We dreamed up the idea of an Internet Archive Telethon, and due to the work of employees, volunteers, and performers, we put together an (almost) 24-hour show. We had an amazing time doing it.
But what were the results?
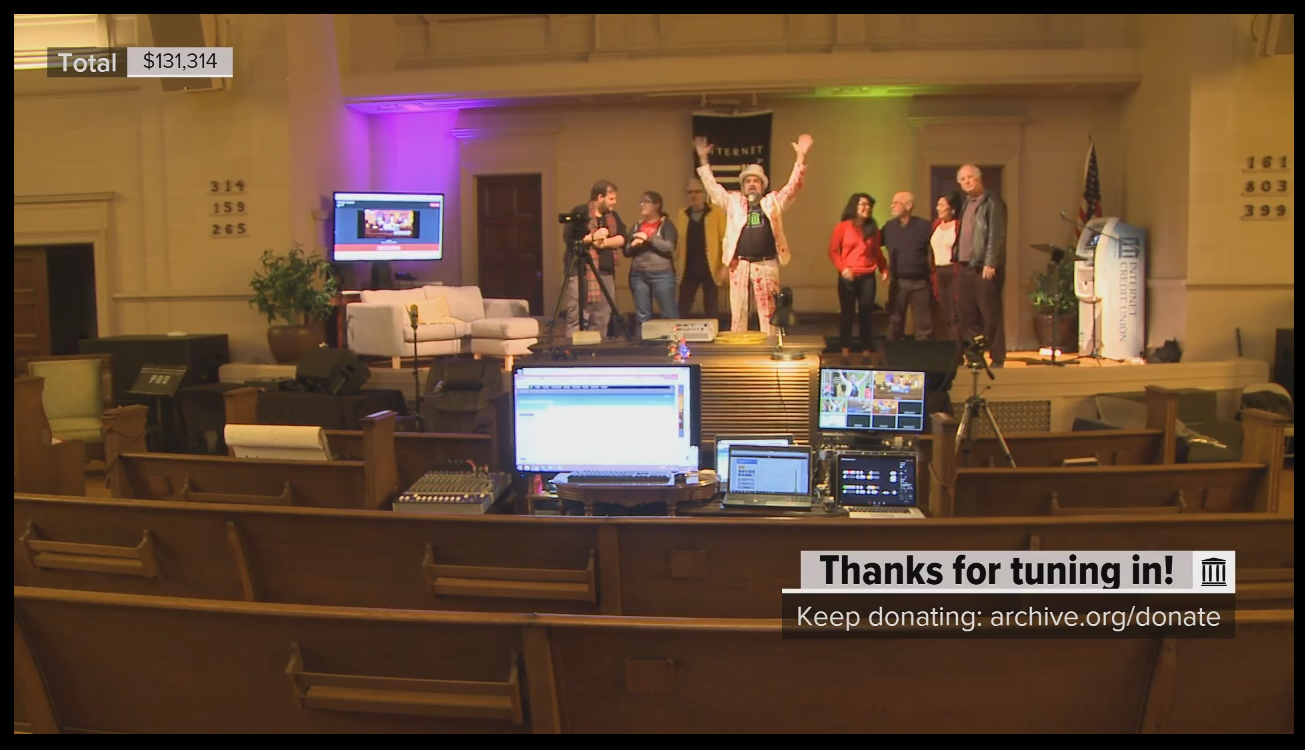
In total, including the 2-1 matching grant we had going on, we raised $131,134 across the 24 hour telethon period. Many donations were $50 or $100, with some lower and a few higher. Watching the funding trends that were in effect from the previous year and this month, there was roughly $30,000 expected to be made if we hadn’t done anything unusual beyond the fundraising banner and the usual contacting of folks to donate. So that means, unscientifically, that the Internet Archive Telethon caused a 400 percent increase in donations, which makes it a wild success!
A shout-out to Doug Kaye of IT Conversations, who donated $10,000 to the event towards the end, as well as Kevin Savetz, who contributed $1,500 in the name of the vintage computing history he and others have been uploading. Limor Fried of Adafruit donated $500, and many, many others contributed other amounts throughout the day and night.
Not only was money raised, but awareness was raised: people were being told about the show and were checking out the Internet Archive for the first time. We got a chance to see everyone excited and happy at the end of the year about this place we work in, and to talk about what brings us there. And the performance acts, all volunteering time and effort, provided us with amazing entertainment and spectacle. It was a resounding success on many other levels as well.
Will it happen again next year? Who knows. What we do know is how incredibly wonderful the experience was, even through all the hard work and intense effort, and how great it is that a mission like the Archive’s can inspire so much.
Thank you so much for being a part of this.
There are so many people to thank for this event. We’ll start with Eddie Codel for livestreaming equipment and Jasmine/Chris/Alex at Support Class for their on-screen reactive graphics – you all made us seem much more professional. On the internal side of Internet Archive employees, June Goldsmith handled administration concerns with the hosting of the event and worked out logistics. The front office (Katherine, Laurel and Michelle) made the calls and the reaching out for security, scheduling and logistics. Michelle invited many of our acts and made logistical arrangements for their media, as well as recruited and organized our team of non-staff volunteers. Wendy Hanamura provided advice, booking, and contacts for multiple acts, as well as being onsite for portions of the event. A lot of employees and volunteers came onsite to help run the Cortex, including Sam, Davide, Jake, Kevin, Laurel, Trevor, Jackie, Carolyn, and Jeff. Rachel Lovinger was a tireless producer for the majority of the cortex’s existence. Carolyn did the Telethon landing page graphics and web design. Will Fitzgerald provided coding for the banner linkage as well as a major assist to near-realtime automatic updating of telethon fundraising totals. Ralf, Tracey, Tim, Trevor, and Brewster and others helped during the Great Network Confusion of December 2015, getting the entire network infrastructure whipped into shape. And, of course, our many acts, including Conspiracy of Beards, Diva Marisa Lendhart, Craig Baldwin, Andy Isaacson, Chris Gray, Justin Hall, Lauren Taylor, Jeff Kaplan, Odd Salon, Gary Gach, Trevor von Stein, the Balkan Brass Band, Alexis Rossi and Dwalu Khasu, Rick and Megan Prelinger, John Perry Barlow and John Gilmore, John Law.
We are no doubt missing many more people who contributed to the Telethon both behind and in front of the camera – it’s a testimony to how many hands came forward to lift this dream up into reality. Thanks to everyone who was a part of it.














{kind=link}
{kind=link}