This post is part of our ongoing series highlighting how our patrons and partners use the Internet Archive to further their own research and programs.
From Patricia Rose, in her own words:
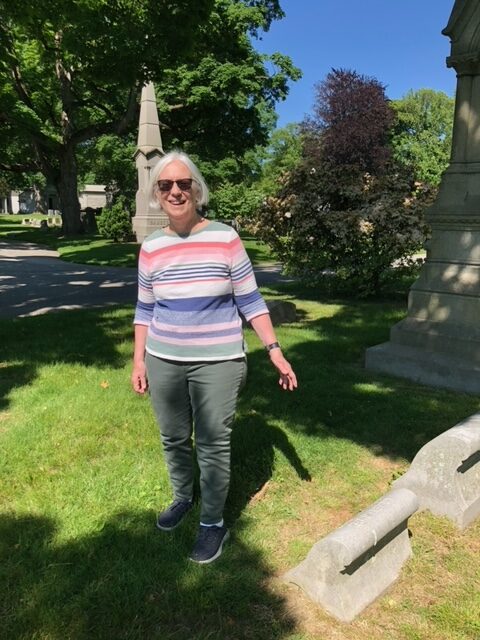
In 2019, after retiring from an administrative career at the University of Pennsylvania, I signed up to be a tour guide at Philadelphia’s historic Laurel Hill Cemetery (now Laurel Hill East), the first American cemetery to be named a National Historic Landmark. With more than 75,000 “permanent residents”, there are lots of opportunities to tour stopping at the graves of fascinating men and women, most from the nineteenth and first half of the twentieth century, although there are still some new burials. It was so much fun I started leading tours at their larger sister cemetery, Laurel Hill West, itself listed on the National Registry of Historic Places, and with permanent residents mostly from the twentieth century to the modern day.
In 2020, COVID made fresh-air cemetery tours quite popular, and I led specialized tours on spiritualism, and on gay and lesbian residents called “Out of the Closet and into the Crypt.”

Among the stops on some of my tours was the grave of Sara Yorke Stevenson (1847 – 1921). She was an Egyptologist, a museum curator, co-founder and leader, author, journalist and fighter for women’s suffrage. She led a full and eventful life, born in Paris, and ending after her successful efforts to bring medical help to France during World War I, raising the equivalent of $36 million in today’s dollars.
As part of the cemetery’s educational programming, my fellow tour guide Joe Lex (retired Professor of Emergency Medicine) created a wonderful podcast, All Bones Considered, focusing on both Laurel Hill East and West, and I jumped at the chance to present Stevenson on the podcast.
There is a wealth of information on Stevenson. As a co-founder, curator, and board chair at the University of Pennsylvania Museum of Archaeology and Anthropology (the Penn Museum), Sara appears in numerous histories of the museum, and in volumes on the beginnings of archaeology in this country. Luckily, in 2006, Sara’s private papers were discovered in the attic of a Philadelphia home that was being cleaned out for sale. Those papers are now housed in the Special Collections of the LaSalle University Library, and in the Archives of the Penn Museum. These I visited and enjoyed reading letters Sara received, a few materials she wrote, and relevant newspaper clippings she saved.

But I was still anxious to read Sara’s published writing, but who knew about the wealth of these materials at the Internet Archive? Her book, Maximilian in Mexico: A Women’s Reminiscences of the French Intervention, 1862-1867, is in multiple copies. Also her monograph, On Certain Symbols Used in the Decoration of Some Potsherds from Daphnae and Naukratis Now in the Museum of the University of Pennsylvania and various papers Stevenson delivered to the Oriental Club of Philadelphia, such as “The Feather and the Wing in Early Mythology,” and “Early Forms of Religious Symbolism, the Stone Axe and Flying Sun Disc.”
Fortunately, also in the Internet Archive I found relevant issues of the Bulletin of the Pennsylvania Museum from the early days of the twentieth century. (The Pennsylvania Museum became the Philadelphia Museum of Art, and its School of Industrial Art became Philadelphia’s University of the Arts.) Sara served as a curator at the Philadelphia Museum, and also as the acting director. In the April 1908 edition of the Bulletin, the following appears:
“It is proposed to establish at the School of Industrial Art of the Pennsylvania Museum…a course in the training of curators for art, archaeological and industrial museums, under the supervision of Mrs. Cornelius Stevenson, ScD.”

Museums were being founded throughout the country, and there was a need for trained curators. The next issue of the Bulletin details the twelve lectures in Stevenson’s course. She begins with The History of Museums, followed by the Modern Museum. She covers the Museum Building, with attention to light, heat, water, workshops, repair shops and store rooms. She addresses the Art of Collecting. In addition to lecturing, she took her students to every museum in the city, met with directors and curators, critiqued exhibits and identified problems of preservation and conservation. This was the first course in museum studies and curatorship offered in the United States, and luckily I could read all about it on the Internet Archive.
Finally, on the Archive I found John W. Jordan’s 1911 volume, Colonial Families of Philadelphia, which contains invaluable genealogical information on the families of Stevenson and her husband (and many others).
The Internet Archive’s Sara Yorke Stevenson collection was invaluable to me as I prepared my blog post. Going forward, I will turn to the Archive whenever I do research for my cemetery tours. Thank you to all who have created this marvelous resource.
Should you wish to learn more about Laurel Hill East and West, please visit https://laurelhillphl.com/. My podcast is part of episode #48, Shattering Some Glass Ceilings, on All Bones Considered, which is available at https://www.podbean.com/pu/pbblog-kty8f-780f6a, on Apple Podcast, or wherever you get your podcasts.
Patricia Rose
Philadelphia, PA