Aruba’s Prime Minister, Evelyn Wever-Croes: “Give them the opportunity to search for the truth.”
Last week Aruba launched the island nation’s digital heritage portal online: Coleccion Aruba. As trumpeted in Wired:“The Internet Archive Just Backed Up an Entire Caribbean Island,” but really the credit goes to Aruba. Digitizing their national cultural heritage (100k items) and putting it online for free public access is a huge achievement.
I met with the Prime Minister (pictured above), the Minister of Culture, and the Minister of Education who backed the efforts made by the National Librarian, National Archivist, and their digital strategist. Never have I seen such unified support for cultural preservation and access. They brought together people from the Dutch islands and the Internet Archive to share the news and to inspire and to lead.
Aruba was the first to sign onto the Four Digital Rights of Memory Institutions: right to Collect, Preserve, provide Access, and interlibrary Collaboration. These are bad times when we have to reclaim these rights that are being taken from all libraries, but Aruba is making a stand. Go Aruba!
Aruba’s National Librarian, Astrid Britten, signs the Four Rights, as the National Archivist, Raymond Hernandez, and Brewster Kahle look on.
If libraries are reduced to only subscribing to commercial database products rather than owning and curating collections, we will be beholden to external corporations and subject to their whims over what’s in licensed collections, and how patrons can access them. The “Spotify for Books” model is not the way we want our libraries to go.
To top it off, the Prime Minister, Evelyn Wever-Croes, inspired us when she told us that for the next generation, we need to “Give them the opportunity to search for the truth.” Yes.
Inspiring to see a country lead so well. I hope we have the honor of working with other nations that will also assert Digital Rights for Libraries, and live by those principles.
From left: Aruba’s National Librarian, Astrid Britten (Director, Biblioteca Nacional Aruba), signs the statement protecting memory organizations online as Raymond Hernandez (Director, Archivo Nacional Aruba) and Brewster Kahle (Founder, Internet Archive) look on.
This was a week of firsts in Aruba. The small island nation in the southern Caribbean launched its new heritage portal, the Aruba Collection (Coleccion Aruba), and it became the first country to sign a statement to protect the digital rights of libraries & other memory institutions.
Internet Archive founder Brewster Kahle and Chris Freeland, director of library services at the Archive, attended the signing ceremony in Aruba, a country in the Kingdom of the Netherlands located 18 miles north of Venezuela.
Support for the statement, Four Digital Rights For Protecting Memory Institutions Online, was spearheaded by Peter Scholing, information scientist and researcher at the country’s national library, Biblioteca Nacional Aruba (BNA). Last fall, he learned about the need for library digital rights to be championed during a conference at the Internet Archive in San Francisco. While much of that discussion was based on the 2022 report, “Securing Digital Rights for Libraries: Towards an Affirmative Policy Agenda for a Better Internet,” authored by Lila Bailey and Michael Menna, and focused on protecting library access to e-books, Scholing was interested in Aruba making a broader statement—one encompassing all memory institutions and the diverse types of materials they house.
“Over the last few months we’ve brainstormed about these digital rights and how to broaden the statement to make it relevant to not only libraries, but also for memory institutions and GLAMs in general,” said Scholing, using the acronym for galleries, libraries, archives & museums. “In that sense, it has become a near universal declaration for open access to information, in line with the United Nations’ Sustainable Development Goals (UN 2030 Agenda/Sustainable Development Goals, #16.10) or other statements on open access to documentary, cultural or digital heritage. This aligns almost perfectly with what we aim to achieve here on Aruba—universal access to “our” information.”
Many memory institutions on the island have long worked together to digitize collections including books, government documents, photos and videos. The statement reinforces the importance of libraries, archives, museums and other memory institutions being able to fulfill their mission by preserving knowledge for the public to access.
Initial Signing Organizations
Archivo Nacional Aruba (ANA)
Aruban National Committee for UNESCO’s Memory of the World Programme
Biblioteca Nacional Aruba (BNA)
Coleccion Aruba
Museo Arkeologico Nacional Aruba (MANA)
Stichting Monumentenfonds Aruba
Union di Organisacionnan Cultural Arubano (UNOCA)
The statement asserts that the rights and responsibilities that memory institutions have always enjoyed offline must also be protected online. To accomplish this goal, libraries, archives and museums must have the legal rights and practical ability to:
Collect digital materials, including those made available only via streaming and other restricted means, through purchase on the open market or any other legal means, no matter the underlying file format;
Preserve those materials, and where necessary repair or reformat them, to ensure their long-term existence and availability;
Provide controlled access to digital materials for advanced research techniques and to patrons where they are—online;
Cooperate with other memory institutions, by sharing or transferring digital collections, so as to provide more equitable access for communities in remote and less well-funded areas.
In Aruba, Scholing said library and archive leaders believed strongly that these rights should be upheld with a public endorsement. Michael Menna, co-author of the statement and the 2022 report, saw this as a key first step in building a coalition of memory institutions.
“Aruba has been brave to make such a clear and unequivocal statement about the many challenges facing libraries, archives, and museums,” said Menna. “Simply put, these essential institutions need better protections to adapt their services to today’s media environment. Hopefully, after hearing Aruba speak out, others can follow suit.”
Report co-author Lila Bailey, senior policy counsel at the Internet Archive, said that seeing the statement embraced and endorsed by memory institutions is rewarding.
“It is a thrill to see Aruba leading the way towards a better digital future for memory institutions worldwide,” said Bailey. “These institutions must meet the needs of a modern public using the best tools available. It is good public policy and basic common sense that libraries, archives and museums should be not only permitted but encouraged to leverage digital technologies to serve their essential public functions.”
The statement can be endorsed by governments, organizations, and individuals following a verification process. If you are interested in signing the statement, or would like to learn more, please complete the initial online inquiry, or e-mail Chris Freeland, Internet Archive’s director of library services, at chrisfreeland@archive.org.
Ham Radio & More was the first radio show devoted to ham radio on the commercial radio band. It began as a one-hour show on KFNN 1510 AM in Phoenix, Arizona, then expanded to a two-hour format and national syndication. The program’s host, Len Winkler, invited guests to discuss the issues of the day and educate listeners about various aspects of the radio hobby. Today the episodes, some more than 30 years old, provide an invaluable time capsule of the ham radio hobby.
just some of the HR&M cassette tapes
Len Winkler said, “I’m so happy that the Digital Library of Amateur Radio & Communications took all my old shows and made them eternally available for everyone to hear and enjoy. I had the absolute pleasure, along with a few super knowledgeable co-hosts, to interview many of the people that made ham radio great in the past and now everyone can go back and listen to what they had to say. From the early beginnings of SETI (search for extraterrestrial intelligence) to Senator Barry Goldwater to the daughter of Marconi. So much thanks to the Digital Library of Amateur Radio & Communications for doing this amazing service.”
Other interviewees included magazine publisher Wayne Green, Sheriff Joe Arpaio, Bob Heil, Bill Pasternak, Fred Maia, and other names well known to the amateur radio community. Discussion topics spanned the technical, such as signal propagation, to community issues, including the debate over the Morse code knowledge requirement for ham radio operators—a requirement eventually dropped, to the benefit of the community.
The radio programs were recorded on cassette tapes when they originally aired. Winkler digitized 149 episodes of the show himself in 2015 and 2016. The digitizing project paused for years. In January 2024 he sent the remaining cassettes to DLARC. Using two audio digitizing workstations, we digitized another 165 episodes in about three weeks. The combined collection is now available online: a total of 464 hours of programming, most of which have not been heard since their original air date. The collection represents nearly every episode of the show: only a few tapes went missing over the years or were unrepairable.
The Digital Library of Amateur Radio & Communications is funded by a grant from Amateur Radio Digital Communications (ARDC) to create a free digital library for the radio community, researchers, educators, and students. DLARC invites radio clubs and individuals to submit material in any format. To contribute or ask questions about the project, contact: Kay Savetz at kay@archive.org or on Mastodon at dlarc@mastodon.radio.
Hundreds of people from all over the world gathered together on January 25 to honor the thousands of movies, plays, books, poems and songs that recently entered the U.S. public domain.
Steamboat Willie, Walt Disney’s 1928 animated film featuring Mickey Mouse, had top billing at the virtual event. Literature now free from restriction for reuse includes Orlando by Virginia Woolf and Tarzan Lord of the Jungle by Edgar R. Burroughs. Sound recordings from 1923 (released on a different schedule) joined the public domain such as ”Down Hearted Blues” by Bessie Smith and ”Who’s Sorry Now” by Isham Jones Orchestra.
WATCH RECORDING:
“There’s so much to rediscover and to celebrate,” said Jennifer Jenkins, director of the Center for the Study of the Public Domain at Duke Law School. For example, the release of The Great Gatsby into the public domain in 2021 inspired a creative flurry — new versions of the novel from the perspective of different characters, a prequel telling the backstory of Nick Caraway, a young adult remix, and song. “From the serious to the creative, to the whimsical to the wacky, these are all the great things we can do…now that [these works] are in the public domain and free to copy, to share, to digitize and to build upon without permission or fee.”
The winning film from the Public Domain Day 2024 Remix Contest was shown as well: “Sick on New Year’s,” by Ty Cummings. Every year since 2021, this contest has invited artists to remix works from its collection to showcase new and creative uses of public domain materials. Fifty films were submitted to this year’s competition, according to Amir Esfahania, artist in residence at the Archive. Learn more about the finalists or watch all the submissions in our recent blog post.
Advocacy
“Celebrating the public domain is not just about vintage references and period-appropriate clothing. It’s about understanding history to inform the present day,” said Lila Bailey, Internet Archive senior policy counsel and co-host of the virtual festivities. “We think there should be time set aside every year to celebrate the immense riches that free and open culture provides to everyone.”
While federal holiday recognition (like MLK Day or Presidents’ Day) for the public domain is unlikely, there was a discussion of an advocacy campaign for establishment of a commemorative Public Domain Day (more along the lines of National Data Privacy Day or National Whistleblowers Day).
“It only requires a simple resolution in the Senate with high chances of recognition,” said Amanda Levendowski, director of Georgetown Law School’s Intellectual Property and Information Policy Clinic. “Prospects for passage are way better than possible. About 80 percent of proposals are passed — and maybe next year, Public Domain Day will be among them.”
Experts said a successful drive for the designation will require a collaborative effort. A kickoff event will be held February 29 in New York City, hosted by Library Futures, executive director Jennie-Rose Halperin announced.
AI and the Public Domain
The online program also featured a panel discussion on generative artificial intelligence, copyright and artist expression. Experts weighed in on just what should be the copyright status of the outputs of generative AI.
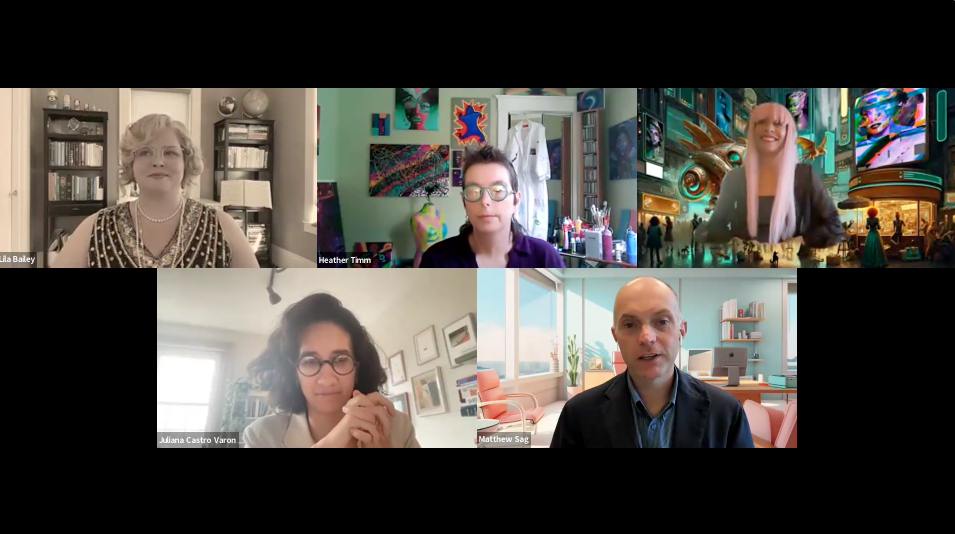
Panelists (clockwise from top left): Lila Bailey (Internet Archive), Heather Timm (artist), Maxximillian (artist), Matthew Sag (Emory Law), and Juliana Castro Varón (Cita Press).
Now, AI tools can turn text or simple descriptions into images that are genuinely new and often look like exactly the kind of things that people get copyrighted if a human made them, explained Matthew Sag, professor of law, artificial intelligence, machine learning, and data science at Emory University.
“The copyright office is quite clear that to get copyright, you have to have human authorship. So something created entirely by an unsupervised machine is not eligible for copyright,” Sag said, noting that the courts have recently agreed. “The interesting question is what about when humans are using AI as a tool and directing the output. This is where the controversy really is.”
On the panel, two artists, Heather Timm and Maxximillian, shared how they both leverage AI in the creative process.
Timm said she started using generative AI in 2021 and thinks the copyright office should cover works that have results from it. She has trained AI models on her own physical work and then created something new collaborating with the machine, as well as conceptualized how to blend different pieces of work in a collage or sculpture.
“I use it almost as a notebook,” Timm said. “If I have a concept or an idea about something on the go, I can immediately prompt that and have it as a placeholder to explore it later.”
As a filmmaker and musician, Maxximillian said she feels passionate about AI and it has saved her time creating animated characters and helping refine her text. “As a professional artist, I rely on copyright to keep viable the works that I produce for clients legally,” said Maxximillian. “It’s important to understand that copyright protection enables the creator to be a steward of that work. The question to consider: Who benefits by denying copyright on AI? I think nobody benefits.”
An open access publisher, Juliana Castro Varón, design director and founder of Cita Press, also addressed the issue. “I believe that AI may pose economic, power, and labor challenges, but I feel very confident that creativity will survive technology,” she said. All books Cita produces are in the public domain for everyone to download. “We are not at all against people using AI for their work, but we continue to hire humans…elevating the work of people is core to our mission.”
***
The event was co-hosted by Internet Archive and Library Futures with support from Creative Commons, Authors Alliance, Public Knowledge, SPARC and Duke Law’s Center for the Study of the Public Domain.
We are looking for filmmakers and artists of all levels to create and upload short films of 2–3 minutes to the Internet Archive to help us celebrate Public Domain Day at our celebrations on January 24 (in-person screening & party) & January 25 (virtual celebration), 2024!
Our short film contest serves as a platform for filmmakers to explore, remix, and breathe new life into the timeless gems that have entered the public domain. From classic literature and silent films to musical compositions and visual art, the contest winners draw inspiration from the vast archive of cultural heritage from 1928. We want artists to use this newly available content to create short films using resources from the Internet Archive’s collections from 1928. The uploaded videos will be judged and prizes of up to $1500 awarded!! (see details below)
Winners will be announced and shown at the in-person Public Domain Day Celebration at the Internet Archive headquarters in San Francisco on January 24, 2024, as well as our virtual celebration on January 25. All other participating videos will be added to a Public Domain Day Collection on archive.org and featured in a blog entry in January of 2024.
Here are a few examples of some of the materials that will become public domain on January 1, 2024:
Make a 2–3 minute movie using at least one work published in 1928 that will become Public Domain on January 1, 2024. This could be a poem, book, film, musical composition, painting, photograph or any other work that will become Public Domain next year. The more different PD materials you use, the better!
Note: If you have a resource from 1928 that is not available on archive.org, you may upload it and then use it in your submission. (Here is how to do that).
Your submission must have a soundtrack. It can be your own voiceover or performance of a public domain musical composition, or you may use public domain or CC0 sound recordings from sources like Openverse and the Free Music Archive.
Note: Music copyright is TRICKY! Currently sound recordings published up to December 31, 1922 are public domain; on the upcoming January 1 that will change to sound recordings published up to December 31, 1923. Sound recordings published later than that are NOT public domain, even if the underlying musical composition is, so watch out for this!
Mix and Mash content however you like, but note that ALL of your sources must be from the public domain. They do not all have to be from 1928. Remember, U.S. government works are public domain no matter when they are published. So feel free to use those NASA images! You may include your own original work if you put a CC0 license on it.
Add a personal touch, make it yours!
Keep the videos light hearted and fun! (It is a celebration after all!)
Submission Deadline
All submissions must be in by Midnight, January 19, 2024 (PST) by loading it into this collection on the Internet Archive.
Upload your film to archive.org with a subject tag field of “public domain day film contest 2024” in the upload form by January 17, 2024. This is the collection it will be archived in.
Link all your sourced materials from 1928 in the upload description
Prizes
1st prize: $1500
2nd prize: $1000
3rd prize: $500
*All prizes sponsored by the Kahle/Austin Foundation
Judges:
Judges will be looking for videos that are fun, interesting and use public domain materials, especially those from 1928. They will be shown at the in-person Public Domain Day party in San Francisco and should highlight the value of having cultural materials that can be reused, remixed, and re-contextualized for a new day. Winners’ pieces will be purchased with the prize money, and viewable on the Internet Archive under a Creative Commons license.
Amir Saber Esfahani (Director of Special Arts Projects, Internet Archive)
Rick Prelinger (Board Member, Internet Archive, Founder, Prelinger Archives)
BZ Petroff (Director of Admin & HR, Internet Archive)
At this year’s annual celebration in San Francisco, the Internet Archive team showcased its innovative projects and rallied supporters around its mission of “Universal Access to All Knowledge.”
Brewster Kahle, Internet Archive’s founder and digital librarian, welcomes hundreds of guests to the annual celebration on October 12, 2023.
“People need libraries more than ever,” said Brewster Kahle, founder of the Internet Archive, at the October 12 event. “We have a set of forces that are making libraries harder and harder to happen—so we have to do something more about it.”
Efforts to ban books and defund libraries are worrisome trends, Kahle said, but there are hopeful signs and emerging champions.
Watch the full live stream of the celebration
Among the headliners of the program was Connie Chan, Supervisor of San Francisco’s District 1, who was honored with the 2023 Internet Archive Hero Award. In April, she authored and unanimously passed a resolution at the San Francisco Board of Supervisors, backing the Internet Archive and the digital rights of all libraries.
Chan spoke at the event about her experience as a first-generation, low-income immigrant who relied on books in Chinese and English at the public library in Chinatown.
Watch Supervisor Chan’s acceptance speech
“Having free access to information was a critical part of my education—and I know I was not alone,” said Chan, who is a supporter of the Internet Archive’s role as a digital, online library. “The Internet Archive is a hidden gem…It is very critical to humanity, to freedom of information, diversity of information and access to truth…We aren’t just fighting for libraries, we are fighting for our humanity.”
Several users shared testimonials about how resources from the Internet Archive have enabled them to advance their research, fact-check politicians’ claims, and inspire their creative works. Content in the collection is helping improve machine translation of languages. It is preserving international television news coverage and Ukrainian memes on social media during the war with Russia.
Quinn Dombrowski, of the Saving Ukrainian Cultural Heritage Online project, shows off Ukrainian memes preserved by the project.
Technology is changing things—some for the worse, but a lot for the better, said David McRaney, speaking via video to the audience in the auditorium at 300 Funston Ave. “And when [technology] changes things for the better, it’s going to expand the limited capabilities of human beings. It’s going to extend the reach of those capabilities, both in speed and scope,” he said. “It’s about a newfound freedom of mind, and time, and democratizing that freedom so everyone has access to it.”
Open Library developer Drini Cami explained how the Internet Archive is using artificial intelligence to improve access to its collections.
When a book is digitized, it used to be that photographs of pages had to be manually cropped by scanning operators. The Internet Archive recently trained a custom machine learning model to automatically suggest page boundaries—allowing staff to double the rate of process. Also, an open-source machine learning tool converts images into text, making it possible for books to be searchable, and for the collection to be available for bulk research, cross-referencing, text analysis, as well as read aloud to people with print disabilities.
Open Library developer Drini Cami.
“Since 2021, we’ve made 14 million books, documents, microfiche, records—you name it—discoverable and accessible in over 100 languages,” Cami said.
As AI technology advanced this year, Internet Archive engineers piloted a metadata extractor, a tool that automatically pulls key data elements from digitized books. This extra information helps librarians match the digitized book to other cataloged records, beginning to resolve the backlog of books with limited metadata in the Archive’s collection. AI is also being leveraged to assist in writing descriptions of magazines and newspapers—reducing the time from 40 to 10 minutes per item.
“Because of AI, we’ve been able to create new tools to streamline the workflows of our librarians and the data staff, and make our materials easier to discover, and work with patrons and researchers, Cami said. “With new AI capabilities being announced and made available at a breakneck rate, new ideas of projects are constantly being added.”
Jamie Joyce & AI hackathon participants.
A recent Internet Archive hackathon explored the risks and opportunities of AI by using the technology itself to generate content, said Jamie Joyce, project lead with the organization’s Democracy’s Library project. One of the hackathon volunteers created an autonomous research agent to crawl the web and identify claims related to AI. With a prompt-based model, the machine was able to generate nearly 23,000 claims from 500 references. The information could be the basis for creating economic, environmental and other arguments about the use of AI technology. Joyce invited others to get involved in future hackathons as the Internet Archive continues to expand its AI potential.
Peter Wang, CEO and co-founder at Anaconda, said interesting kinds of people and communities have emerged around cultures of sharing. For example, those who participate in the DWeb community are often both humanists and technologists, he said, with an understanding about the importance of reducing barriers to information for the future of humanity. Wang said rather than a scarcity mindset, he embraces an abundant approach to knowledge sharing and applying community values to technology solutions.
Peter Wang, CEO and co-founder at Anaconda.
“With information, knowledge and open-source software, if I make a project, I share it with someone else, they’re more likely to find a bug,” he said. “They might improve the documentation a little bit. They might adapt it for a novel use case that I can then benefit from. Sharing increases value.”
The Internet Archive’s Joy Chesbrough, director of philanthropy, closed the program by expressing appreciation for those who have supported the digital library, especially in these precarious times.
“We are one community tied together by the internet, this connected web of knowledge sharing. We have a commitment to an inclusive and open internet, where there are many winners, and where ethical approaches to genuine AI research are supported,” she said. “The real solution lies in our deep human connection. It inspires the most amazing acts of generosity and humanity.”
***
If you value the Internet Archive and our mission to provide “Universal Access to All Knowledge,” please consider making a donation today.
Announced today, Connie Chan, Supervisor of San Francisco’s District 1, will receive the 2023 Internet Archive Hero Award. Supervisor Chan will be presented the award on stage at next week’s evening celebration at the Internet Archive.
The Internet Archive Hero Award is an annual award that recognizes those who have exhibited leadership in making information available for digital learners all over the world. Previous recipients have included public domain advocate Carl Malamud, librarians Kanta Kapoor and Lisa Radha Vohra, copyright expert Michelle Wu, the Biodiversity Heritage Library, and the Grateful Dead.
In April, Supervisor Chan, whose district includes the Internet Archive, authored and unanimously passed a resolution at the San Francisco Board of Supervisors, backing the Internet Archive and the digital rights of all libraries. “At a time when we are seeing an increase in censorship and book bans across the country, we must move to preserve free access to information,” said Supervisor Chan, about the resolution. “I am proud to stand with the Internet Archive, our Richmond District neighbor, and digital libraries throughout the United States.”
Supervisor Connie Chan with Internet Archive’s Brewster Kahle and digital library supporters rally for the digital rights of libraries on the steps of San Francisco City Hall, April 19, 2023.
Many thanks to Supervisor Chan for being a strong advocate for libraries, and for making San Francisco the first municipality to codify the importance of digital libraries and controlled digital lending in a resolution. For this fearless act of standing with libraries, the Internet Archive is proud to honor Supervisor Connie Chan with the 2023 Internet Archive Hero Award.
Join us next week on Thursday, October 12 at 7pm PT, as Supervisor Chan accepts the award live on stage during our evening celebration. Tickets are available for in-person attendance or the livestream.
Internet Archive’s Digital Library of Amateur Radio & Communications has grown to more than 90,000 resources related to amateur radio, shortwave listening, amateur television, and related topics. The newest additions to the free online library include ham radio magazines and newsletters from around the world, podcasts, and discussion forums.
Additions to the newsletter category include The Capitol Hill Monitor, a newsletter for and by scanner radio enthusiasts in the Washington, D.C. region — a complete run from 1992 through today. DLARC has also added more than 300 issues of Florida Skip and its follow-on magazine, SKIP CyberHam, donated by the family of the publisher. Both Capitol Hill Monitor and Florida Skip are online for the first time, scanned from the original paper.
The Cal Poly Amateur Radio Club donated hundreds of radio manuals, catalogs, and magazines — literally emptying file cabinets of material. DLARC has scanned them all and made the trove available online.
Digital Library of Amateur Radio & Communications is funded by a grant from Amateur Radio Digital Communications (ARDC) to create a free digital library for the radio community, researchers, educators, and students. DLARC invites radio clubs and individuals to submit material in any format. If have questions about the project or material to contribute, contact:
Today, the Internet Archive has submitted its appeal [PDF] in Hachette v. Internet Archive. As we stated when the decision was handed down in March, we believe the lower court made errors in facts and law, so we are fighting on in the face of great challenges. We know this won’t be easy, but it’s a necessary fight if we want library collections to survive in the digital age.
Statement from Brewster Kahle, founder and digital librarian of the Internet Archive: “Libraries are under attack like never before. The core values and library functions of preservation and access, equal opportunity, and universal education are being threatened by book bans, budget cuts, onerous licensing schemes, and now by this harmful lawsuit. We are counting on the appellate judges to support libraries and our longstanding and widespread library practices in the digital age. Now is the time to stand up for libraries.”
We will share more information about the appeal as it progresses.
To support our ongoing efforts, please donate as we continue this fight!
Join experts from the library, copyright and information policy fields for a series of conversations exploring some of the most pressing issues facing libraries today: digital ownership and the future of library collections, the emergence of artificial intelligence, and the enduring value of research libraries in the digital age.
This year’s Library Leaders Forum will be organized on two separate dates to provide attendees with a flexible environment in which to reconnect with colleagues. Learn more about the event on the Library Leaders Forum web site, or register below.
October 4: Virtual
October 4 @ 10am PT – 11am PT Online via zoom – Register now
In our virtual session, you’ll hear from Internet Archive staff about our emerging library services and updates on existing efforts, including from our partners. How do libraries empower research in the 21st century? Join in our discussion!
October 12: In-Person
October 12 @ 8:30am – 4pm PT Internet Archive Headquarters @ 300 Funston, San Francisco
At our in-person session, we’ll gather together with the builders & dreamers to envision an equitable future for digital lending. We’ll reserve the afternoon for workshops and unconference breakouts so that you can choose your own conversation, or lead one yourself. Capacity will be capped at 60 attendees.Interested in attending?