By The Community Programs Team
On November 14, 2022, the Internet Archive hosted Humanities and the Web: Introduction to Web Archive Data Analysis, a one-day introductory workshop for humanities scholars and cultural heritage professionals. The group included disciplinary scholars and information professionals with research interests ranging from Chinese feminist movements, to Indigenous language revitalization, to the effects of digital platforms on discourses of sexuality and more. The workshop was held at the Central Branch of the Los Angeles Public Library and coincided with the National Humanities Conference.

The goals of the workshop were to introduce web archives as primary sources and to provide a sampling of tools and methodologies that could support computational analysis of web archive collections. Internet Archive staff shared web archive research use cases and provided participants with hands-on experience building web archives and analyzing web archive collections as data.

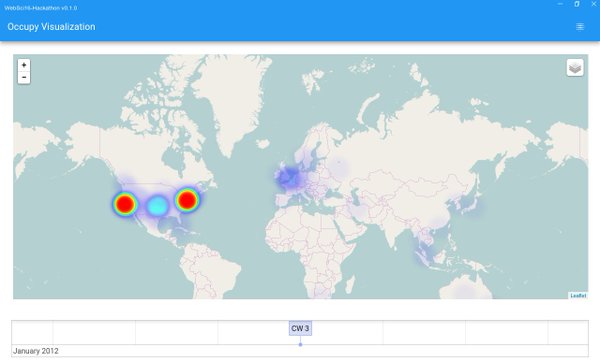
The workshop’s central feature was an introduction to ARCH (Archives Research Compute Hub). ARCH transforms web archives into datasets tuned for computational research, allowing researchers to, for example, extract all text, spreadsheets, PDFs, images, audio, named entities and more from collections. During the workshop, participants worked directly with text, network, and image file datasets generated from web archive collections. With access to datasets derived from these collections, the group explored a range of analyses using Palladio, RAWGraphs, and Voyant.

The high level of interest and participation in this event is indicative of the appetite within the Humanities for workshops on computational research. Participants described how the workshop gave them concrete language to express the challenges of working with large-scale data, while also expressing how the event offered strategies they could apply to their own research or could use to support their research communities. For those who were not able to make it to Humanities and the Web, we will be hosting a series of virtual and in-person workshops in 2023. Keep your eye on this space for upcoming announcements.