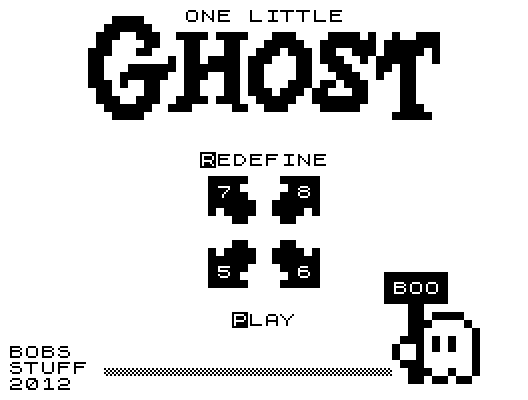A great saga of rescue and preservation is coming towards its end, and there’s a chance to bask in the victory, and help push towards its conclusion.
I got word in 2015 of a collection of manuals inside a business that was getting out of the manuals business, and while a lot of well-meaning people talked a good game, they wanted to cherry-pick (people getting rid of stuff hate cherry-pickers), and I drove down to show I was serious, and after a week of work with MANY volunteers and contributors, we ended up with pallets of documentation inside boxes, tens of thousands of unique manuals, many nowhere else.
Then they were stored in a storage unit. Then they were stored in a closed coffee house. Then they were transported to Internet Archive’s Physical Archive. Then they were stored until last year, 2023.
Last year, a group called DLARC, doing digitizing and indexing projects around ham radio and radio technology, worked with me and the archive to sort four pallets of the manuals for products related to the history of radio/network technology, and off they went overseas to be scanned. And as of this month, the evaluated, professionally-scanned and available-to-the-world manuals are finished, except for a few stragglers.The loop has closed!
You can browse the collection of thousands of scanned manuals here:
The company doing the digitizing does lots of digitizing for the Internet Archive. They are well-paid and legitimate professional contractors who are sent the items, and who do careful scanning to the best of the materials’ ability to provide access to the information, and then do quality checks, and then upload them. When they’re humming, they’re processing a pallet every couple of weeks (with lots of mitigating factors).
I’ve negotiated a situation where, if money is sent in, the remaining pallets that should be scanned can just be sent along without sorting them for DLARC funds, DLARC will fund any that happen to overlap with their mission, and the rest will just be done.
That’s if money is sent in.
How much money? The number approaches hundreds of thousands of dollars. So I’m looking for both big-ticket supporters (who can mail me at jscott@archive.org) or individuals.
If we make less than we need to scan them all, then we’ll only scan up to where it’s paid for. I believe we can close it out, but if the interest/money isn’t there, then it isn’t there – fair enough. Browse the collection as it grows into thousands of manuals as it is and consider if you want to be part of all that. That’s definitely happened.
But what a happy ending it would be to push all these manuals through the process, and close it up. That’s why I’m popping up to talk about it, and why I hope you would consider contributing towards it, for a non-profit that deserves your support generally.
If you’ve ever taken a tour of the Internet Archive headquarters with Brewster Kahle, you’ve likely watched him play a minute or two of the game “Prince of Persia” on our in-browser emulator. While talking through the technology involved, Brewster will press the keys to make the main character run through the dungeons of a kingdom, often dying rather quickly.
Over the years, the area around the “Prince of Persia” station has added additional decorations, including a print drawn by the creator of Prince of Persia, Jordan Mechner. Entitled A Faithful Friend, the print depicts a moment in the Prince of Persia Game where a small mouse visits the captive princess.
Worlds collided recently when Jordan Mechner, in town for the Game Developers Conference 2024 and doing some readings of his new graphic novel memoir Replay, stopped by the Internet Archive for a tour and discussion with Brewster.
This provided a unique opportunity for the creator of a game that Brewster had been playing for years to give him tips to learn how to do a better running jump and get farther along than he had in his many demonstrations on the tour. It can be reported that Brewster was a fast learner and took Jordan’s suggestions to heart.
Jordan was also kind enough to gift a signed copy of Replay to the Internet Archive.
Conversation turned to the Internet Archive’s help in Jordan’s work creating Replay, including images and research for the historical parts of the novel.
During the conversation, Jordan had this to say:
“I appreciate [The Internet Archive] as a graphic novelist and as a game developer. Everything I’ve done throughout my life has been based on inspiration that I get from other things and on research that I’m able to do. When I went online to write and draw this 320-page book about game development and about my life and my family’s history, I looked for visual references of everything from old postcards and photographs to video game consoles.”
“I wanted to draw the floppy disk caddies and 1970s movie posters I had in my office in Brøderbund when I was making the first Prince of Persia on the Apple II. And where could I find a 1983 April issue of Softalk magazine, which is how I learned 6502 assembly language programming? So many times, when I searched online, it was the Internet Archive that came through.”
Brewster agreed:
“Well, I’m glad we’ve been useful to you, but also thank you for going and being a model for taking something that’s very, very popular in the past and making sure that it makes it to a generation that is going to download it from GitHub and play with it and mod it and do something else with it. And you’re welcoming of that next generation, living and growing with your work.”
And Jordan couldn’t have been clearer:
“And I will say that I don’t feel harmed by that. A few years ago somebody took the time to port Prince of Persia to the Commodore 64, which the publisher had no interest in doing in 1989, because the Commodore 64 was already outdated as a platform. Even the Apple II was on its way out. But somebody has done it now just out of love, out of its challenge, and the fact that the source code was available made that easier, I hope.
“Making things available to this generation. They’re going to do weird different things with it, especially if it’s not a permission-based society. But that’s what creativity has always been based on.“
Jordan acknowledged: “Copyright law exists and was created to protect the incentive of creators to work really hard at making something. So that if someone makes something great against all odds and it gets out there and sells a lot of copies, they can make money from it. But at a certain point, things that have been created need to then be used by other people to make their versions of it. The games and movies that we love, operas, films made of the works of Shakespeare, are building on creations of the past.”
There was one last reunion in the visit: Years ago, the Archive was donated a travel case (for trade shows) used by Jordan’s game publisher, Brøderbund Software. It currently lives in one of the Internet Archive’s guest rooms, and Jordan got a quick selfie with a piece of his own history.
In October of 2022, the DISCMASTER site arrived, providing amazing semantic search of thousands of shareware and compilation CD-ROMs at the Internet Archive. In the entry written on the blog back then, the advantages and features of this site were pretty well enumerated.
Unfortunately, the site went down in June of 2023, due to a number of factors, the most pressing of which was a need to switch hosting and administration duties. (It is not run by Internet Archive and is not hosted at Internet Archive’s datacenters.)
However, DISCMASTER HAS RETURNED!
Thanks to a set of generous donors and the efforts of multiple volunteers, the site is back running with all the data and functionality it had in its previous incarnation.
The previous blog entry has fuller details on the meaning of this site and the many uses it has for computer and internet history. All hail DISCMASTER!
One of the Internet Archive’s most viral tweets/toots/skeets happened at the start of 2024, with the announcement/reminder that the Disney short “Steamboat Willie” had entered the public domain just moments before. We have a copy of the film online for everyone to play or download.
Within a short time, even as the hour of midnight of January 1st moved across the earth, countless creations based off the Steamboat Willie character, ranging from the sublime to the profane, rocketed into the Internet.
Along with the flood of images have come a flood of articles and overviews of the legal and other ramifications of a public-domain Mickey Mouse. These are written by very smart people who have spent a lot of time considering these issues.
There’s no point is restating what these and many others are describing (Only Steamboat Willie’s design is public domain, Disney may utilize trademark law like a large hammer to enforce as firmly as they did their copyrights, etc.)
Instead, a few words about the creative ecosystem.
As a variety of slasher movies, costumes, crypto tokens, fan-fiction creations and general meme images of Steamboat Willie cascade into the first parts of 2024, it’s worth noting how the entire situation will feel unusual or a controversial subject to a number of folks.
What it is, however, is a too-long-delayed part of a natural process of works and copyright. The implementation of universal involuntary copyright that then lasts longer than the vast majority of human lifetimes means a disconnect, a vast gulf between the life of creative works and when they become a part of culture at large in anything other than a consumption relationship.
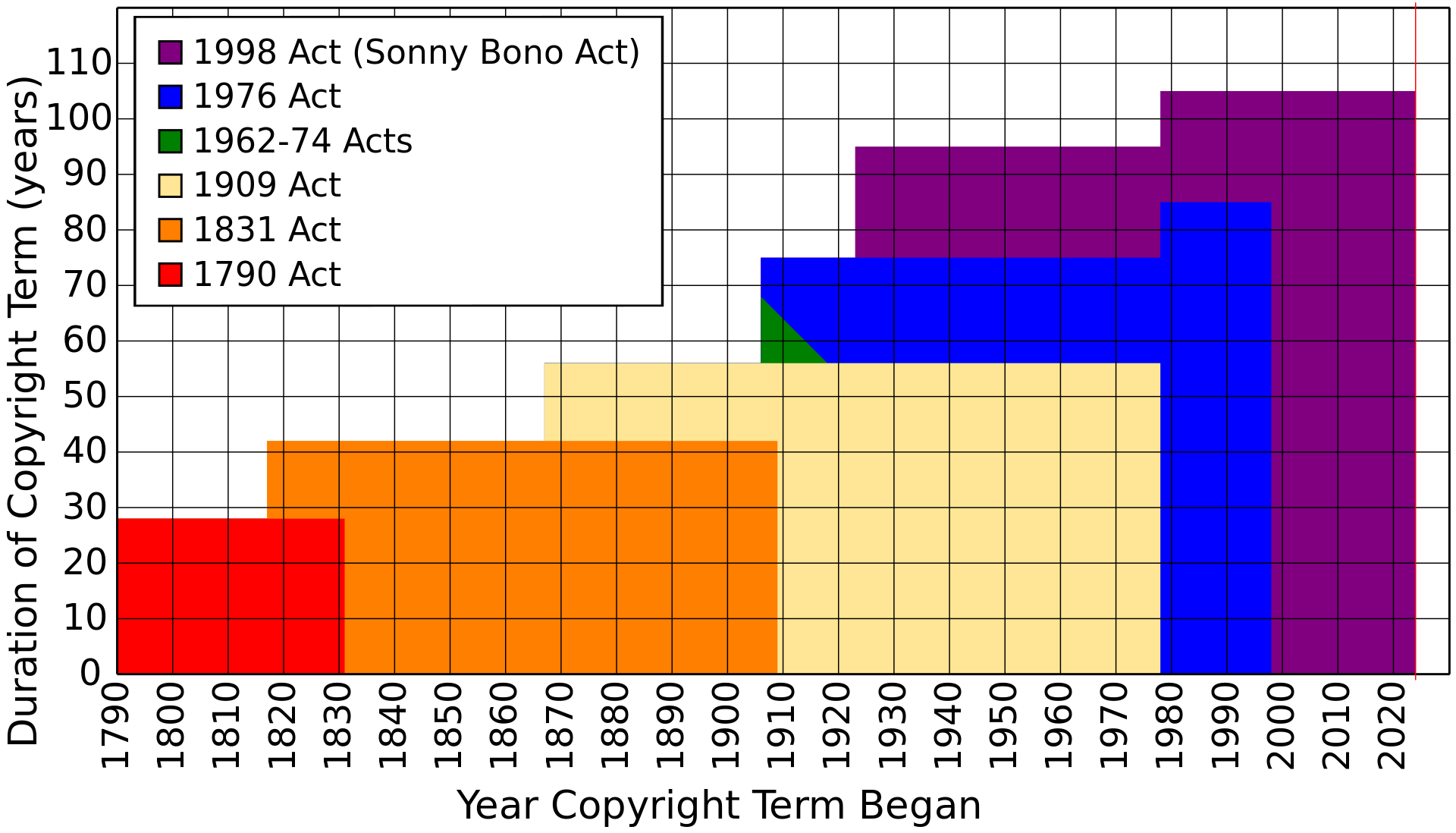
Copyright in the US (and via the Berne Convention and other lobbying, worldwide) has been increasingly extended over the years, often following the impending expiration of the Steamboat Willie copyright, and it has done so in the face of a 20th century that knew much shorter terms (and which led to works such as Pinocchio being used by companies such as Disney after they expired into the pubic domain). As a result of this, we’ve lost the rich ecosystem that creative works grew from, the back-and-forth, parody and reference and re-imagining that existed in previous generations.
The time extension of copyright, from 14 to 28 to “75 years or life of the author plus 50 years” to the current “95 years or life of author plus 70 years” has been a rapid expansion that has swallowed many creative works, and, combined with automatic copyright, has effectively ended a long-rich and held system of creations that could reference near-contemporaries in their works beyond the scope of parody or (often disputed fair use). What was a rich environment is now a rather dry landscape.
The ramifications of this have been many, but one of the most striking has been preservation – with works whose corporate or anonymous creators are undetermined, there is very little incentive to invest in their upkeep and maintenance, meaning that many early works tend to disappear in percentages that are heartbreaking for their size: half of all American films made before 1950 and over 90% of films made before 1929 are lost forever [cite].
That excellent copies of Steamboat Willie still exist are owed mostly to Disney’s own efforts to keep their materials under control and locked down for nearly a century. Steamboat’s fellow members of the Class of 1928 will not, ultimately, be so lucky. Each successive year of items released into the public domain will have a few “stars” to make the news and receive the artistic references that Mickey is getting this month – but hundreds, maybe thousands of works from the same year may never again see the light of day.
So, let us celebrate this temporary oasis in a truly barren landscape, and work, through preservation and protection for libraries and archives, to ensure each year is a more exquisitely complete and maintained ecosystem.
10 years ago, the Internet Archive made an announcement: It was possible for anyone with a reasonably powerful computer running a modern browser to have software emulated, running as it did back when it was fresh and new, with a single click. Now, a decade later, we have surpassed 250,000 pieces of software running at the Archive and it might be a great time to reflect on how different the landscape has become since then.
Anyone can come up with an idea, and the idea of taking the then-quite-mature Javascript language, universally inside all major browsers and having it run complicated programs was not new.
With the rise of a cross-compiler named Emscripten, the idea of taking rather-complicated programs written in other languages and putting them into Javascript was kind of new.
That all being the case, the idea of taking a by-then 20-year-old super-emulator called MAME, using Emscripten to cross-compile it into Javascript, and then running the resulting code in the browser at Internet Archive to make computers and consoles run, was very new.
It was also, objectively, madness.
Well over a thousand hours of work went into the project from a very wide range of volunteers who poured galactic amounts of time into making the project a reality. Along the way, changes were made to Emscripten, the Firefox, Internet Explorer, and Chrome Browsers, MAME, and the Internet Archive’s codebase to accommodate this dream.
Additional announcements came with each expansion of the types of software being emulated, and it became huge news, leading to millions of visitors coming to try this it out.
By any measure, a quarter of a million items later, it has been a huge, huge success.
The rest of this blog entry is pretty pictures and beautiful links, but before we move on, it’s once again important to highlight people who provided major contributions, including Justin Kerk, Daniel Brooks, Vitorio Miliano, James Baicoianu, John Vilk, Tracey Jaquith, Jim Nelson, and Hank Bromley. Dozens more developers spent evenings, weekends, and months to make this system happen. Thank you to everyone involved.
The joy of watching a computer boot up in the browser was (and is) a miraculous feeling. And after that feeling, comes a quick comfort with the situation: Of course we can run computers inside our browsers. Of course we can make most anything we want run in these browser-based computers. What’s next?
Within a short time after our 2013 announcement, the archive was running hundreds, then thousands of individual programs, floppy disks and even cassette-based software from computing’s past.
As emulators besides MAME were added, it became necessary to create a framework for a versatile and understandable method to load emulators. This framework eventually got a name: THE EMULARITY.
In the decade of the Emularity’s existence, the Archive’s software emulation has expanded into directions nobody could have fully expected to work when the project started.
Here are some highlights:
Hypercard Stacks for the Apple Macintosh, a critical period in content creation and computer information architecture, have been restored to easy access, surpassing thousands of hypercards to try instantly.
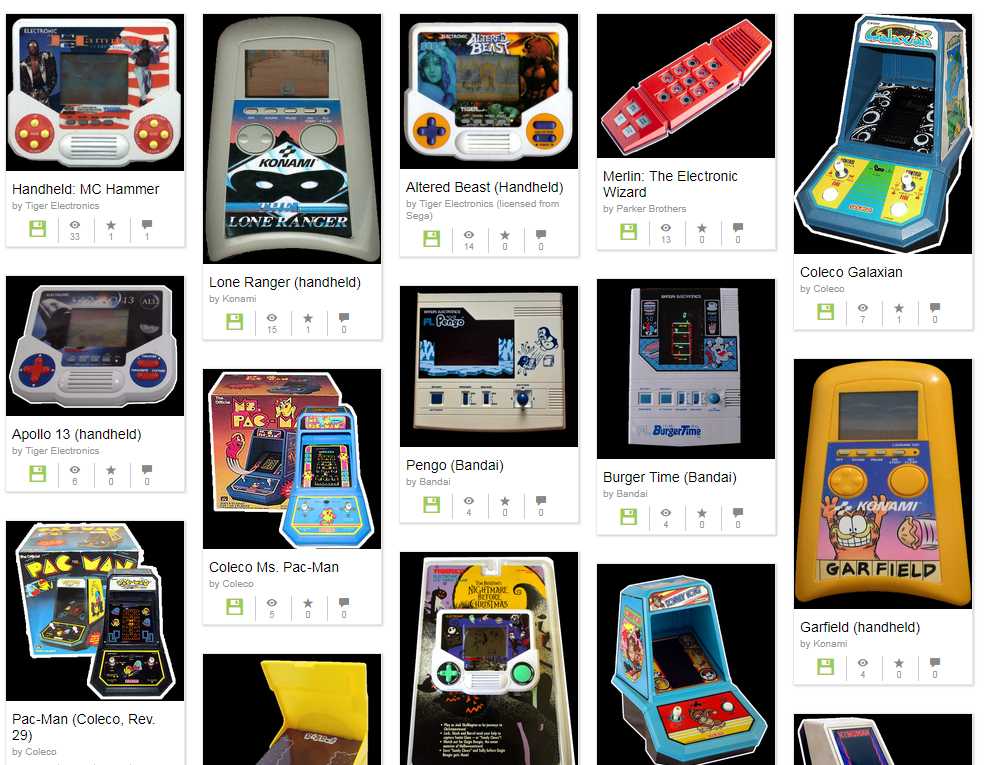
Plastic Electronic Handheld Games, once a staple of toys in the 1970s through the 1990s, have been able to live once again as, including the original housing that these simple (and not so simple) machines relied on instead of graphics.
As the uploads veered into the many thousands, it became more and more difficult for new adventurous users to figure out what, if any, software was at the archive to check out. This has led to specialized collections focused on one type of program, like the Computer Chess Club. People can use these collections as gateways to quickly testing the waters of now-decades of computer and software history, seeing the turns and twists of countless lost companies and individuals who squeezed every last bit of wonder and spectacle out of these underpowered boxes.
The Calculator Drawer took things to a new level when entire calculators could be emulated, including their unique looks, accompanied by a “drawer of manuals” to browse through if you had to learn (or re-learn) how to make these machines run.
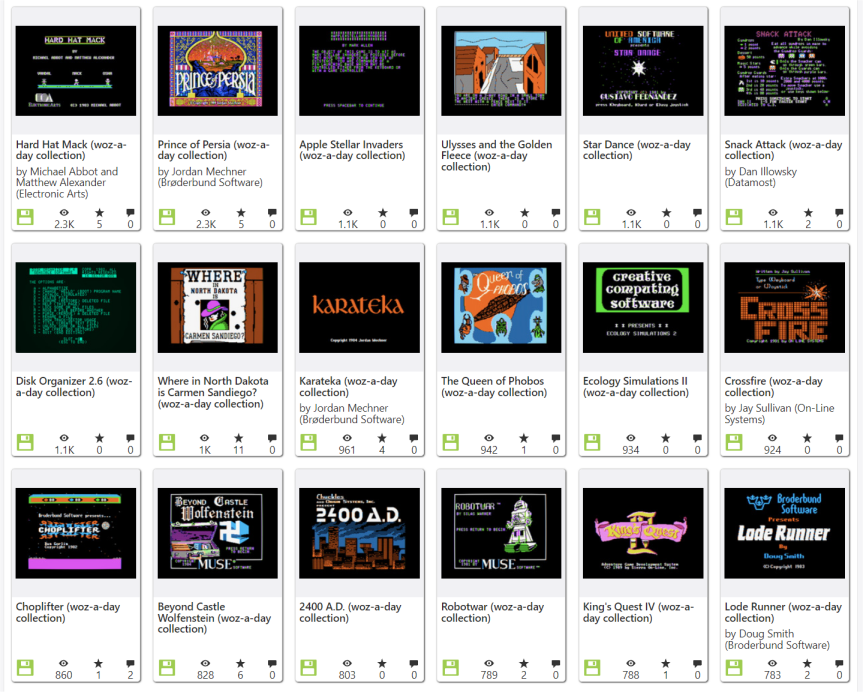
The Woz-a-Day Collection, in many ways, represents the logical end for the role that the Internet Archive’s Emularity can provide for software history. The project is the effort of the software historian 4am, who has spent years on its maintenance. Methodically preserving Apple II software from the original floppy disks, incorporating every last bit and track of the disks with no modifications, and allowing the best fidelity of these programs as they originally were offered, 4am allows some of these programs to be playable for the first time in decades.
With each new batch of added emulated systems and machines have come a greater and greater pool of users, toying with historical software or playing long-forgotten or never-remembered games with a new level of convenience and willingness to try them out.
At this milestone of a decade into this experimental adventure, Internet Archive continues to grow its collection, to test and automate the functioning of both uploaded and self-maintained collections of software, and to provide a vast and necessary service in the preservation of historical software.
While there are plenty of items at the Internet Archive that have no obvious home elsewhere online, there are also cases where we hold a copy of a frequently-available set of material, but we can provide it for much easier distribution and preview, including the ability to download the entire original set of files in one fell swoop.
Such it is with the USC SOUND EFFECTS LIBRARY, a collection of .WAV files taken from rapidly crumbling magnetic tape and presented for reference, enjoyment and even projects.
The world of sound effects is two-fold interesting:
There’s the interesting way we use recorded sound, cut together from various sources and even spliced from organic and generated sources, to provide the audio soundtrack for visual experiences in a way the audience thinks sounds “natural”.
And there’s the actual process of sound effects, of engineers going into the field or into a studio and generating sound after speculative sound, trying to find just the right combination of noise and speech to create just what they might need in the future.
As long as there has been performance on the Radio and to mediums beyond, the generating of sound effects live and recorded is a fascinating skill, shared among many different people, and is rightly considered an awards-worthy occupation. While not everyone is fascinated at this sort of work, many people are, and there’s a childlike delight in going through a “sound library” of effects and noises, getting ideas of how they might be used later.
As explained in a blog entry written by Craig Smith, a variety of tapes called the “Red” and “Gold” libraries of recorded sound effects were joined by a third set from a sound company called Sunset Editorial, who worked on hundreds of films over the years.
This collection has now been mirrored at the Internet Archive.
In the USC Optical Effects Library are over 1,000 digitized tapes of sound effects, including not just the sounds themselves but the voices of many different engineers bracketing them with explanations, cajoling and call-outs while they’re being made. We hear not just a dog panting, but an engineer talking to the dog that they’re doing a good job. Some recordings clearly have a crew sitting around while recordings are being made, and they hush with the sound of professionals knowing they can’t just edit the noise out if they talk over it.
There are machines: Planes, Cars and Weapons. There are explosions, fire and footsteps. There’s effects just called SCIFI or MAGIC, where the shared culture of Hollywood’s take on what things “sounded like” makes itself known.
The pleasant stroll of “just playing” the effects in our browser-based player belies the fact that at one time, this was magnetic reels, sliced with razors and joined with tape, used to remix and reconstitute environments of sound for entertainment. The push to digital allows for much more experimentation and mixing without generational loss and huge amounts of precious time, but in these versions we can hear how much work went into the foundational soundscape of entertainment in the 20th century.
Craig Smith, who made this collection available, goes into great detail in his blog entry about how fragile these tapes had become before being transferred, and how some were lost along the way. Folks unfamiliar with “Sticky Shed Syndrome” and the process of “baking tapes” will be surprised to know how quickly and dramatically tapes can fall apart after a passage of time. With large efforts by a number of people, the amount that was saved is now available at the Archive.
There is extensive metadata in each item, captured as spreadsheets and documents about the assumed sources or credits of the sound. They’re important to bring along with these noises if a patron wants to maintain a local copy.
Speaking of which.
In this collection is a massive compilation of all the data related to the project. It’s located in an item called “Sound Effect Libraries (Red, Gold, Sunset Editorial)”. Patrons whose immediate urge is to grab their own private set of the data to keep “safe” will want to go to this item, using either the direct download of the three .ZIP files inside, or to click on the TORRENT link to download the 20+ gigabytes of files. Depending on your bandwidth, it will take some time to download, but you can be assured that you got “all” the data from this amazing collection. This, in some ways, is the Internet Archive’s greatest strength – direct access to the original files for others to have, instead of adding a layer of processing and change as the presentation mediums of the day require modification for “ease”.
Patrons come to the Internet Archive’s software collections for many reasons, and among the major reasons are some manner of playing historical software in our in-browser emulation environment. Well over a decade old now, the Emularity gives near-instant access to functional versions of what would otherwise be dormant software packages. If a patron wants to go from idly thinking they’d like to try something to playing a 2011 Pac-Man clone running in an obscure DOS graphics resolution, they can be experiencing it in anywhere from seconds to under a minute.
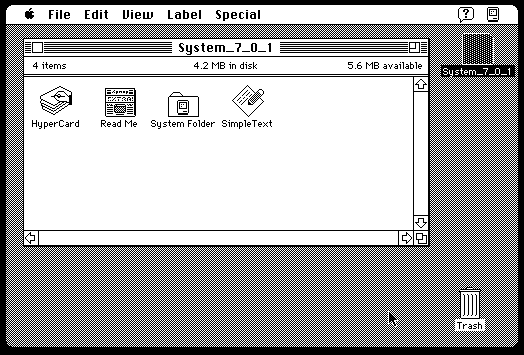
Naturally, “near-instant” is a nebulous, and inaccurate, portrayal of the time required to spin up the Emularity’s environment – a Webassembly runtime with an emulator embedded in it will come through, followed by whatever the total time to download the software itself afterwards. This playable version of Apple Macintosh System 7.0.1 requires 10 additional megabytes to download the hard drive image it is booting. That data will either snap down instantly on your fast connection, or be achingly slow on a less robust one.
Cooked into everything digital and online this present day is the fact that speed and efficiency win out over authenticity and reality. We go from thinking we’d like to hear a piece of music to hearing it (or never hearing it, as we can’t find it), in brisk flashes, a few clicks and a momentary pause. But listen to a track of music written decades ago, and a mass of assumptions by the creators of how you would experience these works no longer apply.
We’re not indicating the only way to enjoy Dark Side of the Moon is to see it mentioned in a magazine or fanzine in 1973, wander down to your local record store, see them stacked up near the front of a rack, and then buy one and take it home, gently unpacking the stickers and poster while playing the album in headphones or on speakers, cross-legged on your shag carpet.
…but they probably thought you were going to at the time.
Such it is, in the emulated world of software, that the way these works will be primarily enjoyed through all of time to come is as discrete blocks, loaded into a waiting process or slot, and then turned on moments after being selected. This is right and good – it’s a decent argument that many people would not want to sit through the “realistic” amount of time it would have taken to boot up software at the time of its release.
But maybe some of you do.
Most people who use computers know that they once loaded from floppy disks, plastic cartridges with magnetic plastic rings inside that could hold some small amount of data. Slow, weird, but the aesthetic experience of the floppy disk has, to some small amount, bubbled up into the present day. It’s seen as a “save icon”, or a reference to times long past, and there’s even a notable amount of “old floppy disks” found in family storage, where younger generations find them in the same way you might find an old smoking pipe or a saved wedding invitation.
But nestled in a relatively short span of time is the era of cassette-based loading, where actual audio tapes could have data stored on them, and played back to load into computers.
In terms of adoption, the cassette-based software period is marked by people entering it and almost immediately clawing their way out of it as soon as they can afford to. The combination of time consuming playback, limited data storage, and lack of read-write ease ensured that as soon as anything better came along, a user would leap to it.
As a result, it has become the case that not only are there people who consider themselves computer enthusiasts who have only a light glancing memory or awareness of cassette-based software – there are people who are not aware this ever even happened.
So, let us begin.
In the wild and wooly days of kit computers, where one of the major options was to be sent a pile of parts and instructions to screw, solder and assemble them into a functioning beast, the option of saving your code into a cassette tape machine was one of the possible storage options. And by “cassette tape machine”, we’re bringing back a dozen memories of schoolchildren in the 1970s:
And this is exactly what it sounds like, using the headphone and microphone jack of these machines that would normally provide language education and field recordings, and attaching them to circuit boards either recording to or listening to standard audio cassettes.
So, an expensive ($27.99 is $151 in today’s dollars.) machine to hook up but due to the dropping costs of blank cassettes, themselves manufactured in the millions to satisfy a range of customers, you could now tinker and toy on these computer kits and save out your digital creations to a medium with a fairly high chance of recovering them again.
Combine the simplicity of the programs involved, the often-cheap tape medium being bought, and the use of labelmakers to create adhesive labels to describe the inside program, and you get a very memorable, very evocative 1970s-1980s aesthetic that will either confuse the new or warm the heart of the old:
As a side note on our introductory tour, it would be possible to save multiple programs on these tapes, but you had to be verycareful about where on the tape counter each program was placed, so your works didn’t override each other, an art far above the head of the impatient or unwilling to rewind to the beginning of the tape and carefully watch a rising counter number to find fresh fields of data.
And the result, not obvious otherwise, are these glyphs providing you a possibly cryptic map of “dumps” (writing of the programs into the tape, following the counter as you would go). Note how in the label, a failed/broken program has to be left where it is on the tape; a combination of hearing the old program under an overwritten one, as well as not being able to predict how many feet down the tape a new program will take, means the road to data dumps is littered with broken memories.
But what is exactly ending up on these audio cassettes (now considered to be data cassettes, or datasettes)?
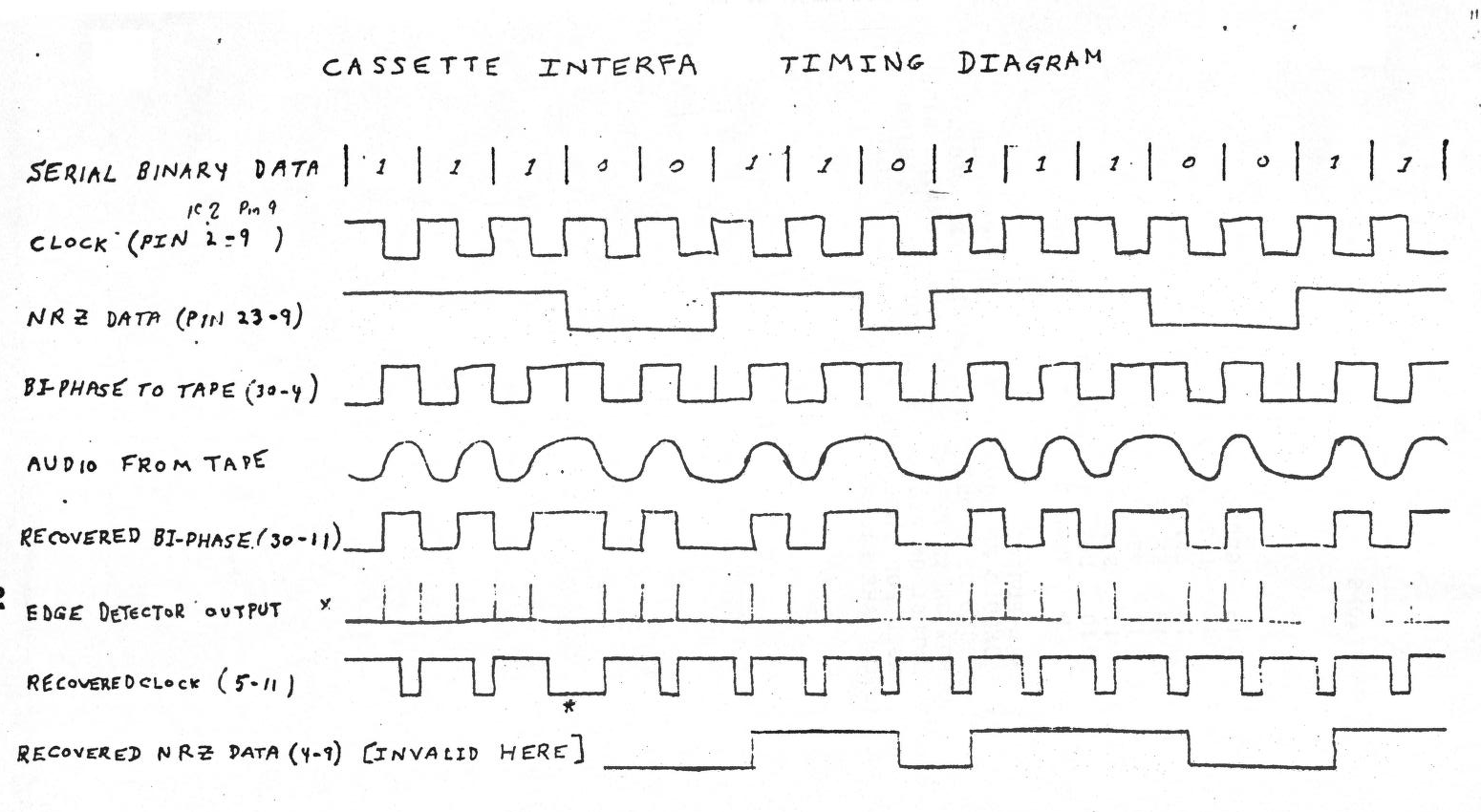
Particularly curious folks can read up about examples like the Tarbell Cassette Interface and Protocols here in the bitsavers collection. But in more general terms, a variety of standards (and not-so-standards) had emerged where pulses of sound went onto an audio cassette, and these sounds reflected individual data that could then be interpreted coming back off the tape. The distinction is important here – these were not digital signals, but digital information encoded as analog/audio recordings. Think of someone shouting the word “42!” instead of digitally encoding up-down on-off data like “101010”.
The questions that might come to mind are probably myriad.
This sounds like it’s incredibly slow. Why yes indeed. The tarbell format/interface linked above brought in data at a screaming 187 bytes per second, that is, a couple short sentences worth of words. Compare that with a capability of 200,000 bytes per second of an early floppy drive and you can see why people would jump. (Naturally, modifications to the Tarbell format and alternative cassette tape electronics could increase the transfer rate to 540 bytes per second and above, but you’re adding complications.)
What even is a “Tarbell”? Oh, you mean Mr. Don Tarbell, creator of the interface in question, who wrote an extensive article about his work in Kilobaud magazine. (RIP to Mr. Tarbell, who died in 1998.)
Won’t it take a very long time to dump and read this data, at such a slow speed? Why, yes! That is the crux of this already-long article, coming up.
Is this the only way people ended up saving and loading data to cassette tapes? Why, no!
In the late 1970s-early 1980s, a myriad of cassette-tape based storage systems started being sold as an option for the “home computer” market, the plastic-wrapped, cheaper but all-in-one-already-built computers being sold by various companies in a bid to become dominant in the market. (Even the ultimately-winning IBM PC had a cassette port, although the system was generally sold with a floppy drive and it’s unlikely any significant number of people used it.) Each of these systems had slightly different approaches to how they wrote data on tape, and read it back, with speed differing notably between them.
By the late 1980s, it was rapidly becoming unusual to depend on data tapes to read and load to home computers, and the jump to floppies and ultimately hard drives and CD-ROMs came with mass adoption in the 1990s.
But it wasn’t completely gone, either.
In this zone, this Venn Diagram of a market of computer end-users with this exhausting set of possible media input devices, commercial creators had a heck of time. Intent on reaching every market they reasonably could, multiple formats meant multiple releases of the same programs.
Does this mean that Activision had to spend the money to make a floppy disk version and a computer cassette version of the game Ghostbusters for Commodore 64? Yes, in fact they did. (One distributor, HES, even made a cartridge version, which was an Australia-only hack that put the contents onto a cartridge and forced a loading as if it was a floppy.)
For someone playing these games, the choice (or lack of choice) of medium meant their memories, experiences and consideration of the programs was very different, reflections of what configuration they could afford.
All these moments of time, washed away like spools of tape.
…unless you seek them out.
Emulation at the Internet Archive is designed to be fast, easy, and a snap between first thought and trying the software out. In general, this is the case; you decide you want to play a game and a very short time later, you’re playing that game.
This is an absolute gift, if your intention is to browse a lot of obscure, weird, or possibly-bad games, giving them minimal amounts of time while discovering what you were looking for. With a few clicks, you run down the massive lists of potential stops, watch the program come up, and give it a quick regard as to whether it’s worth your time or what you were seeking. As a finding and exploratory environment, it’s the way to go.
This comes at a cost, one which a lot of media/content is experiencing, now – your personal investment (time, patience, effort) is miniscule, meaning you will probably switch away in milliseconds if anything is annoying or non-intuitive. Annoying sound? Hard-to-figure-out key mappings? Slow title screen? Onto the next thing.
Loading cassette tapes of data is slow, slower than a modern person might consider reasonable. By using a variety of tricks, providers of older data tried to mitigate this by converting tape data, which would be a slow drip of data, into a single finished, packed set of instructions. The Z80 format, for example, is the result of a snapshot of the memory banks of a Sinclair computer, so if you visit the stacks of Sinclair ZX programs, you’re not loading in data the “old” way – you’re spinning up an already-loaded machine that is just starting off from the moment it all finally loaded in. Dropped off at the finish line, it still feels reduced in speed from today, but that’s just the (intended) experience of the machine it is running on.
Two platforms at the Internet Archive currently provide the experience of loading programs from cassette tapes: The Sinclair ZX-81 and the Commodore 64. Both of these home computers flourished in the early 1980s, with use of them continuing longer based on the available hardware to users up until the 1990s. The ZX-81 itself faded before the C64, and the C64 saw transition to a (slow-reading) floppy drive that made cassettes fall out of favor as the decade moved on.
In both cases, there is the original data provided in a straightforward file; for the ZX-81 a .p or a .tzx tape data compilation, very small and compact. For the Commodore 64 cassette version, a .tap file with the information less compact, because the programs on the Commodore 64 could be significantly bigger.
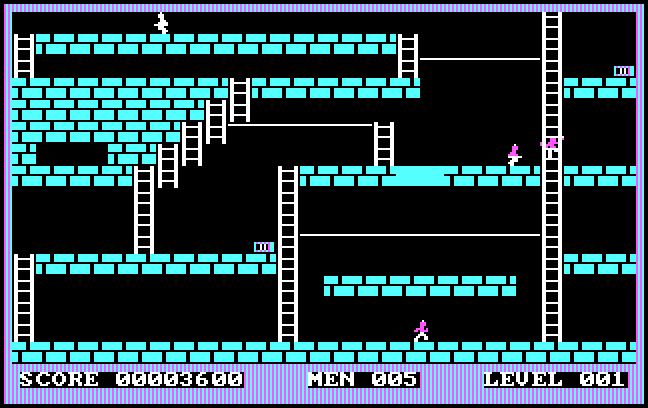
To this extent, loading a program on the ZX-81 emulation can be demonstrated on the program One Little Ghost, a 2012 retro-make version of Pac-Man that stuffs a whole lot of game into a very limited system. Going to this emulation and starting it, you are faced with not an instantly loading, black and white remake of Pac-Man, but this:
Incomprehensible! Mysterious! Uninformative! Welcome to home computing in the 1980s!
This is the gap between today’s fast-food version of computer history, and trying to get things running in the original days of the hardware. We’re not even addressing the peculiar aspects of the ZX-81’s RAMpack, an externally attached device for increasing memory, that was legendary for just falling off while using the machine.
To make this interaction of software-emulated machine and actual machine at all clear, instructions were added to the items added to the Archive’s collection, including this intimidating set of movements and keypresses to be able to set a cassette loading:
“Currently, emulation for this item does not auto-start. To load the ‘cassette’ this program is located on, press the following keys: j (which will appear as LOAD), shift-p shift -p (Which will appear as double quotes) and then ENTER/RETURN. Then press SCROLL LOCK on your keyboard, and the F2 key. If all is working properly, the system will bring up a box showing the cassette tape loading into memory. It will stop when complete and the emulation can be interacted with normally. Some games will run by themselves after cassette loading, while others can be started by pressing the r key and ENTER to run.”
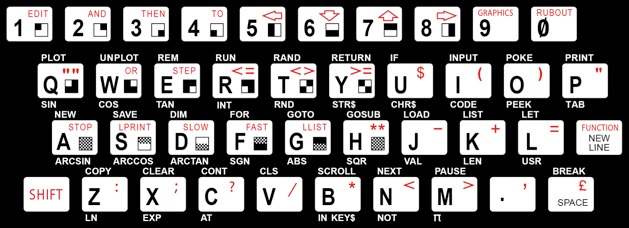
As one last piece of intimidation, the instructions have to include a picture of what the ZX-81 keyboard even looked like:
Once you negotiate the instructions, press all the requested commands, and sit back, the emulation rewards you with a screen not unlike this:
What is happening here is an honest-to-goodness cassette loading sequence. The constantly flashing graphics are an ancient hack to allow the end-user to know things are “working”, that the data is being successfully read off the tape. An additional convenience is provided by the emulator: on the top left is an overlay window indicating that it is 16 seconds into the loading of the data, and that there are six minutes and fifty-two seconds of loading to be done, for a total of 412 tape tick counts. Yes, you are reading that correctly: loading this program will take seven minutes of real time.
Perhaps it becomes obvious why so many shortcuts begin to arrive in emulation and why so many people were willing to spend the equivalent of a short vacation to bring their machines into the floppy age.
You can browse the ZX-81 collection of programs and see preview screenshots of the games. The good news is that a human didn’t generate them – a script called SCREENSHOTGUN started up, “pressed PLAY on the cassette player”, and then waited until the whole thing was loaded, and then removed most of the “loading” screenshots to bring you the result. That is a lot of saved misery.
Which brings us to the Commodore 64.
The Commodore 64 stands to live in fame forever as the most-sold, unchanged home computer in history. From 1982 to 1994, with no substantial changes in its configuration or capabilities, the C64 plowed on through multiple generations of industry standards, providing an inexpensive and dependable on-ramp for families and individuals to acquaint themselves with this “computer in the home” nonsense taking over the general populace.
While much can be made of its shortcomings, most of these have faded into a quaint memory of working around them. The breadth of software, the utter domination of understanding of the ins and outs of the machine’s quirks, and the toil of many millions of users means that the Commodore 64 is a giant in computer history.
And to that end, a group has been working hard to preserve that most odd, increasingly rare-to-find subset of C64 works: the cassette-based commercial products that flourished in the beginning of its life.
And here we find ourselves, a significant number of paragraphs later, to what inspired this walk down tape-loading memory lane: the forgotten minutes-long time of the experience of loading these tapes on the Commodore 64, and the many different ways that companies tried to keep buyers from restlessly complaining the tapes weren’t “working” and giving up before the long loading times revealed the programs.
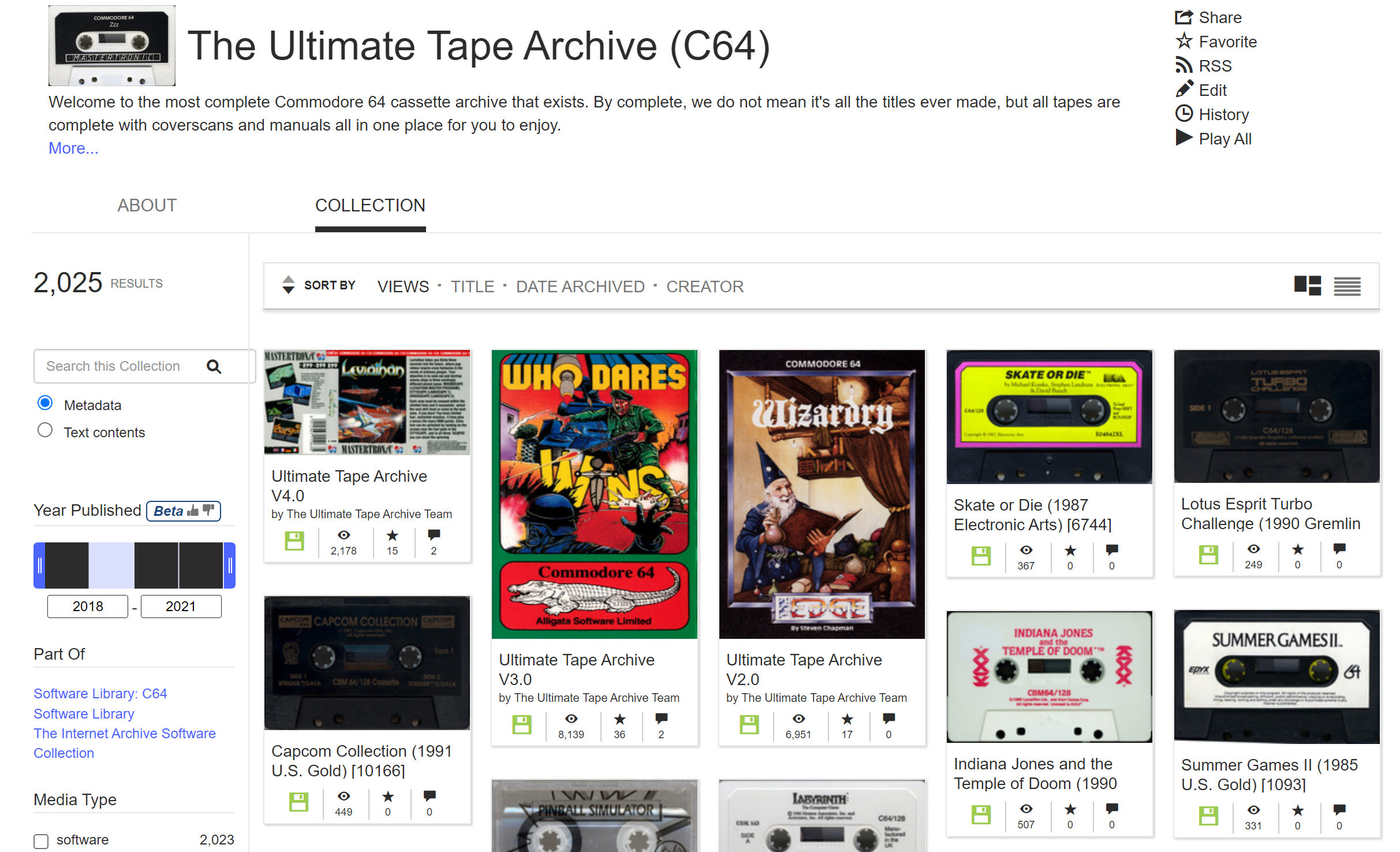
The Ultimate Tape Archive is an effort to preserve these cassette-based titles, including the data on the tape, scans of the tapes themselves, and of the cassette case inserts, papers inside the case, that provided instructions or cover art. The group behind this project have been tirelessly approaching the acquisition and preservation for years, and as of this writing, version 4.0 contains over 2,000 individual tapes.
To honor their work and provide the final step in experiencing them, it is possible to visit the Ultimate Tape Archive on the Internet Archive and emulate these items in the browser. Doing so, however, will be committing the slow burn, the steady and time-consuming cassette loading of the programs.
Luckily, for this essay, a machine stepped forward to do the work.
Utilizing the SCREENSHOTGUN program, the thousands of cassettes from this collection were “inserted”, “loaded”, and “played”, over the course of a month, to allow a later quick assessment of the experience of loading them. The reasoning behind this was that companies employed not just clever, but inspiring ways to distract end-users.
What follows are some of the highlights.
In most cases, the loaders will use the same trick we saw with the ZX-81, except with color: a rapidly pulsating, moving set of lines reflecting that something is happening, and data is coming in. A sense of “hold on, everything is working”, not requiring a lot of machine time to provide, and swapping between colors for a few minutes before a burst of music and graphics came at the end of a reward.
The main variations are the use of different lines or arrangement of lines to reflect this. For example, this thinner and more “high resolution”-feeling version:
This was more than sufficient for most cassette-based titles. But some wanted to go a little further to inform the user.
A significant upgrade was adding a sort of “loading screen” to the process, where the lines would still move, but around a “title card” that informed you what was “coming soon” to your computer. Some had nice graphics to accompany them, representing some attempt at recreating the printed artwork on the cassette insert.
An impressive upgrade, but not something to leave well enough alone to a generation of tinkerers.
To give an answer of “are we there yet?”, some titles included calculated countdown timers to tell users how long they had to go before the game would go:
And again, this would have been a favorable solution to the “sit and wait” problem, but a handful of instances exist of the most rare of tape-loading systems: The Loading Games. Games that would be booted up by the system, that would then load the actual programs in the background while you played an amusement, either a song or a smaller game while waiting.
These are harder to discern using the screenshotting system, but a few are clear:
Perhaps not surprisingly, this clear and available innovation in software loading was ignored when Namco created a “play while you load” system in the 1990s, and they were granted a software patent that killed innovation in the bud for years. The epic story of the software patent for a game while waiting for a game to load was covered extensively by the Electronic Frontier Foundation upon its expiration in 2015.
We are, as a whole, incredibly lucky at how the state of in-browser emulation, built on open standards and persisting through most modern browsers, allows us easy insight into historical software and either experiencing or re-experiencing these bright lights of brilliant code. But we must also realize that a lot of what we are interacting with in the present day are, top to bottom, towering piles of shortcuts and “we’ll just skip ahead”, trying to accommodate a type of user that has no time or patience for how things were once. And this new type of user, ignoring or unaware of the lost minutes any choice could be, find it harder and harder to relate to what came before, the environment that those creations were made in.
Perhaps if you have a spare few minutes, a lull in your day, you might consider browsing the stacks of the Ultimate Tape Archive and finding a compelling cassette tape cover, look over the JPG scans of the cassette inlay and printed instructions, and “press play on tape”, feeling some moments of anticipation as another gifted person’s efforts provided you with a chance to experience a very complex joy emanating from a very simple machine.
In June of 2020, facing a range of challenges, we posted a host of information about how you could help the Internet Archive through difficult and pressing times.
Pretty much all of the suggestions and links in that essay still hold up and are relevant this month as well, and we are the Historical Web people, so here is a full link to that post again:
The start of the pandemic in 2020 had immediate effects on the Internet Archive, especially regarding the San Francisco-located headquarters.
A bustling building full of many dozens of simultaneous projects and conversations became an empty shell. The whole world was grappling with the new situation, and for the Archive, it meant many of the all-hands meetings were moved to strictly online, using Zoom conferencing. We learned fast to be online-first, where we remain currently.
There was one small glimmer of light in this darkness.
It was decided to hire artists to give pre-meeting musical performances at our weekly all-hands. This would add a bit of uplift to the morning gatherings, and allow musicians who had lost access to public performances to make a little income and share their music with a grateful audience of dozens of Internet Archive employees. It was a rousing success, and performances were added to our Friday Lunches as well.
The variety of musicians and performances have been amazing: Instrumentalists, Singers, Dancers, and a breathtaking spectrum of styles and acts have made an appearance on our (virtual) stage.
As was covered in a blog post in 2020, all sorts of great stories and opportunities to learn about these artists have been added to the record. The artists were asked if the Archive could archive their performances, and many have agreed.
Some performers are clearly adjusting to their new circumstances, while others have created entire “online stages” for their performances. All of them show remarkable talent and resilience in willingness to do this strange “gig”, and we’ve even had repeat performances over the years.
We continue to enjoy the creative spirits that start our all-hands, and if you didn’t know about this growing and enjoyable collection… you do now.
Stop by anytime. And note that many of these performances have links to directly support the artists; please do if you can.
It’s time to add another family of emulated older technology to the Internet Archive.
The vast majority of platforms within what we call The Emularity happens because of the work of MAME Team, which has spent over 25 years adding support for tens of thousands of machines, platforms, and tools to their breathtaking system. The amount of arcade machines and computers they now cover is so huge, a site exists just to keep track of what they don’t emulate… yet.
While we have an excellent family of emulators assisting MAME in making programs work in the browser, the vast majority of the items in our Internet Arcade (and Turbo Edition), Console Living Room, and Handheld History collections mostly have MAME to thank.
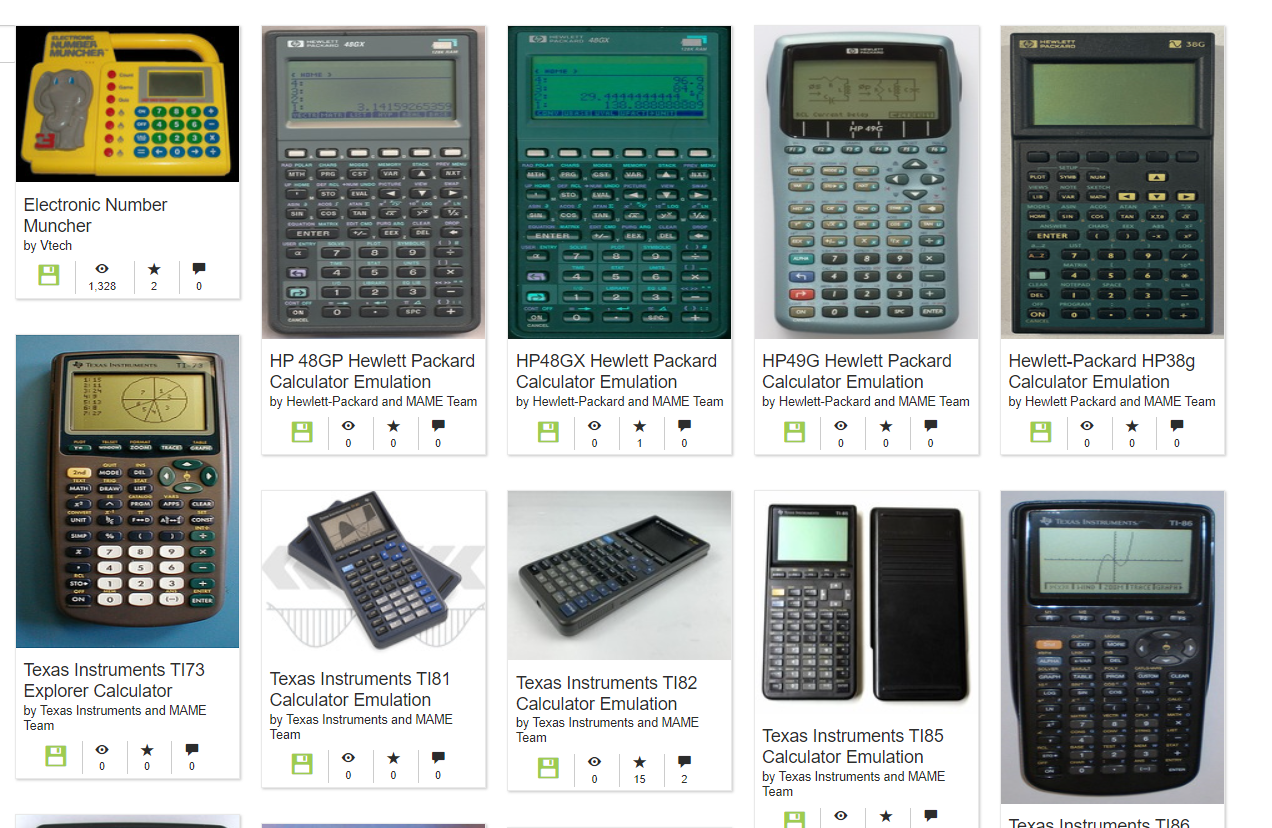
The Calculator Drawer is smaller than these other collections, but they possess a hearty collection of graphing and simple Calculators, emulated in MAME and with an additional layer of presenting the calculator itself, as a clickable graphical object, which you can then do math and graphing on. (You also need to turn many of them on, so look for the “ON” button to get things going.)
If Graphing Calculators were not a part of your childhood or previous life, they may be a bit of a steep climb to get to understand. If you still want to mess around with them, a stash of manuals for most of the models in the collection has been provided.
So, go forth and literally multiply.
However, if you wish to stick around a little bit longer…
The main reason you can do this wonderful “click on an image of a calculator as if it was a real object inside the browser” is because of a feature in MAME called MAME ARTWORK. It is one of a couple solutions to a major problem in emulation, especially of handheld devices, or tools like synthesizers or plastic toys.
The problem is that the actual “emulated” part of many of these machines are a tiny set of LED lights, or a line of LCD numbers, which is where all the circuitry presents its output, while the vast majority of the item is a static piece of metal or plastic with paint, labels and physical heft to the item. Compare, for example, the output of The Little Professor, emulated:
…to what the actual form factor of The Little Professor was:
We can all agree that while one could make the keys for 0-9, OFF, ON and so on “work” on a keyboard input, it would be so much nicer if a representation of the Little Professor calculator was on the screen to type into, pressing keys by a touchscreen or via a mouse (while leaving the keyboard option active).
MAME has two different ways it can render an emulated device that needs “additional” drawing to augment the part of itself that’s reflecting the screen or lights of the device.
One is to have the MAME system itself do a line-drawing of the interface the machine is using. That is, actual vector-based drawing of the buttons, screen and other decorations to help users understand what they’re looking at. To provide a counter-example of The Little Professor, here’s a Chess-Master Diamond system in the plastic realm:
…and here’s what you’ll see when you boot it up in the MAME system:
..definitely pretty sweet, for sure!
And while it’s very nice this option exists, there’s something compelling about a photograph of an original item being shown on-screen along with interactivity, and the best part is how it doesn’t require a deep lore of programming.
It’s called The MAME Artwork System, and while it’s not completely easy to get a hang of, it’s been refined since being introduced in 2006, and it could use help.
There are some amazing efforts that have been done to make these “layout” files for items emulated by MAME, with the best clearinghouse for seeing this work at Mr. Do’s Arcade. By leafing through the collection of artwork made so far, you can see how much better the interface is with a graphical addition. There’s over 1,400 different systems that have gotten the Artwork Treatment, a major success.
But that’s still a tiny percentage of the systems that need to time, focus, and skills of volunteers to make them come alive in this way.
People are often inspired to want to help emulation efforts, since they’re the future of software’s history, but it can be daunting to find a place in, to ramp up to the mass of intricacies and standards of a decades-long project. But perhaps, out there, is someone, maybe even you, who would find it a delight to help acquire excellent photographs of vintage hardware, and collaborate on designing the layout files for them.
This effort will allow us to add more calculators, devices, and hardware out of MAME to be playable at the Internet Archive, and you’ll join the immortal names of the creation of this longstanding project.