This post was originally published in a newsletter by Project Liberty, February 20, 2024. Image by Project Liberty.
In the summer of 2023, the New York Times ran an article titled “Ways You Can Still Cancel Your Federal Student Loan Debt.”
The article outlined six ways to cancel student debt, with the final being:
“Death
This is not something that most people would choose as a solution to their debt burden.”
At least that was the sixth reason until the New York Times revised it with a stealth edit. When you read the article today, choosing death as a solution to a debt burden has been replaced, but there’s no mention that this article was revised. The timestamp is still the day it was originally published.
If not for Internet Archive’s Wayback Machine, this discrepancy wouldn’t have been caught. The Wayback Machine is a digital archive of the internet, and as such, it captured multiple previous versions.
The internet is constantly being revised in ways that allow history to be rewritten and a shared sense of truth to be questioned. With AI-generated disinformation, the potential to exert control over the future by rewriting the past has never been greater.
This week we’re exploring how digital archives are crucial in developing a record of truth in an ever-changing web.
The need for digital archives

Mark Graham, Director of the Wayback Machine, spoke with the Project Liberty Foundation and shared the key reasons why there’s an even greater need for digital archives:
The importance of the internet. So much of what humanity publishes and makes available lives only on the internet. Given how much time we spend online, the internet has become a central medium of human expression, history, and culture.
The fragile and ephemeral nature of the internet. Graham shared two stats that underscore how fragile today’s internet is:
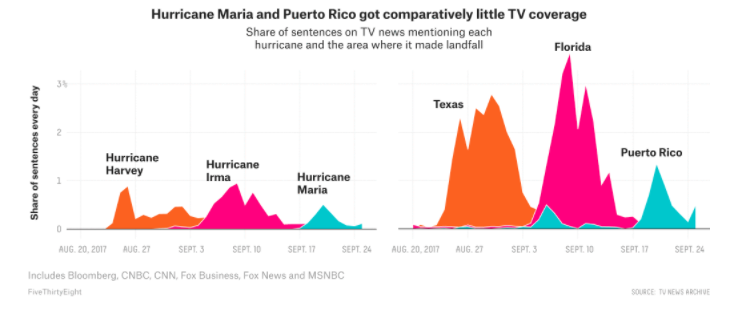
- A study found that of the two million hyperlinks in New York Times articles from 1996 to 2019, 25% of all links were broken (described as link rot).
- The Wayback Machine has fixed 20 million broken links in Wikipedia articles with the correct ones.
“The web itself is a living thing. Webpages change. They go away on quite a frequent basis. There’s no backup system or version control system for the web,” Graham explained. That is, except for archives like the Wayback Machine.
The Wayback Machine
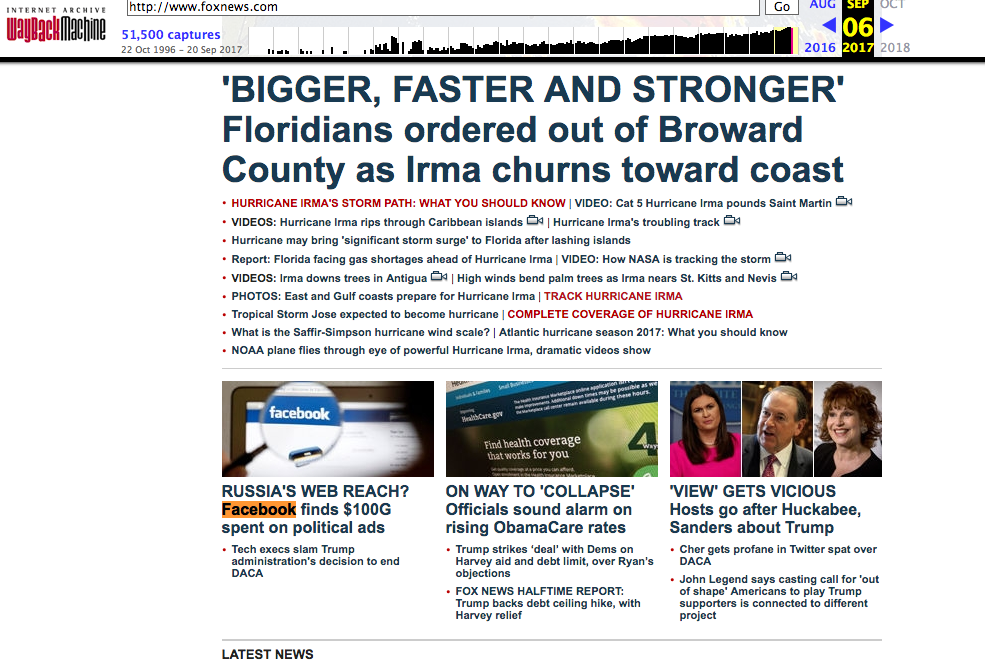
The Wayback Machine is a “time machine for the web,” in Graham’s words. It allows users to trace the evolution (or disappearance) of a webpage over time, enabling them to establish a record of what happened on the internet.
- For example, the Apple.com URL has been archived 539,000 times since its first archived page in October 1996.
- The Wayback Machine has archived over 866 billion webpages in its 28-year history. Today, it archives hundreds of millions of webpages every day and has become one of the most important archives of online content in the world.
How it works
- The Wayback Machine “crawls” the web and downloads publicly accessible information. Webpages, documents, and data are stored with a time-stamped URL.
- For information that’s not publicly accessible, Internet Archive offers web archiving services through Archive-It for 1,200 organizations in 24 countries around the world (from libraries to research institutions).
- The Wayback Machine supports everyday people to help it archive the internet. Anyone can go to Save Page Now to archive a webpage or article.
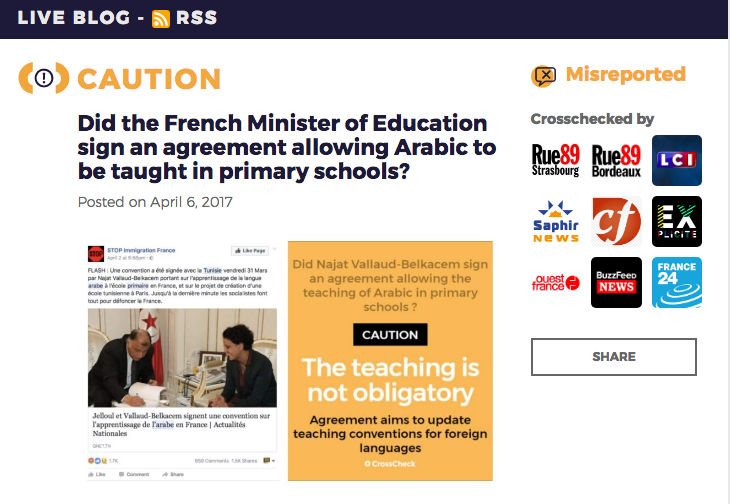
- The Wayback Machine partners with 1,200 fact-checking organizations globally to help it reference material on the web that was the source of disinformation. It has built a library of more than 200,000 examples where a claim has been made, and the Wayback Machine has provided additional context on if that claim is true (known as a review of the claim).
Archive of facts
Fixing links, archiving webpages, and fact-checking digital articles are part of a deeper, more important project to chronicle digital history and establish a record of facts.
- Last month, the archive of press releases from a sitting member of Congress, New York’s Elise Stefanik, vanished after she came under scrutiny. The Wayback Machine documented this erasure and provided a time-stamped record of past versions of her website and press releases.
- In 2018, a US Appeals court ruled that the Wayback Machine’s archive of webpages can be used as legitimate legal evidence.
- The Internet Archive has countless examples of when the press have referenced the Wayback Machine to correct disinformation and dispel rumors. In one example from last year, the Associated Press relied on the Wayback Machine to set the record that the CDC did not say the polio vaccine gave millions of Americans a “cancer virus.”
With the rise of AI-generated disinformation, there’s reason to believe such attempts at rewriting history (even if that history is just yesterday) will become more prevalent and the social contract that has governed web crawlers is coming to an end.
A citizen-powered web
Building digital archives is a bulwark against those attempting to rewrite history and spread misinformation. An archived, time-stamped webpage is not just unimpeachable evidence, it’s a foundational building block of a shared sense of reality.
In 2014, when Malaysia Airlines Flight 17 went down over Ukraine, the Wayback Machine captured evidence that a pro-Russian group was behind the missile attack. But it wasn’t the Wayback Machine’s algorithms that captured the evidence by crawling the internet; it was an individual who found an obscure blog post from a Ukrainian separatist leader touting the shooting down of a plane. That individual identified the blogpost as important enough to be archived, and it became a critical piece of evidence, even after that post disappeared from the internet.
As Graham said, “You don’t know what you got until it’s gone. If you see something, save something.”
What pages can you help archive? Archive them with the Wayback Machine on Save Page Now.









 this tour through the 20th century, the Time Machine was set to 1997. Mark Graham, Director of the
this tour through the 20th century, the Time Machine was set to 1997. Mark Graham, Director of the