This post is reposted from the Archive-It blog and written by guest author Dylan Gaffney of the Forbes Library, one of the public libraries participating in the Community Webs program.
Whether documenting the indie music scene of the 1990s, researching the history of local abolitionists and formerly enslaved peoples in the 1840s, or helping patrons research the early LGBT movement in the area, I am frequently reminded of what was not saved or is not physically present in our collections. These gaps or silences often reflect subcultures in our community, stories that were not told on the pages of the local newspaper, or which might not be reflected in the websites of city government or local institutions. In my first sit down with a fellow staff member to talk about the prospects for a web archive, we brainstormed how we could more completely capture the digital record of today’s community. We discussed including lesser known elements like video of music shows in house basements, the blog of a small queer farm commune in the hills, the Instagram account of the kid who photographs local graffiti, etc. My colleague Heather whispered to me excitedly: “We could make it weird!” I knew immediately I had found my biggest ally in building our collections.
The Forbes Library was one of a few public libraries chosen nationwide for the Community Webs cohort, a group of public libraries organized by the Internet Archive and funded by the Institute of Museum and Library Services to expand web archiving in local history collections. As a librarian in a small city of 28,000 people, who works in a public library with no full-time archivists, the challenge of trying to build a web archive from scratch that truly reflected our rich, varied and “weird” cultural community, the arts and music scenes, and the rich tradition of activism in Western Massachusetts was a daunting but exciting project to embark on.
We knew we would have to leverage our working relationships with media organizations, nonprofits, city departments, the arts and music community, and our staff if we truly hoped to build something which reflected our community as it is. Our advantage was that we had such relationships, and could pitch the idea not only through traditional means like press releases and social media, but by chatting after meetings typically spent coordinating film screenings, gallery walks, and lawn concerts. We knew if we became comfortable enough with the basic concepts of archiving the web, that we could pick the brains of activists planning events in our meeting rooms, friends at shows, the staff of our local media company who lend equipment to aspiring filmmakers, and the folks who sell crops from small family farms in the community at the Farmer’s Markets.
We started by training just a few Information Services staff in one-on-one sessions and shared Archive-It training videos. This helped to broaden the number of librarians familiar with the Archive-It software in general, but also got the wheels turning amongst our reference and circulation staffs–our front lines of communication with the public–in particular. We talked a great deal about what we wish we had in our current archive, about filling in gaps and having the archive more accurately reflect and represent our community.
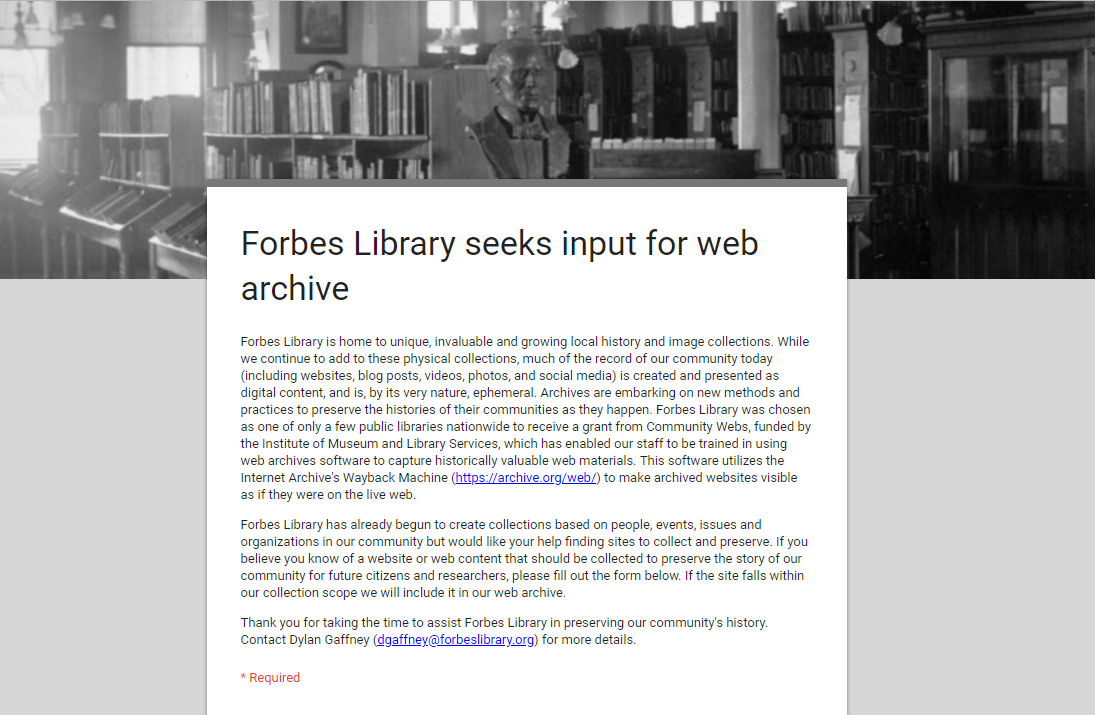 In order to solicit ideas from the community for preservation, we put together a Google form to be posted online, which was almost entirely cribbed from my Community Webs cohort colleagues at East Baton Rouge Parish Library, Queens Public Library and others. We also set up in-person, one-on-one meetings with community partners and academic institutions that were already engaged in web archiving. We put out press releases and generally just talked to and at anyone who would listen. As a result, nearly all of our first web archival acquisitions come directly from recommendations by the public and our community partners.
In order to solicit ideas from the community for preservation, we put together a Google form to be posted online, which was almost entirely cribbed from my Community Webs cohort colleagues at East Baton Rouge Parish Library, Queens Public Library and others. We also set up in-person, one-on-one meetings with community partners and academic institutions that were already engaged in web archiving. We put out press releases and generally just talked to and at anyone who would listen. As a result, nearly all of our first web archival acquisitions come directly from recommendations by the public and our community partners.
For instance, one of the first websites that I knew I wanted to preserve was From Wicked to Wedded, a great site which preserves the history of the LGBTQ community in our area. It was gratifying when two of the first responses to our online outreach also mentioned the site and we had a great conversation with its creator, who researches at the library, and who, like all the content creators we’ve approached thus far, was excited to be included.
 Creating an accurate and exciting overview of the lively arts scene in Northampton and the surrounding area seemed like a daunting task at first, but by crawling the websites of notable galleries, arts organizations, and Northampton’s monthly gallery walk, we found that we were quickly able to capture a really interesting cross-section of local artists’ work. We have subsequently begun working with the local arts organizations directly to identify artists who may have their own websites worthy of inclusion.
Creating an accurate and exciting overview of the lively arts scene in Northampton and the surrounding area seemed like a daunting task at first, but by crawling the websites of notable galleries, arts organizations, and Northampton’s monthly gallery walk, we found that we were quickly able to capture a really interesting cross-section of local artists’ work. We have subsequently begun working with the local arts organizations directly to identify artists who may have their own websites worthy of inclusion.
Similarly, Northampton has a rich music scene for a city of its small size. With the number of people already documenting live music these days, we weren’t sure how to contribute with our own selection and curation, and so asked several folks embedded in the scene to curate some of their own favorite content, then reached out to the bands themselves to get their thoughts. We are still early in this process, but the response has been encouraging and the benefits to the library in building relationships with folks who are documenting the music scene have already led to physical donations to the archive as well.
It was important to us from the beginning to also consult with Northampton Community Television. NCTV partners with the library on film programming to preserve a record of all they do for the community–teaching filmmaking, lending equipment, training and empowering citizen journalists.. They, in turn, have pointed us to local filmmakers, and through our ongoing collaborations around film programming and the Northampton film festival, we have a platform for outreach in that community as well.
Staff members and local activists pointed us in the direction of other new local radio shows and citizen journalism websites, both of which give personal takes on local politics. One was a wonderful radio show called Out There by one of our bicycle trash pickup workers Ruthie. In a single episode, Ruthie will talk to everybody from the mayor, environmental activists and farmers, to the random junior high kids that she runs into hanging out on the bike path under a bridge. The other recommendation was for a new citizen journalism site called Shoestring which asks common sense questions of people in power in local government and places them in a national context. The folks from Shoestring stopped by the library’s Arts and Music desk to ask about our bi-weekly Zine Club meeting, which gave us an opportunity to talk about including their site in our web archive and led to physical donation to the archive as well!
At numerous people’s suggestion, we are preserving the Instagram account of our gruff looking former video store clerk turned City Council president Bill Dwight. Bill has a great camera, a great eye and has the ability to capture a wonderful cross-section of the community in his feed. Dann Vazquez has an instagram feed dedicated to capturing oddball moments, new building developments and local graffiti, (one of the more ephemeral of our community’s arts) which gives a unique day to day perspective of change on the streets of our city.
 We are a community rich in activism, with a long tradition that, like our LGBTQ history, has not been properly reflected in our archives. For years, the personal and organizational archives of local activists have found homes at the larger colleges and Universities in the Five College Area. Now, by including the websites of long-running and new nonprofits and activist organizations, we are able to create a richer archive for future generations to learn from their pioneering work.
We are a community rich in activism, with a long tradition that, like our LGBTQ history, has not been properly reflected in our archives. For years, the personal and organizational archives of local activists have found homes at the larger colleges and Universities in the Five College Area. Now, by including the websites of long-running and new nonprofits and activist organizations, we are able to create a richer archive for future generations to learn from their pioneering work.
We have tried to remain conscious of what communities are being left out of the collections we are developing, such as the non-English speaking communities with whom we need to improve our outreach and individuals and organizations that might not have a digital presence currently. As we have the ability to offer basic training at the library and through our community partners,we have recently been exploring the idea of creating a website or Instagram account designed to give individuals and organizations the opportunity to try out these technologies without the weight of a long-term commitment, but with the assurance that their content would be preserved among our web archives.
It still feels that we are in the earliest phases of this endeavour, but we have tried to build a collaborative system of curation which could be sustained going forward. By spreading the role of curation across the community, we can prevent staff burnout on the project and ensure that the perspectives represented in the archive are broader, more varied, and thus more reflective of our small city as it is.
Additional credits: IA staff Karl-Rainer Blumenthal who edits the Archive-It blog and Maria Praetzellis, who manages the Community Webs program.