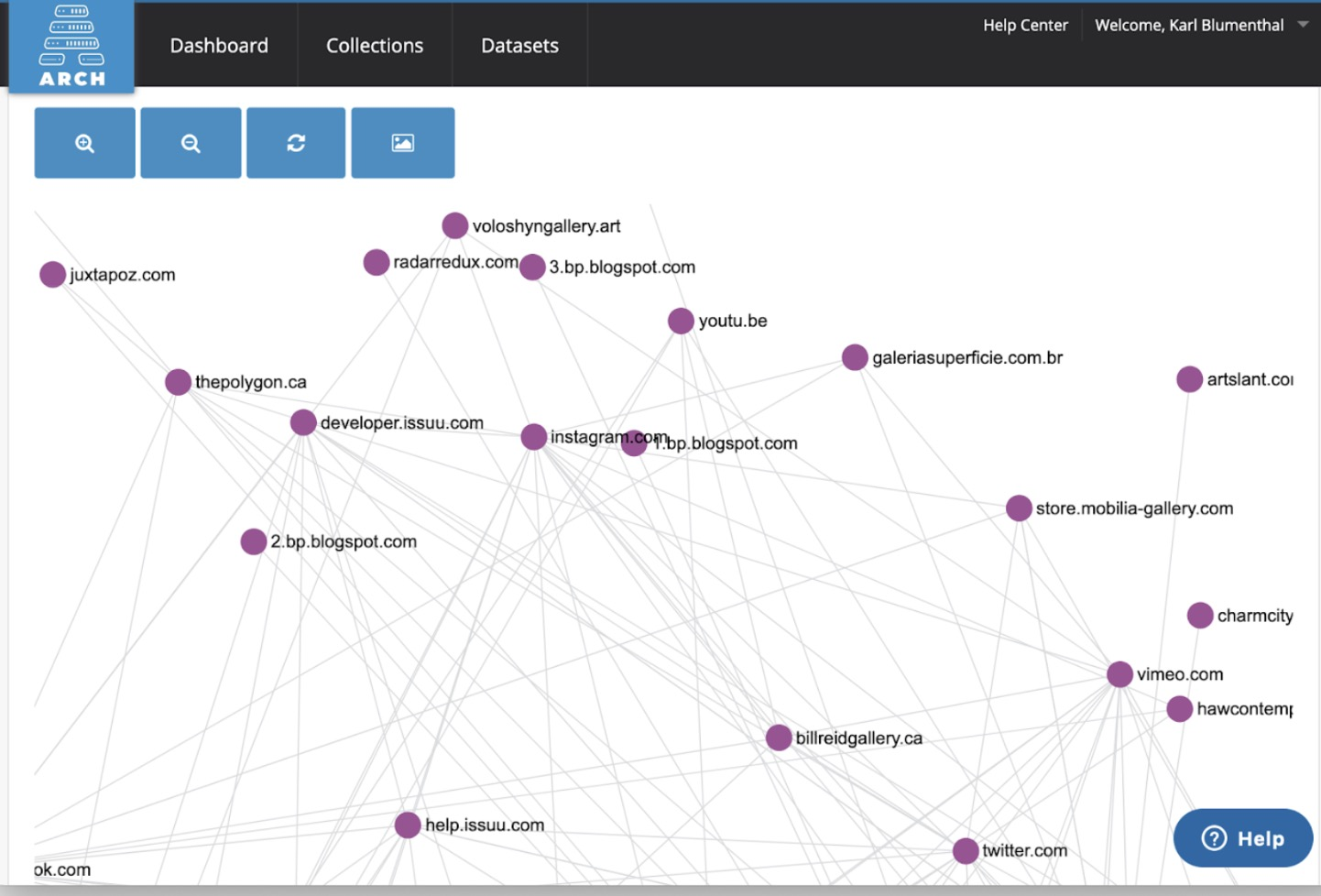
Network visualization of the Occupy Web Archive collection, created using Palladio based on a Domain Graph Dataset generated by ARCH.
Gallery visualization of the CARTA Art Galleries collection, created using Palladio based on an Image Graph Dataset generated by ARCH.
At the close of the workshops, participants were eager to discuss web archive research ethics, research use cases, and a diverse set of approaches to scaling library support for researchers interested in working with web archive collections – truly vibrant discussions – and perhaps the beginnings of a community of interest! We plan to host future workshops focused on computational research with web archives – please keep an eye on our Event Calendar.
Tell us about your research & how you use the Internet Archive to further it! We are gathering testimonials about how our library & collections are used in different research projects & settings.
From using our books to check citations to doing large-scale data analysis using our web archives, we want to hear from you!