On November 14, 2022, the Internet Archive hosted Humanities and the Web: Introduction to Web Archive Data Analysis, a one-day introductory workshop for humanities scholars and cultural heritage professionals. The group included disciplinary scholars and information professionals with research interests ranging from Chinese feminist movements, to Indigenous language revitalization, to the effects of digital platforms on discourses of sexuality and more. The workshop was held at the Central Branch of the Los Angeles Public Library and coincided with the National Humanities Conference.
Attendees and Facilitators at Humanities and the Web: Introduction to Web Archive Data Analysis, November 14, 2022, Los Angeles Public Library
The goals of the workshop were to introduce web archives as primary sources and to provide a sampling of tools and methodologies that could support computational analysis of web archive collections. Internet Archive staff shared web archive research use cases and provided participants with hands-on experience building web archives and analyzing web archive collections as data.
Senior Program Manager, Lori Donovan, guiding attendees in using Voyant to analyze text datasets extracted from an Archive-It collection using ARCH.
The workshop’s central feature was an introduction to ARCH (Archives Research Compute Hub). ARCH transforms web archives into datasets tuned for computational research, allowing researchers to, for example, extract all text, spreadsheets, PDFs, images, audio, named entities and more from collections. During the workshop, participants worked directly with text, network, and image file datasets generated from web archive collections. With access to datasets derived from these collections, the group explored a range of analyses using Palladio, RAWGraphs, and Voyant.
Visualization of the image files contained in the Chicago Architecture Biennial collection, created using Palladio based on an Image File dataset extracted from the collection using ARCH.
The high level of interest and participation in this event is indicative of the appetite within the Humanities for workshops on computational research. Participants described how the workshop gave them concrete language to express the challenges of working with large-scale data, while also expressing how the event offered strategies they could apply to their own research or could use to support their research communities. For those who were not able to make it to Humanities and the Web, we will be hosting a series of virtual and in-person workshops in 2023. Keep your eye on this space for upcoming announcements.
In the six weeks since announcing that Internet Archive has begun gathering content for the Digital Library of Amateur Radio and Communications (DLARC), the project has quickly grown to more than 25,000 items, including ham radio newsletters, podcasts, videos, books, and catalogs. The project seeks additional contributions of material for the free online library.
You are welcome to explore the content currently in the library and watch the primary collection as it grows at https://archive.org/details/dlarc.
The new material includes historical and modern newsletters from diverse amateur radio groups including the National Radio Club (of Aurora, CO); the Telford & District Amateur Radio Society, based in the United Kingdom; the Malta Amateur Radio League; and the South African Radio League. The Tri-State Amateur Radio Society contributed more than 200 items of historical correspondence, newspaper clippings, ham festival flyers, and newsletters. Other publications include Selvamar Noticias, a multilingual digital ham radio magazine; and Florida Skip, an amateur radio newspaper published from 1957 through 1994.The library also includes the complete run of 73 Magazine — more than 500 issues — which are freely and openly available.
More than 300 radio related books are available in DLARC via controlled digital lending. These materials may be checked out by anyone with a free Internet Archive account for a period of one hour to two weeks. Radio and communications books donated to Internet Archive are scanned and added to the DLARC lending library.
Amateur radio podcasts and video channels are also among the first batch of material in the DLARC collection. These include Ham Nation, Foundations of Amateur Radio, the ICQ Amateur/Ham Radio Podcast, with many more to come. Providing a mirror and archive for “born digital” content such as video and podcasts is one of the core goals of DLARC.
Additions to DLARC also include presentations recorded at radio communications conferences, including GRCon, the GNU Radio Conference; and the QSO Today Virtual Ham Expo. A growing reference library of past radio product catalogs includes catalogs from Ham Radio Outlet and C. Crane.
DLARC is growing to be a massive online library of materials and collections related to amateur radio and early digital communications. It is funded by a significant grant from Amateur Radio Digital Communications (ARDC) to create a digital library that documents, preserves, and provides open access to the history of this community.
Anyone with material to contribute to the DLARC library, questions about the project, or interest in similar digital library building projects for other professional communities, please contact:
Kay Savetz, K6KJN Program Manager, Special Collections kay@archive.org Mastodon: dlarc@mastodon.radio
Internet Archive has begun gathering content for the Digital Library of Amateur Radio and Communications (DLARC), which will be a massive online library of materials and collections related to amateur radio and early digital communications. The DLARC is funded by a significant grant from the Amateur Radio Digital Communications (ARDC), a private foundation, to create a digital library that documents, preserves, and provides open access to the history of this community.
The library will be a free online resource that combines archived digitized print materials, born-digital content, websites, oral histories, personal collections, and other related records and publications. The goals of the DLARC are to document the history of amateur radio and to provide freely available educational resources for researchers, students, and the general public. This innovative project includes:
A program to digitize print materials, such as newsletters, journals, books, pamphlets, physical ephemera, and other records from both institutions, groups, and individuals.
A digital archiving program to archive, curate, and provide access to “born-digital” materials, such as digital photos, websites, videos, and podcasts.
A personal archiving campaign to ensure the preservation and future access of both print and digital archives of notable individuals and stakeholders in the amateur radio community.
Conducting oral history interviews with key members of the community.
Preservation of all physical and print collections donated to the Internet Archive.
The DLARC project is looking for partners and contributors with troves of ham radio, amateur radio, and early digital communications related books, magazines, documents, catalogs, manuals, videos, software, personal archives, and other historical records collections, no matter how big or small. In addition to physical material to digitize, we are looking for podcasts, newsletters, video channels, and other digital content that can enrich the DLARC collections. Internet Archive will work directly with groups, publishers, clubs, individuals, and others to ensure the archiving and perpetual access of contributed collections, their physical preservation, their digitization, and their online availability and promotion for use in research, education, and historical documentation. All collections in this digital library will be universally accessible to any user and there will be a customized access and discovery portal with special features for research and educational uses.
We are extremely grateful to ARDC for funding this project and are very excited to work with this community to explore a multi-format digital library that documents and ensures access to the history of a specific, noteworthy community. Anyone with material to contribute to the DLARC library, questions about the project, or interest in similar digital library building projects for other professional communities, please contact:
Kay Savetz, K6KJN Program Manager, Special Collections kay@archive.org Twitter: @KaySavetz
“Technology embodies a set of values,” opened Internet Archive’s Director of Partnerships, Wendy Hanamura, in Ethics of the Decentralized Web & Uses in Humanitarian Work, the final session with METRO Library Council and Library Futures. “What values drive our current web?”
Watch Video:
While most of the audience responded by discussing web monetization or opined about lack of privacy, many still believe in the power of the internet for better sharing. As we build a new web, most would like for it to be driven by a different set of values, particularly community, collaboration, freedom, sovereignty, democracy, and trust.
Beginning with Mai Ishikawa Sutton’s work on the five principles of the DWeb and ending with a demo of the Mapeo project, this session brought in designers, coders, policy professors, and ethicists building a new “web for the people” that would embody the above values, and much more.
In 2016 at a campout in California, Sutton and a community of technology enthusiasts came together to rethink the values embedded in the technology of the web we use and the web we could build. While technology was a major factor in the resulting work, ethical considerations and standing for better technology were just as crucial. They created a document that reflected the interests and values of their community with five principles:
Technology for Human Agency
Distributed Benefits
Mutual Respect
Humanity
Ecological Awareness
The group hopes to revisit some of these principles this summer at DWeb Camp 2022 to better define the “web that we want.” In the Q&A with Hanamura, Sutton clarified the ways in which the DWeb addresses crucial aspects of power, control, and capital. Rather than staying static or solely basing itself in technological innovation, the DWeb community is a way to ensure that benefits “flow back into the community.”
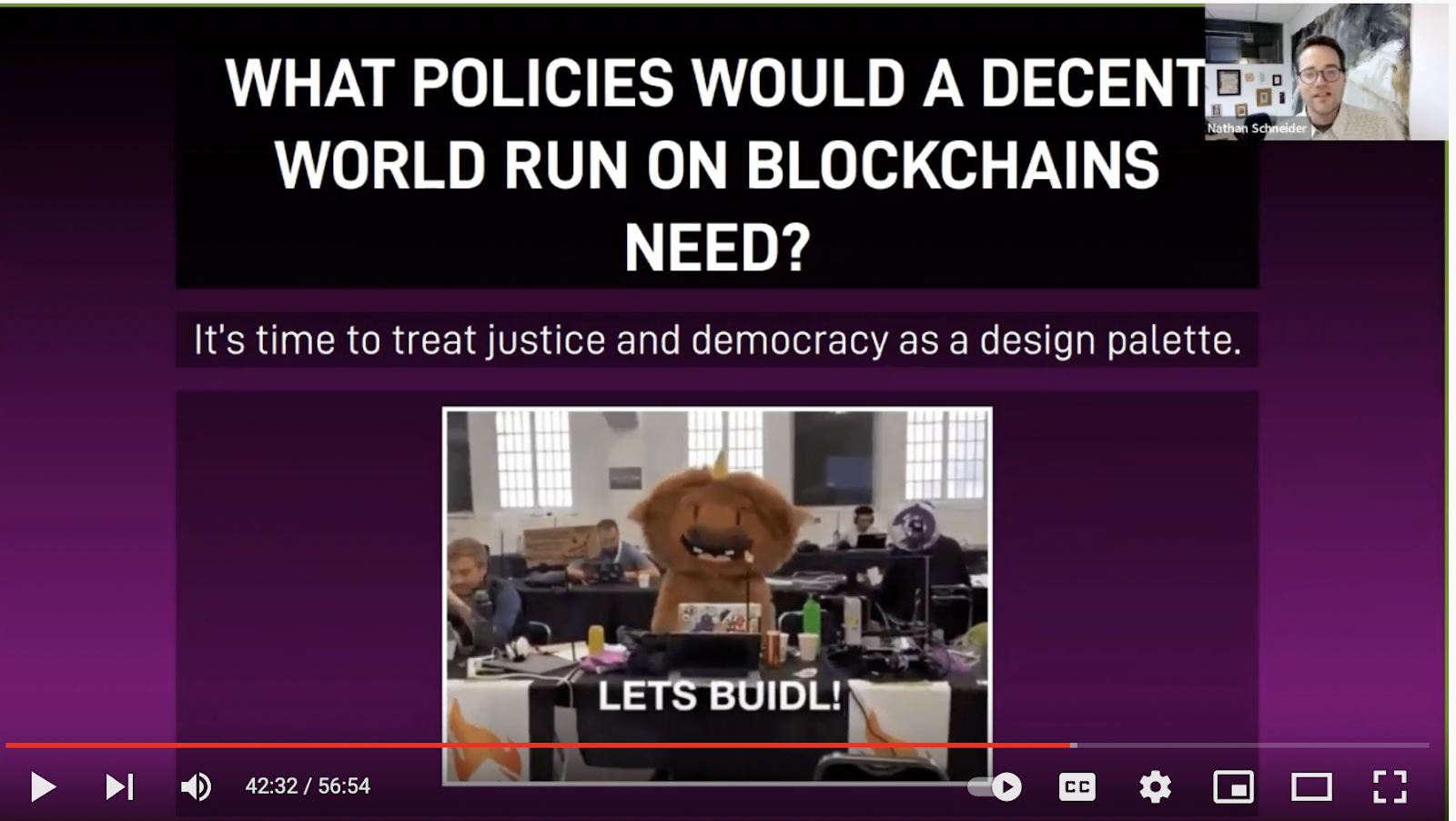
Author and Professor Nathan Schneider followed Sutton to discuss how human rights can be encoded into the blockchain. Schneider’s presentation, “Policy Proposals for Less Dystopian Crypto Protocols” began with a recognition of the issues within blockchain, stating that he wishes to explore how crypto can be “up there with libraries” in terms of building “true civic institutions.” Faced with the dystopia of the current web and recognizing that it could perpetuate the same harms, crypto could present a new form of economic democracy and pluriverses for all. For Schneider, “if code is law,” there are a number of policy proposals that can support a better crypto future. These include building sufficiently decentralized systems, transparent governance, labor over capital, taxation for public goods, reparations, provable zero-carbon, and human rights fail-safes. For his community, this is not about “catching up” to institutions as we know them, but instead doing the work to build a more humane world.
Following Schneider, Luandro Vieira of Digital Democracy demoed his project, Mapeo, a decentralized app built with and for communities. Mapeo is a mobile application that provides free and accessible geospatial technology that is translatable, designed for community, private, and available offline. Originally built for earth defenders, or marginalized people at the front lines of defending their land around the world, Mapeo is highly customizable and used mainly by indigenous people in 16 countries. It is used to map and monitor threats from invasions, mining, logging, and oil activities. Mapeo’s power was demonstrated through the #WaoraniResistance, which protected 1/2 million acres in the Amazon and jeopardized a 7 million acre oil auction.
Through the lens of these three activists and experts, the promise of the DWeb was clear. A new, highly democratic web is possible, but it will take all of us to build it.
We are excited to announce that the National Endowment for the Humanities (NEH) has awarded nearly $50,000 through its Digital Humanities Advancement Grant program to UC Berkeley Library and Internet Archive to study legal and ethical issues in cross-border text data mining research. NEH funding for the project, entitled Legal Literacies for Text Data Mining – Cross Border (LLTDM-X), will support research and analysis that addresses law and policy issues faced by U.S. digital humanities practitioners whose text data mining research and practice intersects with foreign-held or licensed content, or involves international research collaborations. LLTDM-X builds upon Building Legal Literacies for Text Data Mining Institute (Building LLTDM), previously funded by NEH. UC Berkeley Library directed BuildingLLTDM, bringing together expert faculty from across the country to train 32 digital humanities researchers on how to navigate law, policy, ethics, and risk within text data mining projects (results and impacts are summarized in the white paper here.)
Why is LLTDM-X needed?
Text data mining, or TDM, is an increasingly essential and widespread research approach. TDM relies on automated techniques and algorithms to extract revelatory information from large sets of unstructured or thinly-structured digital content. These methodologies allow scholars to identify and analyze critical social, scientific, and literary patterns, trends, and relationships across volumes of data that would otherwise be impossible to sift through. While TDM methodologies offer great potential, they also present scholars with nettlesome law and policy challenges that can prevent them from understanding how to move forward with their research. Building LLTDM trained TDM researchers and professionals on essential principles of licensing, privacy law, as well as ethics and other legal literacies —thereby helping them move forward with impactful digital humanities research. Further, digital humanities research in particular is marked by collaboration across institutions and geographical boundaries. Yet, U.S. practitioners encounter increasingly complex cross-border problems and must accordingly consider how they work with internationally-held materials and international collaborators.
How will LLTDM-X help?
Our long-term goal is to design instructional materials and institutes to support digital humanities TDM scholars facing cross-border issues. Through a series of virtual roundtable discussions, and accompanying legal research and analyses, LLTDM-X will surface these cross-border issues and begin to distill preliminary guidance to help scholars in navigating them. After the roundtables, we will work with the law and ethics experts to create instructive case studies that reflect the types of cross-border TDM issues practitioners encountered. Case studies, guidance, and recommendations will be widely-disseminated via an open access report to be published at the completion of the project. And most importantly, these resources will be used to inform our future educational offerings.
The LLTDM-X team is eager to get started. The project is co-directed by Thomas Padilla, Deputy Director, Archiving and Data Services at Internet Archive and Rachael Samberg, who leads UC Berkeley Library’s Office of Scholarly Communication Services. Stacy Reardon, Literatures and Digital Humanities Librarian, and Timothy Vollmer, Scholarly Communication and Copyright Librarian, both at UC Berkeley Library, round out the team.
We would like to thank NEH’s Office of Digital Humanities again for funding this important work. The full press release is available at UC Berkeley Library’s website. We invite you to contact us with any questions.
In the fifth session of “Imagining a Better Online World: Exploring the Decentralized Web” – a joint series of events with Internet Archive, METRO Library Council, and Library Futures – “Decentralized Apps, the Metaverse, and the ‘Next Big Thing,’” Internet Archive Director of Partnerships Wendy Hanamura took a deep dive into the metaverse and NFTs through an exploration of virtual worlds with pioneering metaverse developer Jin.
Watch session:
In this engaging session, Hanamura and Jin explored the technologies that would transform the future and the world as we know it within Web 3.0: the immersive spaces and built communities of the metaverse. As indicated by participants, to some, NFT and metaverse means “cyberspace on steroids,” or “Second Life,” while for others it holds a more negative connotation. From the “read-only” Web 1.0 to the forthcoming “read-write-trust verifiable” future of Web 3.0, the evolution of the web is leading to an enhancement of reality to create new and augmented realities.
An NFT, or an entry on a blockchain, can be anything from a document to even a virtual representation of a physical space like the Internet Archive. Jin, for example, is able to create a complete virtual desktop where their entire life and memory lives in 3D, and where they conducted the virtual reality interview with Hanamura. From hacker spaces to raves to the virtual representation of the Internet Archive they built as a central space to conduct their work, Jin’s life is mediated and defined through their virtual world building.
What makes Jin’s world unique is their commitment to building with other people in the open source community in an “interesting, collaborative, co-creation.”
Within these worlds, one of the key provisions is interoperability: the ability to carry these worlds between each other. For Jin, this is still a work in progress, with new modes of interoperability still being built. In addition, privacy is a major concern – Web 3.0 provides a new form of privacy through avatars and other obscuring technology, but Jin cautions that due diligence is still warranted, just like in the real world.
The conversation ended with a discussion of the democratizing aspects of NFT creation and independent artists. As an artist, Jin’s first NFT earned him more money than he ever had previously in his career. One of the most exciting aspects of this kind of creation is the way it removes the middle person from the art market: rather than creating for museums or other art markets, Jin is able to reach their audience directly.
Jin ended the session on a positive note: “In virtual reality, you have a lot more bandwidth for empathy. There’s a lot of nuance that is lost in text-based communication platforms. It’s more asynchronous. The sense of presence, of being there with other people, you experience a lot of genuine and good connections… there’s a lot of genuine appreciation of art. That gives me hope.”
The pending sale of Twitter to Elon Musk has generated a buzz about the future of social media and just who should control our data.
Wendy Hanamura, director of partnerships at the Internet Archive, moderated an online discussion April 28 “Goodbye Facebook, Hello Decentralized Social Media?” about the opportunities and dangers ahead. The webinar is part of a series of six workshops, “Imagining a Better Online World: Exploring the Decentralized Web.”
Watch the session recording:
The session featured founders of some of the top decentralized social media networks including Jay Graber, chief executive officer of R&D project Bluesky, Matthew Hodgson, technical co-founder of Matrix, and Andre Staltz, creator of Manyverse. Unlike Twitter, Facebook or Slack, Matrix and Manyverse have no central controlling entity. Instead the peer-to-peer networks shift power to the users and protect privacy.
If Twitter is indeed bought and people are disappointed with the changes, the speakers expressed hope that the public will consider other social networks. “A crisis of this type means that people start installing Manyverse and other alternatives,” Staltz said. “The opportunity side is clear.” Still in the transition period if other platforms are not ready, there is some risk that users will feel stuck and not switch, he added.
Hodgson said there are reasons to be both optimistic and pessimistic about Musk purchasing Twitter. The hope is that he will use his powers for good, making it available to everybody and empowering people to block the content they don’t want to see. The risk is with no moderation, Hodgson said, people will be obnoxious to one another without sufficient controls to filter, and the system will melt down. “It’s certainly got potential to be an experiment. I’m cautiously optimistic on it,” he said.
People who work in decentralized tech recognize the risk that comes when one person can control a network and act for good or bad, Graber said. “This turn of events demonstrates that social networks that are centralized can change very quickly,” she said. “Those changes can potentially disrupt or drastically alter people’s identity, relationships, and the content that they put on there over the years. This highlights the necessity for transition to a protocol-based ecosystem.”
When a platform is user-controlled, it is resilient to disruptive change, Graber said. Decentralization enables immutability so change is hard and is a slow process that requires a lot of people to agree, added Staltz.
The three leaders spoke about how decentralized networks provide a sustainable alternative and are gaining traction. Unlike major players that own user data and monetize personal information, decentralized networks are controlled by users and information lives in many different places.
“Society as a whole is facing a lot of crises,” Graber said. “We have the ability to, as a collective intelligence, to investigate a lot of directions at once. But we don’t actually have the free ability to fully do this in our current social architecture…if you decentralize, you get the ability to innovate and explore many more directions at once. And all the parts get more freedom and autonomy.”
Decentralized social media is structured to change the balance of power, added Hanamura: “In this moment, we want you to know that you have the power. You can take back the power, but you have to understand it and understand your responsibility.”
At a recent webinar hosted by the Internet Archive, leaders from the Biodiversity Heritage Library (BHL) shared how its massive open access digital collection documenting life on the planet is an invaluable resource of use to scientists and ordinary citizens.
“The BHL is a global consortium of the leading natural history museums, botanical gardens, and research institutions — big and small— from all over the world. Working together and in partnership with the Internet Archive, these libraries have digitized more than 60 million pages of scientific literature available to the public”, said Chris Freeland, director of Open Libraries and moderator of the event.
Watch session recording:
Established in 2006 with a commitment to inspiring discovery through free access to biodiversity knowledge, BHL has 19 members and 22 affiliates, plus 100 worldwide partners contributing data. The BHL has content dating back nearly 600 years alongside current literature that, when liberated from the print page, holds immense promise for advancing science and solving today’s pressing problems of climate change and the loss of biodiversity.
Martin Kalfatovic, BHL program director and associate director of the Smithsonian Libraries and Archives, noted in his presentation that Charles Darwin and colleagues famously said “the cultivation of natural science cannot be efficiently carried on without reference to an extensive library.”
“Today, the Biodiversity Heritage Library is creating this global, accessible open library of literature that will help scientists, taxonomists, environmentalists—a host of people working with our planet—to actually have ready access to these collections,” Kalfatovic said. BHL’s mission is to improve research methodology by working with its partner libraries and the broader biodiversity and bioinformatics community. Each month, BHL draws about 142,000 visitors and 12 million users overall.
“The outlook for the planet is challenging. By unlocking this historic data [in the Biodiversity Heritage Library], we can find out where we’ve been over time to find out more about where we need to be in the future.”
Martin Kalfatovic, program director, Biodiversity Heritage Library
Most of the BHL’s materials are from collections in the global north, primarily in large, well-funded institutions. Digitizing these collections helps level the playing field, providing researchers in all parts of the world equal access to vital content.
The vast collection includes species descriptions, distribution records, climate records, history of scientific discovery, information on extinct species, and records of scientific distributions of where species live. To date, BHL has made over 176,000 titles and 281,000 volumes available. Through a partnership with the Global Names Architecture project, more than 243 million instances of taxonomic (Latin) names have been found in BHL content.
Kalfatovic underscored the value of BHL content in understanding the environment in the wake of recent troubling news from the Sixth Assessment Report (AR6) published by the Intergovernmental Panel on Climate Change about the impact of the earth’s warming.
“The outlook for the planet is challenging,” he said. “By unlocking this historic data, we can find out where we’ve been over time to find out more about where we need to be in the future.”
JJ Dearborn, BHL data manager, discussed how digitization transforms physical books into digital objects that can be shared with “anyone, at any time, anywhere.” She describes the Wikimedia ecosystem as “fertile ground for open access experimentation,” crediting the organization with giving BHL the ability to reach new audiences and transform its data into 5-star linked open data. “Dark data” that is locked up in legacy formats, JP2s, and OCR text are sources of valuable checklist, species occurrence, and event sampling data that the larger biodiversity community can use to improve humanity’s collective ability to monitor biodiversity loss and the destructive impacts of climate change, at scale.
The majority of the world’s data today is siloed, unstructured, and unused, Dearborn explained. This “dark data” “represents an untapped resource that could really transform human understanding if it could be truly utilized,” she said. “It might represent a gestalt leap for humanity.”
The event was the fifth in a series of six sessions highlighting how researchers in the humanities use the Internet Archive. The final session of the Library as Laboratory series will be a series of lightning talks on May 11 at 11am PT / 2pm ET—register now!
“How Decentralized Identity Drives Privacy” with Internet Archive, Metro Library Council, and Library Futures
How many passwords do you have saved, and how many of them are controlled by a large, corporate platform instead of by you? Last month’s “Keeping your Personal Data Personal: How Decentralized Identity Drives Privacy” session started with that provocative question in order to illustrate the potential of this emerging technology.
Self-sovereign identity (SSI), defined as “an idea, a movement, and a decentralized approach for establishing trust online,” sits in the middle of the stack of technologies that makes up the decentralized internet. In the words of the Decentralized Identity Resource Guide written specifically for this session, “self-sovereign identity is a system where users themselves–and not centralized platforms or services like Google, Facebook, or LinkedIn–are in control and maintain ownership of their personal information.”
Research shows that the average American has more than 150 different accounts and passwords – a number that has likely skyrocketed since the start of the pandemic. In her presentation, Wendy Hanamura, Director of Partnerships at the Internet Archive, discussed the implications of “trading privacy and security for convenience.” Hanamura drew on her recent experience at SXSW, which bundled her personal data, including medical and vaccine data, into an insecure QR code used by a corporate sponsor to verify her as a participant. In contrast, Hanamura says that the twenty-year old concept of self-sovereign identity can disaggregate these services from corporations, empowering people to be in better control of their own data and identity through principles like control, access, transparency, and consent. While self-sovereign identity presents incredible promise as a concept, it also raises fascinating technical questions around verification and management.
For Kaliya “Identity Woman” Young, her interest in identity comes from networks of global ecology and information technology, which she has been part of for more than twenty years. In 2000, when the Internet was still nascent, she joined with a community to ask: “How can this technology best serve people, organizations, and the planet?” Underlying her work is the strong belief that people should have the right to control their own online identity with the maximum amount of flexibility and access. Using a real life example, Young compared self-sovereign identity to a physical wallet. Like a wallet, self-sovereign identity puts users in control of what they share, and when, with no centralized ability for an issuer to tell when the pieces of information within the wallet is presented.
In contrast, the modern internet operates with a series of centralized identifiers like ICANN or IANA for domain names and IP addresses and corporate private namespaces like Google and Facebook. Young’s research and work decentralizes this way of transmitting information through “signed portable proofs,” which come from a variety of sources rather than one centralized source. These proofs are also called verifiable credentials and have metadata, the claim itself, and a digital signature embedded for validation. All of these pieces come together in a digital wallet, verified by a digital identifier that is unique to a person. Utilizing cryptography, these identifiers would be validated by digital identity documents and registries. In this scenario, organizations like InCommon, an access management service, or even a professional licensing organization like the American Library Association can maintain lists of institutions that would be able to verify the identity or organizational affiliation of an identifier. In the end, Young emphasized a message of empowerment – in her work, self-sovereign identity is about “innovating protocols to represent people in the digital realm in ways that empower them and that they control.”
Next, librarian Lambert Heller of Technische Bibliothek and Irene Adamski of the Berlin-based SSI firm Jolocom discussed and demonstrated their work in creating self-sovereign identity for academic conferences on a new platform called Condidi. This tool allows people running academic events to have a platform that issues digital credentials of attendance in a decentralized system. Utilizing open source and decentralized software, this system minimizes the amount of personal information that attendees need to give over to organizers while still allowing participants to track and log records of their attendance. For libraries, this kind of system is crucial – new systems like Condidi help libraries protect user privacy and open up platform innovation.
Self-sovereign identity also utilizes a new tool called a “smart wallet,” which holds one’s credentials and is controlled by the user. For example, at a conference, a user might want to tell the organizer that she is of age, but not share any other information about herself. A demo of Jolocom’s system demonstrated how this system could work. In the demo, Irene showed how a wallet could allow a person to share just the information she wants through encrypted keys in a conference situation. Jolocom also allows people to verify credentials using an encrypted wallet. According to Adamski, the best part of self sovereign identity is that “you don’t have to share if you don’t want to.” This way, “I am in control of my data.”
To conclude, Heller discussed a recent movement in Europe called “Stop Tracking Science.” To combat publishing oligopolies and data analytics companies, a group of academics have come together to create scholar-led infrastructure. As Heller says, in the current environment, “Your journal is reading you,” which is a terrifying thought about scholarly communications.
These academics are hoping to move toward shared responsibility and open, decentralized infrastructure using the major building blocks that already exist. One example of how academia is already decentralized is through PIDs, or persistent identifiers, which are already widely used through systems like ORCID. According to Heller, these PIDs are “part of the commons” and can be shared in a consistent, open manner across systems, which could be used in a decentralized manner for personal identity rather than a centralized one. To conclude, Heller said, “There is no technical fix for social issues. We need to come up with a model for how trust works in research infrastructure.”
It is clear that self-sovereign identity holds great promise as part of a movement for technology that is privacy-respecting, open, transparent, and empowering. In this future, it will be possible to have a verified identity that is held by you, not by a big corporation – the vision that we are setting out to achieve. Want to help us get there?
The COVID-19 pandemic has been life-changing for people around the globe. As efforts to slow the progress of the virus unfolded in early 2020, librarians, archivists and others with interest in preserving cultural heritage began considering ways to document the personal, societal, and systemic impacts of the global pandemic. These collections included preserving physical, digital and web-based information and artifacts for posterity and future research use.
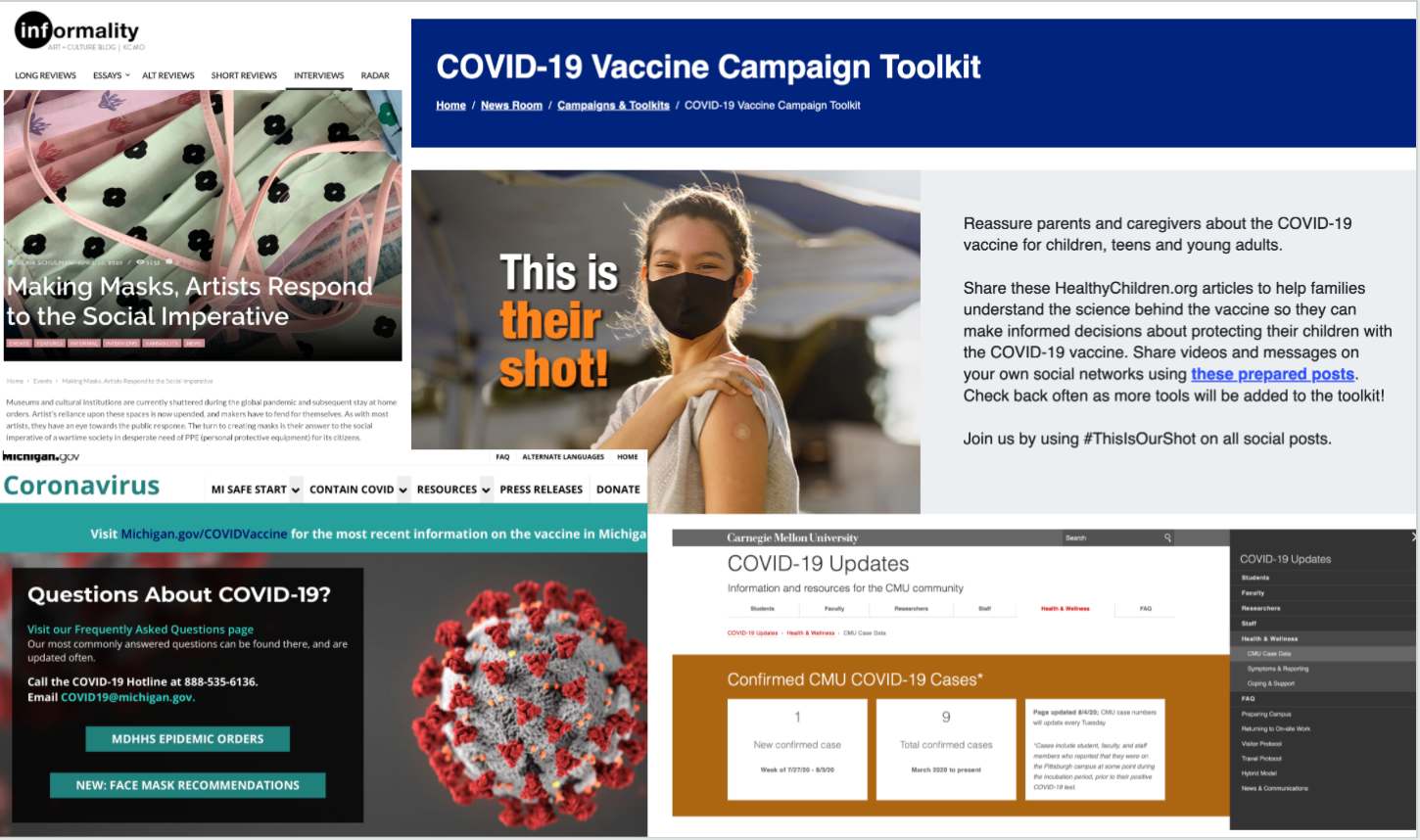
Clockwise from top left: blog post about local artists making masks from Kansas City Public Library’s “COVID-19 Outbreak” collection; youth vaccination campaign website from American Academy of Pediatrics’ “AAP COVID” collection, COVID-19 case dashboard from Carnegie Mellon University’s “COVID-19” collection and COVID-19 FAQs from Library of Michigan’s “COVID-19 in Michigan” collection.
In response, the Internet Archive’s Archive-It service launched a COVID-19 Web Archiving Special Campaign starting in April 2020 to allow existing Archive-It partners to increase their web archiving capacity or new partners to join to collect COVID-19 related content. In all, more than 100 organizations took advantage of the COVID-19 Web Archiving Special Campaign and more than 200 Archive-It partner organizations built more than 300 new collections specifically about the global pandemic and its effects on their regions, institutions, and local communities. From colleges, universities, and governments documenting their own responses to community-driven initiatives like Sonoma County Library’s Sonoma Responds Community Memory Archive, a variety of information has been preserved and made available. These collections are critical historical records in and of themselves, and when taken in aggregate will allow researchers a comprehensive view into life during the pandemic.
Sonoma County Library’s Sonoma Responds: A Community Memory Archive encouraged community members to contribute content documenting their lives during the COVID-19 pandemic.
We have been exploring with partners ways to provide unified access to hundreds of individual COVID-related web collections created by Archive-It users. When the Institute of Museum and Library Services launched the American Rescue Plan grant program, that was part of the broader American Rescue Plan, a $1.9 trillion stimulus package signed into law on March 11, we applied and were awarded funding to build a COVID-19 Web Archive access portal – a dedicated search and discovery access platform for COVID-19 web collections from hundreds of institutions. The COVID-19 Web Archive will allow for browsing and full text search across diverse institutional collections and enable other access methods, including making datasets and code notebooks available for data analysis of the aggregate collections by scholars. This work will support scholars, public health officials, and the general public in fully understanding the scope and magnitude of our historical moment now and into the future. The COVID-19 Web Archive is unique in that it will provide a unified discovery mechanism to hundreds of aggregated web archive collections built by a diverse group of over 200 libraries from over 40 US states and several other nations, from large research libraries to small public libraries to government agencies. If you would like your Archive-It collection or a portion of it included in the COVID-19 Web Archive, please fill out this interest form by Friday, April 29, 2022. If you are an institution in the United States that has COVID-related web archives collected outside of Archive-It or Internet Archive services that you are interested in having included in the COVID-19 Web Archive, please contact covidwebarchive@archive.org.