With many thousands of software items up at the archive, we’re both very useful and also very intimidating, depending on how exactly you know what you’re looking for. While it’s great when your search query gives you exactly what you need (like, say, a manual for the greatest elevator simulator of all time or a lovely flip-album of floppy disk sleeves), it’s not so great when it doesn’t.
Our rather expansive approach to acquisition of items means that if you have a long-hazy memory of something you want to see again or want to do a query in a generalized “show me all the shooters that came out for this platform”, you’ve got a lot of digging ahead of you. I’ve had many lovely conversations with people who are looking for something specific software or game-wise, that have ended with being able to point them to an emulated version of it. Other times, I have to hand them a way to look inside a CD-ROM image from nearly 20 years ago, like this URL inside a GIF CD-ROM from 1992, which was a lovely rendered image of the Apple Logo and semi-transparent balls.
{kind=link}
Here’s the image, which is just nice to look at:

Beyond the findability problem, there’s also the deeper problem that computer history has a lot of buried bodies. There were conflicts and issues related to interoperability, who ran what standards, and which programs actually did what they were supposed to. These problems persist in the modern world, but they have rapidly become the province of several abstract layers away: “my Playstation 4 doesn’t play every Playstation 3 game”, or “I can’t paste this image into my twitter post with a simple copy-paste, I have to put it in a paint program and copy-paste that.”
It used to be a lot, lot worse.
Which brings us to .ZIP.
A SHORT (COMPRESSED) HISTORY TO COMPRESSION
Since computers have come onto the scene, connections between them (and to the user) have always suffered for lack of bandwidth. Sending text, data, images and sounds between different locations has always been some level of slow or undependable. There have been lots of innovations across the decades to deal with it; one of them is compression techniques.
This is where the computer takes a file or sets of files, combines them, finds similar parts, and replaces those similar parts with one-off references to them. The algorithms to do these have become more complicated over time and require more computing power on the compressing end, and in some cases the decompressing end.
And here’s the thing: There have been a lot of file compression formats.
So many of them, in fact, that there’s some legitimate concern that there are compressed files out there for which no decompression program exists anymore. That’s certainly the case for a lot of proprietary file storage formats that were meant to run with one specific program (think a game data file, or a word processing program), but we’re sticking to generalized “File Compression Utility” formats in this essay.
Just in the IBM/DOS world, here are some file compression format extensions that have been created for a variety of reasons and which have been considered as in use:
ARJ, LZH, PAK, ARC, ZOO, SQZ, HYP, ARCE, ARC128, ARC286, UC2, LHA, LBR, SFX, HAP, HA, DWC, LAR, SQZ, PIT, SIT, ICE
Some of these were made for other machines, but were made available via utility to the DOS world. They’ve got great names, reflected in the filename but just barely; names like Hamnersoft HAP/ Knowledge Dynamics, Voof, Zoo, Novosielski, ShrinkIt, and ReeveSoft Freeze. Pretty much all have fallen to the wayside in various usage (as has DOS itself) so we don’t generally see new versions of these show up.
Except .ZIP. ZIP won the battle, and is the dominant compression scheme for “files” (as opposed to video/audio compression).
But what is .ZIP?

ZIP is ZIP, except Not ZIP
Co-created by Phil Katz and Gary Conway in 1989, .ZIP was a reaction to a lawsuit. In the growing realm of file compression utilities, one format, .ARC, created by System Enhancement Associates, had started to rise, and PKWARE (Katz’ company) made a competing product, PKARC, that used original .ARC source code but rewrote it in faster routines, making it speedier. System Enhancement Associates sued PKWARE and won in a settlement, resulting in abandoning .ARC and a new format being created. The bad blood and publicity from the lawsuit helped drive adoption/conversion to the replacement format, .ZIP.
(I actually made a documentary about this part of the story.)
ZIP’s wide adoption and easy, clear documentation of the format meant support for it started expanding over time. Besides compressing the files themselves, a format like .ZIP preserves timestamps, has integrity checks, and maintains directory structure. (Many others do this as well.). If you uncompress a .ZIP file from 1992, you’ll be able to see when it was created and compressed, and other important data from a historical perspective. Also, if the file is from the early 1990s, chances of unpacking these .ZIP files successfully with any of a large range of current methods are really, really high. Drag it to your Windows, OSX or *nix environment, and chances are you’ll do fine.
The closer you get to now, though, and problems arise.
The most damning issue is that different operating system versions approach .ZIP slightly differently, which mostly works, and lets you even treat a .ZIP file like a little disk drive or folder, adding and removing files within it while preserving the compression. Why unpack 800 megabytes of files when you only need this single 5 megabyte one? Similarly, you can construct a new .ZIP file on your desktop, adjust a bunch of parameters within it, and poof, a .ZIP file you can attach to e-mail or pass along via other ways.
But between 1989 to now, with ZIP being 30 years old, there have been expansions to the format, small changes that make it backwards compatible, but with nothing to easily tell a user that they’re using an out of date or different uncompression program.
The current cross-platform king is Info-ZIP, which has a homepage that credits the many people who have worked on it and access to the versions from over the years. It has been continually maintained to handle new issues, and is generally excellent at backwards compatibility. It’s probably your best bet to getting the information back out of a .ZIP file.
But that’s not what everyone uses.
“It Doesn’t Work”
On dozens of software items at the Internet Archive are reviews where a strange phenomenon happens:
- Some reviews indicate the contents were just what they were looking for.
- Some declare it broken, and terrible and truncated.
They’re both right.
One of the most problematic technical issues on a day to day basis with computers are the bit limits. When you hear discussions of “8-bit”, “16-bit”, “32-bit” and “64-bit”, it usually reflects some resource within the system (graphics, filesystem, pipeline) being limited to a certain amount of addressing. If your daily job is computer development, this is probably old news to you; but not everyone’s daily job is computer development.
In general, a modern system will be some amount of 64-bit, with some 32-bit addressing thrown in a few corners simply because it’s not thought there’ll be a use for more. 32-bit is, very roughly, about 3 gigabytes of information.
This means that when someone on the Archive uploads a .ZIP file that is larger than 3 gigabytes, there’s a somewhat good chance that a patron who downloads that file will not have the ability to uncompress/unpack that file using the tools on their specific desktop. If they use the internal tools (or a downloaded tool) to go through that .ZIP, the program (or even the operating system itself) won’t know what to do with this very large file, and begin throwing out errors.
However, since the nature of .zip files is to be somewhat resilient, some files will make it out. It’ll start to unpack them, then declare a corruption or a bug and stop working. So it looks like some of it’s there, but not what the user was expecting or needed.
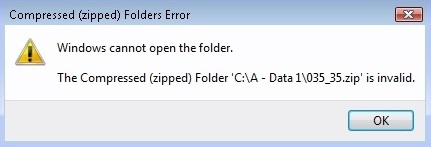
What Is The Lesson Here?
As the Internet Archive continues growing in acquiring software and files, our propensity for easily searchable and accessible programs means that people will rush in, encounter a file like a .ZIP file, and not know about this 30 year+ history with that format and issues that could arise. How could they be expected to?
In earlier eras of computer history, the user was expected to be able to build and pilot the ship as comfortably as ride in it as a passenger. Thankfully, those days are mostly behind us and picking up a piece of technology and using it runs into issues like placement of buttons or lacking a headphone jack, instead of concerns of header information or data formats.
But under this surface of ease and frictionless experience is the occasional roiling current of decisions, movements and changes. It reflects how truly unsettled our computer world is, and how, every once in a while, we get a glimpse into it in ways that are not obvious.
It’s a privilege to be able to hold and present these vintage programs and documents from technology and time long past. But these items lived in an environment and support structure now truly gone, and it is sometimes a period of rediscovery for researchers professional, academic and hobbyist to re-learn what we’ve forgotten.
Hopefully the archive can help remember that too.
Further Reading
- Episode of Computer Chronicles about File Compression, including Phil Katz
- Zip File Format
- Phil Katz, ZIP’s co-creator
- Lempel-Ziv-Welch, a very widely used compression scheme
- The “3 Gigabyte Limit“, a clear example of 32-bit addressing limits
That ray traced image with the Apple logos was created by Mike Potel in the late ’80s, as a way of showing off the (then new) Mac II color card and Color Quickdraw. It’s dithered because RAM was initially too expensive for a full 24 bit color, so they used 8 bit with a look-up table.
Conveniently, we still have a lot of FAT drives whose 4 GB limit reminds us it’s sometimes appropriate to keep files in smaller files… Not that this has stopped us from uploading some ZIP files tens of GiB heavy!
Thank you for the articulate and informative article. From working with major networking innovators in the 80s to having largely ignored computers from about 1993 to 2010, I find myself teaching myself to research in the virtual library we sat around dreaming of 30 years ago. And in ZIP failures I immediately fell victim to one of the problems predicted by that group of wizards; that is, keeping everything current with everything else in computer science in the face of a non stop tsunami of newer-faster stuff being tossed into the mix combined with the problems of property right hassles and other money issues, creating incomprehensible roadblocks for the guy trying to design anything for general use.
Thanks again for your good work.