Kevin Hegg is Head of Digital Projects at James Madison University Libraries (JMU). Kevin has held many technology positions within JMU Libraries. His experience spans a wide variety of technology work, from managing computer labs and server hardware to developing a large open-source software initiative. We are thankful to Kevin for taking time to talk with us about his experience with ARCH (Archives Research Compute Hub), AI, and supporting research at JMU.
Thomas Padilla is Deputy Director, Archiving and Data Services.
Thomas: Thank you for agreeing to talk more about your experience with ARCH, AI, and supporting research. I find that folks are often curious about what set of interests and experiences prepares someone to work in these areas. Can you tell us a bit about yourself and how you began doing this kind of work?
Kevin: Over the span of 27 years, I have held several technology roles within James Madison University (JMU) Libraries. My experience ranges from managing computer labs and server hardware to developing a large open-source software initiative adopted by numerous academic universities across the world. Today I manage a small team that supports faculty and students as they design, implement, and evaluate digital projects that enhance, transform, and promote scholarship, teaching, and learning. I also co-manage Histories Along the Blue Ridge which hosts over 50,000 digitized legal documents from courthouses along Virginia’s Blue Ridge mountains.
Thomas: I gather that your initial interest in using ARCH was to see what potential it afforded for working with James Madison University’s Mapping Black Digital and Public Humanities project. Can you introduce the project to our readers?
Kevin: The Mapping the Black Digital and Public Humanities project began at JMU in Fall 2022. The project draws inspiration from established resources such as the Colored Convention Project and the Reviews in Digital Humanities journal. It employs Airtable for data collection and Tableau for data visualization. The website features a map that not only geographically locates over 440 Black digital and public humanities projects across the United States but also offers detailed information about each initiative. The project is a collaborative endeavor involving JMU graduate students and faculty, in close alliance with JMU Libraries. Over the past year, this interdisciplinary team has dedicated hundreds of hours to data collection, data visualization, and website development.
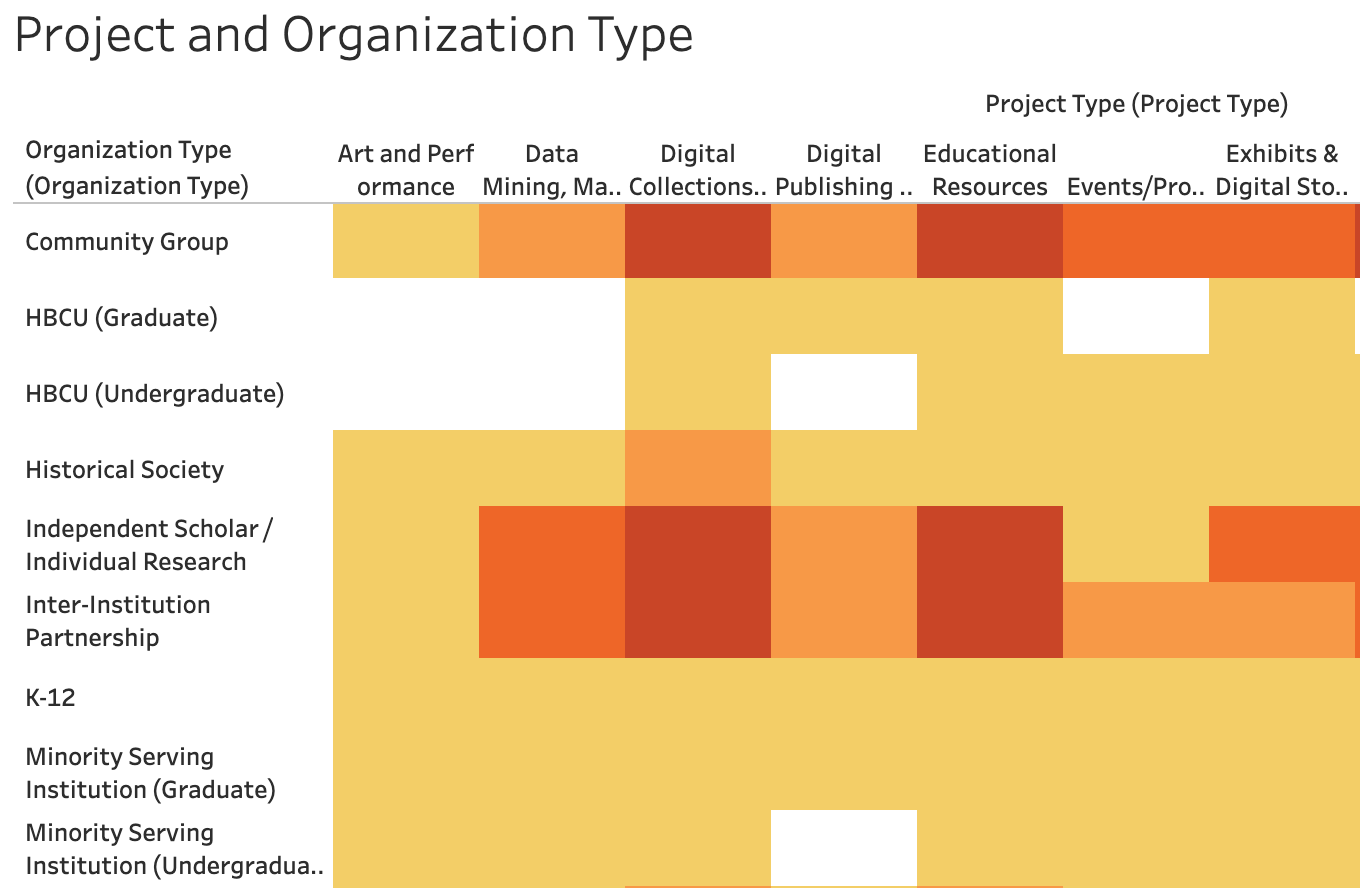
The project has achieved significant milestones. In Fall 2022, Mollie Godfrey and Seán McCarthy, the project leaders, authored, “Race, Space, and Celebrating Simms: Mapping Strategies for Black Feminist Biographical Recovery“, highlighting the value of such mapping projects. At the same time, graduate student Iliana Cosme-Brooks undertook a monumental data collection effort. During the winter months, Mollie and Seán spearheaded an effort to refine the categories and terms used in the project through comprehensive research and user testing. By Spring 2023, the project was integrated into the academic curriculum, where a class of graduate students actively contributed to its inaugural phase. Funding was obtained to maintain and update the database and map during the summer.
Looking ahead, the project team plans to present their work at academic conferences and aims to diversify the team’s expertise further. The overarching objective is to enhance the visibility and interconnectedness of Black digital and public humanities projects, while also welcoming external contributions for the initiative’s continual refinement and expansion.
Thomas: It sounds like the project adopts a holistic approach to experimenting with and integrating the functionality of a wide range of tools and methods (e.g., mapping, data visualization). How do you see tools like ARCH fitting into the project and research services more broadly? What tools and methods have you used in combination with ARCH?
Kevin: ARCH offers faculty and students an invaluable resource for digital scholarship by providing expansive, high-quality datasets. These datasets enable more sophisticated data analytics than typically encountered in undergraduate pedagogy, revealing patterns and trends that would otherwise remain obscured. Despite the increasing importance of digital humanities, a significant portion of faculty and students lack advanced coding skills. The advent of AI-assisted coding platforms like ChatGPT and GitHub CoPilot has democratized access to programming languages such as Python and JavaScript, facilitating their integration into academic research.
For my work, I employed ChatGPT and CoPilot to further process ARCH datasets derived from a curated sample of 20 websites focused on Black digital and public humanities. Utilizing PyCharm—an IDE freely available for educational purposes—and the CoPilot extension, my coding efficiency improved tenfold.
Next, I leveraged ChatGPT’s Advanced Data Analysis plugin to deconstruct visualizations from Stanford’s Palladio platform, a tool commonly used for exploratory data visualizations but lacking a means for sharing the visualizations. With the aid of ChatGPT, I developed JavaScript-based web applications that faithfully replicate Palladio’s graph and gallery visualizations. Specifically, I instructed ChatGPT to employ the D3 JavaScript library for ingesting my modified ARCH datasets into client-side web applications. The final products, including HTML, JavaScript, and CSV files, were made publicly accessible via GitHub Pages (see my graph and gallery on GitHub Pages)
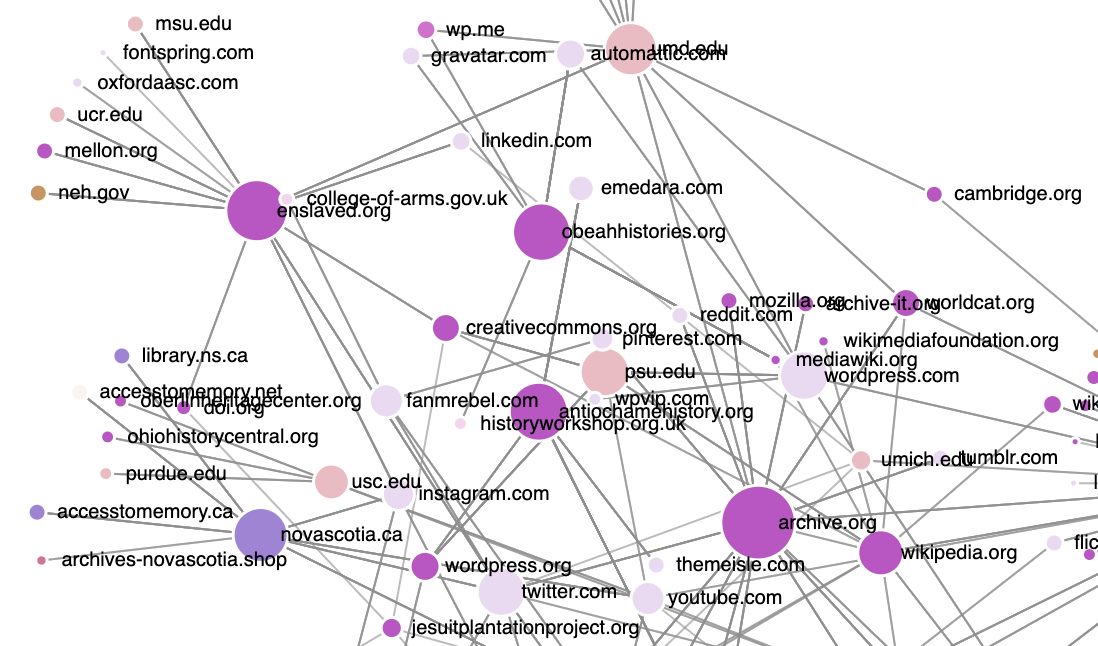
In summary, the integration of Python and AI-assisted coding tools has not only enhanced my use of ARCH datasets but also enabled the creation of client-side web applications for data visualization.
Thomas: Beyond pairing ChatGPT with ARCH, what additional uses are you anticipating for AI-driven tools in your work?
Kevin: AI-driven tools have already radically transformed my daily work. I am using AI to reduce or even eliminate repetitive, mindless tasks that take tens or hundreds of hours. For example, as part of the Mapping project, ChatGPT+ helped me transform an AirTable with almost 500 rows and two dozen columns into a series of 500 blog posts on a WordPress site. ChatGPT+ understands the structure of a WordPress export file. After a couple of hours of iterating through my design requirements with ChatGPT, I was able to import 500 blog posts into a WordPress website. Without this intervention, this task would have required over a hundred hours of tedious copying and pasting. Additionally, we have been using AI-enabled platforms like Otter and Descript to transcribe oral interviews.
I foresee AI-driven tools playing an increasingly pivotal role in many facets of my work. For instance, natural language processing could automate the categorization and summarization of large text-based datasets, making archival research more efficient and our analyses richer. AI can also be used to identify entities in large archival datasets. Archives hold a treasure trove of artifacts waiting to be described and discovered. AI offers tools that will supercharge our construction of finding aids and item-level metadata.
Lastly, AI could facilitate more dynamic and interactive data visualizations, like the ones I published on GitHub Pages. These will offer users a more engaging experience when interacting with our research findings. Overall, the potential of AI is vast, and I’m excited to integrate more AI-driven tools into JMU’s classrooms and research ecosystem.
Thomas: Thanks for taking the time Kevin. To close out, whose work would you like people to know more about?
Kevin: Engaging in Digital Humanities (DH) within the academic library setting is a distinct privilege, one that requires a collaborative ethos. I am fortunate to be a member of an exceptional team at JMU Libraries, a collective too expansive to fully acknowledge here. AI has introduced transformative tools that border on magic. However, loosely paraphrasing Immanuel Kant, it’s crucial to remember that technology devoid of content is empty. I will use this opportunity to spotlight the contributions of three JMU faculty whose work celebrates our local community and furthers social justice.
Mollie Godfrey (Department of English) and Seán McCarthy (Writing, Rhetoric, and Technical Communication) are the visionaries behind two inspiring initiatives: the Mapping Project and the Celebrating Simms Project. The latter serves as a digital, post-custodial archive honoring Lucy F. Simms, an educator born into enslavement in 1856 who impacted three generations of young students in our local community. Both Godfrey and McCarthy have cultivated deep, lasting connections within Harrisonburg’s Black community. Their work strikes a balance between celebration and reparation. Collaborating with them has been as rewarding as it is challenging.
Gianluca De Fazio (Justice Studies) spearheads the Racial Terror: Lynching in Virginia project, illuminating a grim chapter of Virginia’s past. His relentless dedication led to the installation of a historical marker commemorating the tragic lynching of Charlotte Harris. De Fazio, along with colleagues, has also developed nine lesson plans based on this research, which are now integrated into high school curricula. My collaboration with him was a catalyst for pursuing a master’s degree in American History.
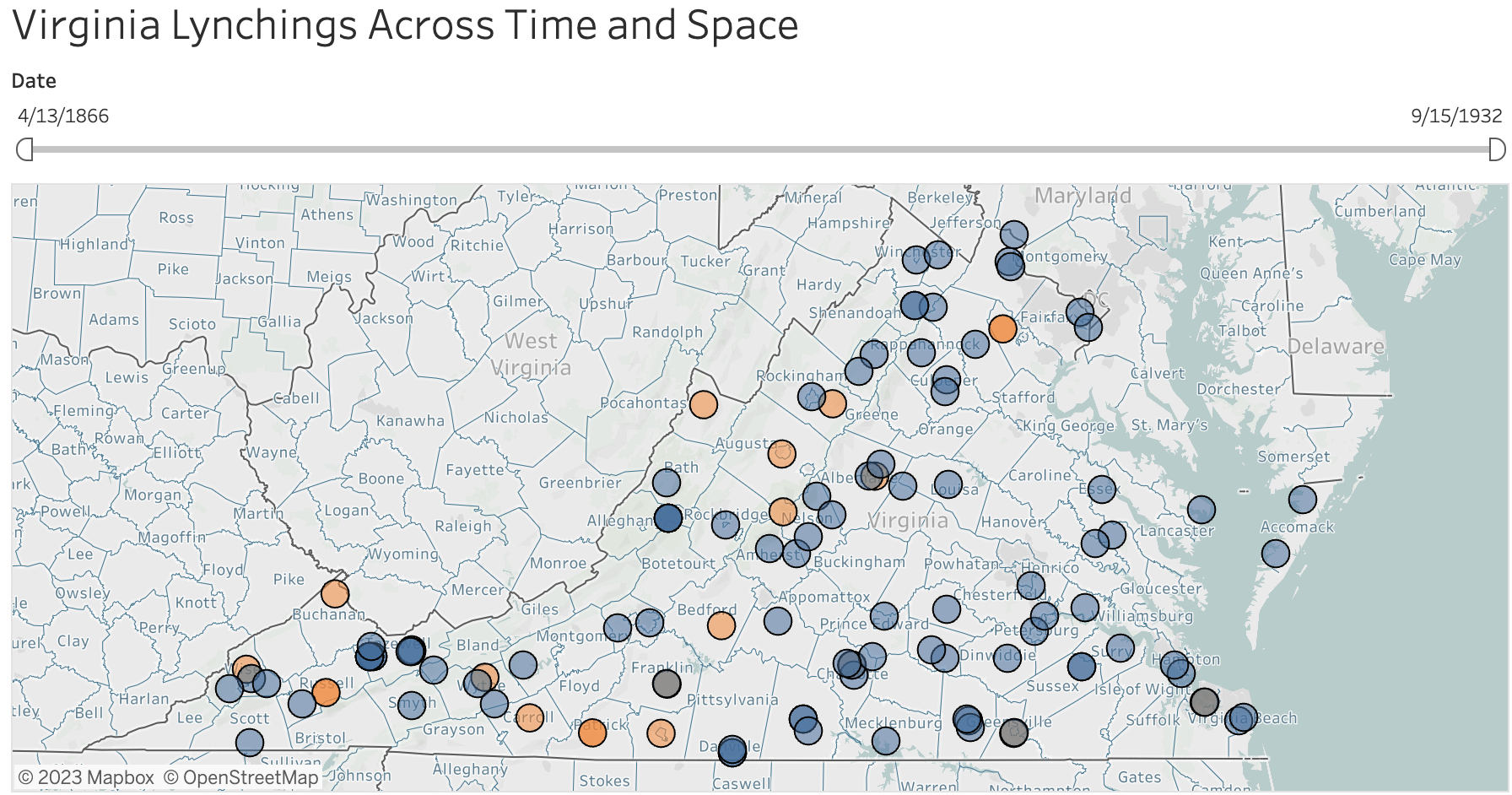
Both the Celebrating Simms and Racial Terror projects are highlighted in the Mapping the Black Digital and Public Humanities initiative. The privilege of contributing to such impactful projects alongside such dedicated individuals has rendered my extensive tenure at JMU both meaningful and, I hope, enduring.


