Living in the middle of Lake Champlain in Vermont, Eleanor Martinez says she enjoys the beautiful scenery all around, especially the fall foliage. It’s been an idyllic place to retire, but there is one thing she misses: a public library.
Martinez, and her husband, Sid, live on Isle La Motte, which is 7 miles long and 2 miles wide, accessible by one bridge and has a population of 400. There is a library on the island, but it is private, and open by appointment only. The public libraries in nearby towns have limited collections.
“The Internet Archive has been a lifesaver,” says Martinez, who discovered the online collection about two years ago. She’s a regular user of the virtual library, checking out books and music on her laptop in the comfort of her rural home.
The wooded, nine-acre property was a draw for the retirees, who relocated in 2018, but it is remote. In the winter, it can sometimes take more than a week for a snowplow to reach their gravel road. Martinez, 66, lived most of her life in more urban areas in California and Minnesota where she enjoyed large, metropolitan public libraries nearby. The Internet Archive has provided access to materials she would not otherwise be able to enjoy in her small town.
Martinez has tapped into the Internet Archive to check out books, from “The Modern Temper” by Joseph Wood Krutch to “The Theory of the Leisure Class” by Thorsten Veblen. She enjoys vintage cookbooks, books on gardening, knitting and poetry.
Martinez found Down Beat magazines dating back to the 1930s about the jazz and blues scene. She’s also discovered music not available elsewhere on vinyl or CD.
“I was able to check out 33-1/3 records and 78s, too,” Martinez said. “This is a boon to those of us who don’t have access to large collections of records, and for those of us who are low-income and living on a fixed income.”
One of her favorite music items is “In a Clock Store,” a novelty recording from 1907 that includes sounds from a clock in the background. “I’m listening to something that is from a time when my grandfather would have been a teenager,” she said. “It was a different world.”
Another copy of that 78rpm recording shines a light on the importance of digitizing and preserving recordings on the obsolete medium—notes made by the audio engineer at the time of digitization indicate that the second side of this record wasn’t able to be preserved “due to physical condition of disc.”
After a pause, Martinez added a final thought: “The Internet Archive has just about everything I’ve been looking for—even things that are pretty obscure. It’s amazing.”
10 years ago, the Internet Archive made an announcement: It was possible for anyone with a reasonably powerful computer running a modern browser to have software emulated, running as it did back when it was fresh and new, with a single click. Now, a decade later, we have surpassed 250,000 pieces of software running at the Archive and it might be a great time to reflect on how different the landscape has become since then.
Anyone can come up with an idea, and the idea of taking the then-quite-mature Javascript language, universally inside all major browsers and having it run complicated programs was not new.
With the rise of a cross-compiler named Emscripten, the idea of taking rather-complicated programs written in other languages and putting them into Javascript was kind of new.
That all being the case, the idea of taking a by-then 20-year-old super-emulator called MAME, using Emscripten to cross-compile it into Javascript, and then running the resulting code in the browser at Internet Archive to make computers and consoles run, was very new.
It was also, objectively, madness.
Well over a thousand hours of work went into the project from a very wide range of volunteers who poured galactic amounts of time into making the project a reality. Along the way, changes were made to Emscripten, the Firefox, Internet Explorer, and Chrome Browsers, MAME, and the Internet Archive’s codebase to accommodate this dream.
Additional announcements came with each expansion of the types of software being emulated, and it became huge news, leading to millions of visitors coming to try this it out.
By any measure, a quarter of a million items later, it has been a huge, huge success.
The rest of this blog entry is pretty pictures and beautiful links, but before we move on, it’s once again important to highlight people who provided major contributions, including Justin Kerk, Daniel Brooks, Vitorio Miliano, James Baicoianu, John Vilk, Tracey Jaquith, Jim Nelson, and Hank Bromley. Dozens more developers spent evenings, weekends, and months to make this system happen. Thank you to everyone involved.
The joy of watching a computer boot up in the browser was (and is) a miraculous feeling. And after that feeling, comes a quick comfort with the situation: Of course we can run computers inside our browsers. Of course we can make most anything we want run in these browser-based computers. What’s next?
Within a short time after our 2013 announcement, the archive was running hundreds, then thousands of individual programs, floppy disks and even cassette-based software from computing’s past.
As emulators besides MAME were added, it became necessary to create a framework for a versatile and understandable method to load emulators. This framework eventually got a name: THE EMULARITY.
In the decade of the Emularity’s existence, the Archive’s software emulation has expanded into directions nobody could have fully expected to work when the project started.
Here are some highlights:
Hypercard Stacks for the Apple Macintosh, a critical period in content creation and computer information architecture, have been restored to easy access, surpassing thousands of hypercards to try instantly.
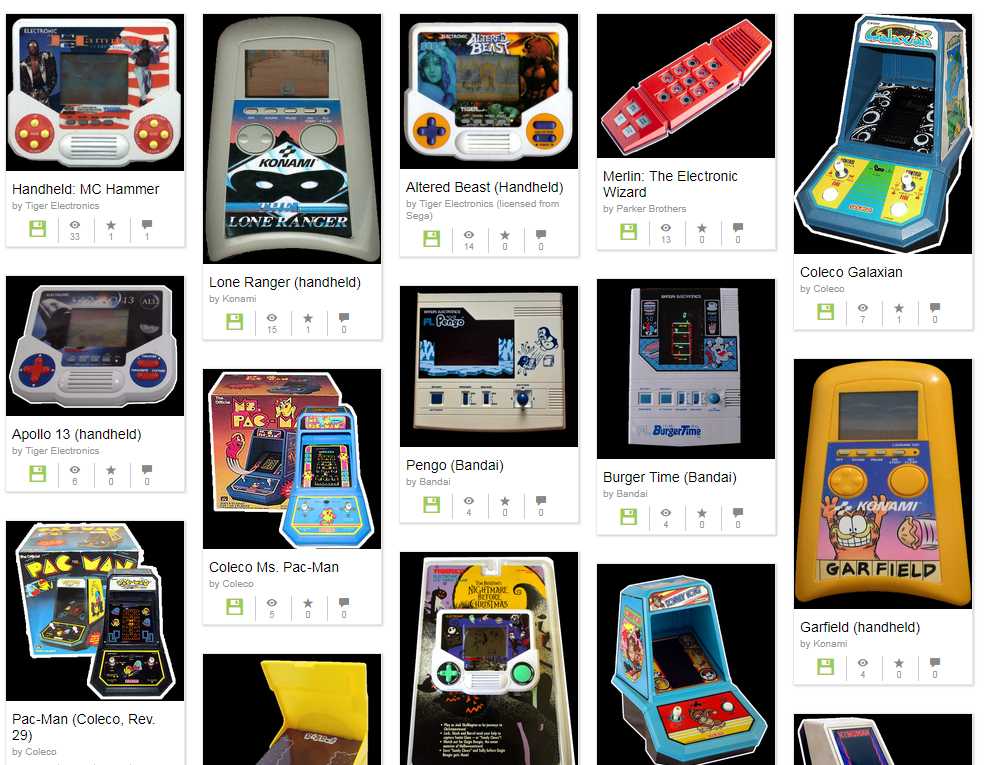
Plastic Electronic Handheld Games, once a staple of toys in the 1970s through the 1990s, have been able to live once again as, including the original housing that these simple (and not so simple) machines relied on instead of graphics.
As the uploads veered into the many thousands, it became more and more difficult for new adventurous users to figure out what, if any, software was at the archive to check out. This has led to specialized collections focused on one type of program, like the Computer Chess Club. People can use these collections as gateways to quickly testing the waters of now-decades of computer and software history, seeing the turns and twists of countless lost companies and individuals who squeezed every last bit of wonder and spectacle out of these underpowered boxes.
The Calculator Drawer took things to a new level when entire calculators could be emulated, including their unique looks, accompanied by a “drawer of manuals” to browse through if you had to learn (or re-learn) how to make these machines run.
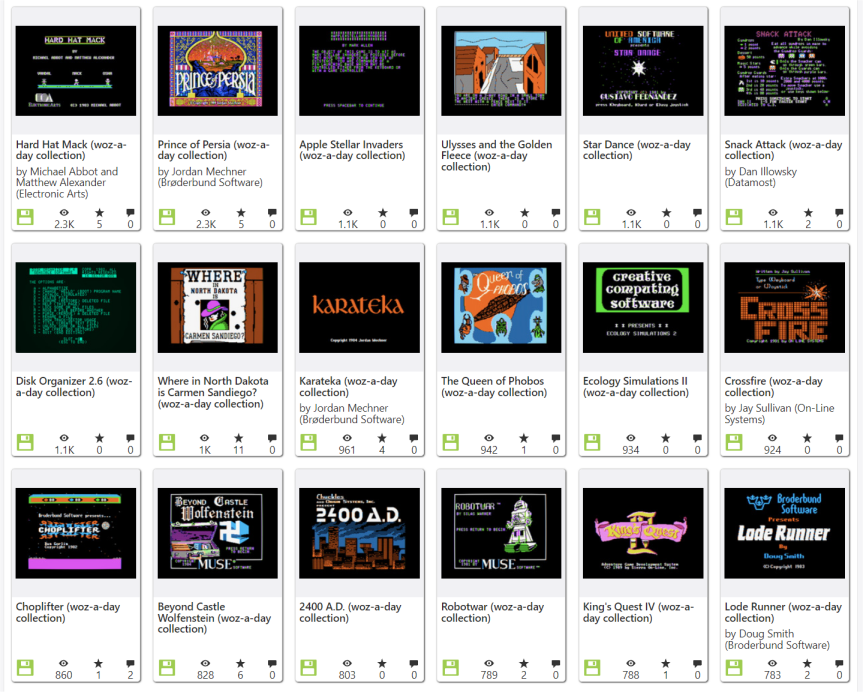
The Woz-a-Day Collection, in many ways, represents the logical end for the role that the Internet Archive’s Emularity can provide for software history. The project is the effort of the software historian 4am, who has spent years on its maintenance. Methodically preserving Apple II software from the original floppy disks, incorporating every last bit and track of the disks with no modifications, and allowing the best fidelity of these programs as they originally were offered, 4am allows some of these programs to be playable for the first time in decades.
With each new batch of added emulated systems and machines have come a greater and greater pool of users, toying with historical software or playing long-forgotten or never-remembered games with a new level of convenience and willingness to try them out.
At this milestone of a decade into this experimental adventure, Internet Archive continues to grow its collection, to test and automate the functioning of both uploaded and self-maintained collections of software, and to provide a vast and necessary service in the preservation of historical software.
In June, we announced the official launch of Archives Research Compute Hub (ARCH) our platform for supporting computational research with digital collections. The Archiving & Data Services group at IA has long provided computational research services via collaborations, dataset services, product features, and other partnerships and software development. In 2020, in partnership with our close collaborators at the Archives Unleashed project, and with funding from the Mellon Foundation, we pursued cooperative technical and community work to make text and data mining services available to any institution building, or researcher using, archival web collections. This led to the release of ARCH, with more than 35 libraries and 60 researchers and curators participating in beta testing and early product pilots. Additional work supported expanding the community of scholars doing computational research using contemporary web collections by providing technical and research support to multi-institutional research teams.
We are pleased to announce that ARCH recently received funding from the Institute of Museum and Library Services (IMLS), via their National Leadership Grants program, supporting ARCH expansion. The project, “Expanding ARCH: Equitable Access to Text and Data Mining Services,” entails two broad areas of work. First, the project will create user-informed workflows and conduct software development that enables a diverse set of partner libraries, archives, and museums to add digital collections of any format (e.g., image collections, text collections) to ARCH for users to study via computational analysis. Working with these partners will help ensure that ARCH can support the needs of organizations of any size that aim to make their digital collections available in new ways. Second, the project will work with librarians and scholars to expand the number and types of data analysis jobs and resulting datasets and data visualizations that can be created using ARCH, including allowing users to build custom research collections that are aggregated from the digital collections of multiple institutions. Expanding the ability for scholars to create aggregated collections and run new data analysis jobs, potentially including artificial intelligence tools, will enable ARCH to significantly increase the type, diversity, scope, and scale of research it supports.
Collaborators on the Expanding ARCH project include a set of institutional partners that will be closely involved in guiding functional requirements, testing designs, and using the newly-built features intended to augment researcher support. Primary institutional partners include University of Denver, University of North Carolina at Chapel Hill, Williams College Museum of Art, and Indianapolis Museum of Art, with additional institutional partners joining in the project’s second year.
Thousands of libraries, archives, museums, and memory organizations work with Internet Archive to build and make openly accessible digitized and born-digital collections. Making these collections available to as many users in as many ways as possible is critical to providing access to knowledge. We are thankful to IMLS for providing the financial support that allows us to expand the ARCH platform to empower new and emerging types of access and research.
A joint blog post between the Internet Archive and the IIIF Community
Summary
After eight years hosting an experimental IIIF service for public benefit, the Internet Archive is moving forward with important steps to make its International Image Interoperability Framework (IIIF) service official. Each year, the Internet Archive receives feedback from friends and partners asking about our long-term plans for supporting IIIF. In response, the Internet Archive is announcing an official IIIF service which aims to increase the resourcing and reliability of the Internet Archive’s IIIF service, upgrade the service to utilize the latest version 3.0 of the IIIF specification, and graduate the service from the iiif.archivelab.org domain to iiif.archive.org. The upgrade also expands the Internet Archive’s IIIF support beyond images to also include audio, movies, and collections — enabling deep zoom on high-resolution images, comparative item analysis, portability across media players, annotation support, and more.
Background
In 2015, a team of enthusiastic Internet Archive volunteers from a group called Archive Labs implemented an experimental IIIF service to give partners and patrons new ways of using Archive.org images and texts. You can read more about the project’s origins and ambitions in this 2015 announcement blog post. The initial service provided researchers with an easy, standardized way to crop and reference specific regions of archive.org images. (Maybe you can tell whose eyes these are?) By making Internet Archive images and texts IIIF-compatible, they may be opened using any number of compatible IIIF viewer apps, each offering their own advantages and unique features. For instance, Mirador is a “multi-up” viewer that makes it easy for researchers to view different images side by side and then zoom into or annotate different areas of interest within each image.
Since its launch more than seven years ago, the IIIF labs service has received millions of requests by more than 15 universities and GLAM (galleries, libraries, archives and museums) organizations across the globe, including University of Texas, UCD Digital Library, Havana University, Digital Library of Georgia, BioStor, Emory University, and McGill University. In this time, the broader IIIF ecosystem itself has blossomed to include hundreds of participating institutions. For all its benefits, the labs IIIF service has been considered “unofficial,” hosted on the separate archivelab.org domain, and several partners have voiced interest in the Internet Archive adopting it as an officially supported service. Today, several members of the IIIF community are collaborating with the Internet Archive to make this happen.
Josh Hadro, managing director of the IIIF Consortium (IIIF-C), sees the Internet Archive as filling a critical role “in serving the average Internet user who may not benefit from the same access to or affiliation with infrastructure offered by traditional research institutions.” The IIIF-C promotes interoperability as a core element of IIIF: the ability to streamline access to information and make cultural materials as easy to use and reuse as possible. Because the Internet Archive enables any patron to upload eligible materials, everyone has the opportunity to benefit from IIIF’s capabilities. IIIF-C counts the Internet Archive as a natural ally because of its ongoing support of open collections delivered via open web standards and protocols. With this project, IIIF-C hopes to make the Internet Archive a go-to resource online that facilitates IIIF work for students and scholars unaffiliated with the kinds of institutions that historically have provided IIIF infrastructure. This is an essential step toward a strategic goal of lowering barriers to IIIF usage and adoption worldwide.
In service of this outcome, the Internet Archive has teamed up with a number of IIIF community members to officialize and upgrade the IIIF service in order to make the best use of the new capabilities introduced into the IIIF specifications in recent years.
In the coming weeks, we’ll share more details about the IIIF improvements that will become available to users of the Internet Archive. First, we want to lay out our current plan for the update, including backwards compatibility affordances, to ensure existing consumers have the information they need to successfully migrate from the unofficial to the official IIIF API.
Thanks
Both the original IIIF labs service the Internet Archive has been running, as well as the new upcoming official IIIF service, wouldn’t have been possible without huge support from volunteers within the IIIF community and Internet Archive staff. A big thank you to the following folks who are making this effort to bring IIIF into production possible:
Internet Archive staff, including Rob, Mek, Drini, Tracey, Brenton, et al.
Stay tuned for more details on the new functionality soon, and if you have questions or would like to get involved in helping us test the new setup, get in touch with IIIF-C at staff@iiif.io. For more updates, including September 13 IIIF Consortium community call announcing the Internet Archive’s IIIF service, please visit the IIIF community calendar at https://iiif.io/community/#calendar.
Technical Notes & FAQs for Partners
This technical section is intended for partners who currently rely on the iiif.archivelab.org IIIF API who may be seeking further details on how these changes might affect them.
What is changing? Previously, partners accessed the Internet Archive’s IIIF labs API from the iiif.archivelab.org domain. As part of the effort to graduate from labs to production, the IIIF API will move to the iiif.archive.org domain. Because we don’t want to break any of the amazing projects and exhibits that patrons have created using the existing IIIF capabilities on the archivelab.org domain, we’re migrating the API in phases.
Phasing migration. The first phase will introduce a new and improved, official Internet Archive IIIF 3.0 service on the iiif.archive.org subdomain. The unofficial, legacy service will continue to run on the iiif.archivelab.org for a grace period, allowing partners to migrate. Once we’ve gathered enough data to be confident requests are being satisfactorily fulfilled by the new official service, the legacy iiif.archivelab.org service will be “sunset” and any request to it will redirect to use the official iiif.archive.org service. At this point, all requests for IIIF manifests and IIIF images (whether to iiif.archivelab.org or iiif.archive.org) will default to the latest 3.0 version of the IIIF APIs and be answered by iiif.archive.org. A specifiable “version” endpoint will be available for consumers whose applications require manifests and images to be served using the IIIF v2.0 legacy format. More details, examples, and technical documentation will be made available on this topic in the coming weeks and will eventually be accessible from iiif.archive.org.
Possible Breaking Changes. 1. When the iiif.archivelab.org service was originally launched, iiif.archive.org was set up to redirect to iiif.archivelab.org as a convenience. Regrettably, during the first phase of development, iiif.archive.org will no longer be a redirect for iiif.archivelab.org and instead will run the new official IIIF service. As a result, partners whose code or applications reference iiif.archive.org (expecting it to redirect to iiif.archivelab.org) will experience a breaking change and will need to either update their references to explicitly refer to the legacy “iiif.archivelab.org” service, or update their code to use the Internet Archive’s new official iiif.archive.org service. As far as we can tell, we’re unaware of partners currently referencing “iiif.archive.org” within public projects on Github or Gitlab and so we hope no one is affected. Still, we want to give fair warning here. For those starting a new project and looking to use the Internet Archive’s IIIF offerings today, we strongly recommend using the iiif.archive.org endpoint. 2. Some partners migrating from the v2 to v3 API who have been saving annotations may also experience a breaking changes because canvas and manifest identifiers for version 3 are necessarily different from version 2 identifiers. We will be doing our best, for the time being, to ensure version 2.0 manifests remain accessible from the archivelab.org address (via redirects) and will retain the iiif.archivelab.org canvas identifiers.
Rachel Simmons first used the Wayback Machine for research projects at her Sacramento, California, high school. Now a senior at UCLA, she’s discovered even more ways to find material not available elsewhere.
Rachel Simmons
Simmons, whose mother and grandmother were both librarians, is an applied math major with a minor in film, television and digital media. As she looks up information about media figures or needs to find a rare film, she says the Internet Archive’s digital collection has been an invaluable resource.
“It’s really great to have access to information for anyone to use from their home computer,” Simmons says. “I don’t physically have to go into a library. If I’m working on something late at night, it’s convenient.”
When taking a class on American film history last year, she was assigned to research a famous actor; she chose Peter Lorre.
“I’m a big fan of classic horror films and he’s an icon whose legacy has continued long past his career,” she said. “I just wanted to learn more about him and what people thought of him at the time.”
To find those contemporary views of Lorre’s work, Simmons turned to the fan magazine collection in the Archive’s Media History Digital Library. There she found interviews with the actor and reviews of his movies from the 1930s. Despite appearing as a mysterious figure on film, Simmons says she learned the interviews present him as a conventional, regular guy. She gained even more insight through the published fan letters in the magazines. “I found it really interesting that I was reading these letters from almost one hundred years ago,” Simmons said.
For another UCLA course, Simmons tapped into the Internet Archive to view silent German films that were discussed in class. While she was studying, Simmons found herself stumbling onto trailers for other films, which led her to checking out similar movies for fun after her projects were complete. Many of the more obscure titles that interest her are not available on streaming services, she notes.
Simmons says she tells others about the resources available through the Internet Archive—including her family of librarians.
Join author Ian Johnson and sociologist Li Jun for an IN-PERSON discussion about “Sparks: China’s Underground Historians and their Battle for the Future”
About Sparks Sparks: China’s Underground Historians and their Battle for the Future (to be published by Oxford University Press on September 26, 2023) describes how some of China’s best-known writers, filmmakers, and artists have overcome crackdowns and censorship to forge a nationwide movement that challenges the Communist Party on its most hallowed ground: its control of history.
The past is a battleground in many countries, but in China it is crucial to political power. In traditional China, dynasties rewrote history to justify their rule by proving that their predecessors were unworthy of holding power. Marxism gave this a modern gloss, describing history as an unstoppable force heading toward Communism’s triumph. The Chinese Communist Party builds on these ideas to whitewash its misdeeds and glorify its rule. Indeed, one of Xi Jinping’s signature policies is the control of history, which he equates with the party’s survival.
But in recent years, a network of independent writers, artists, and filmmakers have begun challenging this state-led disremembering. Using digital technologies to bypass China’s legendary surveillance state, their samizdat journals, guerilla media posts, and underground films document a regular pattern of disasters: from famines and purges of years past to ethnic clashes and virus outbreaks of the present–powerful and inspiring accounts that have underpinned recent protests in China against Xi Jinping’s strongman rule.
Based on years of first-hand research in Xi Jinping’s China, Sparks challenges stereotypes of a China where the state has quashed all free thought, revealing instead a country engaged in one of humanity’s great struggles of memory against forgetting—a battle that will shape the China that emerges in the mid-21st century.
Ian Johnson is a senior fellow at the Council on Foreign Relations. He has lived more than twenty years in China as a student, journalist, and teacher. His work appears regularly in The New York Review of Books,The New York Times, and other publications, and for five years he was on the editorial board of The Journal of Asian Studies. He has won numerous prizes for his coverage of China, including a Pulitzer Prize.
Li Jun (who writes under the penname Li Sipan) is a Ph.D. in political sociology, and a visiting scholar at Stanford University. Before entering academia, she was an investigative reporter for the liberal newspaper group Southern Daily Press and a recognized feminist activist. In 2004, she founded the feminist communications NGO Women’s Awakening Network (新媒体女性), which has played a leading role in China’s anti-sexual harassment campaigns and in the process of legislating against domestic violence. Li’s research focuses on the intergenerational differences in the feminist movement as well as the relationship between the media and the feminist movement in China.
Book Talk: Sparks by Ian Johnson October 19 @ 6pm PT IN-PERSON @ 300 Funston Avenue, San Francisco Register now!
Internet Archive’s Digital Library of Amateur Radio & Communications has grown to more than 90,000 resources related to amateur radio, shortwave listening, amateur television, and related topics. The newest additions to the free online library include ham radio magazines and newsletters from around the world, podcasts, and discussion forums.
Additions to the newsletter category include The Capitol Hill Monitor, a newsletter for and by scanner radio enthusiasts in the Washington, D.C. region — a complete run from 1992 through today. DLARC has also added more than 300 issues of Florida Skip and its follow-on magazine, SKIP CyberHam, donated by the family of the publisher. Both Capitol Hill Monitor and Florida Skip are online for the first time, scanned from the original paper.
The Cal Poly Amateur Radio Club donated hundreds of radio manuals, catalogs, and magazines — literally emptying file cabinets of material. DLARC has scanned them all and made the trove available online.
Digital Library of Amateur Radio & Communications is funded by a grant from Amateur Radio Digital Communications (ARDC) to create a free digital library for the radio community, researchers, educators, and students. DLARC invites radio clubs and individuals to submit material in any format. If have questions about the project or material to contribute, contact:
Today, the Internet Archive has submitted its appeal [PDF] in Hachette v. Internet Archive. As we stated when the decision was handed down in March, we believe the lower court made errors in facts and law, so we are fighting on in the face of great challenges. We know this won’t be easy, but it’s a necessary fight if we want library collections to survive in the digital age.
Statement from Brewster Kahle, founder and digital librarian of the Internet Archive: “Libraries are under attack like never before. The core values and library functions of preservation and access, equal opportunity, and universal education are being threatened by book bans, budget cuts, onerous licensing schemes, and now by this harmful lawsuit. We are counting on the appellate judges to support libraries and our longstanding and widespread library practices in the digital age. Now is the time to stand up for libraries.”
We will share more information about the appeal as it progresses.
To support our ongoing efforts, please donate as we continue this fight!
About Memory, Edited As authoritarianism continues to rise around the world, the stories we tell ourselves about what has happened and what is happening become ever more relevant. In Memory, Edited, Abby Smith Rumsey examines collective memory, how it binds us, and how it can be used by bad actors to manipulate us. Bringing forward the voices of a rich cast of Eastern European artists from the past two hundred years—from Fyodor Dostoevsky to Gerhard Richter—Rumsey shows how their work and lives illustrate the devastation wrought by regimes dependent on entrenched lies to survive. This hijacking of the narrative polarizes communities even as it commandeers our future.
Through an interdisciplinary lens that includes the best thinking from history, the arts, cognitive science, psychology, and political philosophy, Rumsey lays bare our narratives, showing how they are constructed and how they have changed over time. Ever-aware of resisting the false promise of utopia, Rumsey argues that only by confronting the past and reckoning with the crimes that were committed can we ever hope to heal and gain self-knowledge. Memory, Edited is an indispensable text for anyone who cares about democracy, equality, and freedom in our current age of crisis.
Abby Smith Rumsey is an intellectual and cultural historian. She chairs the board of the Center for Advanced Study in the Behavioral Sciences at Stanford University and is the author of When We Are No More: How Digital Memory Is Shaping Our Future.
Rick Prelinger is an archivist, filmmaker, writer and educator.
Book Talk: Memory, Edited September 20 @ 6pm PT IN-PERSON @ 300 Funston Avenue, SF Register now!
When Graeme Currie was working at a university, he went to the campus library for research and often lingered in the stacks just to enjoy the collection.
Now, as a freelance translator and editor operating remotely from a small town near Hamburg, Germany, Currie doesn’t have that same access. Without an institutional affiliation, he relies on materials in the Internet Archive for his work.
“It’s been vital for me because, at times, it’s the only way I can find what I need,” says Currie, 51, who is originally from Scotland. “For freelancers who are working from home without a library nearby and using obscure sources and out-of-print books, there’s nothing to replace the Internet Archive.”
Currie first heard about the Wayback Machine in the early 2000s as a means to check changes in websites. Then, he discovered other services that the Internet Archive provides including its audio and book library.
“For freelancers who are working from home without a library nearby and using obscure sources and out-of-print books, there’s nothing to replace the Internet Archive.”
Graeme Currie, freelance translator & editor
As he edits and translates academic books from German to English, Currie says he often has to check book citations—looking up page numbers and verifying passages. The virtual collection has been helpful as he researches a range of topics in the arts, social sciences and the humanities. Currie says he’s borrowed titles related to philosophy, criminality and global urban history, including the early history of tourism in Sicily.
Not only are many of the books hard to find, but Currie says logistically, they are difficult to obtain. Without the Internet Archive, Currie says he would have to wait weeks for interlibrary loans or try to contact the book authors, who are often unavailable.
“I simply could not do my job without access to a virtual library,” says Currie, who has been freelancing for about five years. “The Internet Archive is like having a university library on your desktop.”
















{kind=link}