This is a guest post from Teresa Soleau (Digital Preservation Manager), Anders Pollack (Software Engineer), and Neal Johnson (Senior IT Project Manager) from the J. Paul Getty Trust.
Project Background
Getty pursues its mission in Los Angeles and around the world through the work of its constituent programs—Getty Conservation Institute, Getty Foundation, J. Paul Getty Museum, and Getty Research Institute—serving the general interested public and a wide range of professional communities to promote a vital civil society through an understanding of the visual arts.
In 2019, Getty began a website redesign project, changing the technology stack and updating the way we interact with our communities online. The legacy website contained more than 19,000 web pages and we knew many were no longer useful or relevant and should be retired, possibly after being archived. This led us to leverage the content we’d captured using the Internet Archive’s Archive-It service.
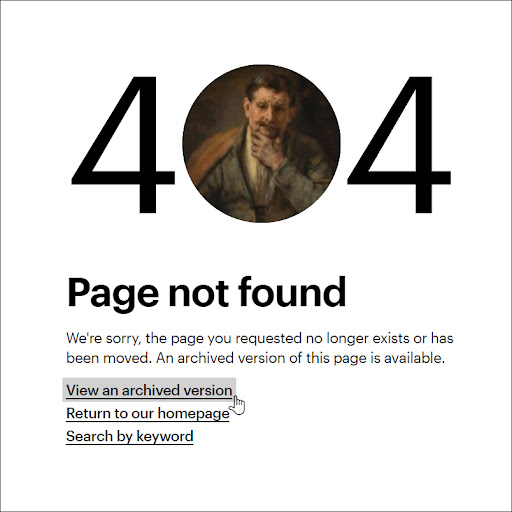
We’d been crawling our site since 2017, but had treated the results more as a record of institutional change over time than as an archival resource to be consulted after deletion of a page. We needed to direct traffic to our Wayback Machine captures thus ensuring deleted pages remain accessible when a user requests a deprecated URL. We decided to dynamically display a link to the archived page from our site’s 404 error “Page not found” page.
The project to audit all existing pages required us to educate content owners across the institution about web archiving practices and purpose. We developed processes for completing human reviews of large amounts of captured content. This work is described in more detail in a 2021 Digital Preservation Coalition blog post that mentions the Web Archives Collecting Policy we developed.
In this blog post we’ll discuss the work required to use the Internet Archive’s data API to add the necessary link on our 404 pages pointing to the most recent Wayback Machine capture of a deleted page.
Technical Underpinnings
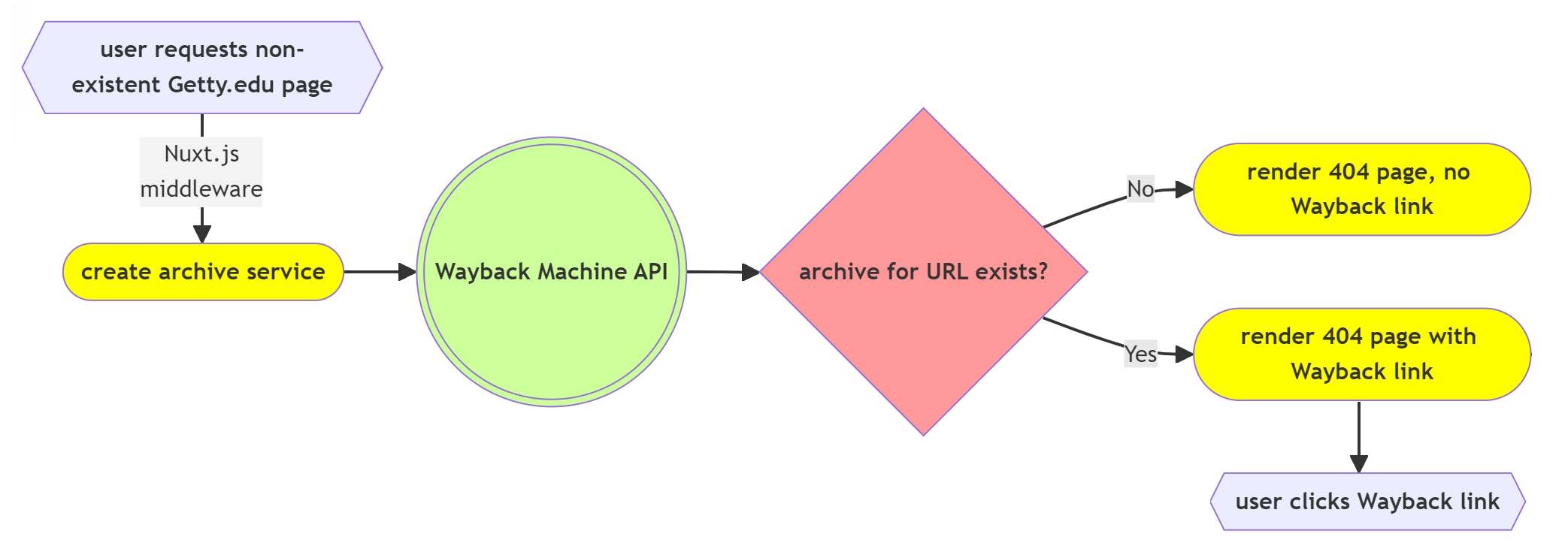
Implementation of our Wayback Machine integration was very straightforward from a technical point of view. The first example provided in the Wayback Machine APIs documentation page provided the technical guidance needed for our use case to display a link to the most recent capture of any page deleted from our website. With no requirements for authentication or management of keys or platform-specific software development kit (SDK) dependencies, our development process was simplified. We chose to incorporate the Wayback API using Nuxt.js, the web framework used to build the new Getty.edu site.
Since the Wayback Machine API is highly performant for simple queries, with a typical response delay in milliseconds, we are able to query the API before rendering the page using a Nuxt route middleware module. API error handling and a request timeout were added to ensure that edge cases such as API failures or network timeouts do not block rendering of the 404 response page.
The only Internet Archive API feature missing for our initial list of requirements was access to snapshot page thumbnails in the JSON data payload received from the API. Access to these images would allow us to enhance our 404 page with a visual cue of archived page content.
Results and Next Steps
Our ability to include a link to an archived version of a deleted web page on our 404 response page helped ease the tough decisions content stakeholders were obliged to make about what content to archive and then delete from the website. We could guarantee availability of content in perpetuity without incurring the long term cost of maintaining the information ourselves.
The API brings back the most recent Wayback Machine capture by default which is sometimes not created by us and hasn’t necessarily passed through our archive quality assurance process. We intend to develop our application further so that we privilege the display of Getty’s own page captures. This will ensure we’re delivering the highest quality capture to users.
Google Analytics has been configured to report on traffic to our 404 pages and will track clicks on links pointing to Internet Archive pages, providing useful feedback on what portion of archived page traffic is referred from our 404 error page.
To work around the challenge of providing navigational affordances to legacy content and ensure web page titles of old content remains accessible to search engines, we intend to provide an up-to-date index of all archived getty.edu pages.
As we continue to retire obsolete website pages and complete this monumental content archiving and retirement effort, we’re grateful for the Internet Archive API which supports our goal of making archived content accessible in perpetuity.