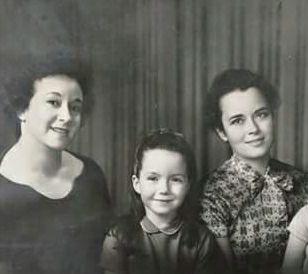by Nancy Watzman & Katie Dahl

With the turn of a dial, some flashing lights, and the requisite puff of fog, emcees Tracey Jaquith, TV Architect, and Jason Scott, Free Range Archivist, cranked up the Internet Archive 20th Century Time Machine on stage before a packed house at the Internet Archive’s annual party on October 11.
Eureka! The cardboard contraption worked! The year was 1912, and out stepped Alexis Rossi, director of Media and Access, her hat adorned with a 78rpm record.
1912
D’Anna Alexander (center) with her mother (right) and grandmother (left).
“Close your eyes and listen,” Rossi asked the audience. And then, out of the speakers floated the scratchy sounds of Billy Murray singing “Low Bridge, Everybody Down” written by Thomas S. Allen. From 1898 to the 1950s, some three million recordings of about three minutes each were made on 78rpm discs. But these discs are now brittle, the music stored on them precious. The Internet Archive is working with partners on the Great 78 Project to store these recordings digitally, so that we and future generations can enjoy them and reflect on our music history. New collections include the Tina Argumedo and Lucrecia Hug 78rpm Collection of dance music collected in Argentina in the mid-1930s.
1927
Next to emerge from the Time Machine was David Leonard, president of the Boston Public Library, which was the first free, municipal library founded in the United States. The mission was and remains bold: make knowledge available to everyone. Knowledge shouldn’t be hidden behind paywalls, restricted to the wealthy but rather should operate under the principle of open access as public good, he explained. Leonard announced that the Boston Public Library would join the Internet Archive’s Great 78 Project, by authorizing the transfer of 200,000 individual 78s and LPs to preserve and make accessible to the public, “a collection that otherwise would remain in storage unavailable to anyone.”

David Leonard and Brewster Kahle
Brewster Kahle, founder and Digital Librarian of the Internet Archive, then came through the time machine to present the Internet Archive Hero Award to Leonard. “I am inspired every time I go through the doors,” said Kahle of the library, noting that the Boston Public Library was the first to digitize not just a presidential library, of John Quincy Adams, but also modern books. Leonard was presented with a tablet imprinted with the Boston Public Library homepage by Internet Archive 2017 Artist in Residence, Jeremiah Jenkins.
1942
Kahle then set the Time Machine to 1942 to explain another new Internet Archive initiative: liberating books published between 1923 to 1941. Working with Elizabeth Townsend Gard, a copyright scholar at Tulane University, the Internet Archive is liberating these books under a little known, and perhaps never used, provision of US copyright law, Section 108h, which allows libraries to scan and make available materials published 1923 to 1941 if they are not being actively sold. The name of the new collection: the Sony Bono Memorial Collection, named for the now deceased congressman and former representative who led the passage of the Copyright Term Extension Act of 1998, which included the 108h provision as a “gift” to libraries.
One of these books includes “Your Life,” a tome written by Kahle’s grandfather, Douglas E. Lurton, a “guide to a desirable living.” “I have one copy of this book and two sons. According to the law, I can’t make one copy and give it to the other son. But now it’s available,” Kahle explained.
1944

Sab Masada
The Time Machine cranked to 1944, out came Rick Prelinger, Internet Archive Board member, archivist, and filmmaker. Prelinger introduced a new addition to the Internet Archive’s film collection: long-forgotten footage of an Arkansas Japanese internment camp from 1944. As the film played on the screen, Prelinger welcomed Sab Masada, 87, who lived at this very camp as a 12-year-old.
Masada talked about his experience at the camp and why it is important for people today to remember it. “Since the election I’ve heard echoes of what I heard in 1942,” Masada said. “Using fear of terrorism to target the Muslims and people south of the border.”
1972
Next to speak was Wendy Hanamura, the director of partnerships. Hanamura explained how as a sixth grader she discovered a book at the library, Executive Order 9066, published in 1972, which chronicled photos of Japanese internment camps during World War II.
“Before I was an internet archivist, I was a daughter and granddaughter of American citizens who were locked up behind barbed wire in the same kind of camps that incarcerated Sab,” said Hanamura. That one book – now out of print – helped her understand what had happened to her family.
Inspired by making it to the semi-final round of the MacArthur 100&Change initiative with a proposal that provides libraries and learners with free digital access to four million books, the Internet Archive is forging ahead with plans, despite not winning the $100 million grant. Among the books the Internet Archive is making available: Executive Order 9066.
1985
The year display turned to 1985, Jason Scott reappeared on stage, explaining his role as a software curator. New this year to the Internet Archive are collections of early Apple software, he explained, with browser emulation allowing the user to experience just what it was like to fire up a Macintosh computer back in its hay day. This includes a collection of the then wildly popular “HyperCards,” a programmatic tool that enabled users to create programs that linked materials in creative ways, before the rise of the world wide web.
1997
After  this tour through the 20th century, the Time Machine was set to 1997. Mark Graham, Director of the Wayback Machine and Vinay Goel, Senior Data Engineer, stepped on stage. Back in 1997, when the Wayback Machine began archiving websites on the still new World Wide Web, the entire thing amounted to 2.2 terabytes of data. Now the Wayback Machine contains 20 petabytes. Graham explained how the Wayback Machine is preserving tweets, government websites, and other materials that could otherwise vanish. One example: this report from The Rachel Maddow Show, which aired on December 16, 2016, about Michael Flynn, then slated to become National Security Advisor. Flynn deleted a tweet he had made linking to a falsified story about Hillary Clinton, but the Internet Archive saved it through the Wayback Machine.
this tour through the 20th century, the Time Machine was set to 1997. Mark Graham, Director of the Wayback Machine and Vinay Goel, Senior Data Engineer, stepped on stage. Back in 1997, when the Wayback Machine began archiving websites on the still new World Wide Web, the entire thing amounted to 2.2 terabytes of data. Now the Wayback Machine contains 20 petabytes. Graham explained how the Wayback Machine is preserving tweets, government websites, and other materials that could otherwise vanish. One example: this report from The Rachel Maddow Show, which aired on December 16, 2016, about Michael Flynn, then slated to become National Security Advisor. Flynn deleted a tweet he had made linking to a falsified story about Hillary Clinton, but the Internet Archive saved it through the Wayback Machine.
Goel took the microphone to announce new improvements to Wayback Machine Search 2.0. Now it’s possible to search for keywords, such as “climate change,” and find not just web pages from a particular time period mentioning these words, but also different format types — such as images, pdfs, or yes, even an old Internet Archive favorite, animated gifs from the now-defunct GeoCities–including snow globes!
Thanks to all who came out to celebrate with the Internet Archive staff and volunteers, or watched online. Please join our efforts to provide Universal Access to All Knowledge, whatever century it is from.
Editor’s Note, 10/16/17: Watch the full event https://archive.org/details/youtube-j1eYfT1r0Tc