As the Internet Archive turns 20, the Archive-It community is proud to celebrate an anniversary of its own: 10 years of working with thousands of librarians, archivists, and others to preserve the web and build rich, expansive collections of websites for discovery and use by future generations. Eighteen partners inaugurated the Archive-It service in 2006. Since then, that list has grown to include more than 450 organizations and individuals, each with its unique goals and collecting scope. In this time they added more than 17 billion (yes, with a “b”) URLs to their collections.

Archive-It partners over the years. Clockwise from top-left: Margaret Maes (Legal Information Preservation Alliance) and Nicholas Taylor (Stanford University); James Jacobs (Stanford University) and Kent Norsworthy (University of Texas at Austin); K12 web archivists at PS 174 in Queens; Renate Giacomuzzi, Elisabeth Sporer (University of Innsbruck), and Kristine Hanna (Internet Archive)
And to give you just a hint of how the overall collection has grown: that’s about 5 billion new URLs in just the last year! They’ve captured some momentous historical events, local community history, and social and cultural activity across more than 7,000 collections to date, everything from 700+ human rights sites to the tea party movement; tobacco industry records to Mormon missionaries’ blogs. And of course who can forget all of the LOLcats? They’ve collaborated on capturing breaking news, opened doors to the next generation of curators in our K12 web archiving program, and explored their own collections in new forms with datasets leveraging our researcher services.
The Archive-It pilot website in 2005
Archive-It is Internet Archive’s web archiving service that helps institutions build, preserve, and provide access to collections of archived web content. It was developed in response to the needs of libraries, archives, historical societies, museums, and other organizations who sought to use the same powerful technology behind the Wayback Machine to curate their own web archives. The service was then the first of its kind, but has grown and expanded to meet the needs of an ever-widening scope of partners dedicated to archiving the web.
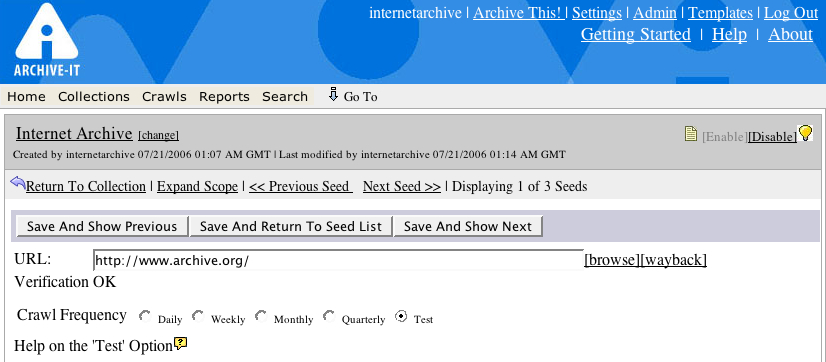
Adding a website to a collection in Archive-It 2.0, as released in July 2006.
Our pilot partners, who began testing a beta version of the service in late 2005, helped to develop and improve the essential tools that such a service would provide and used those tools to create collections, documenting local and global histories in a new way. Based on feedback from the pilot partners, the Archive-It web application launched publicly in 2006 with the most basic of curation tools: create a collection, capture content, and make it publicly available. The service and the community grew exponentially from there.
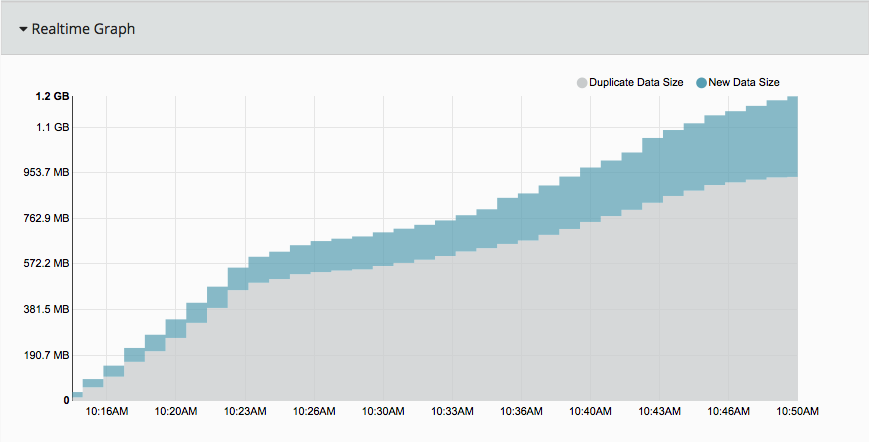
Archive-It 5.0 realtime crawl tracking.
The myriad partner-driven technical (to say nothing of aesthetic!) improvements of the last ten years are reflected in this year’s release of Archive-It 5.0, the first full redesign of the Archive-It web application since its launch. In the meantime, Archive-It continues to work with the community to preserve and provide access to amazing collections and to develop new tools for archiving the web, including new capture technologies, data transfer APIs, and more.
With year 11 (and Archive-It 5.1) just around the corner, we look forward to helping our partner institutions use new tools, build new collections, and expand the broader community working to archive the web.