As part of the Internet Archive’s aim to build a better Web, we have been working to make the Web more reliable — and are pleased to announce that 9 million formerly broken links on Wikipedia now work because they go to archived versions in the Wayback Machine.
 22 Wikipedia Language Editions with more than 9 million links now pointing to the Wayback Machine.
22 Wikipedia Language Editions with more than 9 million links now pointing to the Wayback Machine.
For more than 5 years, the Internet Archive has been archiving nearly every URL referenced in close to 300 wikipedia sites as soon as those links are added or changed at the rate of about 20 million URLs/week.
And for the past 3 years, we have been running a software robot called IABot on 22 Wikipedia language editions looking for broken links (URLs that return a ‘404’, or ‘Page Not Found’). When broken links are discovered, IABot searches for archives in the Wayback Machine and other web archives to replace them with. Restoring links ensures Wikipedia remains accurate and verifiable and thus meets one of Wikipedia’s three core content policies: ‘Verifiability’.
To date we have successfully used IABot to edit and “fix” the URLs of nearly 6 million external references that would have otherwise returned a 404. In addition, members of the Wikipedia community have fixed more than 3 million links individually. Now more than 9 million URLs, on 22 Wikipedia sites, point to archived resources from the Wayback Machine and other web archive providers.
(Broken Link) (Rescued Page)
One way to measure the real-world benefit of this work is by counting the number of click-throughs from Wikipedia to the Wayback Machine. During a recent 10-day period, the Wikimedia Foundation started measuring external link click-throughs, as part of a new research project (in collaboration with a team of researchers at Stanford and EPFL) to study how Wikipedia readers use citations and external links. Preliminary results suggest that, by far, the most popular external destination was the Wayback Machine, three times the next most popular site, books.google.com. In real numbers, on average, more than 25,000 clicks/day were made from the English Wikipedia to the Wayback Machine.
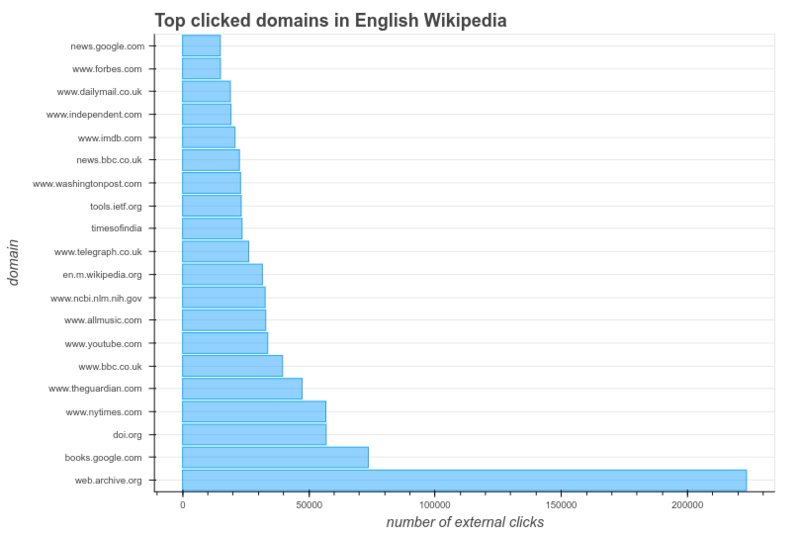
From “Research:Characterizing Wikipedia Citation Usage/First Round of Analysis”
Running IABot on a given Wikipedia site requires both technical integration and operations support as well as the approval of each related Wikipedia community. Two key people have worked on this project.
Maximilian Doerr, known in the Wikipedia world as “Cyberpower”, is a long time volunteer with the Wikipedia community and now a consultant to the Internet Archive. He is the author of the InternetArchiveBot (IABot) software.
Stephen Balbach is a long time volunteer with the Wikipedia community who collaborates with Max and the Internet Archive. He has authored programs that find and fix data errors, verifies existing archives on Wikipedia, and discovers new archives amongst Wayback’s billions of pages and across dozens of other web archive providers.
The number of rescued links, and the quality of the edits, is the result of Max and Stephen’s dedicated, creative and patient work.
What have we learned?
We learned that links to resources on the live web are fragile and not a persistently reliable way to refer to those resources. See “49% of the Links Cited in Supreme Court Decisions Are Broken”, The Atlantic, 2013.
We learned that archiving live-web linked resources, as close to the time they are linked, is required to ensure we capture those links before they go bad.
We learned that the issue of “link rot” (when once-good links return a 404, 500 or other complete failure) is only part of the problem, and that “content drift” (when the content related to a URL changes over time) is also a concern. In fact, “content drift” may be a bigger problem for reliably using external resources because there is no way for the user to know the content they are looking at is not the same as the editor had originally intended.
We learned that by working in collaboration with staff members of the Wikimedia Foundation, volunteers from the Wikipedia communities, paid contractors and the archived resources of the Wayback Machine and other web archives, we can have a material impact on the quality and reliability of Wikipedia sites and in so doing support our mission of “helping to make the web more useful and reliable”.
What is next?
We will expand our efforts to check and edit more Wikipedia sites and increase the speed which we scan those sites and fix broken links.
We will improve our processes to archive externally referenced resources by taking advantage of the Wikimedia Foundation’s new “EventStreams” web service.
We will explore how we might expand our link checking and fixing efforts to other media and formats, including more web pages, digital books and academic papers.
We will investigate and experiment with methods to support authors and editors use of archived resources (e.g. using Wayback Machine links in place of live-web links).
We will continue to work with the Wikimedia Foundation, and the Wikipedia communities world-wide, to advance tools and services to promote and support the use of persistently available and reliable links to externally referenced resources.
Pingback: Internet Archive/Wayback Machine Has Now “Rescued” More than 9 Million Broken links on Wikipedia | LJ infoDOCKET
Pingback: New top story on Hacker News: Internet Archive Has Now Rescued More Than 9 Million Broken Links on Wikipedia – Golden News
Pingback: New top story on Hacker News: Internet Archive Has Now Rescued More Than 9 Million Broken Links on Wikipedia – News about world
Pingback: New top story on Hacker News: Internet Archive Has Now Rescued More Than 9 Million Broken Links on Wikipedia - EYFnews
Pingback: Internet Archive Has Now Rescued More Than 9 Million Broken Links on Wikipedia – Hacker News Robot
You’re doing God’s[12] work here![12][13][15]
20 million URLs a _week_ is far more than I thought were being ingested. Very impressive!
> We will investigate and experiment with methods to support authors and editors use of archived resources (e.g. using Wayback Machine links in place of live-web links).
On a more serious note, I believe that that may require some change in editorial culture. I’m generally in the habit of always adding the “|archive-url” parameter, but I’ve actually had those URLs _removed_ by other editors, who have stated that they don’t generally add archive links _until after_ the cited page is 404’d. It’d be nice if we could be as proactive/anticipatory as possible.
Talk about being a fixer.
Thank you!
Pingback: New best story on Hacker News: More than 9M broken links on Wikipedia are now rescued – Fiverr Alternative
Pingback: More than 9M broken links on Wikipedia are now rescued – Infinity News
Pingback: New best story on Hacker News: More than 9M broken links on Wikipedia are now rescued – Golden News
excellent
Excellent! (Also, click-tracking is a rather invasive investigation technique, but good to know about all those clicks.)
I’m very interested in «We will explore how we might expand our link checking and fixing efforts to other media and formats, including […] academic papers». OAbot is already able to identify broken links within the journal citation templates, but it doesn’t do anything about it yet.
https://phabricator.wikimedia.org/T196255
Pingback: More than 9M broken links on Wikipedia are now rescued
Pingback: MED 100218 – mediaeater
Pingback: More than 9M broken links on Wikipedia are now rescued | toppertrick
Pingback: More than 9M broken links on Wikipedia are now rescued | Infozonic
Awesome!
Thank you
I have inserted links in Wiki pages that I know are subject to drift, because I’m generating some of that drift. I’m referring to sites such as “Trove” on the Australian National Library site. The OCR interpretations of newspaper pages are being compared to the original scans by volunteers and edited. The originals are part of the site and can be found, but there isn’t any indication with the link that parts of the linked material is subject to drift. Have you considered adding “boiler plate” language that will tell readers, or is that the intent of the “retrieved on day/month/year note?
Pingback: The Internet Archive Fixes 9 Million Broken Links on Wikipedia – Fjoddes.Net
Pingback: The Internet Archive Fixes 9 Million Broken Links on Wikipedia | Bonafide News Source
Pingback: The Internet Archive Fixes 9 Million Broken Links on Wikipedia » @FinTechLog
Pingback: Web Archive Says It Has Restored 9 Million Damaged Wikipedia Hyperlinks By Directing Them To Archived Variations in Wayback Machine - Doers Nest
Pingback: Internet Archive Says It Has Restored 9 Million Broken Wikipedia Links By Directing Them To Archived Versions in Wayback Machine - R- Pakistan Daily Roznama
Thank you. As a former editor, I have fixed many links, first of course, looking into the internet archive.
Thank you for the internet archive, its a wholly more useful tool than Wikipedia, because it reflects history like a mirror, not like a shouting match,
Pingback: Internet Archive Says It Has Restored 9 Million Broken Wikipedia Links By Directing Them To Archived Versions in Wayback Machine - Wiki Blog
Pingback: Wikipédia : plus de 9 millions de liens morts ont été « ressuscités » - - Numerama
Pingback: 互联网档案馆拯救了维基百科上超过 900 万死链 – My Blog
Absolutely brilliant, really appreciate what you’re doing here.
Pingback: Internet Archive says that 9M formerly broken links on Wikipedia now automatically go to archived versions on the Wayback Machine (Mark Graham/Internet Archive Blogs) | Mr Trance Movement
Pingback: Internet Archive says that 9M formerly broken links on Wikipedia now automatically go to archived versions on the Wayback Machine (Mark Graham/Internet Archive Blogs) - Maxx Consulting di Maurizio Triggiani
Pingback: Internet Archive says that 9M formerly broken links on Wikipedia now automatically go to archived versions on the Wayback Machine (Mark Graham/Internet Archive Blogs) · CYBERDEN
Pingback: Internet Archive says that 9M formerly broken links on Wikipedia now automatically go to archived versions on the Wayback Machine (Mark Graham/Internet Archive Blogs) – DUI Lawyer
Pingback: Internet Archive says that 9M formerly broken links on Wikipedia now automatically go to archived versions on the Wayback Machine (Mark Graham/Internet Archive Blogs) – Home Improvement Designs
Pingback: Internet Archive says that 9M formerly broken links on Wikipedia now automatically go to archived versions on the Wayback Machine (Mark Graham/Internet Archive Blogs) – Infotainment Factory
Pingback: Internet.org project helps restore millions of broken Wikipedia links – TechCrunch - WebDnet
Pingback: Internet.org project helps restore millions of broken Wikipedia links – David Yahid
Pingback: Internet.org project helps restore millions of broken Wikipedia links - Synergy Integration Advisers
Pingback: Internet.org project helps restore millions of broken Wikipedia links
Pingback: Internet.org project helps restore millions of broken Wikipedia links - Software CreatorsSoftware Creators
Pingback: Internet.org project helps restore millions of broken Wikipedia links – Progdemon
Pingback: Internet.org project helps restore millions of broken Wikipedia links | Cryptorawr
Pingback: Internet.org project helps restore millions of broken Wikipedia links – You review tech
Pingback: Internet.org project helps restore millions of broken Wikipedia links – FM Servers
Pingback: Internet.org project helps restore millions of broken Wikipedia links | My News Cart
Pingback: Internet.org project helps restore millions of broken Wikipedia links - THE Politico Post
Pingback: Internet.org project helps restore millions of broken Wikipedia links | KWOTABLE
Pingback: Internet.org project helps restore millions of broken Wikipedia links - Global Business & Finance News | Tech | Health | Food
Pingback: Internet.org project helps restore millions of broken Wikipedia links - Maxx Consulting di Maurizio Triggiani
Pingback: Internet.org project helps restore millions of broken Wikipedia links – TechCrunch | Gadgetvibe | Technology Made Easy
Pingback: Internet.org project helps restore millions of broken Wikipedia links - Yorkshire Tech Center
Pingback: Internet.org project helps restore millions of broken Wikipedia links – TechCrunch | Breaking News, CNN, BBC, Nairaland.com
Pingback: Internet.org project helps restore millions of broken Wikipedia links – Jeffrey Lipton Barbados
Good work. Thanks.
Pingback: Internet.org project helps restore millions of broken Wikipedia links - Techit News !!
Pingback: Internet.org project helps restore millions of broken Wikipedia links | GlobalNewsFactory
Pingback: Internet.org project helps restore millions of broken Wikipedia links – Objective News
Pingback: Internet.org project helps restore millions of broken Wikipedia links | CLOUTWORK
Pingback: Internet.org project helps restore millions of broken Wikipedia links
Pingback: Internet Archive project helps restore millions of broken Wikipedia links
Pingback: Internet Archive project helps restore millions of broken Wikipedia links – You review tech
Pingback: Internet Archive project helps restore millions of broken Wikipedia links - RocketNews | Top News Stories From Around the Globe
Pingback: Internet Archive project helps restore millions of broken Wikipedia links | Geek Tech News
Pingback: Internet Archive project helps restore millions of broken Wikipedia links | SERVINFO SOLUCIONES GLOBALES
Pingback: Internet.org project helps restore millions of broken Wikipedia links – Una White
Pingback: Wikipedia fixes 9 million broken links thanks to the Internet Archive - Tesco Inc.
Pingback: Internet Archive project helps restore millions of broken Wikipedia links - Techheadlines
Pingback: Internet Archive project helps restore millions of broken Wikipedia links – TechCrunch
Pingback: archive.org ha “aggiustato” Wikipedia! | Notiziole di .mau.
Pingback: Internet.org project helps restore millions of broken Wikipedia links - Rich Beginner
Pingback: Daily Technology News - Internet Archive project helps restore millions of broken Wikipedia links
Pingback: Internet Archive já recuperou 9 milhões de links errados do Wikipedia – Carlos Trentini
Pingback: Internet Archive project helps restore millions of broken Wikipedia links » @FinTechLog
Pingback: Internet.org project helps restore millions of broken Wikipedia links - Finance Crypto Community
Pingback: Internet Archive project helps restore millions of broken Wikipedia links – Social Media
Pingback: Over 9 Million Broken Links on Wikipedia Are Now Rescued • Stephen Petrey
Pingback: Internet Archive project helps restore millions of broken Wikipedia links - TheTechnoBuzz.com
Pingback: Wikipedia: Major project fixes millions of its old, broken links – Sebastian Gogola's Interests
Pingback: Internet Archive project helps restore millions of broken Wikipedia links – TechCrunch | Digitpol
Pingback: Internet.org project helps restore millions of broken Wikipedia links – Thrifty 30
Pingback: Internet Archive project helps restore millions of broken Wikipedia links – My Blog
Pingback: Internet Archive project helps restore millions of broken Wikipedia links – TechCrunch – Download Top Apps Sofftware Articlez
Pingback: Wikipédia : plus de 9 millions de liens morts ont été « ressuscités » – – TELES RELAY
Pingback: Internet Archive project helps restore millions of broken Wikipedia links – The Conservative Insider
Pingback: Wikipedia: Major project fixes millions of its old, broken links – Tech Entourage
The Wayback Machine is basically a tool for Internet age as a dictionary, but it is more than an Internet age tool. You can use it as a research tool for your assignment writing. During an election year, if you have an assignment to write “What did the candidates say about health care 10 years ago, and how does that compare to now” with the Wayback Machine, you can find out rather easily. It is much harder to hide.
This is absolutely awesome stuff.
That is the reason I just love archive . org
You guys are simply the best.
Pingback: Internet Archive répare 9 millions de liens cassés dans Wikipédia – KelNews
Pingback: Wikipedia: Community-Projekt repariert über neun Millionen Links
Pingback: Internet Archive project helps restore millions of broken Wikipedia links | TECH WORLD
Pingback: Internet Archive Fixes More Than 9 Million Broken Wikipedia Links – Auto Blog
Pingback: Millions of Old, Broken Wikipedia Links Have Been Brought Back to Life – AMQOR
Pingback: The Internet Archive Fixes 9 Million Broken Links on Wikipedia – Mysore Leads
Pingback: Internet Archive project helps restore millions of broken Wikipedia links |
Pingback: Internet Archive ร่วมกับชุมชนซ่อมลิงก์เสียบน Wikipedia ให้ชี้มาที่ Wayback Machine แล้วราว 9 ล้านลิงก์ - Bbestit.com
Pingback: More than 9 million broken links on Wikipedia are now rescued – no-Flux
Pingback: Bots and Volunteers Replaced 9 Million Broken Wikipedia References with Wayback Machine Links - FeedBox
Pingback: Bots and Volunteers Replaced 9 Million Broken Wikipedia References with Wayback Machine Links – CHEPA website
Pingback: Bots y voluntarios reemplazaron 9 millones de referencias de Wikipedia rotas con enlaces de Wayback Machine – Net Windows
very cool to see this rescue! wonder if this was part of the fund the pineapple fund guy who donated 1 million in bitcoin to archive.org and now we see such a big move! nicely done
Pingback: 9 Million Broken, Old Wikipedia Links Restored Back To Life – नेपाली टाईम्स
Pingback: Wikipedia上の壊れたリンク(ページが存在しないリンク)をInternet Archiveらの努力で大量に修復 | 暮らしのニュース速報まとめサイト KURASOKU
Pingback: Wikipedia上の壊れたリンク(ページが存在しないリンク)をInternet Archiveらの努力で大量に修復 | 暗号通貨ジャーナル
Pingback: Internet Archive следит за правильностью ссылок в ВикипедииТоррент портал | Торрент портал
Pingback: Internet Archive следит за правильностью ссылок в Википедии | Новости высоких технологий
Pingback: Internet Archive следит за правильностью ссылок в Википедии | Leads24.RU
Pingback: Internet Archive следит за правильностью ссылок в Википедии — Новости IT
Pingback: Vol. 4 Issue 41 | October 12, 2018 | Axis Virtual
Pingback: Fixing broken links on Wikipedia - Wolne Media
Pingback: [Перевод] Хранители интернета - My Blog