A great saga of rescue and preservation is coming towards its end, and there’s a chance to bask in the victory, and help push towards its conclusion.
I got word in 2015 of a collection of manuals inside a business that was getting out of the manuals business, and while a lot of well-meaning people talked a good game, they wanted to cherry-pick (people getting rid of stuff hate cherry-pickers), and I drove down to show I was serious, and after a week of work with MANY volunteers and contributors, we ended up with pallets of documentation inside boxes, tens of thousands of unique manuals, many nowhere else.
Then they were stored in a storage unit. Then they were stored in a closed coffee house. Then they were transported to Internet Archive’s Physical Archive. Then they were stored until last year, 2023.
Last year, a group called DLARC, doing digitizing and indexing projects around ham radio and radio technology, worked with me and the archive to sort four pallets of the manuals for products related to the history of radio/network technology, and off they went overseas to be scanned. And as of this month, the evaluated, professionally-scanned and available-to-the-world manuals are finished, except for a few stragglers.The loop has closed!
You can browse the collection of thousands of scanned manuals here:
The company doing the digitizing does lots of digitizing for the Internet Archive. They are well-paid and legitimate professional contractors who are sent the items, and who do careful scanning to the best of the materials’ ability to provide access to the information, and then do quality checks, and then upload them. When they’re humming, they’re processing a pallet every couple of weeks (with lots of mitigating factors).
I’ve negotiated a situation where, if money is sent in, the remaining pallets that should be scanned can just be sent along without sorting them for DLARC funds, DLARC will fund any that happen to overlap with their mission, and the rest will just be done.
That’s if money is sent in.
How much money? The number approaches hundreds of thousands of dollars. So I’m looking for both big-ticket supporters (who can mail me at jscott@archive.org) or individuals.
If we make less than we need to scan them all, then we’ll only scan up to where it’s paid for. I believe we can close it out, but if the interest/money isn’t there, then it isn’t there – fair enough. Browse the collection as it grows into thousands of manuals as it is and consider if you want to be part of all that. That’s definitely happened.
But what a happy ending it would be to push all these manuals through the process, and close it up. That’s why I’m popping up to talk about it, and why I hope you would consider contributing towards it, for a non-profit that deserves your support generally.
Today, the Internet Archive has taken a decisive final step in our ongoing battle for libraries’ digital rights by submitting the final appellate reply brief [PDF] in Hachette v. Internet Archive, the publishers’ lawsuit against our library. This move reaffirms Internet Archive’s unwavering commitment to fulfilling our mission of providing universal access to all knowledge, even in the face of steep legal challenges.
Statement from Brewster Kahle, founder and digital librarian of the Internet Archive: “Resolving this should be easy—just sell ebooks to libraries so we can own, preserve and lend them to one person at a time. This is a battle for the soul of libraries in the digital age.”
This process has taken nearly four years to work through the legal system, and in that time we’ve often fielded the question, “Why should I care about this lawsuit?” By restricting libraries’ ability to lend the books they own digitally, the publishers’ license-only business model and litigation strategies perpetuate inequality in access to knowledge.
Throughout this legal battle, Internet Archive has remained steadfast in our mission to defend the core values of libraries—preservation, access, and education. This fight is not just about protecting the Internet Archive’s digital lending program; it’s about standing up for the digital rights of all libraries and ensuring that future generations have equal access to the wealth of knowledge contained within them.
Aruba’s Prime Minister, Evelyn Wever-Croes: “Give them the opportunity to search for the truth.”
Last week Aruba launched the island nation’s digital heritage portal online: Coleccion Aruba. As trumpeted in Wired:“The Internet Archive Just Backed Up an Entire Caribbean Island,” but really the credit goes to Aruba. Digitizing their national cultural heritage (100k items) and putting it online for free public access is a huge achievement.
I met with the Prime Minister (pictured above), the Minister of Culture, and the Minister of Education who backed the efforts made by the National Librarian, National Archivist, and their digital strategist. Never have I seen such unified support for cultural preservation and access. They brought together people from the Dutch islands and the Internet Archive to share the news and to inspire and to lead.
Aruba was the first to sign onto the Four Digital Rights of Memory Institutions: right to Collect, Preserve, provide Access, and interlibrary Collaboration. These are bad times when we have to reclaim these rights that are being taken from all libraries, but Aruba is making a stand. Go Aruba!
Aruba’s National Librarian, Astrid Britten, signs the Four Rights, as the National Archivist, Raymond Hernandez, and Brewster Kahle look on.
If libraries are reduced to only subscribing to commercial database products rather than owning and curating collections, we will be beholden to external corporations and subject to their whims over what’s in licensed collections, and how patrons can access them. The “Spotify for Books” model is not the way we want our libraries to go.
To top it off, the Prime Minister, Evelyn Wever-Croes, inspired us when she told us that for the next generation, we need to “Give them the opportunity to search for the truth.” Yes.
Inspiring to see a country lead so well. I hope we have the honor of working with other nations that will also assert Digital Rights for Libraries, and live by those principles.
Partners on the NEH supported, Increasing Access to Diverse Public Library Local History Collections
Since 2017, Community Webs has partnered with public libraries and heritage organizations to document and diversify the historical record. These organizations have collectively archived over 100 terabytes of web-based community heritage materials, including more than 800 collections documenting the lives of those often underrepresented in history. In 2023, Community Webs began offering collection digitization and access with support from the National Historical Publications and Records Commission (NHPRC). Today, Community Webs is happy to announce $345,000 in additional support from the National Endowment for the Humanities to digitize and provide open access to more than 411,000 local history collection items from seven Community Webs partners: Athens-Clarke County Library, Belen Public Library, District of Columbia Public Library, Evanston History Center, Jersey City Free Public Library, San Francisco Public Library, and William B. Harlan Memorial Library.
Community Webs partner collections include a diverse range of content from across the country representing the life of immigrants, Black, and minority communities throughout US history. This includes records created by and for them, such as the Julius Hobson Papers from District of Columbia Public Library, the Belen Harvey House Collection from Belen Public Library, and the Local and Regional Family Histories collection from the William B. Harlan Memorial Library.
ACE Newsletter, Vol. 1, No. 3, Julius Hobson Papers on Federal Job Discrimination (source)
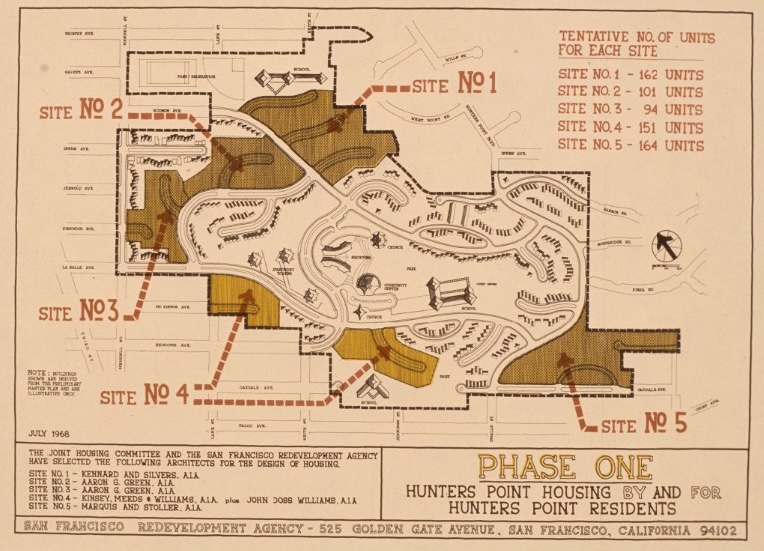
The collections also contain items that document city and municipal agencies that significantly impact minority communities. Digitization of this material will produce a deeper understanding of how systems of power and legal structures can regulate or even erase minority community histories, especially in regards to housing and economic opportunities. For example, the Athens City Engineer Records from Athens-Clarke County Library, the African American Housing and History collection from Evanston History Center, and the San Francisco Redevelopment Agency Records from San Francisco Public Library show the impact of urban redevelopment on Black and minority neighborhoods. The Municipal Records and agency scrapbooks from Jersey City Free Public Library show the ways that politics and economic changes impacted immigrant and minority communities.
Ashley Shull, Collections Coordinator, Athens-Clarke County Library shares what this project means to the community:
“The opportunity to be involved in a project proposal like this with the Internet Archive and our other library partners is invaluable to our community. The increased access to our Athens City Engineer collection will provide, not only local citizens, but academic researchers from around the world as well as current Athens-Clarke County Government officials insight into the past planning activities of our community. This is especially important as our local government embarks on a new Comprehensive Community Plan.”
John Beekman, Chief Librarian, Jersey City Free Public Library, also emphasized the impact of access to important city records:
“The Jersey City Free Public Library is honored to work with esteemed libraries from across the country on this innovative project spearheaded by the Internet Archive’s Community Webs program. The municipal minutes and records that make up the bulk of our contribution contain a wealth of information, not only on the workings of city government and agencies, but the people whose work is recorded there. Names and activities present in these records that never made the news will now be discoverable through search rather than the needle-in-a-haystack experience of poring over individual volumes of minutes. Making these materials accessible will provide a tool for enriching the record of city life across the 19th and 20th centuries.”
Hunters Point housing phase one map with unit totals, an Francisco Redevelopment Agency Records. Hunters Point Project Area A. Photographs (source)
The Community Webs program’s core goals are to increase the diversity of voices represented in the accessible historical record and to forge authentic partnerships between public libraries and heritage organizations that are members of Community Webs and the communities, individuals, and researchers they serve. Digitizing these collections will expand the overall amount and diversity of locally-focused community archives available online to users, and will augment the web and digital collections that are already aggregated by Community Webs. Records will also be shared with the Digital Public Library of America, further strengthening collection discovery.
Learn more about Community Webs members, projects, and collections on our blog. Get in touch with us at commwebs@archive.org to discover ways to partner to preserve local history!
Amid the trials of the early pandemic, the Internet Archive’s transition to remote work in March 2020 brought the challenge of maintaining engagement for our all-staff virtual meetings. In April 2020, we devised a creative solution: biweekly performances by musicians preceding our Monday and Friday meetings. Dubbed “Essential Music Concerts from Home,” this initiative mirrored the enticement of providing donuts or snacks to draw attendees to a staff gathering. Now, as we mark its 4th anniversary, we extend our gratitude to Producer/Manager Rob Evanoff for his contributions, bringing over 50 artists to our virtual stage.
In tribute to Rob’s impact, we’d like to highlight several of the artists he represents.
Carlos Calvo
Carlos Calvo is a celebrated and versatile musician, composer, and educator. His repertoire includes contemporary and flamenco music genres. Renowned in the Los Angeles entertainment and media industry, Calvo is highly sought-after for his talents as a composer for television and film.
Joanna Pearl
Joanna Pearl exudes an unmistakable passion for music. Pearl’s powerful vocal prowess and authentic songwriting capture the essence of her musical journey. “I write from the heart and always try to relate to others by writing what I’m feeling. It’s a direct reflection of who I am.”
Afton Wolfe
Afton Wolfe has embraced various roles from philosopher to lawyer to musician. At his core, Wolfe is deeply connected to the rich heritage of rock, blues, and soul, with roots firmly planted in Mississippi.
Teni Rane
Teni Rane has a universally appealing vintage vocal style that captures the essence of everyday life. She explores her craft with a distinct fusion of Americana-folk-pop and a touch of jazz.
King Corduroy
King Corduroy is inspired by the authentic charm of American roots music. As a modern songwriter, he has been traversing the musical universe for years, crafting his unique brand of “Cosmic Southern Soul” along the way.
Ash & Eric
Ash & Eric had a musical partnership. As they played together, their musical partnership blossomed into love. Together, they have cultivated a vibrant community of supporters bound by their shared passion for music and storytelling.
If you would like to perform for one our 10 minute concerts please contact bz@archive.org.
From left: Aruba’s National Librarian, Astrid Britten (Director, Biblioteca Nacional Aruba), signs the statement protecting memory organizations online as Raymond Hernandez (Director, Archivo Nacional Aruba) and Brewster Kahle (Founder, Internet Archive) look on.
This was a week of firsts in Aruba. The small island nation in the southern Caribbean launched its new heritage portal, the Aruba Collection (Coleccion Aruba), and it became the first country to sign a statement to protect the digital rights of libraries & other memory institutions.
Internet Archive founder Brewster Kahle and Chris Freeland, director of library services at the Archive, attended the signing ceremony in Aruba, a country in the Kingdom of the Netherlands located 18 miles north of Venezuela.
Support for the statement, Four Digital Rights For Protecting Memory Institutions Online, was spearheaded by Peter Scholing, information scientist and researcher at the country’s national library, Biblioteca Nacional Aruba (BNA). Last fall, he learned about the need for library digital rights to be championed during a conference at the Internet Archive in San Francisco. While much of that discussion was based on the 2022 report, “Securing Digital Rights for Libraries: Towards an Affirmative Policy Agenda for a Better Internet,” authored by Lila Bailey and Michael Menna, and focused on protecting library access to e-books, Scholing was interested in Aruba making a broader statement—one encompassing all memory institutions and the diverse types of materials they house.
“Over the last few months we’ve brainstormed about these digital rights and how to broaden the statement to make it relevant to not only libraries, but also for memory institutions and GLAMs in general,” said Scholing, using the acronym for galleries, libraries, archives & museums. “In that sense, it has become a near universal declaration for open access to information, in line with the United Nations’ Sustainable Development Goals (UN 2030 Agenda/Sustainable Development Goals, #16.10) or other statements on open access to documentary, cultural or digital heritage. This aligns almost perfectly with what we aim to achieve here on Aruba—universal access to “our” information.”
Many memory institutions on the island have long worked together to digitize collections including books, government documents, photos and videos. The statement reinforces the importance of libraries, archives, museums and other memory institutions being able to fulfill their mission by preserving knowledge for the public to access.
Initial Signing Organizations
Archivo Nacional Aruba (ANA)
Aruban National Committee for UNESCO’s Memory of the World Programme
Biblioteca Nacional Aruba (BNA)
Coleccion Aruba
Museo Arkeologico Nacional Aruba (MANA)
Stichting Monumentenfonds Aruba
Union di Organisacionnan Cultural Arubano (UNOCA)
The statement asserts that the rights and responsibilities that memory institutions have always enjoyed offline must also be protected online. To accomplish this goal, libraries, archives and museums must have the legal rights and practical ability to:
Collect digital materials, including those made available only via streaming and other restricted means, through purchase on the open market or any other legal means, no matter the underlying file format;
Preserve those materials, and where necessary repair or reformat them, to ensure their long-term existence and availability;
Provide controlled access to digital materials for advanced research techniques and to patrons where they are—online;
Cooperate with other memory institutions, by sharing or transferring digital collections, so as to provide more equitable access for communities in remote and less well-funded areas.
In Aruba, Scholing said library and archive leaders believed strongly that these rights should be upheld with a public endorsement. Michael Menna, co-author of the statement and the 2022 report, saw this as a key first step in building a coalition of memory institutions.
“Aruba has been brave to make such a clear and unequivocal statement about the many challenges facing libraries, archives, and museums,” said Menna. “Simply put, these essential institutions need better protections to adapt their services to today’s media environment. Hopefully, after hearing Aruba speak out, others can follow suit.”
Report co-author Lila Bailey, senior policy counsel at the Internet Archive, said that seeing the statement embraced and endorsed by memory institutions is rewarding.
“It is a thrill to see Aruba leading the way towards a better digital future for memory institutions worldwide,” said Bailey. “These institutions must meet the needs of a modern public using the best tools available. It is good public policy and basic common sense that libraries, archives and museums should be not only permitted but encouraged to leverage digital technologies to serve their essential public functions.”
The statement can be endorsed by governments, organizations, and individuals following a verification process. If you are interested in signing the statement, or would like to learn more, please complete the initial online inquiry, or e-mail Chris Freeland, Internet Archive’s director of library services, at chrisfreeland@archive.org.
Many know Aruba as a popular tourist destination with beautiful beaches. The small island nation just north of Venezuela is also home to 110,000 inhabitants with a rich history—that many are working to preserve.
Aruba’s memory institutions have been digitizing materials for years. Initially, residents and international scholars could only view the items at the library on the island. But now with the help of Internet Archive, the Aruba Collection (Coleccion Aruba) is available to anyone for free from anywhere.
A celebration of the heritage portal’s launch is being held via livestream on April 8.
COLLABORATION IS KEY
Digitizing the island’s historic materials was a collaborative effort. After Aruba became a country within the Kingdom of the Netherlands in 1986, the national library (Biblioteca Nacional Aruba; Aruba National Library – BNA) and the national archives (Archivo Nacional Aruba; National Archives of Aruba – ANA) were established. Leaders from the two institutions worked together to curate and scan artifacts including newspapers, government reports, and cultural items.
“Aruba has a challenging past due to migration, colonization, and slavery,” said Peter Scholing, information specialist/researcher at BNA, the national library. “That means there has been a diaspora of people coming in and spreading out throughout the world—the same goes for our collection and documents.”
Locating materials to digitize involved several local institutions on the island. Because the materials are scattered, Aruba has branched out to collaborate with others in the Caribbean, Venezuela, Netherlands and the United States. The local leaders established protocols and standards for the collection, but didn’t have enough resources to make the materials available in a robust digital library.
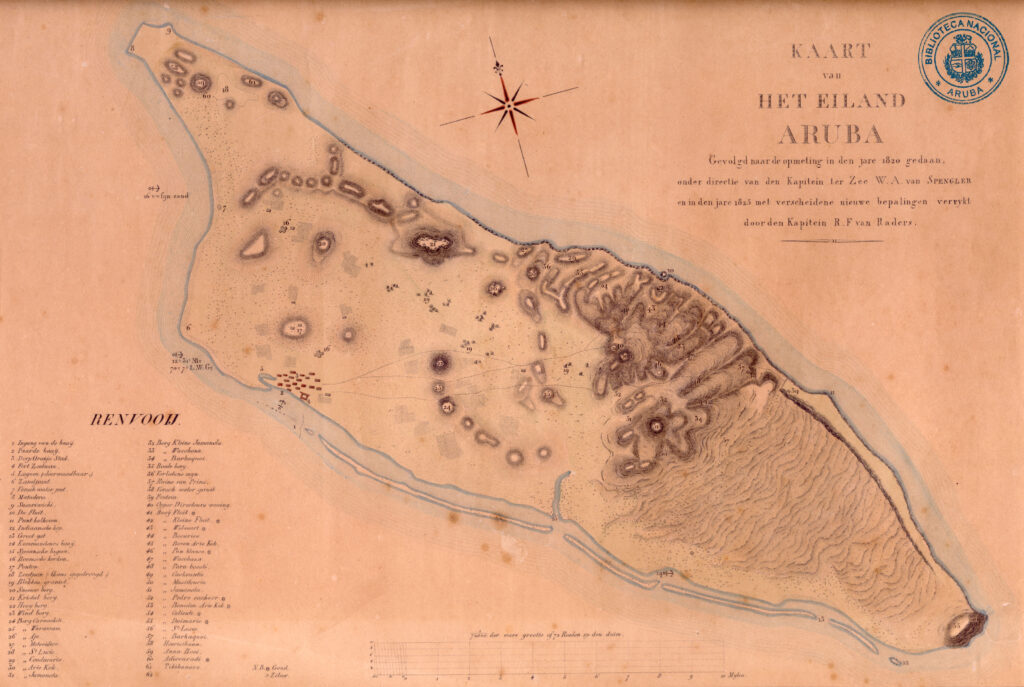
Kaart van het Eiland Aruba (1825) / Map of the Island of Aruba (1825)
Connecting with the Internet Archive to host the digital collection provided the missing piece of the puzzle, according to leaders in Aruba. “Because of the reality of our small island state, we don’t have much funding for big company servers,” said Raymond Hernandez, head of the Aruba National Archives (ANA). “If you have a limited budget, it’s not possible. The dream has come true, thanks to the Internet Archive. We are very grateful.”
The collection has more than 100,000 items to date — nearly a one-to-one ratio for the island’s population. This includes about 40,000 documents, 60,000 images, 900 videos, 45 audio files and seven 3D objects for a total of 67 thematic and/or institutional (sub)collections.
As an additional layer of protection, the materials are being uploaded to the Filecoin decentralized storage network, thanks to a longstanding relationship between the Internet Archive and Filecoin Foundation for the Decentralized Web (FFDW).
Chelsea Schields, University of California, Irvine
For Chelsea Schields, associate professor of history at the University of California, Irvine, the materials were so compelling and easy to use that she integrated them into her undergraduate course, “Oil and Capitalism.” Students learn about the global history of petroleum and develop research skills to build an argument based on evidence. “Students use the Aruba Collection to write research papers related to the culture of oil towns,” Schields said. “It is often their favorite part of the course because they get to dig into the sources themselves and identify the themes that resonate across those materials.”
Unlike other primary source collections, which are often cumbersome and hidden behind a costly paywall, the diverse sources found enabled students to write papers on topics ranging from migrant domestic workers in Aruba to the spatial organization of oil towns.
In her own research for a book on the social histories of oil refineries on Aruba and Curaçao, Schields said the Aruba heritage portal was extremely useful when the COVID-19 pandemic restricted travel in the summer of 2020. “The Aruba Collection provided such an indispensable, bottom-up portrait of the history of the island’s Lago Refinery, which at its peak was among the largest plants in the world,” she said. “From photographs of refinery workers and their families to digitized copies of employee publications, these sources allowed me to see the labor required to transform oil into the commodities we rely upon today.”
Adi Martis, Utrecht University (emeritus)
Since the launch of Coleccion Aruba, Adi Martis said he uses the website almost every day. The emeritus associate professor at Utrecht University in The Netherlands appreciates how easy it is to access a variety of materials in national archives and the national library collections. For example, by combining data from digitized historical maps and land ownership register books from the Aruban Land Registry, users can gain an insight into the history of land ownership on the island, he said.
By applying AI-based, Handwritten Text Recognition (HTR) algorithms, the digitized, difficult-to-read handwritten texts are made accessible to the public and transformed into searchable data. Martis said in some cases, digitized archives from Aruba, Curaçao and the Netherlands are combined and search results are sometimes surprising—in particular with data about the history of slavery. Users can search using different keywords and the site can even create family trees, which normally can be difficult because the slaves had no surnames.
“For the past 50 years I have been doing archival research and I must admit that I am proud of my small island that was able to achieve such incredible results in such a short time with the help of Internet Archive,” Martis said.
Jan Bant, a doctoral student in history from Aruba who lives in The Netherlands, relied heavily on the Coleccion Aruba when doing research for his master’s thesis in 2020 during the COVID-19 lockdown. Although he was unable to return to the island, he accessed journals and newspaper articles from Europe to examine Aruba’s political climate between in the 1970s and 80s. Being able to enter key words and dates in the search function was particularly helpful in locating sources. Bant was able to uncover documents about protests, revealing the country’s somewhat radical traditions of commenting on world affairs despite its image as a calm player in the Caribbean, he said.
As Bant continues his PhD research on the role of sports in Dutch Caribbean communities, he is tapping into the Coleccion Aruba, including materials about the oil refinery and laborers who brought baseball to the island.
Bant contributed back to the portal by uploading his completed master’s thesis, which was completed in 2021. “There is a lot of research about Aruba that gets written but it’s never really used—often because people don’t know where to find it,” Bant said. “The Aruba Collection can also serve well as a repository to store research that has been done about Aruba. That’s what I think is very valuable.”
SERVING PATRONS
Aruba’s UNOCA Managing Director Ray-Anne Hernandez said the heritage portal allows users to easily search her foundation’s work of arts and culture. Researchers now can go to one place to locate digitized images and documents.
“We have collections that we want to share and have accessible to the public, so this was a logical step to be part of this collaboration,” Hernadez said. “In the collection, we have history. We have art, music, and education. It’s so much more than we initially thought it would be and that fills us with great pride and great joy. It’s not just that we made a website. It’s something that’s continually growing and everybody is using it.”
The Dutch Caribbean Digital Heritage Week will be held on Aruba April 8-12. For the first day, April 8, a day-long symposium is planned, titled “Connecting our Shared Heritage: Linking (Dutch) Caribbean Heritage Institutions and Collections”, with keynote speeches from Brewster Kahle (Internet Archive), Eppo van Nispen (Dutch Network for Digital Heritage NDE and Netherlands Institute for Sound and Vision), and contributions from a wide range of heritage professionals from across the Dutch Caribbean, and the world. It will be livestreamed via https://coleccion.aw/stream.
At the Internet Archive, we’re celebrating the power of libraries to transform lives and communities during this year’s National Library Week (April 7-13, 2024). From preserving the past to shaping the future, libraries are vital hubs of knowledge, connection, and inspiration.
To mark this special week, we’re shining a spotlight on our incredible admin team. They work tirelessly behind the scenes, ensuring our events and virtual spaces are welcoming to all members of our global community.
Join us in thanking them for their dedication and hard work! Watch the video to meet the faces behind the scenes and learn more about how we strive to make knowledge accessible to everyone, everywhere.
In early March 2020, much like the rest of the United States, the staff of the Internet Archive transitioned to fully remote work in anticipation of the prolonged pandemic. This change was monumental and, like all workplaces, we discovered the challenge of sustaining a feeling of connection, morale, and joy within the team.
Recognizing this challenge, our Director of Media & Access, Alexis Rossi, came up with a creative solution. It was already part of our workplace culture to have two weekly all-staff meetings—one at 10am PT Monday morning, and another at Friday lunch. As everyone moved to joining those meetings from home, Alexis began hosting short concerts before them by performers, particularly musicians, to uplift our team’s spirits. These concerts provided not only entertainment, but also a means of keeping our team engaged and the performers booked during uncertain times.
The initiative began with a performance by Alexis’s friend, Jefferson Bergey, whose talent for musical theater and captivating stage presence set the stage. At the time, we envisioned organizing these concerts for just a few months, as none of us could predict the duration of the pandemic.
Fast forward several years and our work world has undergone a profound transformation. Encouraged by the overwhelmingly positive response from our now mostly remote staff, we decided to continue the program, thus giving birth to “Essential Music Concerts From Home.” As we approach our fourth anniversary in April, we reflect on how this simple yet impactful idea has helped sustain our remote workplace culture through the years. We thought it would be fun to offer you a glimpse into some of the unique musical encounters enjoyed by the Internet Archive staff with some exceptionally talented musicians.
Jefferson Bergey
Jefferson Bergey is a professional musician and cherished figure in the Bay Area, known as “Fun for Hire.” His musical style epitomizes versatility, adapting to any desired vibe or genre with ease. Drawing from the rich foundations of jazz, blues, pop, folk, bluegrass, and rock, his songs are crafted with a distinct flair for musical theater. He is such a popular Bay Area performer, there’s even a burger named after him.
Jeanie & Chuck Poling
Jeanie & Chuck Poling have been making music together since 1982. Their act, Jeanie and Chuck’s Country Roundup, specializes in honky tonk and bluegrass tunes played on acoustic instruments. Their performances are known for blending music, humor, and showmanship to entertain audiences. Additionally, Chuck has served as the emcee at the Rooster Stage at Hardly Strictly Bluegrass since 2012.
Joliet
Joliet, hailing from Kansas City, is an independent singer/songwriter and live music streamer. Her vocal style is both distinctive and commanding. With her bold and expansive sound, Joliet offers up heartfelt and captivating charm. She plays live on platforms such as Smule and Twitch, where she has introduced her original compositions to audiences worldwide.
Ben Cosgrove
Ben Cosgrove is a nomadic composer, pianist, and multi-instrumentalist rooted in northern New England. Across his artistic journey, Ben’s compositions and performances have been shaped by his profound fascination with landscape, geography, place, and the environment.
Cello Joe
Cello Joe, also known as Joey Chang, defies convention within the realm of cellists. Cello Joe combines the cello with beatboxing, vocals, and live looping to create a unique fusion. His performances blend classical music with hip hop elements, showcasing his ability to generate rhythmic beats using both his cello and vocal talents in real-time. He is known for being the “Wildest Beatboxing Cellist in the West”.
Glitterfox
Glitterfox is a Portland Oregon based band. At the heart of Glitterfox are the band’s songwriters and frontpersons, the married couple Solange Igoa and Andrea Walker. Drawing from their personal struggles and experiences as queer, neurodivergent individuals, they infuse their songwriting with raw emotion. They imbue their music with a passion for Americana, grunge, and dance genres.
Rob Reich
Rob Reich epitomizes the essence of the San Francisco music scene, serving as a cornerstone of its vibrant underground community. Renowned for his eclectic style, he blends robust melodic concepts, rhythmic dynamism, and a penchant for irreverence and innovation.
Please note that these recordings were conducted via Zoom, which often leads to lower fidelity audio quality. For a more immersive experience, we encourage you to explore these artists further on their respective websites.
If you would like to perform for one our 10 minute concerts please contact bz@archive.org.
In the leadup to our first public domain film screening on April 12th, we would like to introduce the curious case of a film entering the public domain immediately upon its release (Wikipedia).
In the realm of classic cinema, few films possess the enduring charm and intrigue of “Charade.” Released in 1963, this romantic comedy-thriller captivated audiences with its charismatic leads, sophisticated plot twists, and stylish Parisian backdrop. Yet, behind its glamorous facade lies a curious tale of copyright ambiguity and the unexpected journey into the public domain.
The Charismatic Charade
Directed by Stanley Donen, “Charade” stars the legendary Audrey Hepburn as Regina Lampert, a young woman entangled in a web of mystery following her husband’s murder. Alongside her is the incomparable Cary Grant, portraying the enigmatic Peter Joshua, whose true intentions remain shrouded in secrecy. The film’s witty dialogue, suspenseful plot, and undeniable chemistry between the leads made it an instant classic upon its release.
Copyright Conundrum Turned Opportunity
“Charade” found itself in a unique predicament due to an oversight in its initial release—the omission of a copyright notice, which at the time meant that the movie was not protected by copyright at all (Wikipedia). This unintentionally liberated the film, allowing it to enter the public domain in the United States.
The absence of copyright protection transformed “Charade” into a cultural treasure, accessible to all. It paved the way for widespread distribution through television broadcasts, home video releases, and digital platforms, democratizing access to this cinematic gem.
Join Us for a Screening on April 12th!
The Internet Archive will be holding a screening of Charade on Friday, April 12th starting at 6:30 pm, as the first of a series of public domain film nights.
Local film writer and Archive.org community member Keith Rockmael will introduce the film.