In celebration of National Library Week, we’d like to introduce you to some of the professional librarians who work at the Internet Archive and in projects closely associated with our programs. Over the next two weeks, you’ll hear from librarians and other information professionals who are using their education and training in library science and related fields to support the Internet Archive’s patrons.
What draws librarians to work at the Internet Archive? From patron services to collection management to web archiving, the answers are as varied as the departments in which these professionals work. But a common theme emerges from the profiles—that of professionals wanting to use their skills and knowledge in support of the Internet Archive’s mission: “Universal Access to All Knowledge.”
We hope that over these next two weeks you’ll learn something about the librarians working behind the scenes at the Internet Archive, and you’ll come to appreciate the training and dedication that influence their daily work. We’re pleased to help you “Meet the Librarians” during this National Library Week and beyond:
Jessamyn West, accessibility – Vermont Mutual Aid Society
For scholars, especially those in the humanities, the library is their laboratory. Published works and manuscripts are their materials of science. Today, to do meaningful research, that also means having access to modern datasets that facilitate data mining and machine learning.
On March 2, the Internet Archive launched a new series of webinars highlighting its efforts to support data-intensive scholarship and digital humanities projects. The first session focused on the methods and techniques available for analyzing web archives at scale.
Watch the session recording now:
“If we can have collections of cultural materials that are useful in ways that are easy to use — still respectful of rights holders — then we can start to get a bigger idea of what’s going on in the media ecosystem,” said Internet Archive Founder Brewster Kahle.
Just what can be done with billions of archived web pages? The possibilities are endless.
Jefferson Bailey, Internet Archive’s Director of Web Archiving & Data Services, and Helge Holzmann, Web Data Engineer, shared some of the technical issues libraries should consider and tools available to make large amounts of digital content available to the public.
The Internet Archive gathers information from the web through different methods including global and domain crawling, data partnerships and curation services. It preserves different types of content (text, code, audio-visual) in a variety of formats.
Social scientists, data analysts, historians and literary scholars make requests for data from the web archive for computational use in their research. Institutions use its service to build small and large collections for a range of purposes. Sometimes the projects can be complex and it can be a challenge to wrangle the volume of data, said Bailey.
The Internet Archive has worked on a project reviewing changes to the content of 800,000 corporate home pages since 1996. It has also done data mining for a language analysis that did custom extractions for Icelandic, Norwegian and Irish translation.
Transforming data into useful information requires data engineering. As librarians consider how to respond to inquiries for data, they should look at their tech resources, workflow and capacity. While more complicated to produce, the potential has expanded given the size, scale and longitudinal analysis that can be done.
“We are getting more and more computational use data requests each year,” Bailey said. “If librarians, archivists, cultural heritage custodians haven’t gotten these requests yet, they will be getting them soon.”
Up next in the Library as Laboratory series:
The next webinar in the series will be held March 16, and will highlight five innovative web archiving research projects from the Archives Unleashed Cohort Program. Register now.
As part of our ongoing efforts to archive and provide perpetual access to at-risk, open-access scholarship, we have released Refcat (“reference” + “catalog”), the citation index culled from the catalog that underpins our IA Scholar service for discovering the scholarly literature and research outputs within Internet Archive. This first release of the Refcat dataset contains over 1.3 billion citations extracted from over 60 million metadata records and over 120 million scholarly artifacts (articles, books, datasets, proceedings, code, etc) that IA Scholar has archived through web harvesting, digitization, integrations with other open knowledge services, and through partnerships and joint initiatives.
Refcat represents one of the larger citation graph datasets of scholarly literature, as well as uniquely containing a notable portion of citations from works that do not have a DOI or persistent identifier. We hope this dataset will be a valuable community resource alongside other critical knowledge graph projects, including those with which we are collaborating, such as OpenCitations and Wikicite.
The Refcat dataset is released under a CC0 license and is available for download from archive.org. The related software created for the extraction and matching process, including exact and fuzzy citation matching (refcat and fuzzycat), are also released as open-source tools. For those interested in technical details about the project, a white paper is available on arxiv.org authored by IA engineers, including Martin Czygan, who led work on Refcat, and is described in our catalog user guide.
What does Refcat mean for regular users of IA Scholar? Refcat results from work to ensure the interconnection between material within IA Scholar and other resources archived in Internet Archive in order to make browsing and lookups easier and to ensure overall citation integrity and persistence. For example, there are over 25 million web links in the citations in Refcat and we were able to match ~14 million of these to archived web pages in Wayback Machine and also found that ~18% of these matched web citations are no longer available on the live web. Web links in citations not in Wayback Machine have been added to ongoing web harvests. We also matched over 20 million citations to books that are available for lending in our Open Library service and matched over 1 million citations to Wikipedia entries.
Besides interconnection, Refcat will allow users to understand what works have cited a specific scholarly resource (i.e. “cited by” or “inbound citations”) that will help with improved discovery features. Finally, knowing the full “knowledge graph” of IA Scholar helps us better identify important scholarly material that we have not yet archived, thus improving the overall quality and extent of the collection. This, in turn, aids scholars by ensuring their open-access work is archived and accessible forever, especially for those whose publisher may not have the resources for long-term preservation, and it ensures that related outputs like research registrations or datasets are also archived, matched to the article of record, and available into the future.
The Refcat release is a milestone of Phase Two of our project, “Ensuring the Persistent Access of Long Tail Open Access Journal Literature,” first announced in 2018 and supported by funding from the Andrew W. Mellon Foundation. Current work focuses on citation integrity within the IA Scholar archive, partnerships and services, such as our role in the multi-institutional Project Jasper and our partnership with Center for Open Science, and the addition of secondary scholarly outputs to IA Scholar, including datasets, software, and other non-article/book scholarly materials. Lookout for a plethora of announcements about other IA Scholar milestones in the coming months!
Community Webs, the Internet Archive’s community history web and digital archiving program, is welcoming over 60 new members from across the US, Canada, and internationally. This new cohort is the first expansion of the Community Webs program outside of the United States and we are thrilled to be supporting the development of diverse, community-based web collections on an international scale.
Community Webs empowers cultural heritage organizations to collaborate with their communities to build web and digital archives of primary sources documenting local history and culture, especially collections inclusive of voices typically underrepresented in traditional memory collections. The program achieves this mission by providing its members with free access to the Archive-It web archiving service, digital preservation and digitization services, and technical support and training in topics such as web archiving, community outreach, and digital preservation. The program also offers resources to support a local history archiving community of practice and to facilitate scholarly research.
New Community Webs member Karen Ng, Archivist at Sḵwx̱wú7mesh Úxwumixw (Squamish Nation), BC, Canada, notes that the program offers a way to capture community-generated online content in a context where many of the Nation’s records are held by other institutions. “The Squamish Nation community is active in creating and documenting language, traditional knowledge, and histories. Now more than ever in the digital age, it is imperative that these stories and histories be captured and stored in accessible ways for future generations.”
Similarly, for Maryna Chernyavska, Archivist at the Kule Folklore Centre in Edmonton, Canada, the program will allow the Centre to continue building relationships with community members and organizations. “Being able to assist local heritage organizations with web archiving will help us empower these communities to preserve their heritage based on their values and priorities, but also according to professional standards.”
The current expansion of the program was made possible in part by generous funding from the Andrew Mellon Foundation, which supports the growth of Community Webs to new public libraries in the US. Additional funding provided by the Internet Archive allows the program to reach cultural heritage organizations in Canada and beyond. This newest cohort brings the total number of participants in Community Webs to over 150 organizations, a ten-fold increase since the program’s inception in 2017. For a full list of new participants, see below. The program continues to add members – if your institution is interested in joining, please view our open calls for applications and please make your favorite local memory organization aware of the opportunity.
Programming for the new cohort is underway and these members are already diving into the program’s educational resources and familiarizing themselves with the technical aspects of web archiving and digital preservation. We kicked things off recently with introductory Zoom sessions, where participants met one another and shared their organizations’ missions, communities served and goals for membership in the program. Online training modules, developed by staff at the Internet Archive and the Educopia Institute, went live for new members at the beginning of September. And our new cohort joined our existing Community Webs partners at our virtual Partner Meeting on September 22nd.
We are thrilled to see the program continuing to grow and we look forward to working with our newest cohort. A warm welcome to the following new Community Webs members!
Canada:
Aanischaaukamikw Cree Cultural Institute
Age of Sail Museum and Archives
Ajax Public Library
Blue Mountains Public Library – Craigleith Heritage Depot
Canadian Friends Historical Association
Charlotte County Archives
City of Kawartha Lakes Public Library
Community Archives of Belleville and Hastings County
Confluence Concerts | Toronto Performing Arts Archives
Edson and District Historical Society – Galloway Station Museum & Archives
Essex-Kent Mennonite Historical Association
Ex Libris Association
Fishing Lake Métis Settlement Public Library
Frog Lake First Nations Library
Goulbourn Museum
Grimsby Public Library
Hamilton Public Library
Kule Folklore Centre
Maskwacis Cultural College
Meaford Museum
Milton Public Library
Mission Folk Music Festival
Nipissing Nation Kendaaswin
North Lanark Regional Museum
Northern Ontario Railroad Museum and Heritage Centre
Parkwood National Historic Site
Regina Public Library
Sḵwx̱wú7mesh Úxwumixw (Squamish Nation) Archives
Société historique du Madawaska Inc.
St. Clair West Oral History Project
Temagami First Nation Public Library
The ArQuives: Canada’s LGBTQ2+ Archives
The Historical Society of Ottawa
Thunder Bay Museum
Tk’emlups te Secwepemc
International:
Biblioteca Nacional Aruba
Institute of Information Science, Academia Sinica (Taiwan)
Mbube Cultural Preservation Foundation (Nigeria)
National Library and Information System Authority (NALIS) (Republic of Trinidad and Tobago)
United States:
Abilene Public Library
Ashland City Library
Auburn Avenue Research Library on African American Culture and History
Charlotte County Libraries & History
Choctaw Cultural Center
Cultura Local ABI
DC History Center
Forsyth County Public Library
Fort Worth Public Library
Inuit Circumpolar Council – Alaska
Menominee Tribal Archives
Mineral Point Library Archives
Obama Hawaiian Africana Museum
Scott County Library System
South Sioux City Public Library
St. Louis Media History Foundation
Tacoma Public Library
The History Project
The Seattle Public Library
Tipp City Public Library
University of Hawaiʻi – West Oʻahu
Wilmington Public Library District
Congrats to these new partners! We are excited to have you on board.
Much of the art gallery, artist, and arts organization materials that were once published in print form are now available primarily or solely on the web. These groups, like many in the cultural sector, have also been hit especially hard by the global pandemic, making their web presences particularly at-risk of being lost if they are not proactively collected and preserved.The creation of reference and research resources that promote streamlined access and enable new types of scholarly use will ensure that the art historical record of the 21st century, and especially of our current global pandemic, is readily accessible far into the future.
For this reason, the Internet Archive, along with the New York Art Resources Consortium (NYARC), are pleased to announce our project Consortial Action to Preserve Born-Digital, Web-Based Art History & Culture. The project recently received a two-year, $305,343 Humanities Collections and Reference Resources grant from the Division of Preservation and Access at the National Endowment for the Humanities. This award will support the formation of a cooperative group of 30+ art and museum libraries from across the United States to collaborate on the preservation of, and access to vital arts content from the web.
The Internet Archive has a long history of building and supporting collaborative communities and providing non-profit web, preservation, and access services to cultural heritage organizations. The multi-institutional initiative between Internet Archive, NYARC, and other arts and museum organizations will build on similar community-based archiving and professional cultivation projects in the Community Programs group, especially our Community Webs program, currently expanding nationally and internationally. Community Webs has received funding from The Andrew W. Mellon Foundation and IMLS to provide public libraries and cultural heritage organizations with services, training, and professional development opportunities to document their diverse local history.
NYARC are pioneers in collaborative web archiving and shared services, among art and museum libraries. NYARC’s robust web archive collections encompass art resources, artists’ websites, auction catalogs, catalogues raisonnes, and hundreds of New York City gallery websites. The Internet Archive and NYARC have partnered on work to build born-digital collecting capacity among arts organizations in the past, most recently in the IMLS-funded Advancing Art Libraries and Curated Web Archives National forum and related events. Through discussions, workshops and roadmapping sessions with leaders in art and museum libraries, a strategy and plan towards an inclusive, sustainable, cooperative approach to collecting and stewarding born-digital, locally-focused art history collection was developed, forming the basis of this broader cooperative effort.
Members in the project’s preliminary group of art and museum libraries will select topics and specific web content that is relevant to their expertise, will provide metadata to facilitate access to archived content, and will participate in planning and evaluation meetings, all while curating a valuable reference resource that will enhance their traditional collecting areas. The Internet Archive will coordinate communications, facilitate governance and collective curatorial activities, provide technical digital library and archive services, and help enable members to build and maintain discovery and access platforms, as well as facilitate researcher use of the collections resulting from the group’s work.
If your art or museum library is interested in joining this collaborative effort, please fill out this participation form by July 31 to join us!
The Internet Archive’s Community Webs Program provides training and education, infrastructure and services, and professional community cultivation for public librarians across the country to document their local history and the lives of their patrons. Following our recent announcement of the program’s national expansion, with support from the Andrew W. Mellon Foundation, we are excited to welcome the first class of 50+ new public libraries to the program. This brings the current number of new and returning Community Webs participants to 90+ libraries from 33 states and 3 US territories. This diverse group of organizations includes multiple state libraries representing their regions, as well as a mix of large metropolitan library systems, small libraries in rural areas, and libraries like the Feleti Barstow Public Library in American Samoa. All will be working to document their communities, with a particular focus on archiving materials from traditionally underrepresented groups.
The new cohort class kicked off with virtual introductory events in mid-March, where participants met one another and shared stories about their communities and their goals for preserving and providing access to local history materials. Member libraries are currently receiving training in topics such as collection development and starting to build digital collections that reflect local diversity, events, and culture.
Program participant Kathleen Pickering, Director of the Belen Public Library and Harvey House Museum in Belen, New Mexico notes that their library “is committed to free and open-source electronic resources for our patrons, especially given the low-income status of many of our residents” and Community Webs will help further that goal. Similarly, new cohort member Aaron Ramirez of Pueblo City-County Library District (PCCLD)found Community Webs to be a great fit for existing institutional goals and initiatives. “PCCLD’s five-year strategic plan directs us to embrace local cultures, to include individuals of all skill levels and physical abilities, and to enrich established partnerships and collaborations. The groups that have not seen themselves in our archives will find through this project PCCLD’s intention and means to listen and go forward as allies and as a resource of support, rather than an institution serving only the affluent.”
Makiba J. Foster
Makiba J. Foster, Manager of The African American Research Library and Cultural Center of Broward County, Florida pointed out that “as content becomes increasingly digital, we need this opportunity to document the digital life and content of our community which includes a diverse representation of the Black Diaspora.” Makiba was a member of the original Community Webs cohort in a previous position at the Schomburg Center for Research in Black Culture at New York Public Library, and recently presented on her work archiving the black diaspora to a group of more than 200 attendees.
The Community Webs Program is continuing to grow towards the milestone of over 150 participating libraries across the United States and will soon announce another call for applicants for a U.S. cohort starting in late summer. The program also is beginning to expand internationally, starting in Canada, exploring the addition of other types of libraries and cultural heritage organizations, and expanding its suite of training and services available to participants. Expect more news on these initiatives soon.
Welcome to our new cohort of Community Webs libraries! The full list of new members:
Alamogordo Public Library (New Mexico)
Amelia Island Museum of History (Florida)
ART | library deco (Texas)
Asbury Park Public Library (New Jersey)
Atlanta History Center (Georgia)
Bartholomew County Public Library (Indiana)
Bedford Public Library System (Virginia)
Belen Public Library and Harvey House Museum (New Mexico)
Bensenville Community Public Library (Illinois)
Biblioteca Municipal Aurea M. Pérez (Puerto Rico)
Carbondale Public Library (Illinois)
Cedar Mill & Bethany Community Libraries (Oregon)
Charlotte Mecklenburg Library (North Carolina)
Chicago Public Library (Illinois)
City Archives & Special Collections, New Orleans Public Library (Louisiana)
Dayton Metro Library (Ohio)
Elba Public Library (Alabama)
Essex Library Association (Connecticut)
Everett Public Library (Washington)
Feleti Barstow Public Library (American Samoa)
Forsyth County Public Library (North Carolina)
Hartford History Center, Hartford Public Library (Connecticut)
Heritage Public Library (Virginia)
Huntsville-Madison County Public Library (Alabama)
James Blackstone Memorial Library (Connecticut)
Jefferson Parish Library (Louisiana)
Jefferson-Madison Regional Library (Virginia)
Laramie County Library System (Wyoming)
Lawrence Public Library (Massachusetts)
Los Angeles Public Library (California)
Mill Valley Public Library, Lucretia Little History Room (California)
Missoula Public Library (Montana)
Niagara Falls Public Library (New York)
Pueblo City-County Library District (Colorado)
Rochester Public Library (New York)
Santa Cruz Public Libraries (California)
South Pasadena Public Library (California)
State Library of Pennsylvania (Pennsylvania)
Tangipahoa Parish Library (Louisiana)
The African American Research Library and Cultural Center (Florida)
In July, we announced our partnership with the Archives Unleashed project as part of our ongoing effort to make new services available for scholars and students to study the archived web. Joining the curatorial power of our Archive-It service, our work supporting text and data mining, and Archives Unleashed’s in-browser analysis tools will open up new opportunities for understanding the petabyte-scale volume of historical records in web archives.
As part of our partnership, we are releasing a series of publicly available datasets created from archived web collections. Alongside these efforts, the project is also launching a Cohort Program providing funding and technical support for research teams interested in studying web archive collections. These twin efforts aim to help build the infrastructure and services to allow more researchers to leverage web archives in their scholarly work. More details on the new public datasets and the cohorts program are below.
Early Web Datasets
Our first in a series of public datasets from the web collections are oriented around the theme of the early web. These are, of course, datasets intended for data mining and researchers using computational tools to study large amounts of data, so are absent the informational or nostalgia value of looking at archived webpages in the Wayback Machine. If the latter is more your interest, here is an archived Geocities page with unicorn GIFs.
GeoCities Collection (1994–2009)
As one of the first platforms for creating web pages without expertise, Geocities lowered the barrier of entry for a new generation of website creators. There were at least 38 million pages displayed by GeoCities before it was terminated by Yahoo! in 2009. This dataset collection contains a number of individual datasets that include data such as domain counts, image graph and web graph data, and binary file information for a variety of file formats like audio, video, and text and image files. A graphml file is also available for the domain graph.
Friendster was an early and widely used social media networking site where users were able to establish and maintain layers of shared connections with other users. This dataset collection contains graph files that allow data-driven research to explore how certain pages within Friendster linked to each other. It also contains a dataset that provides some basic metadata about the individual files within the archival collection.
These two related datasets were generated from the Internet Archive’s global web archive collection. The first dataset, “Parallel Language Records of the Early Web (1996–1999)” provides a dataset of multilingual records, or URLs of websites that have the same text represented in multiple languages. Such multi-language text from websites are a rich source for parallel language corpora and can be valuable in machine translation. The second dataset, “Language Annotations of the Early Web (1996–1999)” is another metadata set that annotates the language of over four million websites using Compact Language Detector (CLD3).
Applications are now being accepted from research teams interested in performing computational analysis of web archive data. Five cohorts teams of up to five members each will be selected to participate in the program from July 2021 to June 2022. Teams will:
Participate in cohort events, training, and support, with a closing event held at Internet Archive, in San Francisco, California, USA tentatively in May 2022. Prior events will be virtual or in-person, depending on COVID-19 restrictions
Receive bi-monthly mentorship via support meetings with the Archives Unleashed team
Work in the Archive-It Research Cloud to generate custom datasets
Receive funding of $11,500 CAD to support project work. Additional support will be provided for travel to the Internet Archive event
Looking for a research paper but can’t find a copy in your library’s catalog or popular search engines? Give Internet Archive Scholar a try! We might have a PDF from a “vanished” Open Access publisher in our web archive, an author’s pre-publication manuscript from their archived faculty webpage, or a digitized microfilm version of an older publication.
We hope Internet Archive Scholar will aid researchers and librarians looking for specific open access papers that may not be otherwise available to them. Judith van Stegeren (@jd7g on Twitter), a PhD candidate in the Netherlands, encountered just such a situation recently when sharing a workshop paper on procedural generation in computer games: “Towards Qualitative Procedural Generation” by Mark R. Johnson, originally presented at the Computational Creativity & Games Workshop in 2016. The papers for this particular year of the workshop are not indexed in the usual bibliographic catalogs, and the original workshop website hosting the Open Access papers is no longer accessible. Fortunately, copies of all the 2016 workshop papers were captured in the Wayback Machine, and can be found today by searching IA Scholar by title or conference name.
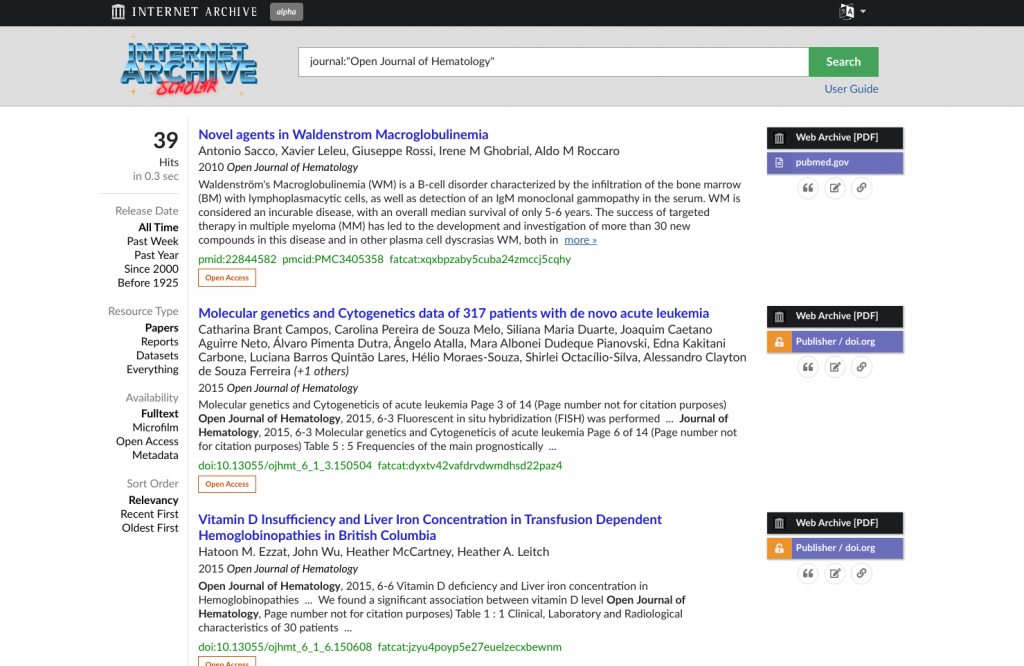
As another example, dozens of papers from the Open Journal of Hematology are no longer resolvable via DOI. As mentioned in a previous blog post, the publisher’s website vanished and has been replaced with unrelated advertisements. But before that happened, the papers were captured in the Wayback Machine, indexed in our catalog, and can now be searched in full:
IA Scholar Search Results
IA Scholar is a simple, access-oriented interface to content identified across several Internet Archive collections, including web archives, archive.org files, and digitized print materials. The full text of articles is searchable for users that are hunting for particular phrases or keywords. This complements our existing full-text search index of millions of digitized books and other documents on archive.org.
The service builds on Fatcat, an open catalog we have developed to identify at-risk and web-published open scholarly outputs that can benefit from long-term preservation, additional metadata, and perpetual access. Fatcat includes resources that may be useful to librarians and archivists, such as bulk metadata dumps, a read/write API, command-line tool, and file-level archival metadata. If you are interested in collaborating with us, or are a researcher interested in text analysis applications, we have a public chat channel or can be contacted by email at info@archive.org.
IA Scholar marks a milestone in our work initiated in 2018 to leverage the automation and scale of web and API harvesting in providing open infrastructure for the preservation of and perpetual access to scholarly materials from the public web. We particularly want to thank the Mellon Foundation for their original and ongoing support of this work, our many current partners, and the other collaborators, contributors, and volunteers.
All of this is possible because of the incredible open research ecosystem built and collectively maintained by Open Access advocates. Thank you to the DOAJ and other groups for helping catalog open access journals which has aided preservation. Thank you to the Biodiversity Heritage Library and its supporters for digitizing print journal literature. And thank you to the many other organizations we have worked with, integrated, or whose services we have utilized, including open web indices (Unpaywall, CORE, CiteseerX, Microsoft Academic, Semantic Scholar), directories of open journals (DOAJ, ROADSHERPA/ROMEO, JURN, Wikidata), and open bibliographic catalogs (Crossref, Datacite, J-STAGE, Pubmed, dblp).
Local history collections are necessary to understanding the life and culture of a community. As methods for sharing information have shifted towards the web, there are many more avenues for community members to document diverse experiences. Public libraries play a critical role in building community-oriented archives and these collections are particularly important in recording the impact of unprecedented events on the lives of local citizens.
Last week, we announced a major national expansion of our Community Webs program providing infrastructure, services, and training to public librarians to archive local history as documented on the web… We now invite public libraries in the United States and cultural heritage organizations in U.S. territories to apply to join the Community Webs program. Participants in the program receive free web archiving and technical services, education, professional development, and funding to build community history web archives, especially collections documenting the lives of patrons and communities traditionally under-represented in the historical record.
If you are a public librarian interested in joining the Community Webs program please review the full call for applications and the program FAQs. Online applications are being accepted through Sunday, January 31, 2021.
“Whether documenting the indie music scene of the 1990s, researching the history of local abolitionists and formerly enslaved peoples, or helping patrons research the early LGBT movement, I am frequently reminded of what was not saved or is not physically present in our collections. These gaps or silences often reflect subcultures in our community.” – Dylan Gaffney, Forbes Library, in Northampton, MA
The program is seeking public libraries to join a diverse network of 150+ organizations that are:
Documenting local history by saving web-published sites, stories and community engagement on the web.
Growing their professional skills and increasing institutional technical capacity by engaging in a supportive network of peer organizations pursuing this work.
Building a public understanding of web archiving as a practice and its importance to preserving 21st century community history and underrepresented voices.
Current Community Webs cohort members have created nearly 300 publicly available local history web archive collections on topics ranging from COVID-19, to local arts and culture, to 2020 local and U.S. elections. Collecting the web-published materials of local organizations, movements and individuals is often the primary way to document their presence for future historians.
“During the summer of 2016, Baton Rouge witnessed the shooting of Alton Sterling, the mass shooting of Baton Rouge law enforcement, and the Great Flood of 2016. While watching these events unfold from our smartphones and computers, we at the East Baton Rouge Parish Library realized this information might be in jeopardy of never being acquired and preserved due to a shift in the way information is being created and disseminated.” – Emily Ward, East Baton Rouge Parish Library
Benefits of participation in Community Webs include:
A three-year subscription to the Archive-It web archiving service.
Funding to support travel to a full-day Community Webs National Symposium (projected for 2021 and in 2022) and other professional development opportunities.
Extensive training and educational resources provided by professional staff.
Membership in an active and diverse community of public librarians across the country.
Options to increase access (and discoverability) to program collections via hubs, such as DPLA.
Funding to support local outreach, public programming, and community collaborations.
Please feel free to email us with any questions and be sure to apply by Sunday, January 31, 2021.
More than ever, the lives of communities are documented online. The web remains a vital resource for traditionally under-represented groups to write and share about their lives and experiences. Preserving this web-published material, in turn, allows libraries to build more expansive, inclusive, and community-oriented archival collections.
In 2017, the Internet Archive’s Archive-It service launched the program, “Community Webs: Empowering Public Libraries to Create Community History Web Archives.” The program provides training, professional development, cohort building, and technical services for public librarians to curate community archives of websites, social media, and online material documenting the experiences of their patrons, especially those often underrepresented in traditional physical archives. Since its launch, the program has grown to include 40 public libraries in 21 states that have built almost 300 collections documenting local civic life, especially of marginalized groups, creating an archive totaling over 50 terabytes and tens of millions of individual digital documents, images, audio-video, and more. The program received additional funding in 2019 to continue its work and focus on strategic planning, partnering with the Educopia Institute to ensure the growth and sustainability of the program and the cohort.
We are excited to announce that Community Webs has received $1,130,000 in funding from The Andrew W. Mellon Foundation for “Community Webs: A National Network of Public Library Web Archives Documenting Local History & Underrepresented Groups,” an nationwide expansion of the program to include a minimum of 2 public libraries in each of the 50 United States, plus additional local history organizations in U.S territories, for a total of 150-200 participating public libraries and heritage organizations. Participants will receive web archiving and access services, training and education, and funds to promote and pursue their community archiving. The Community Webs National Network will also make the resulting public library local history community web archives available to scholars through specialized access tools and datasets, partner with affiliated national discovery and digital collections platforms such as DPLA, and build partnerships and collaborations with state and regional groups advancing local history digital preservation efforts. We thank The Andrew W. Mellon Foundation for their generous support to grow this program nationwide and empower hundreds of public librarians to build archives that elevate the voices, lives, and events of their underrepresented communities and ensure this material is permanently available to patrons, students, scholars, and citizens.
Over the course of the Community Webs program, participating public libraries have created diverse collections on a wide range of topics, often in collaboration with members of their local communities. Examples include:
Community Webs members have created collections related to the COVID-19 pandemic, including Schomburg Center for Research in Black Culture’s “Novel Coronavirus COVID-19” collection which focuses on “the African diasporan experiences of COVID-19 including racial disparities in health outcomes and access, the impact on Black-owned businesses, and cultural production.” Athens Regional Library System created a collection of “Athens, Georgia Area COVID-19 Response” which focuses on the social, economic and health impacts of COVID-19 on the local community, with specific attention on community efforts to support frontline workers. A recent American Libraries article featured the COVID archiving work of public libraries.
Columbus Metropolitan Library’s archive of “Immigrant Experience”, a collection of websites on the activities, needs, and culture of immigrant communities in Central Ohio.
Birmingham Public Library’s “LGBTQ in Alabama” collection “documenting the history and experiences of the LGBTQ community in Alabama.”
Community Webs public librarians at IA HQ
We look forward to expanding the Community Webs program nationwide in order to enable hundreds of public libraries to continue to build web collections documenting their communities, especially in these historic times.
We expect to put out a Call for Applications in early December for public libraries to join Community Webs. Please pass along this opportunity to your local public library. For more information on the program, check out our website or email us with questions.