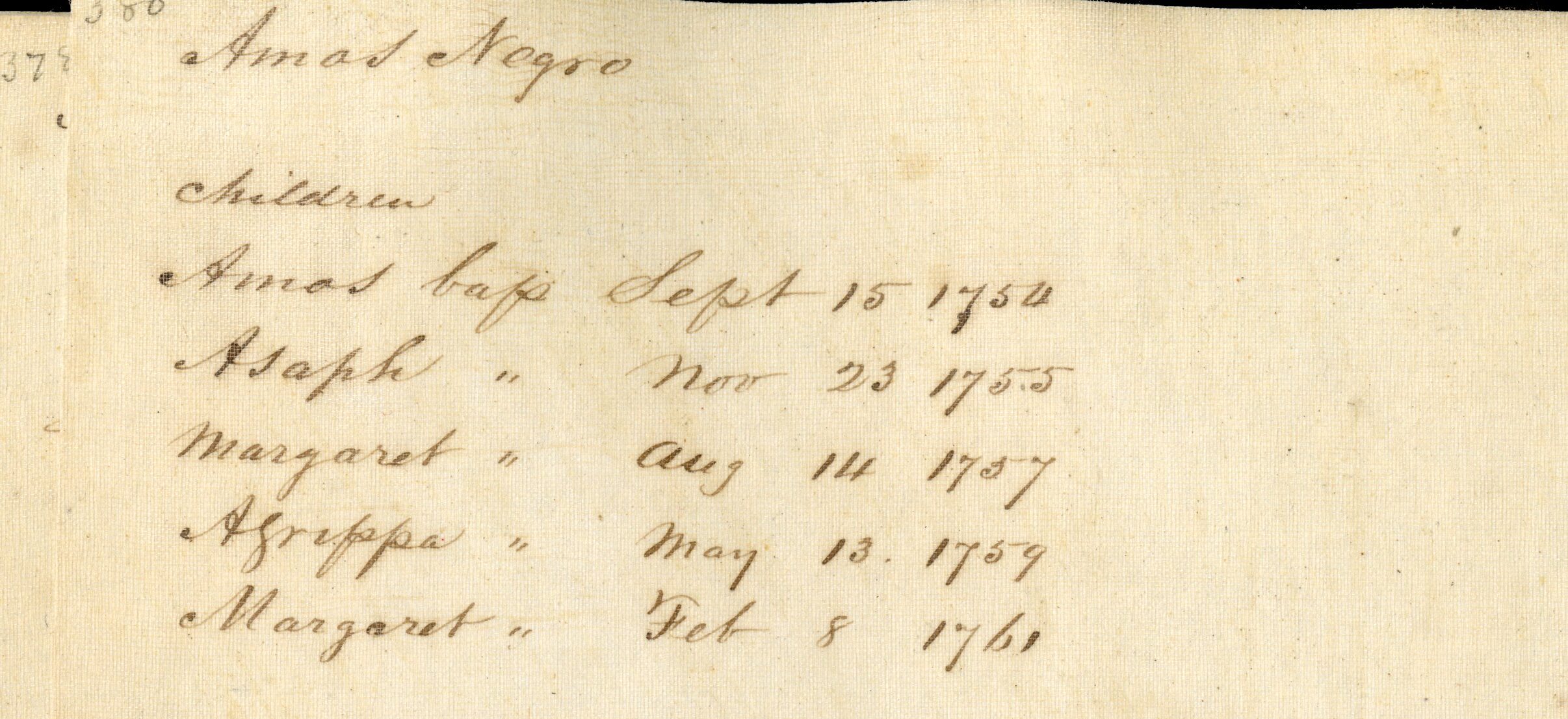In early March 2020, much like the rest of the United States, the staff of the Internet Archive transitioned to fully remote work in anticipation of the prolonged pandemic. This change was monumental and, like all workplaces, we discovered the challenge of sustaining a feeling of connection, morale, and joy within the team.
Recognizing this challenge, our Director of Media & Access, Alexis Rossi, came up with a creative solution. It was already part of our workplace culture to have two weekly all-staff meetings—one at 10am PT Monday morning, and another at Friday lunch. As everyone moved to joining those meetings from home, Alexis began hosting short concerts before them by performers, particularly musicians, to uplift our team’s spirits. These concerts provided not only entertainment, but also a means of keeping our team engaged and the performers booked during uncertain times.
The initiative began with a performance by Alexis’s friend, Jefferson Bergey, whose talent for musical theater and captivating stage presence set the stage. At the time, we envisioned organizing these concerts for just a few months, as none of us could predict the duration of the pandemic.
Fast forward several years and our work world has undergone a profound transformation. Encouraged by the overwhelmingly positive response from our now mostly remote staff, we decided to continue the program, thus giving birth to “Essential Music Concerts From Home.” As we approach our fourth anniversary in April, we reflect on how this simple yet impactful idea has helped sustain our remote workplace culture through the years. We thought it would be fun to offer you a glimpse into some of the unique musical encounters enjoyed by the Internet Archive staff with some exceptionally talented musicians.
Jefferson Bergey
Jefferson Bergey is a professional musician and cherished figure in the Bay Area, known as “Fun for Hire.” His musical style epitomizes versatility, adapting to any desired vibe or genre with ease. Drawing from the rich foundations of jazz, blues, pop, folk, bluegrass, and rock, his songs are crafted with a distinct flair for musical theater. He is such a popular Bay Area performer, there’s even a burger named after him.
Jeanie & Chuck Poling
Jeanie & Chuck Poling have been making music together since 1982. Their act, Jeanie and Chuck’s Country Roundup, specializes in honky tonk and bluegrass tunes played on acoustic instruments. Their performances are known for blending music, humor, and showmanship to entertain audiences. Additionally, Chuck has served as the emcee at the Rooster Stage at Hardly Strictly Bluegrass since 2012.
Joliet
Joliet, hailing from Kansas City, is an independent singer/songwriter and live music streamer. Her vocal style is both distinctive and commanding. With her bold and expansive sound, Joliet offers up heartfelt and captivating charm. She plays live on platforms such as Smule and Twitch, where she has introduced her original compositions to audiences worldwide.
Ben Cosgrove
Ben Cosgrove is a nomadic composer, pianist, and multi-instrumentalist rooted in northern New England. Across his artistic journey, Ben’s compositions and performances have been shaped by his profound fascination with landscape, geography, place, and the environment.
Cello Joe
Cello Joe, also known as Joey Chang, defies convention within the realm of cellists. Cello Joe combines the cello with beatboxing, vocals, and live looping to create a unique fusion. His performances blend classical music with hip hop elements, showcasing his ability to generate rhythmic beats using both his cello and vocal talents in real-time. He is known for being the “Wildest Beatboxing Cellist in the West”.
Glitterfox
Glitterfox is a Portland Oregon based band. At the heart of Glitterfox are the band’s songwriters and frontpersons, the married couple Solange Igoa and Andrea Walker. Drawing from their personal struggles and experiences as queer, neurodivergent individuals, they infuse their songwriting with raw emotion. They imbue their music with a passion for Americana, grunge, and dance genres.
Rob Reich
Rob Reich epitomizes the essence of the San Francisco music scene, serving as a cornerstone of its vibrant underground community. Renowned for his eclectic style, he blends robust melodic concepts, rhythmic dynamism, and a penchant for irreverence and innovation.
Please note that these recordings were conducted via Zoom, which often leads to lower fidelity audio quality. For a more immersive experience, we encourage you to explore these artists further on their respective websites.
If you would like to perform for one our 10 minute concerts please contact bz@archive.org.
In the leadup to our first public domain film screening on April 12th, we would like to introduce the curious case of a film entering the public domain immediately upon its release (Wikipedia).
In the realm of classic cinema, few films possess the enduring charm and intrigue of “Charade.” Released in 1963, this romantic comedy-thriller captivated audiences with its charismatic leads, sophisticated plot twists, and stylish Parisian backdrop. Yet, behind its glamorous facade lies a curious tale of copyright ambiguity and the unexpected journey into the public domain.
The Charismatic Charade
Directed by Stanley Donen, “Charade” stars the legendary Audrey Hepburn as Regina Lampert, a young woman entangled in a web of mystery following her husband’s murder. Alongside her is the incomparable Cary Grant, portraying the enigmatic Peter Joshua, whose true intentions remain shrouded in secrecy. The film’s witty dialogue, suspenseful plot, and undeniable chemistry between the leads made it an instant classic upon its release.
Copyright Conundrum Turned Opportunity
“Charade” found itself in a unique predicament due to an oversight in its initial release—the omission of a copyright notice, which at the time meant that the movie was not protected by copyright at all (Wikipedia). This unintentionally liberated the film, allowing it to enter the public domain in the United States.
The absence of copyright protection transformed “Charade” into a cultural treasure, accessible to all. It paved the way for widespread distribution through television broadcasts, home video releases, and digital platforms, democratizing access to this cinematic gem.
Join Us for a Screening on April 12th!
The Internet Archive will be holding a screening of Charade on Friday, April 12th starting at 6:30 pm, as the first of a series of public domain film nights.
Local film writer and Archive.org community member Keith Rockmael will introduce the film.
“Sinykin’s Big Fiction is a book of major ambition and many satisfactions. Come for the comprehensive reframing of a key phase in U.S. literary history, stay for the parade of interesting people, the fascinating backstories of bestsellers, the electrically entertaining prose. The story of literary publishing in the postwar period has never been told with such verve.” – Mark McGurl, author of Everything and Less: The Novel in the Age of Amazon
Book Talk: Big Fiction Thursday, May 9 @ 10am PT / 1pm ET Register now for the virtual event!
In the late 1950s, Random House editor Jason Epstein would talk jazz with Ralph Ellison or chat with Andy Warhol while pouring drinks in his office. By the 1970s, editors were poring over profit-and-loss statements. The electronics company RCA bought Random House in 1965, and then other large corporations purchased other formerly independent publishers. As multinational conglomerates consolidated the industry, the business of literature—and literature itself—transformed.
Dan Sinykin explores how changes in the publishing industry have affected fiction, literary form, and what it means to be an author. Giving an inside look at the industry’s daily routines, personal dramas, and institutional crises, he reveals how conglomeration has shaped what kinds of books and writers are published. Sinykin examines four different sectors of the publishing industry: mass-market books by brand-name authors like Danielle Steel; trade publishers that encouraged genre elements in literary fiction; nonprofits such as Graywolf that aspired to protect literature from market pressures; and the distinctive niche of employee-owned W. W. Norton. He emphasizes how women and people of color navigated shifts in publishing, arguing that writers such as Toni Morrison allegorized their experiences in their fiction.
Big Fiction features dazzling readings of a vast range of novelists—including E. L. Doctorow, Judith Krantz, Renata Adler, Stephen King, Joan Didion, Cormac McCarthy, Chuck Palahniuk, Patrick O’Brian, and Walter Mosley—as well as vivid portraits of industry figures. Written in gripping and lively prose, this deeply original book recasts the past six decades of American fiction.
DAN SINYKIN is an assistant professor of English at Emory University with a courtesy appointment in quantitative theory and methods. He is the author of American Literature and the Long Downturn: Neoliberal Apocalypse (2020). His writing has appeared in the New York Times, the Washington Post, the Los Angeles Review of Books, The Rumpus, Dissent, and other publications.
TED UNDERWOOD is a professor in the School of Information Sciences and also holds an appointment with the Department of English in the College of Liberal Arts and Sciences. After writing two books that describe eighteenth- and nineteenth-century literature using familiar critical methods, he turned to new opportunities created by large digital libraries, using machine learning to explore patterns of literary change that become visible across centuries and thousands of books. His most recent project moves in the opposite direction, using theories of historical interpretation to guide the development of large language models.
He has authored three books about literary history, Distant Horizons (The University of Chicago Press Books, 2019), Why Literary Periods Mattered: Historical Contrast and the Prestige of English Studies (Stanford University Press, 2013), and The Work of the Sun: Literature, Science and Political Economy 1760-1860 (New York: Palgrave, 2005).
Book Talk: Big Fiction Thursday, May 9 @ 10am PT / 1pm ET Register now for the virtual event!
Guest blog by ngọc triệu from the DWeb Camp Core Organizing team.
Thank you to all who joined us in our Information Sessions and took the time to share your questions with us over the past month. We received a great number of inquiries and have tried our best to answer them in this blog post.
If you find that your questions are not covered or if you need further clarification, please don’t hesitate to reach out to us at dweb+fellowship@archive.org.
Fellowship
Q: What are the qualities that you are looking for in Fellows? A: In selecting Fellows, we seek individuals who are building or leveraging network technologies to uplift communities facing systemic inequality and help bring about autonomy, resilience, justice and social equity. Rather than adhering to a rigid set of criteria, we embrace diversity in backgrounds and expertises among our Fellows.
Q: How are the Fellows selected? A: The Fellows are chosen by the Fellowship Selection Committee, which comprises past Fellows and members of the DWeb Core Team. Applications will be evaluated across four key areas:
DWeb Technology and Organizing: To what extent does the applicant utilize decentralized web technology and/or decentralized organizing tactics to tackle real-world challenges?
Community Engagement: How actively does the applicant work directly with and for under-resourced constituencies or marginalized communities?
DWeb Principles Alignment: Does the applicant and their work resonate with the values and spirit of the DWeb Principles?
Camp Participation: To what degree would the applicant benefit from attending Camp, and vice versa, how important is it that their perspective and experience is shared at the event for others to learn from?
Q: Do Fellows have to be super technical (in other words, do they need to know how to code)? A: No. Even though we prioritize applicants who have experiences developing and utilizing DWeb technologies in their work, we have also accepted Fellows who are not as technical in the past.
Q: What’s the best way to prepare for an application? A: The best way to prepare for your application is familiarize yourself with the DWeb Principles. You can also gain insight into previous Fellows and their projects: 2019 Fellows, 2022 Fellows, 2023 Fellows. This will help you assess whether you and your projects align well with the Fellowship Program.
If you have a technical background, emphasize how your work relates to DWeb technologies and their application in real-world situations. For non-technical applicants, discuss how your work could benefit from DWeb technologies and outline the support or connections you are seeking for at Camp.
We value brevity in responses. If you choose to apply through a written application, consider drafting your responses in a separate document to avoid losing your work while using a browser.
Q: What kind of knowledge, skills, and/or experience do you expect Fellows to share? A: Fellows are expected to share about the projects they work on and intend to present at Camp. This might encompass practical knowledge, professional skills, community stories, and related work experience, such as how they have utilized DWeb technologies to address the challenges facing their communities.
Q: What are examples of workshops or presentations that Fellows have organized at camp in the past? A: Here are some examples of workshops and talks the our previous Fellows organized:
Co-creating Terrastories. A multi-day build-a-thon workshop where participants worked on improving Terrastories (an open-source, offline-first app for mapping oral histories) to better suit the needs of the Haudenosaunee Indigenous community who are mapping traditional knowledge of water alongside scientific research about river contamination. Led by Rudo Kemper, 2022 Cohort and the Digital Democracy team.
Mesh Network Building Session. A workshop where participants learned how to crimp ethernet cable, build wireless links, and attach applications to the DWeb mesh community network. Led by Esther Jang, 2022 Cohort.
Old Policy, New Tech: Reconciling Permissioned Blockchain Systems with Transatlantic Privacy Frameworks. A talk by Remy Hellstern, 2022 Cohort.
This Is a Journey Into Sound: A Proposal for Beats, Tech and Future Economies. A workshop led by brandon king & Stacco Troncoso, 2023 Cohort.
Data Feminism: An Intersectional Approach to Data Gathering, Analyzing, and Sharing. A workshop led by Jack Keen Fox, 2023 Cohort.
Designing for Intersectional Data Sovereignty. A talk by Camille Nibungco, 2023 Cohort.
Q: How big will the cohort be this year? A: We aim to bring approximately 20 to 25 Fellows to DWeb Camp this year.
Q. Does the Fellowship cover visa fees? A: No, unfortunately, we can only cover travel expenses to/from your place of origin to Camp. However, we can provide you with a sponsorship letter and request expedited processing for your visa.
Q. Does the Fellowship cover travel from where the applicant is to Camp and back? What about food? A: Yes. If you arrive at Camp with a car, your gas and related expenses will be reimbursed. If you require a flight, our team collaborates with a travel agency to assist you in arranging your travel to and from Camp. In some cases, we can provide a stipend for taxi fares and meals when you’re in San Francisco.
At Camp, all meals are provided, including breakfast, lunch, dinner, and late-night snacks. Please note that there are no financial transactions at Camp and we encourage our campers to bring snacks to share with the community.
Q. Do you have to know how to set up a tent? A: No. As Fellows, your accommodation will be provided for you. However, if you are interested in learning how to set up a tent, we are happy to show you how during Build Days.
Q. Where to find prior nodes? Has there been traction from Fellows to set up new nodes in their country beyond the US and Europe? A: You can find a listing of all DWeb nodes here. Our Fellows have organized events and contributed to their local nodes worldwide over the past years. Last year, a few Fellows gathered and hosted the first DWeb Camp in Brazil with the support of CooLab.
You can read our reflections about the event here (in English) and here (in Spanish).
DWeb Camp
Q: What’s the focus of DWeb Camp this year? A: The theme of DWeb Camp 2024 is Migration: Moving Together. We’ll be exploring how we can move together toward the Web we want and deserve. Stay tuned for more information on our website!
Q. How many people do you expect to attend DWeb Camp this year? A: Last year, we had approximately 470 attendees and 35 Fellows at DWeb Camp. It’s worth noting that our event caters to a diverse age range, as we welcomed 25 attendees under the age of 18. We expect the same amount of attendees this year.
Q. Can you explain the different ways to volunteer if I’m not selected as a Fellow? A: Yes! There are three ways to volunteer:
1. Space Steward. As a Space Steward, your responsibilities include organizing and managing the schedule for your space, ensuring familiarity with Camp Navarro, and preparing the required space, equipment, and materials for talks and workshops. Your Camp ticket will be provided.
2. Camp Volunteer. As a Camp Volunteer, you’ll assist in setting up and taking down camp infrastructure, handling various kitchen duties, cleaning up, etc. You’ll be asked to work five 3-hour shifts (total 15 hours). You’ll receive a 50% discount on your camp ticket.
3. Weaver. As a Weaver, your role involves facilitating conversations among campers within small groups during Camp. This position is not compensated and requires the least time commitment.
Q: How are DWeb Camp & the Fellowship funded? A: DWeb Camp and the Fellowship Program are funded by various organizations and individuals. Some of our past sponsors include the Internet Archive, Filecoin Foundation, Ford Foundation, Mask, Gitcoin, Jolocom, Bluesky, Ethereum Foundation, and more.
If you’ve ever taken a tour of the Internet Archive headquarters with Brewster Kahle, you’ve likely watched him play a minute or two of the game “Prince of Persia” on our in-browser emulator. While talking through the technology involved, Brewster will press the keys to make the main character run through the dungeons of a kingdom, often dying rather quickly.
Over the years, the area around the “Prince of Persia” station has added additional decorations, including a print drawn by the creator of Prince of Persia, Jordan Mechner. Entitled A Faithful Friend, the print depicts a moment in the Prince of Persia Game where a small mouse visits the captive princess.
Worlds collided recently when Jordan Mechner, in town for the Game Developers Conference 2024 and doing some readings of his new graphic novel memoir Replay, stopped by the Internet Archive for a tour and discussion with Brewster.
This provided a unique opportunity for the creator of a game that Brewster had been playing for years to give him tips to learn how to do a better running jump and get farther along than he had in his many demonstrations on the tour. It can be reported that Brewster was a fast learner and took Jordan’s suggestions to heart.
Jordan was also kind enough to gift a signed copy of Replay to the Internet Archive.
Conversation turned to the Internet Archive’s help in Jordan’s work creating Replay, including images and research for the historical parts of the novel.
During the conversation, Jordan had this to say:
“I appreciate [The Internet Archive] as a graphic novelist and as a game developer. Everything I’ve done throughout my life has been based on inspiration that I get from other things and on research that I’m able to do. When I went online to write and draw this 320-page book about game development and about my life and my family’s history, I looked for visual references of everything from old postcards and photographs to video game consoles.”
“I wanted to draw the floppy disk caddies and 1970s movie posters I had in my office in Brøderbund when I was making the first Prince of Persia on the Apple II. And where could I find a 1983 April issue of Softalk magazine, which is how I learned 6502 assembly language programming? So many times, when I searched online, it was the Internet Archive that came through.”
Brewster agreed:
“Well, I’m glad we’ve been useful to you, but also thank you for going and being a model for taking something that’s very, very popular in the past and making sure that it makes it to a generation that is going to download it from GitHub and play with it and mod it and do something else with it. And you’re welcoming of that next generation, living and growing with your work.”
And Jordan couldn’t have been clearer:
“And I will say that I don’t feel harmed by that. A few years ago somebody took the time to port Prince of Persia to the Commodore 64, which the publisher had no interest in doing in 1989, because the Commodore 64 was already outdated as a platform. Even the Apple II was on its way out. But somebody has done it now just out of love, out of its challenge, and the fact that the source code was available made that easier, I hope.
“Making things available to this generation. They’re going to do weird different things with it, especially if it’s not a permission-based society. But that’s what creativity has always been based on.“
Jordan acknowledged: “Copyright law exists and was created to protect the incentive of creators to work really hard at making something. So that if someone makes something great against all odds and it gets out there and sells a lot of copies, they can make money from it. But at a certain point, things that have been created need to then be used by other people to make their versions of it. The games and movies that we love, operas, films made of the works of Shakespeare, are building on creations of the past.”
There was one last reunion in the visit: Years ago, the Archive was donated a travel case (for trade shows) used by Jordan’s game publisher, Brøderbund Software. It currently lives in one of the Internet Archive’s guest rooms, and Jordan got a quick selfie with a piece of his own history.
As an editorial strategist and tech journalist, JD Shadel spends a lot of time thinking about how the content on the internet continues to rapidly evolve. One telling example they’ve followed closely is the evolution of GIFs. Two decades ago, the web was filled with millions of jittery, pixelated, handmade GIFs wherever you looked. And for many of us, there’s a nostalgia for the early days of the web when things felt a bit wilder and untamed.
That nostalgia for the version of the internet they grew up with is what first sparked Shadel’s interest in collecting old-school GIFs. During the first months of pandemic lockdowns in 2020, Shadel started spending a lot of their extra spare time diving deep into the Internet Archive’s GifCities collection. Shadel’s personal fascination began with under construction GIFs, a rich niche in the GifCities collection full of animated construction workers and tools. Then came seeking out GIFs of Furbies, Tamagotchi, and other cultural touchstones that the 33-year-old came of age with online. Over the next few years, downloading and organizing GIFs became a hobby for Shadel.
Recently, it came time to update Shadel’s professional website. “It’s one of those evergreen chores it’s easy to obsess over as a freelancer, when your website is your calling card for new work,” said Shadel, who found themself digging back through the hundreds of GIFs they’ve curated thanks to the Internet Archive.
Early cyberspace-themed GIFs became the theme for their new and somewhat unconventional portfolio, which features more than two dozen images sourced entirely from GifCities. Users can, for example, click on a spinning globe for an introduction or a British Furby to learn about Shadel’s background as an American now based in London—including editorial work for outlets such as Vice, The Washington Post, and Conde Nast Traveler and consulting for clients including Airbnb and Adidas.
“I’m so happy GifCities exists to capture that specific snapshot of the internet,” Shadel said. “It really relates, metaphorically, to a lot of my work where the real world and the internet blur, where the digital and the physical intersect.”
In addition to GifCities, the Wayback Machine has also been useful to Shadel. Professionally, it is a resource when reporting and fact checking stories. Personally, they recently found material from a band they played in years ago.
“The Internet Archive just touches my digital life in so many different ways,” Shadel said. “As a journalist, it’s a fact-checking tool. Having the ephemeral internet preserved for future researchers, writers, reporters and editors is a huge service to democracy. And it’s also just fun.”
On the website with its Space Jam-like navigation, Shadel wanted to reference the history of the internet — and maybe even inspire visitors to think more actively about their own role in charting the future. “I think we can reclaim our digital lives and rekindle the notion of ourselves as ‘netizens’—citizens of the internet and not just passive participants,” Shadel said.
“That’s why the work of the Internet Archive is so important,” they continued. “Despite the fact that we have access to more information than ever before, it’s really easy to forget digital histories and the lessons that we can learn from that.”
Shadel’s writing touches on a range of intersecting topics—such as tech, travel and queerness—but the one thing they hope everyone takes away from their work is the idea that we’re all netizens with a role to play in shaping what we want these shared public spaces to be.
“If we all have some shared sense of ownership of the internet, which is so involved in our lives, I believe we have a greater chance to make it better.” Sometimes, that can start in simple ways—in this case, building a DIY website with a bunch of old GIFs reminded one tech journalist in London that there are lessons we can take from the early internet. “We all have a part to play in making the internet a better place.” And at the least, they hope you enjoy the GIFs they’ve selected.
A family in Hatfield, ca. 1889. L.H. Kingsley, photographer.
Guest post by Dylan Gaffney, Information Services Associate for Local History & Special Collections, Forbes Library.
This post is part of a series written by members of the Community Webs program. Community Webs advances the capacity for community-focused memory organizations to build web and digital archives documenting local histories and underrepresented voices. For more information, visit communitywebs.archive-it.org.
Forbes Library has been a member of Community Webs since its inception in 2017. At that time, we were hopeful that the program would allow us to create an archive which more fully represented the community in which we live, and provide a more diverse history/record of our region and the people we serve. This project inspired archives staff to examine the many silences in our archives, and make plans for the ethical collection and preservation of materials that would help fill in these gaps in our historical record. At the same time, the library had begun to shift its focus toward collaboration with other local historical and community organizations.
In the years following the kickoff of the Community Webs Project, Forbes library co-hosted multiple series of exhibits, films, workshops, walking tours, and community reads on themes of mass incarceration, the Underground Railroad, and the history of slavery in our region. These events, and the passionate response of the community to them, inspired us to continue seeking out collaborations, large and small, and solidified our view that surfacing stories of people who had been underrepresented in the archives should be a core value in our work as an institution.
This work inspired Forbes Library, Historic Northampton, UMass Amherst, and the Pioneer Valley History Network to take lead roles in the 2021 Documenting Early Black Lives in the Connecticut River Valley project, which seeks to gather the fragmentary information about Black lives from the wide range of sources and archives in Western Massachusetts so that a whole might be perceived that is larger than the sum of those parts. The project, to date, has surfaced over 3500 records or references to people of color, enslaved and free, in Western Massachusetts from the 17th through 19th centuries. These histories are being made available through the project’s database and on the project website. We contributed an essay titled Searching for Black History in a Public Library Archive to the Project Handbook on the experiences and takeaways of doing this work from a public librarian’s perspective.
We know too little about Black lives in rural and small-town New England, and the places Black residents were able to carve out for themselves in these communities. With this project, we hoped to uncover names, details of their lives, and some small sense of how people of color survived in the Connecticut River Valley before and after the abolition of slavery in Massachusetts in 1783. At the kickoff event for the project, UMass Amherst professor Gretchen Holbrook Gerzina mentioned challenging the assumptions of others (sometimes called Gatekeepers) who “might be quick to discourage a researcher interested in Black History, reporting that they don’t have much…or not thinking about ways that records of white families might be useful to this research” Gerzina remarked that researchers, curators, and librarians should ”start from the perspective of presence.”
As the Documenting Black Lives project was undertaken with grant funding, and the time thus limited, we needed to develop an approach that would be productive right away. We identified several collections in the library’s Hampshire Room for Local History that we expected could be productive resources for identifying enslaved people in the area. The most promising of these was the Judd Manuscript Collection, a collection of 60+ volumes created by local newspaper editor and historian Sylvester Judd in the 1840s. The manuscript was originally purchased from the Judd estate by local historian James Trumbull and subsequently sold to the trustees of the library. It has been the property of the library since 1904, but use has been limited to a small group of academics and local historians who were aware of the contents and could physically visit during our few open archives hours. Those who knew of its tremendous historical value had discovered that it features content documenting Indigenous lives, enslaved people, and free Black people in New England and had used it to research Indigenous culture, the history of colonial settlement, enslavement, and the early abolitionist movement in the area.
Public Historian and Author Marla Miller on the value of Judd:
“Sylvester Judd, in his transcriptions of historic documents as well as the conversations he described with local residents, preserves extraordinary details that survive nowhere else. Because of Judd’s meticulous, wide-ranging work, I was able to gain insight into the lives of laboring people that would never otherwise have been possible…Judd’s notes preserve genealogical information about enslaved people that is found nowhere else. The Judd manuscript is almost archaeological in nature, with shards of evidence that can be unearthed via careful scrutiny. As he records, for instance, who had the first piano in town, who laid the first carpet, the sound of the geese squawking through Sunday sermons, and a hundred other small details of daily life, a picture emerges that simply cannot be found in any other kind of more formal or systematic archival material. These pages, filled from edge to edge with his notes, cross references, sketches, and other materials, simply teem with the kinds of details that historians crave, but cannot hope to find—except in Northampton.”
If we start from an assumption of presence (of underrepresented people both in the community and in the archives), the primary obstacles to discovering and surfacing information in collections like ours, often revolve around issues of access, and methodologies for search and discovery. We had long dreamed of digitizing all 60+ bound volumes of the collection to make them available to a wider group of researchers and the public at large. When the Community Webs program began to explore funding for a digitization program dedicated to expanding the amount and diversity of locally-focused community archives available online to users, the Judd Manuscript Collection seemed a good fit.
Now that the volumes have been digitized, our mission is to spread the word about their value and availability, so that the materials within can inform and inspire new research and discovery. As an illustration of the value of the collection and its contents, it is useful to look at how the increased availability of this resource could lead to new discoveries in long hidden collections. As an example, I will examine how Judd enriched our understanding of one local Black family.
Judd devoted entire volumes to genealogies of local families, but the 600+ page volume on Northampton Genealogies contains, to our knowledge, only two Black families, both listed without last names. The work we had done in the Documenting Black Lives project enabled us to compile a list of 3500+ entries for Black residents of the region in the period between the 1650-1900. We recognized these names as those of Amos and Bathsheba Hull and their children. Bathsheba can be found elsewhere in our own archives as a member of the Church of Christ during Jonathan Edwards ministry between 1729-1750, in records recorded by Jonathan Edwards own hand.
This entry transcribed from a local merchant’s account book shows items purchased by Amos Hull, the services he would perform in exchange for goods received, and the rate at which he was paid. It notes that in 1761, the same year their daughter Margaret was born, Amos Hull died. Afterward, his widow Bathsheba paid for his and her accounts by washing. Bathsheba surely would have a difficult time supporting multiple children without her husband, and documents subsequently found elsewhere in our archives and in other institutions prove this to be the case.
By 1762, a document found elsewhere in our archives records their son Asaph indentured to Seth Pomeroy, who is well known for his service in the French and Indian War and would go onto fight at the Battle of Bunker Hill and achieve the rank of Major General.
Bathsheba and her family come up again in several entries in Judd, including multiple mentions of the town seizing her land and displacing her from it in 1765. This cruel act forces Bathsheba and her young children from the town. Bathsheba and her son Agrippa would relocate to Stockbridge, Massachusetts. It is in Stockbridge where Agrippa Hull would enlist in May of 1777, and served for the remainder of the Revolutionary War in the Continental Army, including witnessing the surrender of British General John Burgoyne at Saratoga, New York, enduring the winter of 1777-78 at Valley Forge and was part of the battle at Monmouth Courthouse, New Jersey in June 1778. He then served as a personal assistant for the famed Polish general, revolutionary and engineer Taddeusz Kosciuszko and became a close friend of the General, during their years of War Service together. Agrippa’s story and friendship with Kosciuszko, along with Kosciuszko’s friendship with Thomas Jefferson is examined in Gary Nash and Graham Hodge’s 2012 book “Friends of Liberty: Thomas Jefferson, Tadeusz Kosciuszko, and Agrippa Hull”.
Portrait of Agrippa Hull, Courtesy of the Stockbridge Library, Museum & Archives.
Agrippa Hull went on to become the most prominent black landowner in Stockbridge MA and is buried along with his wife and children in Stockbridge Cemetery. His brother Amos Hull, Jr. also fought in the Continental Army, and surfaces in Belchertown MA records recorded as part of the Documenting Black Lives project.
This is just one brief example of the elaborate web of information that can be revealed when we prioritize the surfacing of stories that had previously been hidden in our collections, increase access through digitization, and collaborate to research and promote the information within.
“ We can hardly wait to learn— alongside the many other academic and avocational historians whose work will be enriched and transformed by these records—what else remains to be discovered. Once available in digital form, available for scouring by researchers with their own wide range of questions, these materials will certainly spark, inform, and enrich generations of new research, from student papers to dissertations to academic monographs. It is almost impossible to predict all the ways the volumes might reshape historiography, as well as conventional historical wisdom, because the contents at present are comparatively difficult to ferret out. But to be sure, these volumes have the potential to transform local and regional historical understanding, and once digitized, will certainly come to the attention of researchers nationwide.”
The Internet Archive and Community Webs are thankful for the support from the National Historical Publications & Records Commission for Collaborative Access to Diverse Public Library Local History Collections, which will digitize and provide access to a diverse range of local history archives that represent the experiences of immigrant, indigenous, and African American communities throughout the United States.
Join us for a book talk with ANDREA I. COPLAND & KATHLEEN DeLAURENTI about UNLOCKING THE DIGITAL AGE, a crucial resource for early career musicians navigating the complexities of the digital era.
“[Musicians,] Use this book as a tool to enhance your understanding, protect your creations, and confidently step into the world of digital music. Embrace the journey with the same fervor you bring to your music and let this guide be a catalyst in shaping a fulfilling and sustainable musical career.” – Dean Fred Bronstein, THE PEABODY INSTITUTE OF THE JOHNS HOPKINS UNIVERSITY
Based on coursework developed at the Peabody Conservatory, Unlocking the Digital Age: The Musician’s Guide to Research, Copyright, and Publishingby Andrea I. Copland and Kathleen DeLaurenti [READ NOW] serves as a crucial resource for early career musicians navigating the complexities of the digital era. This guide bridges the gap between creative practice and scholarly research, empowering musicians to confidently share and protect their work as they expand their performing lives beyond the concert stage as citizen artists. It offers a plain language resource that helps early career musicians see where creative practice and creative research intersect and how to traverse information systems to share their work. As professional musicians and researchers, the authors’ experiences on stage and in academia makes this guide an indispensable tool for musicians aiming to thrive in the digital landscape.
Copland and DeLaurenti will be in conversation with musician and educator, Kyoko Kitamura. Music librarian Matthew Vest will facilitate our discussion.
Unlocking the Digital Age: The Musician’s Guide to Research, Copyright, and Publishing is available to read & download.
ANDREA I. COPLAND is an oboist, music historian, and librarian based in Baltimore, MD. Andrea has dual master’s of music degrees in oboe performance and music history from the Peabody Institute of the Johns Hopkins University and is currently Research Coordinator at the Répertoire International de la Presse Musicale (RIPM) database. She is also a teaching artist with the Baltimore Symphony Orchestra’s OrchKids program and writes a public musicology blog, Outward Sound, on substack.
KATHLEEN DeLAURENTI is the Director of the Arthur Friedheim Library at the Peabody Institute of The Johns Hopkins University where she also teaches Foundations of Music Research in the graduate program. Previously, she served as scholarly communication librarian at the College of William and Mary where she participated in establishing state-wide open educational resources (OER) initiatives. She is co-chair of the Music Library Association (MLA) Legislation Committee as well as a member of the Copyright Education sub-committee of the American Library Association (ALA) and is past winner of the ALA Robert Oakley Memorial Scholarship for copyright research. DeLaurenti is passionate about copyright education, especially for musicians. She is active in communities of practice working on music copyright education, sustainable economic models for artists and musicians, and policy for a balanced copyright system. DeLaurenti served as the inaugural Open Access Editor of MLA and continues to serve on the MLA Open Access Editorial Board. She holds an MLIS from the University of Washington and a BFA in vocal performance from Carnegie Mellon University.
KYOKO KITAMURA is a Brookyn-based vocal improviser, bandleader, composer and educator, currently co-leading the quartet Geometry (with cornetist Taylor Ho Bynum, guitarist Joe Morris and cellist Tomeka Reid) and the trio Siren Xypher (with violist Melanie Dyer and pianist Mara Rosenbloom). A long-time collaborator of legendary composer Anthony Braxton, Kitamura appears on many of his releases and is the creator of the acclaimed 2023 documentary Introduction to Syntactical Ghost Trance Music which DownBeat Magazine calls “an invaluable resource for Braxton-philes.” Active in interdisciplinary performances, Kitamura recently provided vocals for, and appeared in, artist Matthew Barney’s 2023 five-channel installation Secondary.
MATTHEW VEST is the Music Inquiry and Research Librarian at UCLA. His research interests include change leadership in higher education, digital projects and publishing for music and the humanities, and composers working at the margins of the second Viennese School. He has also worked in the music libraries at the University of Virginia, Davidson College, and Indiana University and is the Open Access Editor for the Music Library Association.
Book Talk: UNLOCKING THE DIGITAL AGE April 3 @ 10am PT / 1pm ET VIRTUAL Register now!
Growing up in New Jersey, Beth Noveck says she was surrounded by so many books in her home that it felt like a library.
Simon and Doris Noveck. Image credit: Reiner Leist, American Portraits Prestel Publishing, 1999
Her father, Simon Noveck, was a voracious reader. A rabbi with a Ph.D. in political science from Columbia University, Simon collected books about Jewish philosophy, history, and sociology. Her mother, Doris, was interested in books about the arts and cooking. Together, they traveled around the world and often brought home souvenirs in the form of books, including a Turkish dictionary and a guidebook from a Jewish cemetery in Prague.
Over the years, the Novecks amassed a collection of more than 10,000 volumes. After they died (Simon in 2005; Doris in 2022), the family had to decide what to do with all the books.
“My parents had always talked about the idea of building a lending library, creating a home for the collection that people could access,” said Beth, a professor at Northeastern University in Boston.
While storing the items in a physical library was not feasible, Beth said the Internet Archive provided the perfect solution: Digitizing the collection.
Donating the collection
The donation process started by completing the Internet Archive’s physical item donation form. She then got in touch with the Internet Archive team who helped answer questions about the deduplication, packing and shipping process.
“We work with prospective donors to make sure that the valuable information in their collections will be unique to our library,” said Liz Rosenberg, Internet Archive’s donations manager. “Once we determine the collection will help add new resources to our library we help coordinate the logistics of getting the collection to the physical archives. There can be all sorts of logistics puzzles involved in physical item donations, especially for sizable donations like this one, like how to box books for efficient storage and transport. It’s always meaningful to work with families to help honor the legacy of their loved ones by preserving the materials they curated over time.”
Boxing and moving the collection.
In November, the family donated approximately 5,000 books in 200 boxes—every book from the collection that the Archive did not already have online. Staff from the Internet Archive provided the boxes, staff and two trucks to move the items from New Jersey to the physical archives. The items will eventually be scanned, cataloged and available for free to the public online.
“I can think of no better way to honor my father’s memory and all the work that he did to create this collection,” Beth said. “This way his legacy continues, and other people get to benefit from the work that he did. I’m so thrilled and grateful for this opportunity.”
To decide what to donate, Beth and her son, Amedeo Bettauer, 14, used the Donate Books app (iPhone / Android) from the Internet Archive to review each book to see if it would be new to the collection or a duplicate. The books had been moved to a family member’s house in New Jersey, where Beth and Amedeo went over the course of five weekends last fall (by plane, car or train) to sort out the collection.
“It was an occasion for a lot of reminiscence, wonderful stories and exchange of memories,” Beth said.
Understanding the collection
Born in 1914, Simon had served congregations in New York City and Hartford, Connecticut; was the head of adult education for B’Nai Brith; and wrote several books about Jewish history, sociology and philosophy. Living far from a research library in rural New Jersey, Beth said her parents frequently bought books and remained in touch with the wider world through their reading.
Sample book from the donation.
For Amedeo, who never met his grandfather, the process was a chance to learn more about his family’s history.
“Books really do reflect a person,” Amedeo said. “Getting to see my grandfather’s entire collection gave me a window into who he was, as a man, which was very interesting. There were some moments where I thought, ‘Wait, that’s a book that I might have gotten or that I even have.’ It was very enlightening to see.”
Amedeo and Beth said they were amazed at the breadth of the collection, including papers from U.S. presidents, and rare books on a variety of topics. The process was both sentimental and enjoyable, Beth said, knowing that her father had read every book they sorted. A long-time fan and supporter of the Internet Archive, she said it was very satisfying for the family to know that so much of the collection will be preserved.
“A lot of my grandfather’s books were very esoteric, so he might have been the only person left that had a physical copy of a certain book,” Amedeo said. “To have that be lost or destroyed would be a catastrophic loss of knowledge. This way the collection is digitized and forever available to everyone for free. I think it’s what my grandparents would have wanted.”
LOST LANDSCAPES OF SAN FRANCISCO: The City and Bay in Motion March 18 @ 6:30pm – 9pm Internet Archive, 300 Funston Avenue, San Francisco Buy Tickets
This 18th edition of LOST LANDSCAPES immerses viewers in the dynamic tapestry of mobility and communication across the Bay Area. Delving into the rich archival footage of San Francisco and its environs, the film captures the essence of daily life, work, and celebration, while revisiting both familiar and obscure historical moments.
This unique film event is taking place at the Internet Archive where you can experience rare and unseen footage from the Prelinger Archives. The film features footage drawn from a vast repository of over 3,000 newly scanned archival films, including home movies, government productions, industrial reels, and unexpected gems.
By attending, you’ll directly contribute to supporting the Internet Archive. Rick Prelinger will be presenting as per usual. Don’t miss this opportunity to be a part of truly special evening!
Doors open at 6:30 pm. Film starts at 7:30 PM. Register now!
No one will be turned away due to lack of funds!
LOST LANDSCAPES OF SAN FRANCISCO: The City and Bay in Motion March 18 @ 6:30pm – 9pm Internet Archive, 300 Funston Avenue, San Francisco Buy Tickets