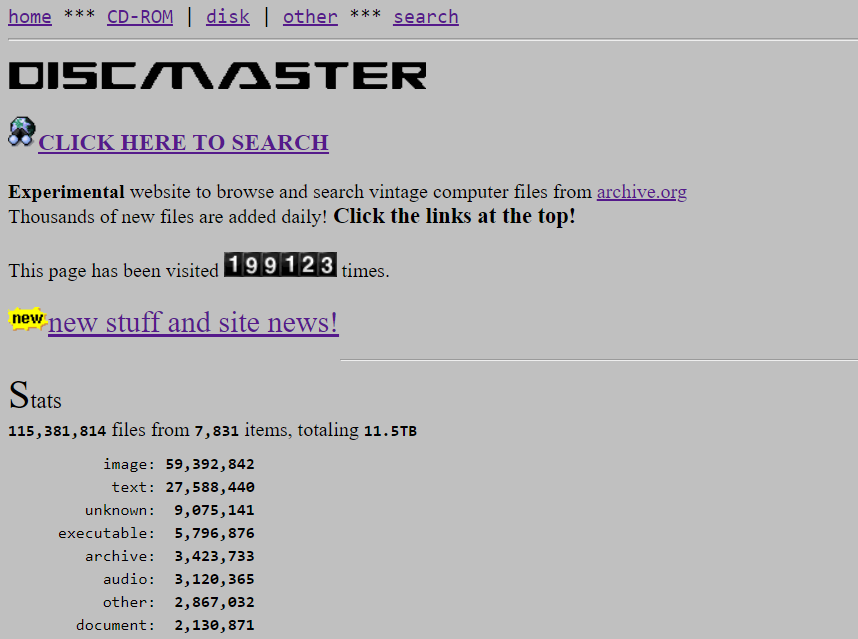
In October of 2022, the DISCMASTER site arrived, providing amazing semantic search of thousands of shareware and compilation CD-ROMs at the Internet Archive. In the entry written on the blog back then, the advantages and features of this site were pretty well enumerated.
Unfortunately, the site went down in June of 2023, due to a number of factors, the most pressing of which was a need to switch hosting and administration duties. (It is not run by Internet Archive and is not hosted at Internet Archive’s datacenters.)
However, DISCMASTER HAS RETURNED!
Thanks to a set of generous donors and the efforts of multiple volunteers, the site is back running with all the data and functionality it had in its previous incarnation.
The previous blog entry has fuller details on the meaning of this site and the many uses it has for computer and internet history. All hail DISCMASTER!
When Zeau Modig began as the graduate school librarian at the International Institute for Restorative Practices (IIRP) nearly a decade ago, many of the students lived nearby. They came to the Bethlehem, Pennsylvania, campus to check out some of the library’s 1,500 print books and make photocopies.
Zeau Modig, librarian
Today, the majority of students live elsewhere in a dozen different countries from Brazil to Hungary—and instruction has moved online. This is driving up demand for e-books. Modig has found resources on the Internet Archive to fill the gap between what her physical library can provide and the needs of her community.
“The Internet Archive has been amazing for us to be able to get material into our students’ hands, and making it accessible, especially for the people overseas studying in less developed countries,” Modig said. “If you’re not in the United States it’s not as easy to get books because of shipping—it could take weeks to get there. The Internet Archive has really been a tremendous help to our students.”
The graduate program attracts students who are often mid-career, working in education, criminal justice, business or any field looking for strategies and scholarship to address conflicts, repair harm, and restore community among individuals and groups. To understand the foundational ideas behind restorative practices, the classes sometimes assign readings of theoretical models that are hard to find. Modig said students often turn to the Internet Archive to find obscure books or journals that have otherwise vanished.
Modig said she values the Archive’s collaboration with Wikipedia to turn reference links in Wikipedia articles blue, connecting citations to the original source content in Archive’s digital collections. This effort gives scholars single-click access to verify information for their research.
“It’s made my life as a librarian so much easier,” Modig said of the Archive. “The faculty, too, most of whom work remotely, really appreciate having books at their fingertips.”
Outside her job, Modig said she uses the Archive for genealogy research, leisure reading and entertainment. She recently discovered a commemorative family reunion volume from 1883 on her French Huguenot relatives that gave her insight into her family history. Inspired by the Netflix series, “The Queen’s Gambit,” Modig checked out the original novel on which the show was based.
“Internet Archive has become an essential information lifeline for my graduate institution’s students and faculty, and also for me personally.”
Zeau Modig, librarian, International Institute for Restorative Practices
Unfortunately, as a result of the publishers’ lawsuit against the Internet Archive’s lending library, “The Queen’s Gambit” is no longer available for borrowing.
When Modig learned that the book can no longer be checked out to one reader at a time, she paused. “I’m glad I had the opportunity to enjoy this book while I could,” she said. “I hope that the publishers involved in the lawsuit against the Internet Archive will come to realize the advantages that controlled digital lending holds for them as well as for readers, and allow the Internet Archive to restore access to their content.”
“Overall, the Internet Archive has become an essential information lifeline for my graduate institution’s students and faculty, and also for me personally,” Modig said. “It would be deeply disappointing for us if this rich trove of content is no longer available through the Internet Archive.”
Last summer, Internet Archive launched ARCH (Archives Research Compute Hub), a research service that supports creation, computational analysis, sharing, and preservation of research datasets from terabytes and even petabytes of data from digital collections – with an initial focus on web archive collections. In line with Internet Archive’s mission to provide “universal access to all knowledge” we aim to make ARCH as universally accessible as possible.
Computational research and education cannot remain solely accessible to the world’s most well-resourced organizations. With philanthropic support, Internet Archive is initiating Advancing Inclusive Computational Research with ARCH, a pilot program specifically designed to support an initial cohort of five less well-resourced organizations throughout the world.
Opportunity
Organizational access to ARCH for 1 year – supporting research teams, pedagogical efforts, and/or library, archive, and museum worker experimentation.
Access to thousands of curated web archive collections – abundant thematic range with potential to drive multidisciplinary research and education.
Enhanced Internet Archive training and support – expert synchronous and asynchronous support from Internet Archive staff.
Cohort experience – opportunities to share challenges and successes with a supportive group of peers.
Eligibility
Demonstrated need-based rationale for participation in Advancing Inclusive Computational Research with Archives Research Compute Hub: we will take a number of factors into consideration, including but not limited to stated organizational resources relative to peer organizations, ongoing experience contending with historic and contemporary inequities, as well as levels of national development as assessed by the United Nations Least Developed Countries effort and Human Development Index.
Organization type: universities, research institutes, libraries, archives, museums, government offices, non-governmental organizations.
We’ve heard you loud and clear since January 1—you love the public domain! We do, too, so let’s celebrate together…
Next week we have two events to help welcome the new works of art that entered the public domain (in the US) on January 1. We hope you can join us in-person or online:
Wednesday, January 24
Public Domain Day Party in San Francisco! Celebrate 1928 In-Person at the Internet Archive 6pm – 8pm PT $15 registration – Register now!
Step into a time capsule of creativity as we celebrate the release of new cultural treasures into the public domain. Join us for an unforgettable evening filled with period tunes, classic cocktails, and a cinematic journey into the past. These works, once bound by copyright restrictions, will be released into the wild, opening up new opportunities for artistic expression, adaptation, and innovation.
Thursday, January 25
Weird Tales from the Public Domain: Freeing Culture from Corporate Captivity Online 10am PT – 11:30am PT Free – Register now!
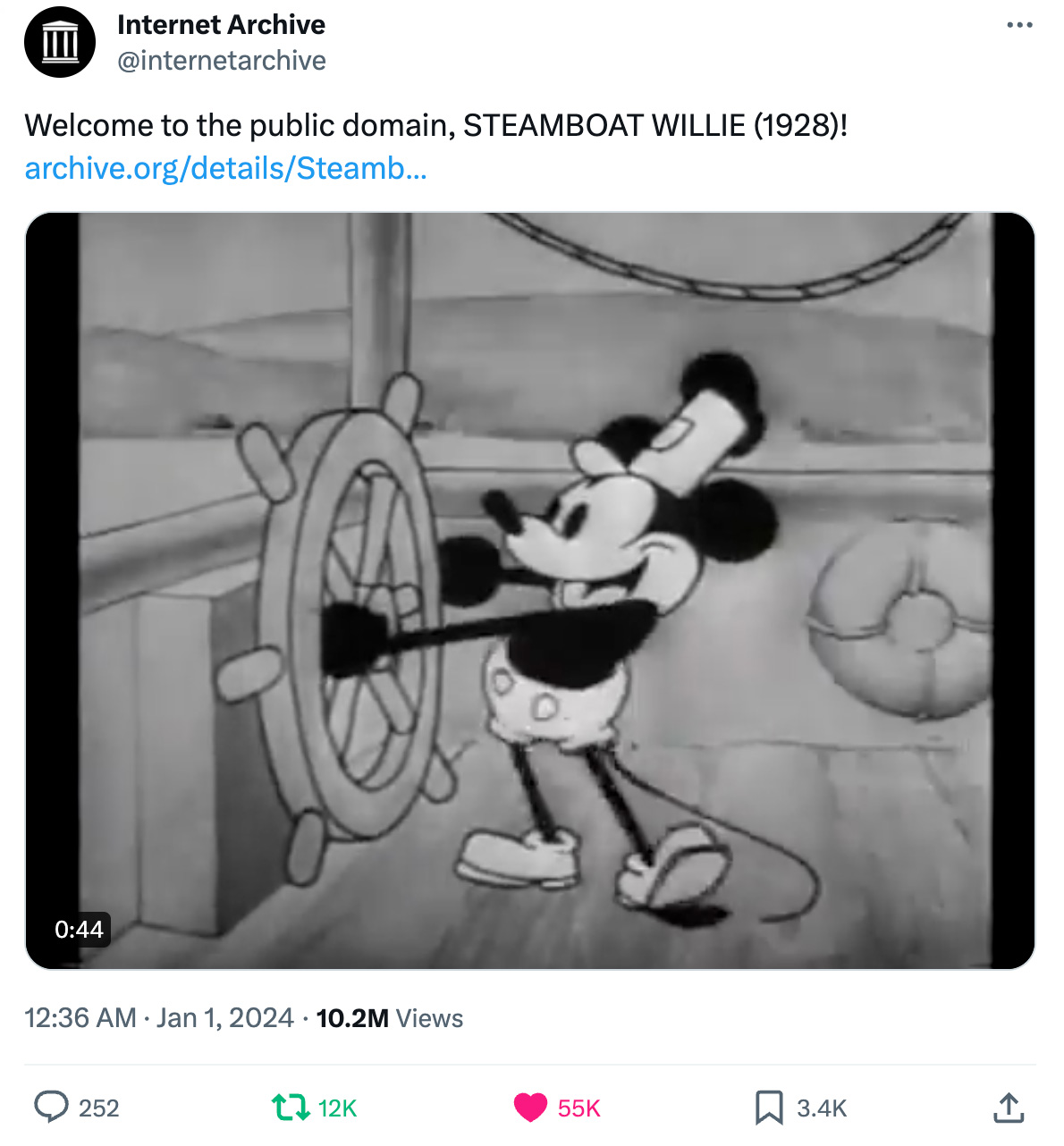
The mouse that became Mickey is finally free of his corporate captivity as the copyright term of the 1928 animated Disney film, Steamboat Willie, expired along with that of thousands of other cultural works on the first day of 2024.
Join us for a virtual celebration with an amazing lineup of academics, librarians, musicians, artists and advocates coming together to help illuminate the significance of this new class of works entering the public domain!
Remix Contest – Deadline for submission is January 19
There’s still time to register for our Public Domain Day Remix Contest. We are looking for filmmakers and artists of all levels to create and upload short films of 2–3 minutes to the Internet Archive to help us celebrate Public Domain Day! Read the contest guidelines.
Last week, Mickey Mouse and Elon Musk helped raise the visibility of library preservation and the Internet Archive’s mission across social media in an unexpected convergence of the public domain, popular culture and the publishers’ lawsuit against our library.
It started less than an hour into the new year. At 12:36am, we posted a 45 second clip from Steamboat Willie to X (formerly Twitter) with the iconic introduction of Mickey Mouse. By the next morning, the video had reached hundreds of thousands of views; by the end of the day, views had climbed into the millions. To date, the clip (above) has been viewed 10.2 million times.
As a result of that interest, people began looking at our profile and older posts. One key user posted a message of support about our blog post highlighting the amicus briefs filed in support of our appeal in Hachette v. Internet Archive, the lawsuit against our library.
That post, and presumably coupled with the visibility from the viral Mickey Mouse tweet, started a groundswell of support for the Internet Archive, with thousands of users sharing their thoughts on the importance of our mission.
In that chatter, a meme started forming: “Protect the Internet Archive – pass it on”
So many people were sharing this sentiment that “Protect the Internet Archive” started trending.
And then Elon Musk weighed in with “Support the Internet Archive!”:
With Musk’s enormous following on X, activity across our profile and posts skyrocketed, including our reply, but none more so than the post he shared about our appeal. To date, the post has been viewed more than 20 million times.
But it didn’t stop there. Because of the overwhelming level of support & visibility, we were getting dozens of messages from supporters asking how they can help our cause. In addition to telling our new followers about our mission, we also invited people to tell the publishers to stop suing libraries and sell us ebooks we can own and preserve.
And they did. Hundreds of users shared a message to the publishers with the hashtag #SellDontSue.
And then, like all viral moments, the attention faded. As of today (January 11, 2024), activity around our feed has returned to normal levels.
So what does it all mean??
While our time in the spotlight was brief, it was definitely meaningful. Now that we’ve had a little perspective and distance, we can point to three main takeaways from our viral week:
Takeaway #1: People love the public domain! Mickey Mouse moving into the public domain is a story decades in the making, so no surprise that there was an increased level of interest this year. However, we’ve noted an upswing in engagement for posts about the public domain every January, and excellent attendance at our public domain celebrations. We love the public domain, too, so we’re going to keep promoting the materials moving out of copyright year after year.
Takeaway #2: More people are armed with facts about the lawsuit against our library, and are voicing their support for library digital lending, digital ownership and preservation.
Takeaway #3: We helped more people understand the opportunities (preservation) & challenges (lawsuits) libraries face in the digital age. New people were introduced to our mission, to the legal challenges that libraries are facing in the digital age, and to understanding what’s possible when libraries are allowed to own and preserve materials for the long term.
So, a big thank you to everyone who shared posts, spoke out in support of the Internet Archive, or otherwise helped bring new visibility to our mission and work last week. We are committed to preserving materials in the public domain, fighting the lawsuits against our library, and continuing our mission of providing “Universal Access to All Knowledge”—onward!
One of the Internet Archive’s most viral tweets/toots/skeets happened at the start of 2024, with the announcement/reminder that the Disney short “Steamboat Willie” had entered the public domain just moments before. We have a copy of the film online for everyone to play or download.
Within a short time, even as the hour of midnight of January 1st moved across the earth, countless creations based off the Steamboat Willie character, ranging from the sublime to the profane, rocketed into the Internet.
Along with the flood of images have come a flood of articles and overviews of the legal and other ramifications of a public-domain Mickey Mouse. These are written by very smart people who have spent a lot of time considering these issues.
There’s no point is restating what these and many others are describing (Only Steamboat Willie’s design is public domain, Disney may utilize trademark law like a large hammer to enforce as firmly as they did their copyrights, etc.)
Instead, a few words about the creative ecosystem.
As a variety of slasher movies, costumes, crypto tokens, fan-fiction creations and general meme images of Steamboat Willie cascade into the first parts of 2024, it’s worth noting how the entire situation will feel unusual or a controversial subject to a number of folks.
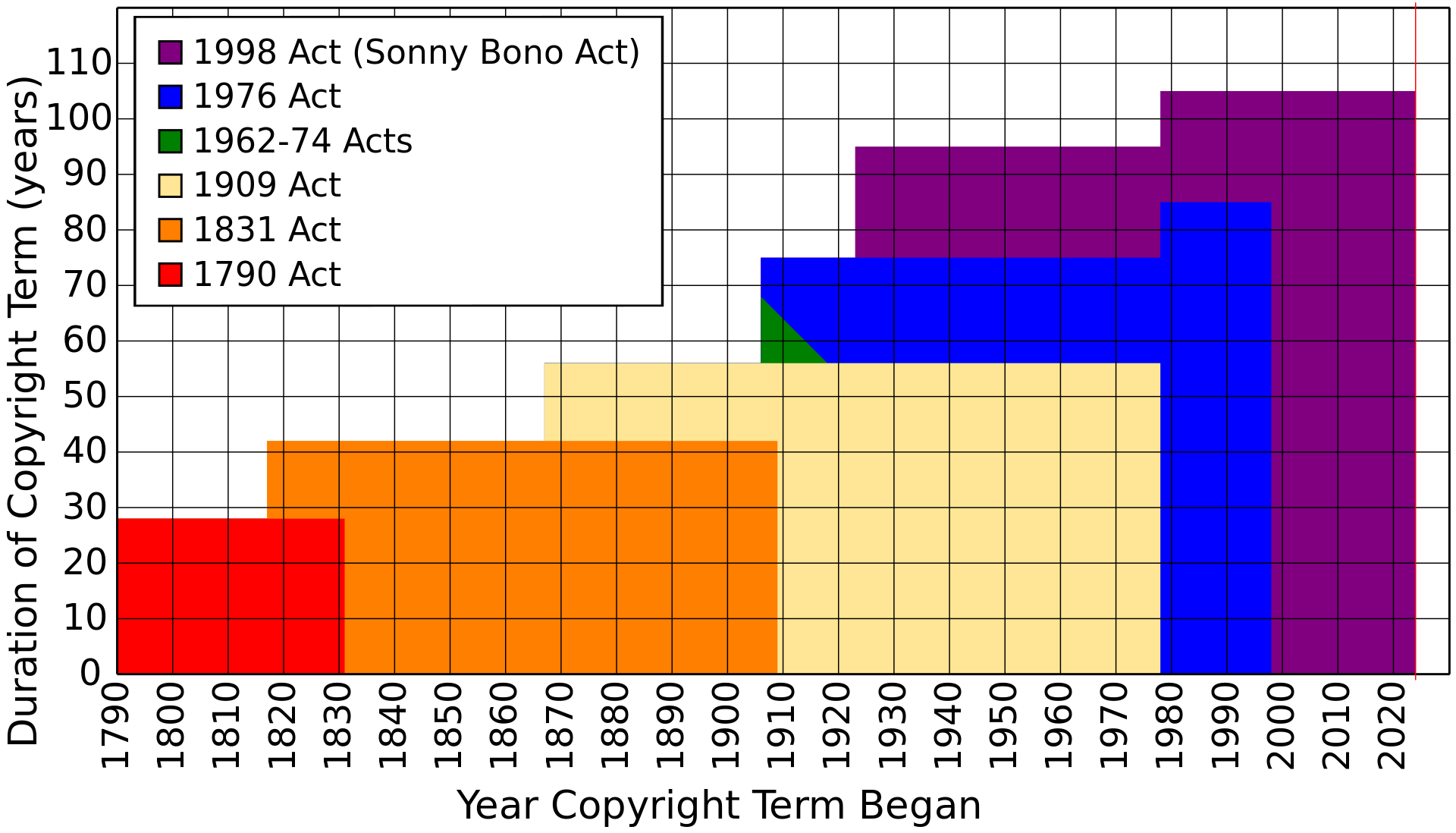
What it is, however, is a too-long-delayed part of a natural process of works and copyright. The implementation of universal involuntary copyright that then lasts longer than the vast majority of human lifetimes means a disconnect, a vast gulf between the life of creative works and when they become a part of culture at large in anything other than a consumption relationship.
Copyright in the US (and via the Berne Convention and other lobbying, worldwide) has been increasingly extended over the years, often following the impending expiration of the Steamboat Willie copyright, and it has done so in the face of a 20th century that knew much shorter terms (and which led to works such as Pinocchio being used by companies such as Disney after they expired into the pubic domain). As a result of this, we’ve lost the rich ecosystem that creative works grew from, the back-and-forth, parody and reference and re-imagining that existed in previous generations.
The time extension of copyright, from 14 to 28 to “75 years or life of the author plus 50 years” to the current “95 years or life of author plus 70 years” has been a rapid expansion that has swallowed many creative works, and, combined with automatic copyright, has effectively ended a long-rich and held system of creations that could reference near-contemporaries in their works beyond the scope of parody or (often disputed fair use). What was a rich environment is now a rather dry landscape.
The ramifications of this have been many, but one of the most striking has been preservation – with works whose corporate or anonymous creators are undetermined, there is very little incentive to invest in their upkeep and maintenance, meaning that many early works tend to disappear in percentages that are heartbreaking for their size: half of all American films made before 1950 and over 90% of films made before 1929 are lost forever [cite].
That excellent copies of Steamboat Willie still exist are owed mostly to Disney’s own efforts to keep their materials under control and locked down for nearly a century. Steamboat’s fellow members of the Class of 1928 will not, ultimately, be so lucky. Each successive year of items released into the public domain will have a few “stars” to make the news and receive the artistic references that Mickey is getting this month – but hundreds, maybe thousands of works from the same year may never again see the light of day.
So, let us celebrate this temporary oasis in a truly barren landscape, and work, through preservation and protection for libraries and archives, to ensure each year is a more exquisitely complete and maintained ecosystem.
This year we are welcoming many works from 1928 into the U.S. public domain (books, movies, images, etc.), as well as recorded sound from 1923.
Some of the big events from 1928 include the first machine sliced and wrapped loaf of bread being sold, the fatal Okeechobee hurricane, the failure of the St. Francis Dam in Los Angeles, the discovery of a moldy petri dish that would lead to the creation of penicillin, Amelia Earheart flying across the Atlantic, and a certain mouse making his public debut.
Movies
Everybody’s talking about Mickey. On November 18th, 1928 Steamboat Willie was published, the third Mickey Mouse film by Walt Disney and the first one to be published with sound. The prior two Mickey Mouse films, including Plane Crazy, had not been picked up for distribution so this was the public’s first introduction to the mouse. Steamboat Willie may have been named after another popular movie that came out in 1928, Buster Keaton’s Steamboat Bill, Jr., or perhaps the Vaudeville song, “Steamboat Bill” (popularized in 1910) which was included in the soundtrack (along with the 19th century song “Turkey in the Straw”).
The Jazz Age was really swinging, and 1923 saw the first recordings by King Oliver’s Jazz Band, including early work from Louis Armstrong on Dipper Mouth Blues. The first recorded example of jazz band boogie-woogie also came out that year, The Fives by Tampa Blue Jazz Band. And dancing the Charleston became a craze in 1923, thanks to Charleston from the 1923 musical “Runnin’ Wild.”
While the entrance to Tutankhamun’s tomb was found in 1922, it wasn’t until February of 1923 that the tomb was unsealed and of course the event was memorialized in song, including Old King Tut by Billy Jones and Ernest Hare, and Tut-Ankh-Amen (In the Valley of the Kings) by S. S. Leviathan Orchestra.
Some popular songs from 1923 that are have joined the public domain include:
Last week saw a massive outpouring of support for the Internet Archive and our legal positions from prominent library and nonprofit organizations, as well as hundreds of librarians and academics, who filed amicus (“friend of the court”) briefs in the Hachette v. Internet Archive Second Circuit appeal. Read on to learn why they believe our appeal should succeed.
American Library Association and Association of Research Libraries. This brief supports the Internet Archive’s position that our use of Controlled Digital Lending is a nonprofit educational use rather than a “commercial” one, and urges the Court to consider the broader impact its decision will have on a host of everyday library practices that rely on fair use. “Libraries rely on fair use at every step in a typical digital preservation workflow, from cataloging to access.” Read the full brief here.
Authors Alliance. This brief voices the strong support of authors for the Internet Archive and controlled digital lending. “Authors want and need libraries to purchase their books, but the copyright system has never required libraries to pay for those books again and again in order to provide readers with access in formats relevant to them in light of evolving technology.” Read the full brief here.
Center for Democracy & Technology, Library Freedom Project, and Public Knowledge. This brief focuses on the significant privacy issues at play in this case. “Readers should not have to choose to either forfeit their privacy or forgo digital access to information; nor should libraries be forced to impose this choice on readers. CDL provides an ecosystem where all people, including those with mobility limitations and print disabilities, can pursue knowledge in a privacy-protective manner.” Read the full brief here.
Copia Institute. This brief raises the important First Amendment considerations embodied in fair use, arguing that the district court decision rejecting Internet Archive’s fair use defense put copyright law in conflict with the Constitution. “Copyright law should want to promote access to works, because it does nothing to promote progress if the law incentives the creation of works that no one can actually enjoy. In this case, enabling the books that were already lawfully readable to be read is what copyright law should instead be glad for the Internet Archive to do.” Read the full brief here.
Copyright Scholars. In this brief, 11 prominent copyright scholars argue forcefully for the Second Circuit to overturn the district court’s decision. “By eliminating the ability of libraries to use CDL as a means of ensuring long-term affordable digital access to their collections, publishers threaten the core functions of the library—acquiring, preserving, and sharing information. Avoiding those public harms urges a finding of fair use.” Read the full brief here.
eBook Study Group, Library Futures Project, EveryLibrary Institute, ReadersFirst, SPARC, ASERL, BLC, PALCI, Urban Libraries Unite and 218 individual librarians. This brief explains the history and development of CDL, how deeply embedded the practice is today, and urges the appellate Court not to disrupt this long-standing and widespread practice. “CDL has become a critical part of library practice in the United States because it provides a reasonable way to offer digital access to libraries’ legally acquired collections. Over 100 libraries across the United States rely on a CDL program to distribute their collections, particularly for out-of-print works, reserves, or for works that are less frequently circulated.” Read the full brief here.
HathiTrust. Digital Library consortium HathiTrust cautions the appellate court not to follow the district court’s ruling that IA’s use was “commercial” or harmed the publishers market, and warns against a broad ruling that could sweep in many other digital library practices. “[The district court’] ruling has been widely perceived by libraries as a threat to lending of digital copies in general, or even “part of a broader historical push to make libraries obsolete.” Neither the record in this case nor the applicable law supports such a result.” Read the full brief here.
Intellectual Property Law Professors. This brief focuses entirely on the district court’s deeply problematic ruling the the Internet Archive’s controlled digital lending program is “commercial.” “While there are many commercial fair uses, the Internet Archive’s digital lending program falls on the specially favored nonprofit, noncommercial side. The District Court therefore erred in interpreting “commercial” so broadly as to encompass the Internet Archive’s nonprofit lending.” Read the full brief here.
Kevin L. Smith and William M Cross. In this brief, two library and information scholars and historians with deep expertise regarding libraries and archives explain that “CDL is just one of numerous innovations in library services that have been developed and implemented through many decades and can be adapted to legal requirements. This case presents an opportunity for the Court to make clear that libraries, acting within the law, have the imperative to deploy technologies and build innovative services in furtherance of broad access to information.” Read the full brief here.
Law Library Directors, Professors and Academics. Over 50 law library directors, professors, librarians, and graduate students signed onto this brief arguing that the district court did not appropriately consider the public benefits of CDL. “Neither the public nor authors, both of whom are the intended beneficiaries of copyright, benefit from libraries spending public or community funds on the same content repeatedly instead of acquiring new content. The logical consequence is that the public has access to fewer authors and works, fewer authors get wide exposure, and fewer works are preserved for future generations.” Read the full brief here.
Wikipedia, Creative Commons, and Project Gutenberg. Three prominent open knowledge organizations filed this brief focusing on the damage the lower court ruling could do to all nonprofit uses of in-copyright material. “The district court’s decision contains factual and legal errors that, if endorsed by this Court, could threaten the ability of all nonprofits to make fair use of copyrighted material.” Read the full brief here.
Internet Archive drew more than 2,000 attendees to its popular book talk series in 2023, held in collaboration with Authors Alliance. The books and authors represented in this year’s series covered topics as varied as digital copyright, the persistence of history and culture through preservation, early personal computing history, and the harms of political control and corporate surveillance. Browse the full collection.
Some of my clearest and fondest childhood memories are being in the kitchen with my grandmother and learning how to bake.
My grandmother and my grandfather immigrated from Mexico to the Maryland suburbs in the late 1950s. Raising six children while learning English as a second language and living as a minority in a very homogenous community could not have been easy for her—but by the time I knew my grandmother, she was, to my eyes, the picture of American suburban domesticity. Alongside our Mexican staple dishes at the dinner table, my grandmother loved to bake sweet treats out of her much-beloved Better Homes & Gardens cookbook. And, as soon as I was old enough to hold a mixing spoon, I would be beside her, learning how to level the flour in a measuring cup and stirring the mixing bowl for bundt cakes.
When my grandparents retired and moved from Maryland to Texas in 2003, that cookbook was donated–hopefully continuing to aid other amateur chefs to this day. But recently, I found myself wondering about one particular recipe.
So, I turned to the Internet Archive and was surprised and delighted to find that we have a digitized version of the same Better Homes & Gardens New Cookbook I remember so fondly from my childhood. And there, on page 258, was the first recipe I remember baking on my own at eight years old: a batch of Peanut Butter Cookies. Looking at the recipe now, I’m transported back to that time, remembering how proud my grandmother was when I showed her the cookies I’d baked.
I know that among the millions of texts in the Archive, there are countless other memories like this one waiting to be unlocked for numerous patrons. As I was perusing our collections, I stumbled upon some new favorites, including:
I love each of these texts because I know each recipe contained within their pages likely has a story just like my own—beautiful memories of cooking them for and with loved ones.
I hope you’ll also consider supporting our work in helping us preserve numerous cherished memories on the Archive. To make a year-end donation, please visit archive.org/donate. Thank you to all of our supporters who make this work possible.
Jessica Cepeda joined the Internet Archive’s Philanthropy team as a Major Gift Officer in 2022. She has a passion for engaging with donors and connecting them with opportunities to support the Archive. She comes to the Archive with a decade of experience in nonprofit development and individual giving, most recently at NYU Stern School of Business. She received a BA in the College of Letters from Wesleyan University and loves that her work at the Archive marries her passion for books and technology and her deep and abiding belief in providing free and open access to knowledge. Jessica lives in Brooklyn, NY, which she has called home for the last ten years. Outside of her work for the Archive, she enjoys traveling, reading, cooking, and exploring the city with her dog, Harry.